
基于轻量级神经网络的新冠肺炎CT新型识别技术
2022-11-02 07:26郭艺杜秋晨吴朦朦马鹏涛李冠华
中国医学物理学杂志 2022年10期
郭艺,杜秋晨,吴朦朦,马鹏涛,李冠华
1.火箭军特色医学中心麻醉科,北京 100088;2.北京航空航天大学电子信息工程学院,北京 100191;3.火箭军特色医学中心影像科,北京 100088
前言
新型冠状病毒肺炎(简称新冠肺炎)是指由2019新型冠状病毒感染所导致的肺炎,具有传染性强和隐蔽性高等特点。目前,新冠肺炎感染了全球2亿人并导致500万人死亡,对经济发展和人民生活造成严重的影响。控制新冠肺炎最有效的方式是加强检测,有效地控制传染源。核酸检测利用病毒中特异性RNA 序列区分新冠肺炎病毒,已成为新冠肺炎检测的首要标准。但由于核酸检测至少需要4 h 才能得到结果,并且阳性准确率约为50%,需连续检测多次才能确诊,并且在疫情爆发地区存在核酸检测试剂数量不足的情况。对比之下,电子计算机断层扫描(CT)设备普及程度高,各级医院均可完成检测,并且CT 检测高效快捷、辐射量低、准确性高,已成为新冠肺炎临床检测的标准[1]。
新冠肺炎的CT 影像具有与其他肺炎不同的特征,新冠病毒进入人体后会在支气管和肺泡的上皮细胞中大量繁殖,人体则产生淋巴细胞和单核细胞对抗病毒,导致肺间质增厚、肺泡腔渗出增多,CT 影像呈现磨玻璃影。新冠肺炎早期的病灶多呈现于胸腔外围、肺部下方,CT 图像呈现小斑片状磨玻璃影;随着新冠肺炎的发展,病灶融合扩大,磨玻璃影出现不规则状,呈边界模糊的扇形或楔形;重症期病灶范围大量增加,胸腔大部分呈现磨玻璃影,俗称“白肺”[2]。虽然新冠肺炎的CT 影像特征明显,但由于患病初期的病灶范围小,识别准确率不高。
随着人工智能(AI)技术迅速发展,AI技术已经广泛应用于医学影像分析[3],在新冠肺炎CT识别方面取得了一定成果。研究表明,AI能够有效辅助低年资的影像科医师,提高新冠肺炎CT诊断的准确性[4]。国家超级计算长沙中心发挥AI和区块链等新技术优势,利用高性能计算资源提高检测效率和准确性[5]。国家超级计算天津中心提出新冠肺炎CT影像综合分析辅助系统,实现快速高效的新冠肺炎检测[6]。深度神经网络是AI技术在医学影像分析中的常用方法,深度神经网络可以从大量数据样本中自动学习新冠肺炎CT影像特征,但特征识别模型训练过程通常需要在高性能GPU上花费大量的时间,并且训练出的模型参数庞大,不适合在基层医院广泛部署。
为了提高新冠肺炎CT 影像识别率的同时降低深度神经网络的运算量,设计一种基于轻量级深度学习的新冠肺炎CT 新型识别技术,其创新点在于:(1)选取目前公开的所有新冠肺炎CT 图像数据集,经过数据集清洗、样本灰度图均衡化等预处理后作为训练数据,通过大样本提高深度学习的泛化能力,进而提高新冠肺炎CT 诊断的准确性;(2)提出基于DenseNet 的人工神经网络结构,采用GhostNet 卷积简化网络参数,使深度学习模型能够在无GPU 的医用计算机上运行,便于网络的部署及CT 序列识别;(3)利用传统图像处理方法进行肺部图像分割,利用分割出的肺部位置引导深度学习网络进一步提高新冠肺炎CT 诊断的准确性;(4)由于新冠肺炎检测中漏检比误检的风险更大,在损失函数中提出加权交叉熵函数,重点降低漏检率。误检情况可通过增强CT或其他诊疗方法进一步排查。
1 相关研究
新冠肺炎的CT 诊断方法引起越来越多的研究者重视,主流研究方法大多是基于神经网络的,从利用现有深度学习模型在新冠肺炎CT 图像上训练发展到利用新冠肺炎CT 图像的特点设计高精度的深度学习模型。
早期研究中,研究者利用现有的神经网络模型在新冠肺炎CT 数据集上进行微调,取得了一定的成果。文献[7]是最早将神经网络用于新冠肺炎CT 诊断的研究,作者利用AlexNet 识别新冠肺炎CT 图像,提取COVID-CT 数据集中每位患者的一幅图像作为训练集,达到80%的准确率,尽管准确率不高,但是证明了神经网络在新冠肺炎CT 图像识别中的可行性。文献[8]基于VGG模型进行新冠肺炎远程诊断,结合CT影像和X光图像使准确率达到了90%。文献[9]选择GoogleNet和ResNet神经网络模型在COVID-19数据集上进行试验,准确率分别为90%和91%。文献[10]采用ResNet152 和VGG16 网络模型,在所收集的2 373幅新冠肺炎CT图像中进行试验,准确率超过92%。上述方法采用通用的神经网络模型,没有结合新冠肺炎CT图像的特点,识别准确率有待提高。
针对新冠肺炎CT 图像识别准确率不高的问题,研究人员不断对神经网络模型进行改进,探索适合新冠肺炎CT 图像识别的模型。文献[11]从新冠肺炎病理区域提取图像块作为训练集,利用禁忌遗传算法获取卷积神经网络模型中最优的超参数组合,准确率达到93%,不过该方法仅能利用图像块的局部信息,不能利用肺部图像的整体信息。文献[12]基于公开的COVID-19 CT 分割数据集进行训练,在UNet++网络的基础上引入注意力模块和残差模块用于有效提取纹理和语义信息,不仅能够判断是否具有新冠肺炎,而且具有全自动分割新冠肺炎病灶区域的能力。文献[13]采用VGGNet 和ResNet 两个卷积神经网络作为基础的深度学习模型,引入可视化类激活图,提高新冠肺炎CT 识别的深度学习模型的可解释性。
2 数据集构建及数据预处理
2.1 数据集构建
为了提高新冠肺炎图像CT 识别的准确性,构建的深度学习数据集应包含尽可能丰富的新冠肺炎CT图像。在构建数据集的过程中,本研究整合了目前公开的新冠肺炎CT 影像数据集,构建出包含大量样本的数据集,该数据集优势在于:第一,使用公开数据集方便与其他研究者进行分析和对比,消除由于数据集中样本分布不同对结果造成的影响;第二,将多个数据集中的影像图像整合在一起,组合成大样本数据集,大样本量不仅能够提供足够多的新冠肺炎共性特征用于训练,而且能够提供不同患者的个性特征,增强深度学习网络泛化能力,从而提高新冠肺炎识别的准确性。
本研究构建的数据集整合了4种公开的数据集,分别为COVID-CT识别数据集[14]、COVID-19 CT分割数据集[15]、COVID-CTset数据集[16]和SIRM COVID-19数据集[17],4种数据集包含的新冠肺炎影像数量如表1所示。COVID-CT识别数据集是从medRxiv和bioRxiv预印本论文中提取的影像,多数为彩色PNG图像,根据论文中描述的患者情况,获取了216例肺炎患者的349张新冠CT影像。由于不同论文中影像的亮度、胸腔位置不同,数据集中的影像差异较大,COVID-CT识别数据集需要进行预处理;COVID-19 CT分割数据集包含40例患者的100幅CT影像,均为JPG格式,每幅图像有对应的由放射专家分割出的新冠肺炎区域,由于COVID-19 CT分割数据集是用于影像分割而非识别的,所以没有未感染新冠肺炎的影像;COVID-CTset是目前样本数量最多的新冠肺炎CT影像数据集,包含95例患者的15 589幅新冠肺炎CT影像以及48 260幅正常肺部影像,影像采用16位的TIFF格式影像序列表示,比8位图像包含更多的灰度级信息,但一些影像没有显示出肺窗,影像大小统一为512像素的正方形,TIFF格式影像不能直接显示,需要转化为灰度图像才能正常显示;SIRM COVID-19数据集包含60例患者的379幅图像,不仅有胸腔横向CT影像,而且有纵向CT影像。
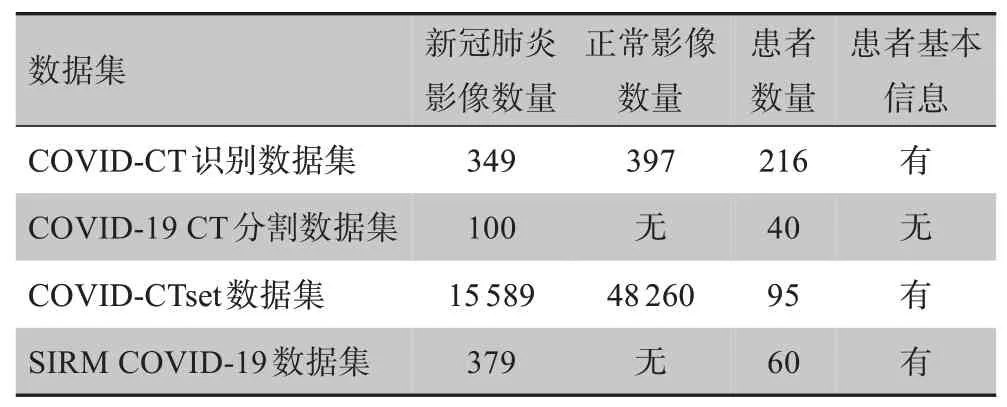
表1 整合的4种公开数据集对比Table 1 Comparison of 4 public datasets
2.2 CT影像预处理
预处理是CT 影像识别的前提条件,不同数据集中的影像亮度和尺寸不同,并且CT 影像序列中有部分图像没有包含肺窗,难以实现新冠肺炎识别。需要进行预处理的CT影像如图1所示。图1a中肺部影像区域较小,包含的肺部特征较少,难以进行新冠肺炎识别;图1b 中肺部影像亮度较低,影像特征不明显;图1c 中肺部影像亮度过高,会引入肺部血管影响的干扰。因此,CT 影像预处理包括影像亮度均衡化和数据集清洗两个步骤。亮度规范化是将不同数据集中亮度范围不同的图像规范化到同一范围,数据集清洗是去掉数据集中不能用于识别的无肺窗影像。
(1)图像亮度规范化:图像亮度规范化是将数据集中所有图像亮度规范化到同一范围,目的是消除不同数据集中影像数据范围的差异。例如COVIDCTset数据集中影像最大灰度值为5 000,其他数据集中影像最大灰度值为255,二者差距将近20 倍,特征差距太大会导致神经网络不容易收敛;此外,同一数据集中也会出现亮度差异很大的图像,例如图1b 和图1c 均源自COVID-CT 识别数据集。考虑到CT 影像的特点主要分为胸壁和胸腔两部分,分别以浅色和深色作为主要色调,将胸壁和胸腔分别规范化到两个固定灰度级,图像其他区域灰度级通过线性变换得出。图1经过亮度规范化后的结果图像如图2所示,可以看出所有数据集图像亮度处于同一范围。
(2)数据集清洗:数据集清洗的目的是剔除掉没有肺窗区域的图像,该类图像产生于CT 扫描的开始阶段和结束阶段,对肺部CT 新冠肺炎识别没有意义,去掉没有肺窗的图像可以防止对后续数据预处理过程造成影响。数据集清洗的方法是肺部图像分割,采用传统图像处理方法分割出肺窗区域,计算肺窗区域占整幅图像的比例。根据对数据集中图像的分析,肺窗区域占整幅图像的比例低于20%则认为肺窗区域过小,不能包含足够的特征用于检测识别,应该从数据集中去掉。
数据集清洗的具体步骤包括阈值分割、图像形态学和图像连通域操作。第一,阈值分割是对图像进行二值化处理,通过观察可见,肺窗区域是胸腔CT影像中最大的两个空洞,空洞的亮度值明显低于周围的腹腔壁,可以通过二值化进行区分,二值化的阈值使用经典算法大津法(OSTU)实现。二值化的结果是将图像大致分成3 个区域:外部区域、胸腔区域和胸壁区域;第二,经过阈值分割的影像胸腔区域留有一些毛细血管的图像,通过图像形态学中的开运算去除,开运算是先对图像进行腐蚀,去除图像细节部分,但胸壁区域会变薄;之后对图像进行膨胀,恢复影像中胸壁区域厚度,CT 影像经过开运算后得到光滑的分割图像;第三,通过计算连通域的面积确定胸腔区域占整幅图像的比例,如果比例小于10%则认为影像中没有肺窗,无法进行新冠肺炎识别,需从数据集中去掉。以图2c 为例,进行数据集清洗的过程图像如图3所示。
CT影像经过上述步骤不仅完成数据集清洗,同时实现肺窗区域的分割,虽然这种分割方法不一定精确,但是大致位置是正确的,可以用来作为辅助信息提高CT影像识别的准确性。新冠肺炎病灶集中在肺窗区域,新冠肺炎早期病灶集中在胸腔和胸壁交界处,正如图3c中黑色和白色分界线区域,所以利用CT影像分割结果能够为CT影像识别提供有用信息。
3 新冠肺炎CT识别模型
由于新冠肺炎CT 影像特征不明显,较浅的神经网络结构难以充分提取特征,识别准确度较低;较深的神经网络中用于训练的参数过多,在样本不足时容易过拟合,导致识别准确性降低。综合考虑现有网络模型,考虑选用DenseNet作为CT 影像识别的主干网络模型。由于DenseNet主要是通过拼接每个特征扩大特征容量,网络模型中参数量不会过大,有利于训练过程稳定收敛,提高识别准确性。新冠肺炎CT 识别模型如图4所示,图4a 表示组成DenseNet 的DenseBlock结构,图4b表示完整的DenseNet网络。
3.1 模型输入部分
新冠肺炎CT 识别模型的输入部分包括亮度规范化后的CT 影像(Ctimg)以及在数据集清洗过程中得到的胸腔区域分割结果图(Seg),Ctimg 为单通道灰度图像,Seg 为二值图像,二者融合方式为按通道拼接。首先将Ctimg 通过卷积核为3×3 的卷积层得到16 通道的特征图I,之后将I 与Seg 按通道拼接,得到17通道的特征图作为DenseNet识别部分的输入。
3.2 DenseBlock结构
DenseNet 是近年来提出的高精度网络结构,由于其高效利用了特征图,一定程度上减少了训练参数的数量,并且减轻了反向传播中的梯度消失,因此DenseNet 在图像生成和识别任务中均取得了较好的效果。DenseNet 由多个 DenseBlock 构成,DenseBlock 建立起所有层之间的密集连接,后一层的输入是前面所有输出特征层的按通道级联,实现特征层的重用。DenseBlock 的结构如图4a 所示,图中的DenseLayer 包含两个卷积层:第一个卷积层的卷积核大小为1、步长为1、边界填充为0、输出特征通道数为128;第二个卷积层的卷积核大小为3、步长为1、边界填充为1、输出特征通道数为32,每个卷积层之前都有BatchNorm 层和ReLU 层。DenseLayer 的输入特征图和输出特征图尺寸相同,输出特征图通道数固定为32,用于提取局部特征。
DenseLayer 是构成DenseBlock 的主要元素,图4a 中的DenseBlock 由3 个DenseLayer 级联组成,分别称为DenseLayer1、DenseLayer2 和DenseLayer3。DenseLayer1 的输入特征i0 为输入部分得到的17 通道特征,经过该层处理后得到浅层特征d1;DenseLayer2 的输入特征i1 为DenseLayer1 的输出特征d1 和DenseLayer1 前一层的d0 按通道拼接而成,通过DenseLayer2 的卷积运算得到中层特征d2;同理,DenseLayer3 的输入特征i2 为前面所有层的特征图d0、d1 和d2 按通道拼接而成,通过DenseLayer3 后得到深层特征d3;整个DenseLayer 的输出特征O 为d0、d1、d2和d3按通道拼接。
从图4a 可以看出,由3 个DenseLayer 组成的DenseBlock,实际应用中可由n个DenseLayer 组成DenseBlock,第i个DenseLayer 的输入为之前所有DenseLayer 的输出以及第一个DenseLayer 的输入按通道拼接而成,DenseBlock 的输出特征通道数为:输入特征通道数+DenseLayer 数量×32。通过DenseBlock,深度神经网络各个阶段的特征得到充分融合,有利于提取新冠肺炎特征。
3.3 DenseNet网络
DenseNet由多个DenseBlock组成,如图4b所示。图像识别神经网络通常通过池化层或步长大于1 的卷积层来减小特征图的大小,但是DenseBlock 的密集连接需要保证特征图大小一致,因此在每个DenseBlock 之间插入转接层来减小特征图尺寸。转接层由BatchNorm 层、ReLU 层、卷积层(核尺寸为1,步长为1)和平均池化层(核尺寸为2,步长为2)级联组成,经过转接层的特征图通道数和尺寸均减小为输入特征图的一半。
新冠肺炎CT 识别的DenseNet 模型包含4 个DenseBlock,每个DenseBlock 包含的DenseLayer 数量分别为6、12、32和32,每个特征图像的通道数标注在特征图向下方。最后通过全局池化层和线性层得到患病和正常的概率。
3.4 Ghost卷积
DenseNet 网络的后半段 DenseBlock3 和DenseBlock4 中由于卷积层通道数过多,会一定程度上影响网络的效率。文献[18]提出Ghost 卷积用于解决卷积层通道数量过多的问题,文献中可视化了卷积特征图中每个通道的图像,发现多组相似的特征图像,提出卷积层中的一半特征图可利用另一半特征图通过简单变换得到,如图5所示。以输入和输出特征通道数分别为256 和32 的卷积层为例,Ghost卷积首先通过普通卷积层得到166通道特征图L2,之后将L2 通过变换层得到L3,变换层通过通道可分离卷积实现,最后将L2 和L3 按通道拼接作为Ghost 卷积的输出。在特征图通道较多时会减少将近一半的计算量。
4 实验与分析
4.1 实验条件
实验中所用的硬件平台CPU 为Intel i7-7700K,16 GB 内存,显卡为NVIDIA GTX1080,8 G 显存。软件系统为CentOS7,Python 版本为3.6.8,深度学习框架为PyTorch 1.3.1。实验数据集按照5:1 随机划分为训练集和测试集,训练前批尺寸(BatchSize)和学习率需要设置为固定值,批尺寸通常根据经验值设置为4 或8,由于显存限制,实验中设置批尺寸为4,能够满足稳定收敛的要求。学习率首先通过经验值设定为0.01 进行训练,在训练中观察误差曲线,发现振荡较大,难以稳定收敛。改进学习率为0.001 后进行训练,发现误差曲线下降缓慢并且训练集损失和测试集损失有一定误差,表明网络有一定的过拟合。因此选择学习率为0.005。二分类模型的评价标准通常采用精确率、召回率、准确率和F1值,根据二分类混淆矩阵计算。二分类混淆矩阵包含TP、FP、TN 和FN 4个值,TP表示正确识别出的新冠肺炎影像数量,FP 表示把正常影像识别成新冠肺炎影像的数量,TN表示正确识别出的正常影像数量,FN 表示把新冠肺炎影像识别成正常影像的数量。
模型的精确率、召回率、准确率和F1值定义如式(1)~式(4)所示:
在上述指标中,召回率是新冠肺炎CT 识别中最重要的指标,保证能够完全检测出感染者,允许部分的正常人误检为患者。因此在二分类交叉熵损失函数的基础上提出加权交叉熵损失函数,即增大假阴性的惩罚,损失函数L表达式如下:
其中,y表示真实类别,患病为1,正常为0,y'表示网络预测概率,w为权重,设置为0.7。
4.2 迁移学习
实验过程采用迁移学习的方式进行训练。迁移学习利用新冠肺炎识别任务之间的相关性,把已经训练好的模型参数迁移到新的模型中,赋予新的模型先验知识,使模型学习效率提高,容易实现更高的分类精度[19]。本研究提出的网络模型的初始参数值参考文献[20],文献[20]中网络结构采用标准的DenseNet-169,与图4b 中的DenseNet 部分一致。文献[20]利用COVID-CT 识别数据集采用自监督方式进行训练,得到的精确率、召回率、准确率和F1值分别为0.91、0.79、0.85、0.84,是目前CT 影像识别效果最好的模型之一。
本研究提出的网络结构在DenseNet-169 的基础上增加输入部分,替换后两个DenseBlock 中的卷积层为Ghost 卷积并修改最后的线性层为全局池化层来减小训练参数量[21]。本研究提出的网络结构DenseNet 部分的前两个DenseBlock 层(D0-T2)与文献[20]中网络结构完全相同,利用文献[20]中训练好的网络参数作为初始值。DenseNet 部分的后两个DenseBlock 层(T2-D4)使用Ghost卷积,Ghost卷积层中一半的参数从文献[20]对应的卷积层中选取,另一半的参数通过学习关系自动生成。本研究提出网络的输入部分参数采用随机数方式初始化。
4.3 实验结果
为了证明本研究所提网络结构的有效性,采用本研究数据集与其他常见网络结构的结果进行对比。同时为了证明迁移学习的有效性,对本文网络没有使用迁移学习和使用迁移学习的情况进行对比,结果如表2所示。由表2可知,随着网络层数的增加,从VGG-16、ResNet-50 到DenseNet-169 的效果逐渐变好。本研究网络识别结果的召回率在所有对比方法中最高,表明加权交叉熵损失函数的有效性。虽然本研究网络精确率不是很高,但是在所有对比方法中处于平均水平。本研究网络在迁移学习中的效果好于无迁移学习的情况,表明迁移学习能够为网络参数提供先验知识,避免陷入局部最优。在迁移学习情况下,本研究网络召回率、准确率和F1值达到最高,表明所提出方法的有效性。
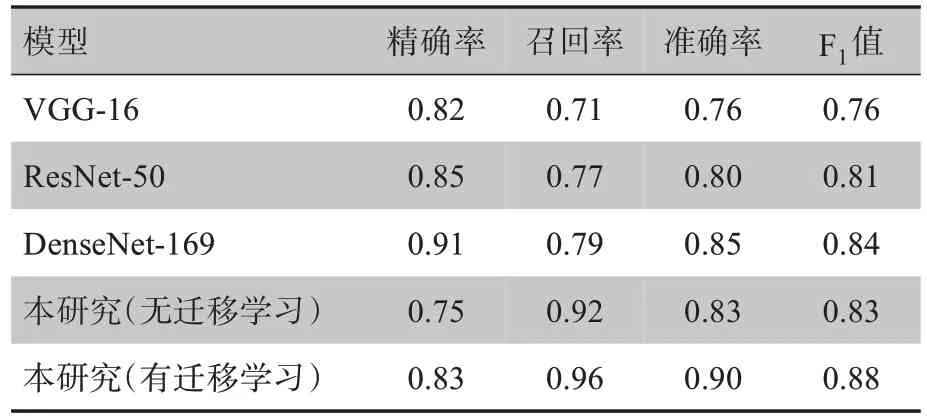
表2 实验结果对比Table 2 Comparison of experimental results
将训练好的模型移植到普通医用PC(CPU Intel i5-750,内存8 G,无GPU)上,模型推理时间为236 ms,能够达到快速识别的效果,能够满足对CT 影响序列的连续识别。虽然本研究网络对单幅CT 影像识别率有限,但对CT 扫描过程中的多幅影像识别结果进行综合分析判断后,能够得出非常准确的诊断结果。
5 结论
本研究提出的基于轻量级人工神经网络的新冠肺炎CT 影像识别方法,网络结构采用DenseNet主干网络外加轻量级Ghost 卷积,大量增加网络深度的同时没有增加太多训练参数。整合所有公开的新冠肺炎CT 影像数据集以提高网络泛化能力,加入肺部区域分割图像以提高网络的识别能力,采用加权交叉熵损失函数降低新冠肺炎识别的漏诊率,采用迁移学习的方法进行训练。实验结果表明,本研究所提出的方法能够有效识别新冠肺炎CT 影像,精确率、召回率、准确率和F1 值分别为83%、96%、90%和88%,后三项均优于对比方法,精确率处于所有对比方法的平均水平。这表明实验结果降低了漏诊率,能够保证有效地控制新冠疫情。所提方法虽然在新冠肺炎CT 识别方面取得了较好的效果,但随着新冠肺炎病毒不断变异,新冠肺炎CT 影响可能会呈现新的变化,网络模型应该快速适应这种变化,在实际使用中,应进一步提高人工网络模型微调的效率,以适应新冠病毒变化,保证网络识别效率始终在较高水平。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
青少年科技博览(中学版)(2021年4期)2021-08-30
今日农业(2021年7期)2021-07-28
小学生必读(中年级版)(2021年4期)2021-07-19
小读者之友(2020年4期)2020-05-15
电子制作(2019年11期)2019-07-04
