
Collaborative Pushing and Grasping of Tightly Stacked Objects via Deep Reinforcement Learning
2022-10-26 12:24:00YuxiangYangZhihaoNiMingyuGaoJingZhangandDachengTao
Yuxiang Yang, Zhihao Ni, Mingyu Gao, Jing Zhang,, and Dacheng Tao,
Abstract—Directly grasping the tightly stacked objects may cause collisions and result in failures, degenerating the functionality of robotic arms. Inspired by the observation that first pushing objects to a state of mutual separation and then grasping them individually can effectively increase the success rate, we devise a novel deep Q-learning framework to achieve collaborative pushing and grasping. Specifically, an efficient nonmaximum suppression policy (PolicyNMS) is proposed to dynamically evaluate pushing and grasping actions by enforcing a suppression constraint on unreasonable actions. Moreover, a novel data-driven pushing reward network called PR-Net is designed to effectively assess the degree of separation or aggregation between objects. To benchmark the proposed method, we establish a dataset containing common household items dataset (CHID) in both simulation and real scenarios.Although trained using simulation data only, experiment results validate that our method generalizes well to real scenarios and achieves a 97% grasp success rate at a fast speed for object separation in the real-world environment.
I. INTRODUCTION
GRASPING is one of the most fundamental problems in the area of robotics [1], [2], which has important applications in many scenarios, such as sorting robot, service robot and human-robot interaction. It has attracted increasing attention in recent years, however, remaining challenging for a robot arm to grasp tightly stacked objects automatically.
Traditional grasping methods are usually applied in a controlled environment with the known object model [3],which have limited the adaptability for different objects and scenarios. Recently, researchers apply deep learning and reinforcement learning into robotic tasks to improve the grasping success rate in various scenarios with different targets. For example, in [4]–[6], deep neural networks were used to predict the grasp point, angle, and jaw width from the input image. In [7]–[9], deep learning and reinforcement learning were combined for robotic grasping, which mapped the RGB-D image to specific action strategy and performed unsupervised learning to use the reward function. Although these methods can achieve grasping at a reasonable success rate, they struggle in handling tightly stacked objects since it is hard to find a suitable grasp point on an object and grasp it without causing collisions [10]. Therefore, how to design effective strategies to grasp tightly stacked objects remains challenging.
In practice, first pushing tightly stacked objects to a state of mutual separation can facilitate the subsequent grasping phase and significantly increase the success rate [11]. Therefore,how to model both tasks into a unified multi-task framework to enable collaborative pushing and grasping is a promising direction to solve the problem. Recently, some collaborative pushing and grasping methods [12]–[16] based on deep reinforcement learning have been proposed. Zenget al. [12]proposed a deep Q-learning framework to tackle this task.However, its reward function only accounts for whether there should be a push action without evaluating the consequence of the push action, which affects the effectiveness of the pushing strategy. The pushing reward functions in [13]–[15] were defined using the image difference before and after the pushing action, while the validity of the pushing action was still not evaluated. Yanget al. [16] evaluated the pushing effect using the maximum Q value of local area around the push point before and after the pushing action. Since the evaluation only accounted for the consequence of pushing at a local area, it may result in predicting ineffective actions that achieve no gains from a global perspective, e.g., separating a small group of objects while some of them may be closer to the remaining objects. Indeed, how to design a pushing reward function to comprehensively evaluate the consequence of the pushing action remains under-explored.
Besides, these methods [12]–[16] mainly used toy blocks as representative objects in the experiments, which have simple colors and shapes and lack of diversity and generality. Using simple objects during training may lead to a poor generalization capability when transferring to new scenarios,e.g., from the simulation environment to the real environment and from specific objects to unknown objects. Therefore, it is also very important to construct an object dataset containing objects in various shapes and colors to improve the generalization capability of the trained model.
To address these issues, we propose a novel collaborative pushing and grasping method based on deep Q-learning with an efficient non-maximum suppression policy (PolicyNMS),which can help to suppress unreasonable actions. Moreover, a novel pushing reward function based on convolutional neural networks called PR-Net is devised, which can comprehensively assess the degree of aggregation or separation between objects for each candidate pushing action from a global perspective, therefore helping the model to predict more effective pushing actions. Furthermore, we establish a dataset named CHID (common household items dataset) containing common household items in various colors and shapes and construct training scenarios from easy to difficult following the curriculum learning idea, which are beneficial to enhance the generalization capability of the collaborative pushing and grasping model. Experiments show that our method can efficiently accomplish the grasping task of tightly stacked objects via collaborative pushing and grasping and generalize well from simulation to real application and from specific objects to unknown objects as illustrated in Fig. 1. The proposed method has a wide range of applications like industrial parts sorting and household clutter sorting. The contributions of this study can be summarized as:

Fig. 1. Illustration of the proposed method for collaborative pushing and grasping tightly stacked objects.
1) A novel model-free deep Q-learning method is proposed for grasping tightly stacked objects via collaborative pushing and grasping, where an efficient PolicyNMS is devised to suppress unreasonable actions.
2) A novel pushing reward function called PR-Net is devised to predict the global reward for each candidate pushing action by comprehensively assessing the degree of aggregation or separation between objects.
3) A common household item dataset with curriculum training scenarios from easy to difficult is established to train and evaluate the model. Experimental results demonstrate the generalization capability of our model.
The remainder of the paper is organized as follows. Section II reviews related work. In Section III, we present the details of the proposed method, including the PolicyNMS, the reward functions, and the proposed CHID dataset. The experimental results and analysis are presented in Section IV. Finally, we conclude the paper in Section V.
II. RELATED WORK
A. Grasping Methods
Grasping is one of the most fundamental and interesting problems in robotics research. Recently, data-driven robotic grasping methods have achieved a lot of progress. 6D pose estimation methods [17], [18] were proposed to complete precise positioning of objects and achieved grasping. Kehlet al. [17] extended the popular object detection network SSD(single shot multibox detector) [19] for 6D pose estimation and achieved good results from a single RGB image. Wanget al. [18] proposed a DenseFusion network to extract RGB and depth features separately and fuse them to estimate precise 6D pose. But these methods all need the 3D model information of the target objects, which is difficult to acquire in many practical applications.
Differently from them, deep neural networks [4]–[6] were used to directly predict the grasp point, angle, and jaw width from the image, which can be well generalized to unknown objects and accomplish the grasping task. Mahleret al. [4]proposed a grasp quality convolutional neural network that predicts grasps location from synthetic point cloud data.Kumraet al. [6] proposed a generative residual convolutional neural network that usesn-channel input data to generate images that can be used to infer grasp rectangles for each pixel. Although good grasping performance has been achieved, these methods [4]–[6] based on supervised learning are limited to single grasp strategy and unable to achieve the coordination of different strategies throughout the task.
Reinforcement learning using long-term future views can help the agent to learn a more robust and comprehensive policy. In [8], [9], [20]–[22], deep reinforcement learning methods were proposed to model the grasping task and use reward functions to guide the grasp strategy for accomplishing the task, achieving good generalization performance.However, for densely stacked objects, grasping them directly will cause collisions between objects as well as collisions between the gripper and objects, resulting in failures.Differently from these methods, we propose a collaborative pushing and grasping method based on reinforcement learning, which first pushes the tightly stacked objects to separate them from each other and then grasps each object sequentially. In this way, our method can significantly improve the success rate.
B. Pushing Methods
Pushing is another fundamental task in robotics research[23]. Pushing to separate the tightly stacked objects can help improve the success rate of grasping. Actually, separating objects in close proximity is the prerequisite for many other subsequent operations [24], such as object classification,object arrangement, and object stacking. Deep learning methods are widely applied in robotic pushing problems [25],[26]. Katzet al. [25] presented an interactive segmentation algorithm to push cluttered objects. Similarly, Eitelet al. [26]also applied an object segmentation algorithm and then generated a series of push action sets based on the segmentation results. However, the segmentation results may be incorrect, especially for unknown objects, which greatly affect the robustness of these segmentation-based methods.
Reinforcement learning based pushing also attracts increasing attention in recent years [27], [28]. Andrychowiczet al. [27] proposed the hindsight experience replay method to train the policy for those robotic tasks like pushing from the sparse and binary reward. But their environments were pretty simple, where only one object was needed to be pushed in the workspace. Kiatoset al. [28] designed a pushing method to separate a target object from the cluttered environment based on reinforcement learning. However, it is designed to separate single specific target rather than all generic objects in the complex environment. Differently from these methods, we focus on obtaining the suitable push sequence to separate all the objects in dense clutter, which is essential to improve the success rate of subsequent grasping.
C. Multi-task Learning
Recently, researchers focused on multi-task learning of collaborative pushing and grasping [12]–[16] based on deep reinforcement learning. In [12], a deep Q-learning framework was proposed to address this task. However, the pushing reward function in [12] only assessed whether the object was pushed, rather than evaluating the effectiveness of the push action. Hence, this method [12] may result in pushing the whole objects in a certain direction. The pushing reward functions in [13]–[15] were defined using the scene image difference before and after the pushing action, while the effectiveness of the pushing action was still not assessed. The reward function in [16] evaluated the pushing consequence by comparing the Q value around the push point before and after the pushing action. However, only evaluating the pushing effectiveness in a local area may result in non-optimal pushing action from a global perspective, e .g., separating a small group of objects while some of them may be closer to the remaining objects. Besides, these methods mainly used toy blocks during training and testing, which have simple colors and shapes and lack of diversity and generality. Using simple training objects may lead to a poor generalization capability when transferring to new scenarios, e.g., from the simulation environment to the real environment and from specific objects to unknown objects.
By contrast, we establish a CHID dataset containing common household items in various shapes and colors, which can be used to improve the generalization capability of the trained model. In addition, following the multi-task learning idea, we design a novel collaborative pushing and grasping method based on deep Q-learning, where an efficient nonmaximum suppression policy is designed to suppress unreasonable actions. Furthermore, we propose a new datadriven pushing reward network that can comprehensively assess the degree of separation and aggregation between objects from a global view rather than the local neighborhood based assessment in previous method [16].
III. THE PROPOSED METHOD
Pushing and grasping objects using a robotic arm can be expressed as a Markov decision process (MDP) [29], [30].MDP is commonly represented by a quaternion (S,A,P,R),whereSdenotes the state space,Adenotes the action space,Pdenotes the transition probability, andRdenotes the reward function. The value-based reinforcement learning (RL)method can effectively deal with the MDP problem. Among them, deep Q-learning (DQN) methods [31]–[33] aim to obtain an end-to-end mapping functionQ(S,A;θ) from state spaceSto action spaceAby learning the network parametersθ, which have demonstrated good performance and great potential in the field of robotics. In this paper, a novel collaborative pushing and grasping framework based on DQN is proposed for automatically pushing and grasping tightly stacked objects. As shown in Fig. 2, the proposed framework consists of a pushing network (Action-PNet) and a grasping network (Action-GNet), which follows the idea of first separating the cluttered objects by pushing and then grasping them one-by-one.
A. Collaborative Pushing and Grasping Network
The action space includes four components: action type∅={push,grasp}, locations (x,y,z), rotation angle Θ, and push lengthL. During pushing, we set ∆Θ=22.5° to indicate the interval of pushing directions in a range of 360°, i.e., a total of 16 pushing directions. During grasping, we set∆Θ=11.25°in a range of 180°to indicate the interval of grasping directions, i .e., a total of 16 grasping directions.
At timet, the statestis obtained from the RGB-D images.Specifically, we map color and depth images to the robotic arm coordinate system and obtain the color-state-map and the depth-state-map. As shown in Fig. 2, our Action-PNet and Action-GNet are built upon the 121-layer DenseNet [34] pretrained on ImageNet [35] to extract features from the colorstate-map and depth-state-map. After feature concatenation,two identical blocks with batch normalization (BN) [36],rectified linear unit (ReLU) [37], and 1×1 convolution are used in Action-PNet and Action-GNet for further feature embedding. Then, the bilinear interpolation layer is used to obtain the pixel-wise state-action prediction valueQ(st,a;θ).Note that the pushing process switches to the grasping process according to the separation degree of objects, i.e., the pushing state-action prediction value will decrease to a low level when the objects are already separated from each other.
Moreover, efficient prior constraints are devised to reduce the complexity of action space and accelerate the training process. As shown in Fig. 2, we present the dynamic action maskM(st,∅) to optimize the action strategy
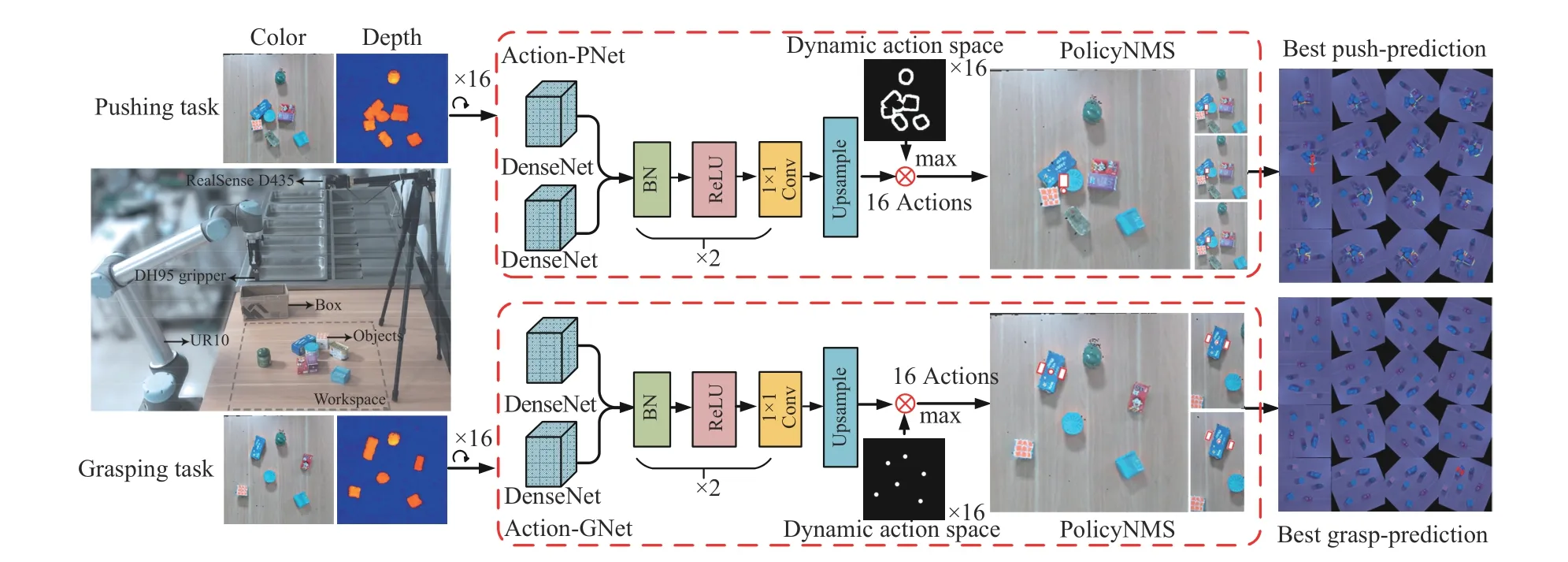
Fig. 2. Illustration of the proposed collaborative pushing and grasping method based on deep reinforcement learning.
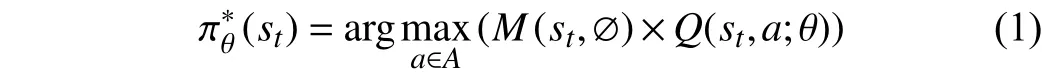
where,M(st,∅) is obtained by the object contours for pushing actions, andM(st,∅) is obtained by the centers of object contours for grasping actions.
B. Non-maximum Suppression Policy (PolicyNMS)
Non-maximum suppression (NMS) algorithms [38], [39] are widely applied to deal with highly redundant candidate boxes in object detection tasks. Inspired by these NMS algorithms,we propose an efficient PolicyNMS to suppress unreasonable actions. Specifically, we construct redundant boxes on each candidate action and calculate the confidences ( i.e., the object percentage) of redundant boxes to evaluate the reasonableness of an action as shown in Fig. 3.
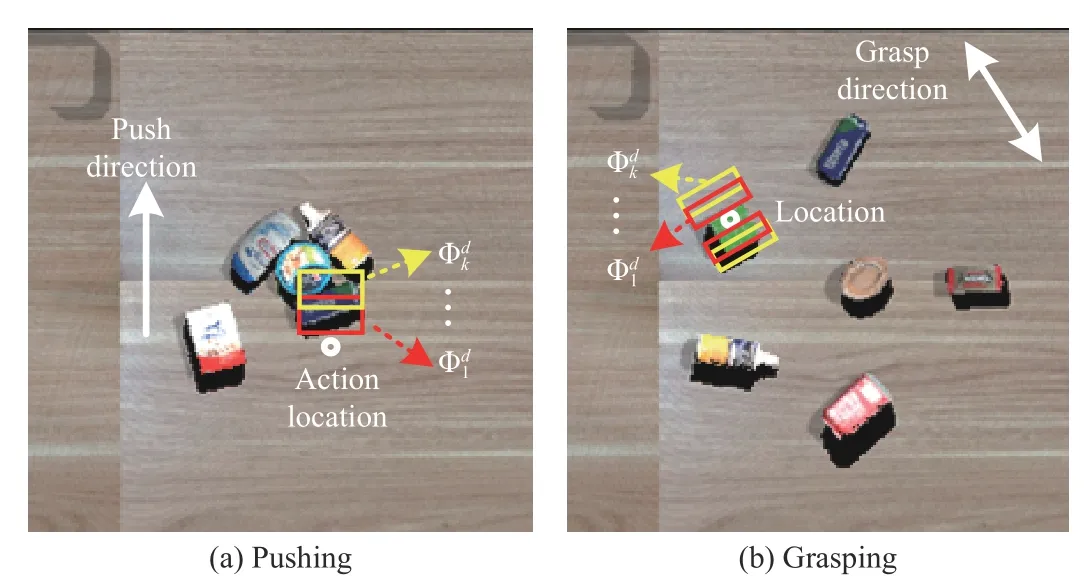
Fig. 3. Illustration of our PolicyNMS.
PolicyNMS aims to use a constraint πNMS(st) to suppress unreasonable actions and help to obtain the final action as

According to (1), we can obtain the action locations (x,y,z)and the corresponding state-action predictions in 16 action directions, respectively. As shown in Fig. 3, different shifts at the original action location are implemented along each action direction to obtain the boxes, wherek∈[1,K] denotes different shifts in each direction,d∈[0,15] denotes 16 directions. For pushing and grasping, boxes of different shapes are designed as shown in Figs. 3(a) and (b). The probabilityis defined as the percentage of objects in the box. Then, the probabilitiescorresponding to different shifts in the same direction are averaged to get the action probabilityPd
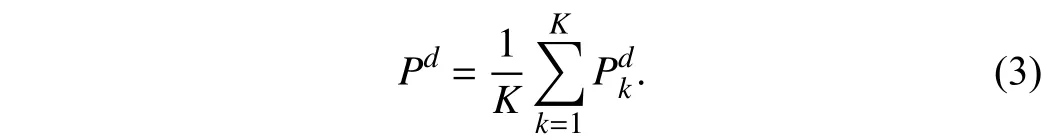
During pushing, a largerPdrepresents a higher possibility of successfully pushing the object. For grasping, a smallerPdmeans a larger grasping space for the gripper and a lower possibility of collision. Therefore, for 16 action directions we can obtain the constraint on unreasonable action πNMS(st)
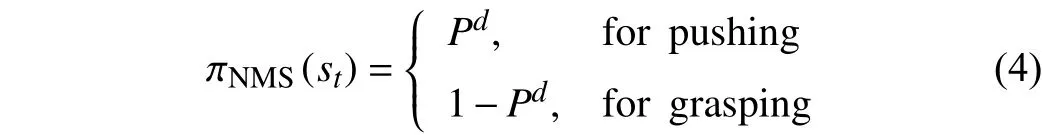
where πNMS(st) is a 16-dimensional vector.
By using such a constraint for unreasonable action suppression, our method can significantly improve the convergence speed and predict more reasonable actions.
C. Rewards for Pushing and Grasping
To better evaluate the quality of the action strategies, novel rewards for pushing and grasping are designed in this paper.As shown in Fig. 4, a convolutional neural network based pushing reward is designed to evaluate the separation or aggregation trend after pushing, called PR-Net.
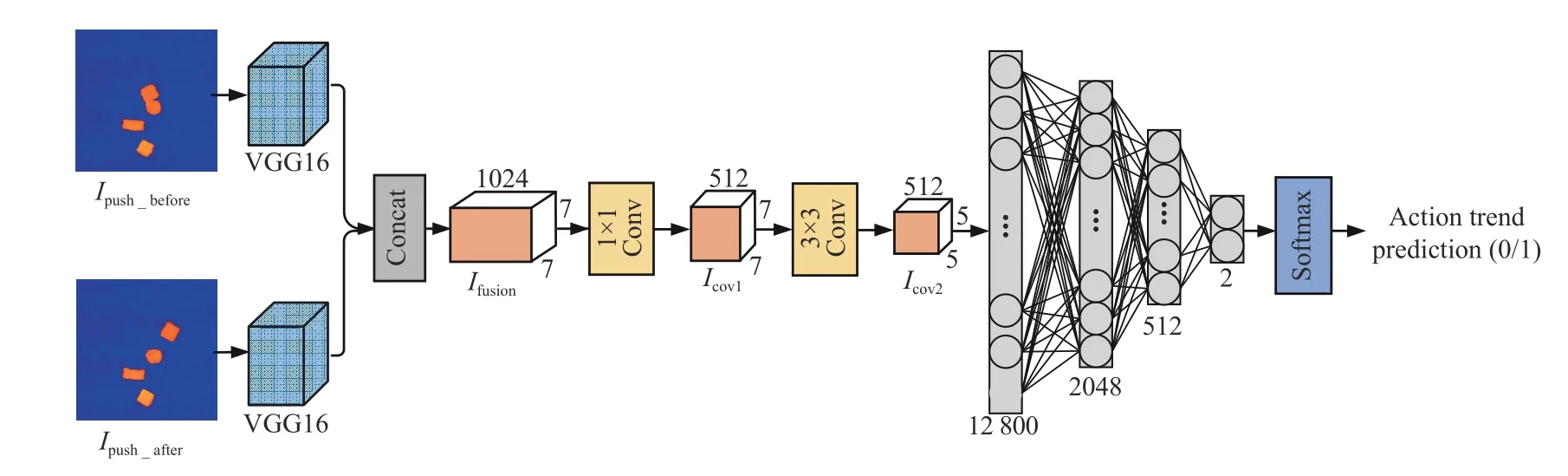
Fig. 4. The proposed PR-Net architecture.
Firstly, two sequential depth-state-mapsIpush_before,Ipush_afterof size 224×224×3 are fed into two branches, respectively.In each branch, the VGG-16 (visual geometry group 16-layer)network is used as the backbone and outputs the 7×7×512 feature maps. Then, the feature maps from both branches are concatenated to obtain the 7×7×1024 fused feature mapsIfusion, which are fed into a convolution layer with a kernel of size 1 ×1, followed by a BN layer and an ReLU layer, i .e.,
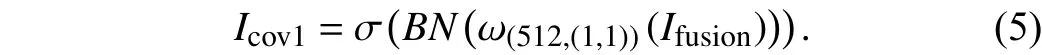
whereIcov1∈R512×7×7denotes the output feature maps, and ω(512,(1,1))denotes the learnable parameters,BN(·) denotes the batch normalization layer, and σ(·) denotes the ReLU activation layer.
Then, we obtainIcov2∈R512×5×5by feeding the output feature maps into another convolution layer with a kernel of size 3×3×512, followed by a BN layer and an ReLU layer,i.e.,

The feature mapsIcov2are flattened and fed into three fully connected layers. We use dropout to avoid overfitting and an ReLU layer as the activation function after the first two layers.The last fully connected layer is fed into a softmax layer to predict a probability vector for a binary classification task, i .e.,whether or not the objects are separated further after a pushing action.
We use the cross-entropy loss to train the PR-Net
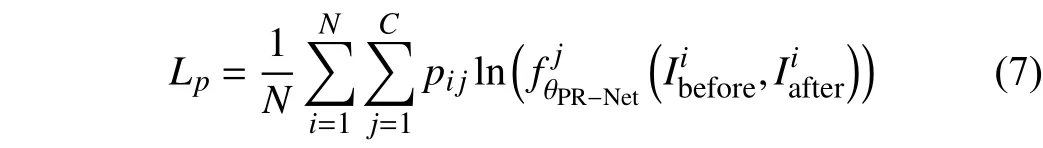
whereandrepresent theith input image pair of the PR-Net, θPR−Netrepresents the learnable parameters of the PRNet,represents the mapping function of the PR-Net,pijrepresents the one-hot encoding vector of the ground truth label of theith sample,Crepresents the number of classes,Nrepresents the total number of samples in the training set,Lp(·) represents the loss function of the PR-Net.
Finally, a pushing rewardrpcan be derived from the output of the PR-Net, which is defined as
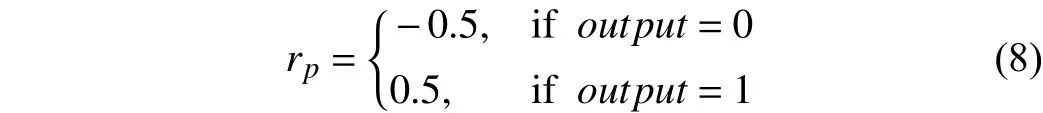
whereoutput=0 means that the push action aggregates the objects, andoutput=1 means that the push action separates the objects.
PR-Net can efficiently predict the global reward for each candidate pushing action by assessing the degree of aggregation or separation from the full view of scene.
An efficient grasping reward functionrgis also designed
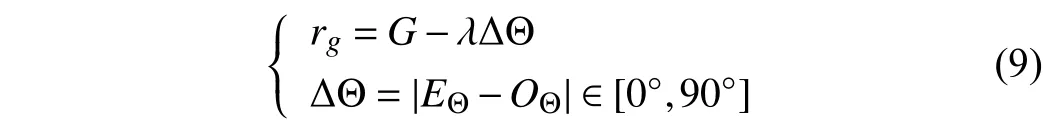
whereGdenotes the grasp result, i.e., 0 for a failed grasp and 1.5 for a successful one. ∆Θ denotes the angle constraint indicating the absolute difference between the rotation angleEΘof gripper and the angleOΘof the object,λis a hyperparameter, which is set to 0.02. The angle constraint ∆Θ can help to obtain a more precise grasp policy, which will be discussed in Section IV.
D. The Common Household Item Dataset (CHID)
Differently from [12]–[16], [40], we use common household items as the targets in our pushing and grasping task. To this end, we establish a common household item dataset (CHID),which contains many different household items in various shapes, colors, textures, and sizes, i.e., a better collection of various generic objects in the household scenario.Specifically, we select the household object meshes from Freiburg spatial relations dataset [41] and 3D Warehouse Web1https://3dwarehouse.sketchup.com. We also set the physical properties for these objects, so that the dataset can simulate physical collision, friction, and other phenomena in the real world. The simulation items in the training set and testing set are shown in Figs. 5(a) and (b),each includes 15 kinds of objects. Note that the objects in the testing set are disjoint with those in the training set. The realworld testing items for testing are presented in Fig. 5(c),which are also disjoint with the simulation items in the training set.

Fig. 5. Some items from the CHID dataset. (a) Simulation items in the training set; (b) Simulation items in the testing set; (c) Real-world items for testing.
Then, we randomly selectn∈[3,6] objects in the training set to build training scenarios and randomly selectn∈[3,8]objects in the testing set to build testing scenarios. To learn an effective pushing strategy to separate objects, we set two difficulty levels during training by following the idea of curriculum learning. As shown in Fig. 6(a), there are clear gaps between objects in the easy scenarios, which are used for the initial stage of training. As shown in Fig. 6(b), objects in the difficult scenarios are packed tightly, which are used for the later stage of training. Training from easy to difficult is beneficial for speeding up the convergence and learning a robust pushing strategy. As shown in Fig. 6(c), the real-world testing scenarios are very different from the simulation ones,which are used to evaluate the generalization capability of the proposed method.

Fig. 6. Training and testing scenarios. (a) Easy scenarios for the initial stage of training; (b) Difficult scenarios for later stage of training; (c) The real-world testing scenarios.
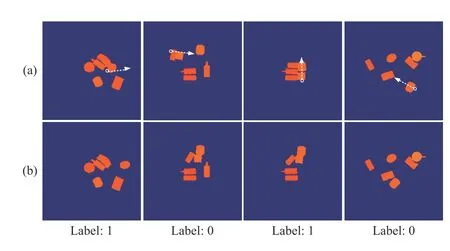
Fig. 7. Some training and testing pairs for our PR-Net: (a) Depthstate-maps before a pushing action; (b) Depth-state-maps after the action. The bottom labels denote aggregation (0) or separation (1). The white arrows indicate the pushing directions.
Finally, we establish the training and testing sets for our PRNet as shown in Fig. 7, including 31 628 training pairs and 7907 testing pairs. Each pair contains the depth-state-map before a pushing action and the depth-state-map after the pushing action, as well as the ground truth label, i.e., 0 means aggregation while 1 means separation.
IV. EXPERIMENTAL RESULTS
In the experiments, we evaluated the proposed method in both the simulation and real-world environments. First, we compared our method with the Non-RL pushing method and directly grasping method to verify the performance of the proposed method. Then, we performed the ablation studies to validate the effectiveness of the proposed PolicyNMS and PRNet. Finally, we demonstrated the generalization capability of the proposed method from the simulation testing scenarios to real-world scenarios.
A. Implementation Details
We built a simulation environment in Gazebo, including a UR10 robotic arm equipped with a robotiq85 gripper and a Kinect RGB-D camera fixed on the table. We trained our RL method using stochastic gradient descent (SGD) with a fixed learning rate of 0.0001, momentum of 0.95, and weight decay of 2E–5 on an Ubuntu 16.04 server with two NVIDIA GTX 1080Ti GPUs. We applied DQN [33] with a prioritized experience replay [42] to train our Action-PNet and Action-GNet for 20 000 steps and 8000 steps, respectively. It took about 15 s for each step. And we updated the parameters of the target network in every 200 steps.ε-greedy [31] was used as the action selecting policy, whereεwas initialized as 0.4 and then annealed to 0.1 during training. The future discount factorγwas set as 0.5. For PR-Net, we used the VGG-16 network pretrained on ImageNet [35] as the backbone and trained it for 60 epochs using SGD with a fixed learning rate of 0.0001, momentum of 0.95, and weight decay of 2E–5. The batch size was set to 32. Horizontal and vertical flipping was used for data augmentation during training.
B. Dataset and Evaluation Metrics
We adopted the established dataset CHID described in Section III-D as the benchmark. Specifically, we used the training set including the easy scenarios and difficult scenarios to train the proposed model and tested it on the simulation testing scenarios as well as the real-world scenarios. For each number of objects (n∈[3,8]), we conducted 25 tests,respectively. The performances of different methods were evaluated in terms of the following metrics: 1) success rate of separation (pushing times ≤2×n), wherenrepresents the number of objects to be separated. If the pushing times in one test exceed 2×n, this test is regarded as failure; 2) pushing efficiency metric, i.e., the mean and standard variance of pushing times in 25 tests at different settings (n∈[3,8]). The smaller this mean value is, the more effective the current method is. Besides, a smaller variance indicates a more robust pushing strategy; and 3) success rate of grasping, which is defined as the average ratio between the number of objects and the total grasping times in 25 tests at different settings.
C. Pushing and Grasping Results in Simulation Scenarios
First, we compared our RL-based pushing method with the supervised learning method (named as Non-RL pushing),which has the same structure with the Action-PNet but is trained in a supervised manner, where the binary classification labels are predicted by PR-Net. For each number of objects(n∈[3,8]) , we conducted 25 scenarios, i.e., randomly selected the corresponding number of objects from the testing set and tightly stacked them together for each scenario. The success rate of separation and pushing efficiency metrics are reported in Table I. Compared with the Non-RL pushing method, the performance of our method is much better. As the number of objects increases, the difficulty of the pushing task becomes higher, and the advantage of our method becomes more and more obvious. Besides, the less pushing times demonstrate that the proposed RL based pushing method using long-term future rewards separates objects more effectively while the smaller variance shows its robustness. Although onlyn∈[3,6]objects were used during training, the proposed method still obtained high performance for pushing more tightly stacked objects ( e.g.,n∈[7,8]) during testing, which demonstrates the generalization capability of our method. In addition, we replaced the proposed PR-Net reward with the local rewardfunction of a recently proposed RL-based collaborative pushing and grasping method [16] and constructed comparative experiments. As shown in Table I, the proposed method can obtain significant advantages over local reward RL pushing [16]. It is because that only evaluating the pushing effectiveness in a local area may result in non-optimal pushing action from a global perspective, e.g., separating a small group of objects while some of them may be closer to the remaining objects, which well demonstrates the superior performance of our designed PR-Net reward.
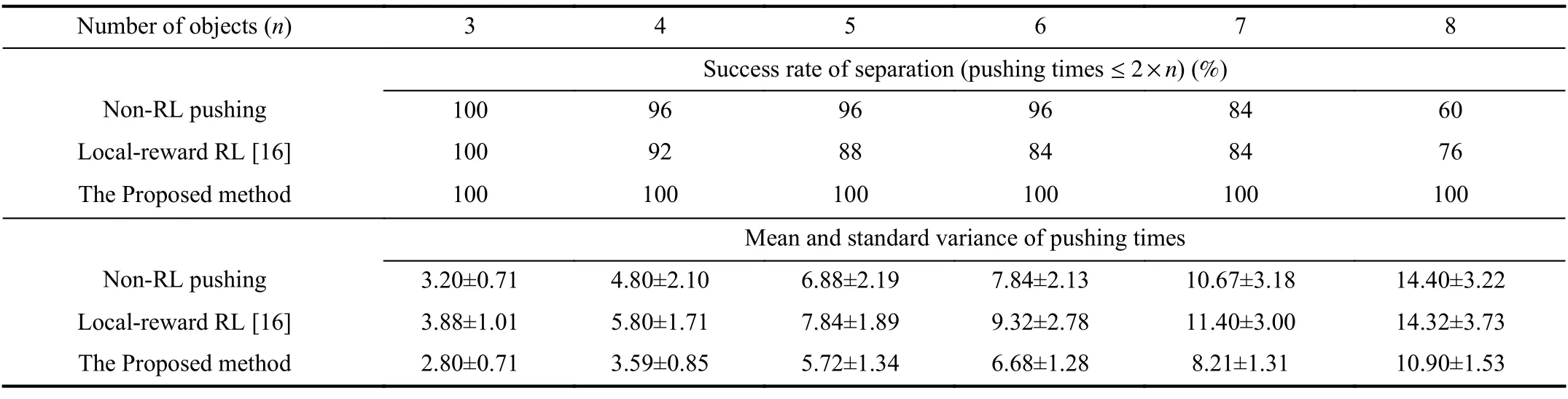
TABLE I COMPARISON WITH OTHER PUSHING METHODS

TABLE II COMPARISON WITH THE GRASPING-ONLY METHOD
Then, we conducted experiments to compare grasping-only method and the proposed collaborative pushing and grasping method for grasping tightly stacked objects. The graspingonly method has the same structure with our Action-GNet and was used for directly grasping objects without pushing. As shown in Table II, the success rate of grasping of the grasping-only method is very low. It is because directly grasping the tightly stacked objects will cause collisions and result in failures. By contrast, the proposed method can achieve a much higher success rate, which demonstrates the superiority of our collaborative pushing and grasping framework over the grasping-only one. The simulation testing environment is presented in Fig. 8.
Fig. 8. Illustration of the simulation testing environment.
D. Ablation Study
Ablation studies of the components of the proposed method were performed to validate their effectiveness. First,experiments were conducted to verify the performance of the pushing reward network PR-Net and the PolicyNMS in the pushing task. Specifically, we conducted experiments for the following three models.
Model 1:the push reward without PR-Net, i.e., only getting the final reward when the separation is done, and Action-PNet without PolicyNMS.
Model 2:the push reward using PR-Net and Action-PNet without PolicyNMS.
Model 3:the push reward using PR-Net and Action-PNet using PolicyNMS. The training results of these three models for the setting of 6 objects are plotted in Fig. 9. It can be seen that the proposed PR-Net can help the method achieve better pushing efficiency by adequately evaluating the rationality of pushing actions and the proposed PolicyNMS contributes significantly to the faster learning speed by suppressing unreasonable pushing actions.
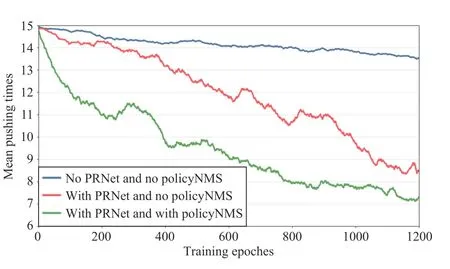
Fig. 9. Ablation study of PR-Net and PolicyNMS for pushing.
Then, to evaluate the effectiveness of the proposed grasping angle reward function defined in (9) and PolicyNMS in the grasping task, we conducted experiments for the following three models.
Model 1:the grasping reward without the angle constraint defined in (9) and the Action-GNet without PolicyNMS.
Model 2:the grasping reward with the angle constraint and the Action-GNet without PolicyNMS.
Model 3:the grasp reward with the angle constraint and the Action-GNet with PolicyNMS. The training results of these three models for the setting of 6 objects are plotted in Fig. 10.It can be seen that PolicyNMS and the grasping angle reward bring a higher success rate of grasping. Specifically, the grasping angle constraint reward benefits the final performance while contributing less to the learning speed. By contrast, PolicyNMS has a larger impact on the learning speed, which helps the agent learn much faster by suppressing unreasonable grasping actions to avoid failure grasping and collisions.
E. Evaluation Results in Real-world Scenarios
We evaluated the proposed method in real-world scenarios.The testing suit consists of a UR10 robotic arm with a DH-95 gripper, and a Realsense RGB-D camera fixed on the desktop as shown in Fig. 2. We used the network trained in the simulation training scenarios directly to the real-world testing scenarios. Specifically, we randomly selectedn∈[3,8] realworld household objects and tightly stacked them together. In all the real-world tests, our method successfully separated all the objects under the push times limitation, i.e., ≤2×n. An visual demo of pushing and grasping in the real-world environment is presented in Fig. 11. As shown in the first column of Table III, our method can achieve a robust and efficient pushing performance in the real-world tests, which are comparable to the results in the simulation tests as shown in Table I. Besides, the high success rates of grasping are also comparable to the results in Table II. The results validate the good generalization capability of the proposed method from simulation environment to real-world environment as well as from specific objects to unknown objects. Furthermore, we also prepared much more difficult testing scenarios, wheren∈[3,8] identical objects are tightly stacked together as shown in Fig. 12. These tests further demonstrate the excellent generalization capability and adaptability of our method,which is important for practical applications. A video demo of the testings in the real-world environment is also provided2https://github.com/nizhihao/Collaborative-Pushing-Grasping.
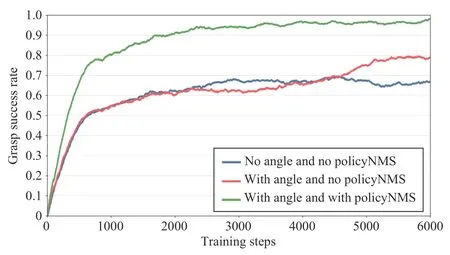
Fig. 10. Ablation study of the proposed grasping angle reward and PolicyNMS for grasping.
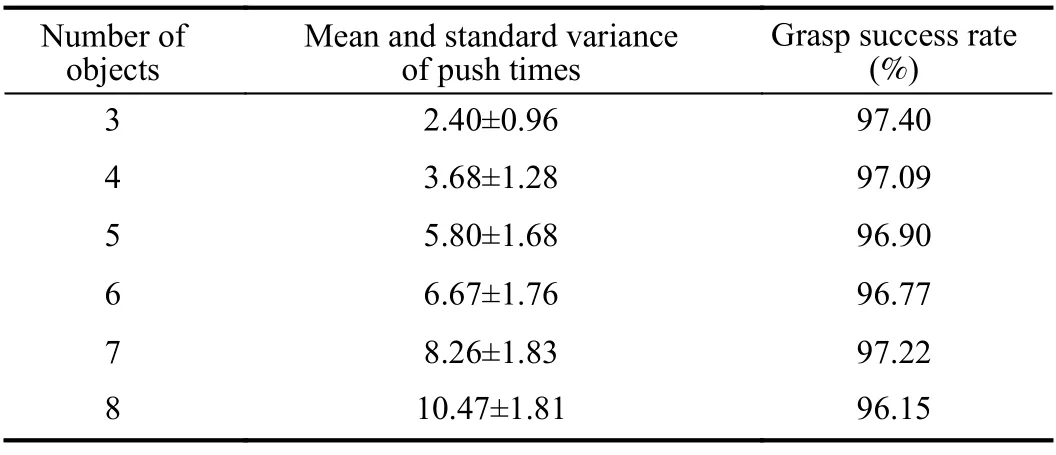
TABLE III RESULTS OF OUR METHOD IN REAL-WORLD ENVIRONMENT

Fig. 11. Testing for random objects stacked tightly in real-world environment.

Fig. 12. Testing for identical objects stacked tightly in real-world environment.
V. CONCLUSIONS
In the paper, we propose a novel deep Q-learning method for collaboratively pushing and grasping tightly stacked objects. Specifically, a novel efficient non-maximum suppression policy is designed, which can help accelerate the learning speed by suppressing unreasonable actions to avoid bad consequences. For the pushing task, an end-to-end datadriven pushing reward network is designed to assess the state of aggregation or separation after different pushing actions from a global perspective. For the grasping task, an efficient grasping reward function with angel constraint is defined to help optimize the angle of grasping actions. They contribute to developing an efficient and robust pushing strategy as well as the high success rates of pushing and grasping. Moreover, we establish the common household item dataset containing various objects in different colors, shapes, textures, and sizes,forming lots of easy to difficult training scenarios.Experimental results demonstrate the superiority of the proposed method over the non-RL pushing method and directly grasping method for this challenging task, as well as its fast learning speed, good generalization capability and robustness. One of the limitation of the method is that there is no constraint of the pushing distance, which may push some objects out of the boundary. In the future work, we can explore an effective constraint to deal with this limitation.
 IEEE/CAA Journal of Automatica Sinica2022年1期
IEEE/CAA Journal of Automatica Sinica2022年1期
- IEEE/CAA Journal of Automatica Sinica的其它文章
- A Lane-Level Road Marking Map Using a Monocular Camera
- Adaptive Decentralized Asymptotic Tracking Control for Large-Scale Nonlinear Systems With Unknown Strong Interconnections
- A Distributed Framework for Large-scale Protein-protein Interaction Data Analysis and Prediction Using MapReduce
- Monocular Visual-Inertial and Robotic-Arm Calibration in a Unifying Framework
- Price-Based Residential Demand Response Management in Smart Grids: A Reinforcement Learning-Based Approach
- Human-in-the-Loop Consensus Control for Nonlinear Multi-Agent Systems With Actuator Faults