
基于聚类划分与双向LSTM 网络的台区线损率计算*
2022-10-22 03:37鹏白玉岭王林梅陈一鸣高挺孙
电子器件 2022年4期
王 鹏白玉岭王林梅陈一鸣高 挺孙 杰
(1.国网台州供电公司,浙江 台州 318000;2.北京中恒博瑞数字电力科技有限公司,北京 100085)
目前电网企业台区线损管理普遍采用一刀切的方式,通过人工设置台区合理线损率开展日常管理工作,没有考虑各台区在导线选型、供电半径、负荷分布、用户类别、负载水平、用电季节、运行年限等方面的差异,缺乏科学依据,在指导具体节能降耗工作实施方面缺乏实际参考意义。鉴于电网企业对台区线损管理的要求逐年提高,确定更加合理、精确的理论线损率计算方法迫在眉睫。
传统的台区理论线损率计算方法有潮流计算法、负荷曲线法、节点电压法等[1-3]。由于台区分支线路复杂,节点多,量测点少,台账数据不完整,线损率计算困难。近年来,人工智能算法逐渐应用于配电网线损率计算。文献[4]提出了基于支持向量机回归的计算方法,文献[5]研究了基于改进核心向量机的配电网线损预测方法,文献[6]提出了一种基于径向基函数神经网络和改进的自适应二次变异差分进化算法的线损分析方法。但上述文献的应用领域均为10 kV 线路领域,在台区线损率计算与分析方面的研究成果相对较少。文献[7]提出了一种基于数据挖掘技术的台区线损预测模型,利用K 均值聚类将线损数据按照台区特征分类,并对每一类数据采用线性回归进行预测;文献[8]提出一种改进K 均值聚类和BP神经网络的计算模型。上述文献研究重点虽然集中在台区线损率计算分析领域,但是还存在一些不足:(1)影响因素考虑得不够全面,基本上只考虑供电量、配电变压器总容量、线路总长度等,对低压台区自身的属性特征涉及较少,同时计算过程中线路总长度、供电半径等数据难以直接得到;(2)对设备(资产)运维精益管理系统、SG186 营销业务应用系统、用电信息采集系统等现有数据的挖掘力度不够,造成大量数据资源闲置,并没有得到高效利用。本文提出了一种基于聚类划分与双向LSTM 网络的台区线损率计算方法,基于台区静态参数特征采用K-medoids 聚类算法将台区划分为不同类别;然后对于每一类台区,基于台区静态参数特征和运行参数特征采用双向LSTM网络构建台区线损率计算模型,提高了线损率计算的精准度。以某公司28 167 个台区样本数据进行仿真计算,结果验证了本文所提算法准确性明显优于支持向量机、回归树、线性回归等算法。
1 台区线损率计算整体流程
由于台区参数特征的不同,线损率分布规律有所差异。因此,需要根据台区参数特征,将台区划分为不同类别,相同类别台区线损率规律大致相同;然后在每一类台区中分别研究台区线损率的波动规律,使得计算模型更加精准。基于聚类划分与双向LSTM 网络的台区线损率计算方法整体框架如图1所示,具体包括:首先选取影响线损率的台区静态参数特征,例如运行年限、城农网标识,基于静态参数特征采用聚类算法将台区划分为不同类别;接着,选择影响线损率的台区运行参数特征,例如负载率、三相不平衡度,基于台区静态参数特征和运行参数特征,采用双向LSTM 网络构建台区线损率计算模型,并评价模型的精准度;最后,基于该模型计算台区线损率理论值。

图1 台区线损率计算整体流程
在台区线损率计算模型的训练阶段,台区样本集合需要剔除线损率异常台区。异常台区的日、月线损数据波动大,失真严重,增加了非主要因素的干扰,不能真实反映实际线损率水平,增加了分析台区线损影响因素及其影响大小的难度。
2 基于K-medoids 聚类的台区类别划分
通常情况下,参数特征类似的台区线损率波动规律也相似。在台区类别划分阶段,需要分析台区线损率影响因素,选择影响程度大的参数特征;然后基于参数特征采用合适的聚类算法将海量台区划分为不同类别。
2.1 台区静态参数特征选择
在台区类别聚类划分过程中,台区特征参数选择至关重要,既要能反映线损率波动规律又要考虑数据获取的难易程度。综合分析电网企业设备(资产)运维精益管理系统、SG186 营销业务应用系统现有可用数据,用于聚类划分的台区特征参数如下:
(1)台区运行年限。随着运行时间增长,当初台区设计实施标准已经很难够满足电力负荷增长的需求。同时由于某些台区长期处于过负荷的状态、线路老化失修严重,其线损相对较大,容易出现线损率异常现象。
(2)城农网标识。城乡经济发展二元结构的存在,城乡居民用电习惯的不同、都会导致线损率大小的不同。同时,城乡台区供电半径的不同、配网技术的差别、线路规划改建的不同也是影响线损率的重要因素。
(3)居民容量占比。居民用户和非居民用户两类用户的用电特点有很大差异,对台区线损的影响也不同。居民容量占比代表居民用户对台区线损率起主导作用的大小。
(4)居民户均容量。在居民型台区中,居民户均容量代表台区用户的用电水平,不同用电水平的台区线损率值可能会有差异。
(5)台区用户数量。根据台区内总用户数将台区划分为小规模台区、中规模台区、大规模台区。台区用户数是影响台区线损率的重要因素[9]。
2.2 基于K-medoids 算法的台区类别划分
由于现有档案资料未标记台区的类别,台区类别划分是一个典型的无监督聚类问题。K-means 算法和K-medoids 算法是两种最常用基于划分的聚类方法。其中,K-means 算法由于采用簇中对象的均值作为簇中心,当遇到离群点对象时会严重扭曲簇中心,影响了其他对象到簇的分配,因而K-means 算法对噪声数据比较敏感。与K-means 算法相比,K-medoids算法选取实际对象作为簇中心对象,剩余对象分配到与其最相似的中心对象所在的簇,从而降低了噪声数据的影响[10]。本文采用K-medoids 算法开展台区类别的聚类划分。在聚类过程中,K-medoids 算法采用聚类质量评价函数进行对象迭代划分,函数定义如下:
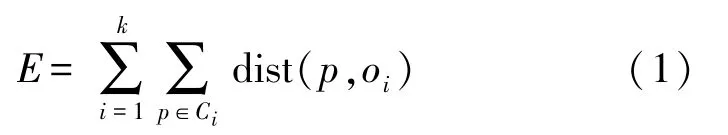
式中:E是参加聚类的所有对象p与其所属簇的中心对象oi的绝对误差之和。K-medoids 算法通过最小化E把所有对象分配至k个簇。
K-medoids 算法具体划分流程如下:
输入:包含n个对象的数据集D和簇数k
输出:k个簇的集合
(1)在数据对象集合D中随机选择k个对象作为每个簇初始中心对象;
(2)将剩余对象分配至与其最近的中心对象所代表的簇中;
(3)选取一个未选取过的中心对象oi;
(4)选取一个未选取过的非中心对象oj;如果用oj替换oi聚类质量评价函数变小,则用oj替换oi并形成新k个中心对象的聚类集合;
(5)重复步骤(4)直至所有非中心对象都被选取过;
(6)重复步骤(3)直至所有中心对象都被选取过;
采用K-medoids 算法开展台区类别聚类划分时,需要提前确定台区类别数量。由于一开始无法确定合适的台区类别数量,本文设置不同台区类别数量开展台区聚类划分,然后评估不同类别数量聚类划分的聚类质量,最终选择聚类质量最好的台区类别划分。轮廓系数是一种常用的聚类质量评价方法,它通过计算不同簇对象的分离情况和相同簇对象的紧凑情况来评估聚类实际效果,具体定义如下:
对于包含n个对象的数据集D,假设D被划分为k个簇C1,…,Ck。对于每个对象o∈D,计算o与相同簇其他对象之间的平均距离a(o),o到不同簇对象的最小平均距离b(o)。假设o∈Ci且1≤i≤k,则
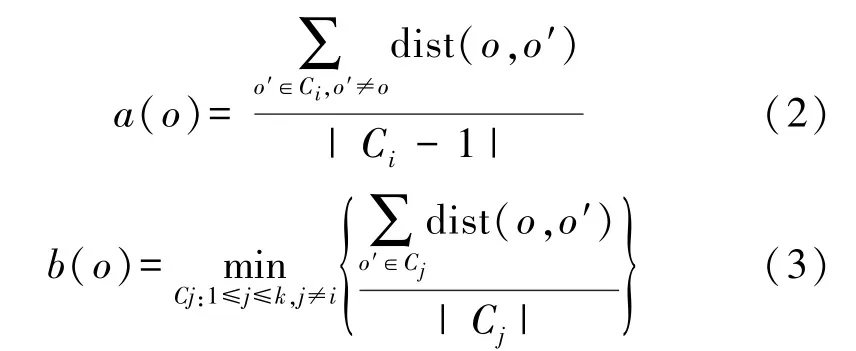
式中:dist 为距离函数,dist(o,o′)指对象之间的距离。

a(o)越小对象o与所属簇越紧凑,b(o)越大对象o所属簇越分离。当轮廓系数值s(o)接近1 时,对象o与所属簇是紧凑的,同时对象o与其他簇是远离的。对象o的轮廓系数只能反映对象o的聚类效果,为了度量整个数据集的聚类效果,采用数据集中所有对象的轮廓系数的均值。
3 基于双向LSTM 网络的台区线损率计算
在台区类别划分后,除了台区运行年限、居民容量占比、居民户均容量、台区用户数量、供电半径等台区静态特征参数外,还需要选择台区运行状态参数。本文选取台区运行状态参数主要包括售电量、负载率、三相不平衡度、功率因数、环境温度。然后基于台区静态参数特征和运行参数特征采用回归算法模型构建台区线损率计算模型,开展台区理论线损率计算。
3.1 LSTM 单元
LSTM 网络是一种常用的门控循环神经网络。LSTM 引入了3 个门,即输入门、遗忘门、输出门,以及与隐藏状态形状相同的记忆细胞,从而记录额外的信息。LSTM 单元结构如下图所示:

图2 LSTM 单元结构
(1)输入门、遗忘门和输出门
长短期记忆的门的输入均为当前时间步输入Xt与上一时间步的隐藏状态Ht-1,输出由值域为[0,1]的sigmoid 激活函数的全连接层计算得到。具体来说,假设隐藏单元个数为h,给定时间步t的小批量输入Xt∈Rn×d(样本数为n,输入个数为d)和上一时间步隐藏状态Ht-1∈Rn×h。时间步t的输入门It∈Rn×h、遗忘门Ft∈Rn×h和输出门Ot∈Rn×h分别计算如下:
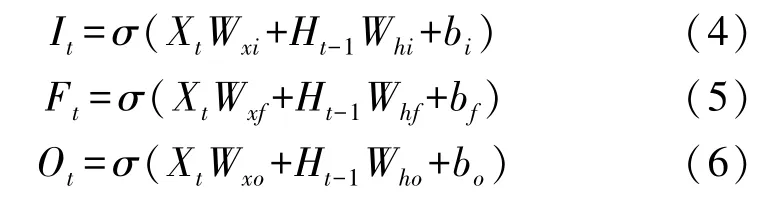
式中:Wxi,Wxf,Wxo∈Rd×h,Whi,Whf,Who∈Rh×h是权重参数,bi,bf,bo是偏差参数。
(2)候选记忆细胞、记忆细胞
时间步t的候选记忆细胞∈Rn×h的计算为:

式中:Wxc∈Rd×h和Whc∈Rh×h是权重参数,bc∈Rl×h是偏重参数,tanh 函数是值域[-1,1]的激活函数。
当前时间步记忆细胞的计算组合了上一时间步记忆细胞和当前时间步候选记忆细胞的信息,并通过遗忘门和输入门来控制信息的流动:

式中:⊙为逻辑运算器,表示按元素乘法。
遗忘门控制上一个时间步的记忆细胞中的信息能否流入到当前时间步,而输入门则控制当前时间步的输入通过候选记忆细胞流入当前时间步的记忆细胞。如果遗忘门一直近似1 且输入门一直近似0,过去的记忆细胞将一直通过时间保存并传递至当前时间步。
(4)隐藏状态
在记忆细胞基础上,可以通过输出门来控制从记忆细胞到隐藏状态Ht∈Rn×h的信息流动:

式中:tanh 函数确保隐藏状态元素在-1 到1 之间。需要注意的是,当输出门近似1 时,记忆细胞信息将传递到隐藏状态供输出层使用;当输出门近似0 时,记忆细胞信息志自己保留[11-13]。
3.2 双向LSTM 网络
基于时间序列的预测,当前时间点临近过去和未来的序列信息都可用于评估当前时刻,且不依赖预定义参数。然而LSTM 神经网络只能使用某一时刻之前的输入信息来预测结果。双向LSTM 则基于整个时间序列对输出进行预测,首先将隐藏层神经元分成正时间方向和负时间方向两个部分,具有两个独立的隐藏层,然后前馈到相同的输出层,同时包括过去和未来的序列信息。双向LSTM 结构见图3。

图3 双向LSTM 网络结构
第1 层LSTM 计算当前时间点顺序信息,第2 层LSTM 反向读取相同的序列,添加逆序信息,每层LSTM 具有不同参数。双向LSTM 网络弥补了LSTM缺乏下文语义信息的不足[14-15]。
4 实例分析
为了验证本文所提方法的有效性,以某市公司线损率稳定的公用变压器台区数据为例(共28 167个台区)进行线损率的计算和分析。选择台区样本数据时重点剔除以下几种不合格台区:(1)采集未全覆盖;(2)台区下有特殊用户,如光伏发电;(3)发生业务变更,如户变关系调整;(4)线损率为负值或超过10%。确定台区样本集合后,从一体化电量与线损管理系统、设备(资产)运维精益管理系统、SG186 营销业务应用系统、用电信息采集系统等抽取台区静态特征参数和运行特征参数。
在台区类别聚类划分阶段采用K-medoids 算法,样本输入属性包括:运行年限、城农网标识、居民容量占比、居民户均容量、台区用户数量。设定聚类簇数为2 至20,计算每种簇参数情况下聚类结果的轮廓系数,各种聚类簇数对应的轮廓系数如表1 所示。
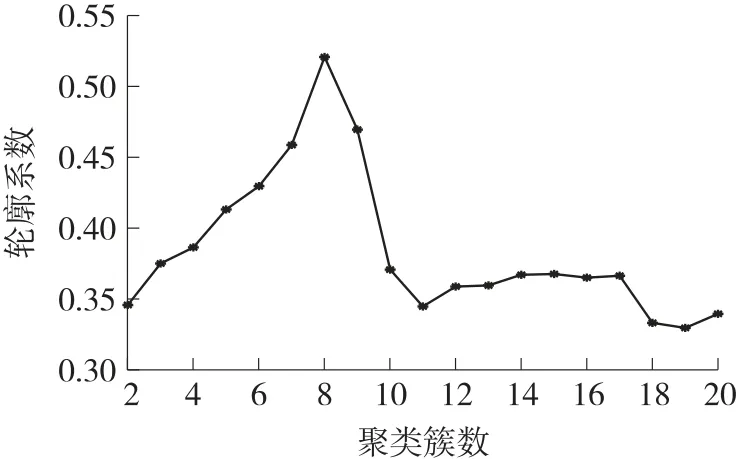
图4 不同聚类簇数的轮廓系数

表1 各聚类中心对象的属性值
通过对轮廓系数的分析,可知在聚类簇数为9时,台区聚类划分结果质量最好,将其作为台区类别划分的最终结果。部分聚类簇的中心对象如下表所示,可以看出,聚类1 是城网运行时间较短台区,同时该类台区用户数量和户均容量都较大;聚类2 和聚类3 也是城网台区,但是运行时间和户均容量都和聚类1 有较大差别;聚类4 是农网老旧台区,用户数量大户均容量小。
各个聚类簇的台区数量如图5 所示:
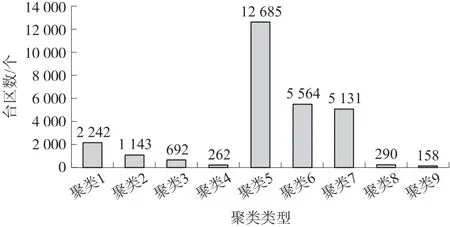
图5 各个聚类的台区数量
在台区类别划分基础上,针对每类台区分别基于双向LSTM 网络构建台区线损率计算模型,模型输入属性包括台区运行年限、居民容量占比、居民户均容量、台区用户数量、日售电量、日负载率、日均三相不平衡度、日均功率因数、日均气温。在台区线损率计算模型训练阶段,最重要的参数是双向LSTM网络层数和每层隐藏单元的数量。层数越多、隐藏单元数量越多,模型非线性拟合能力越强,但模型复杂度也会大幅增加。在确定LSTM 模型的层数及其隐藏单元数量时,首先搜索单层模型的最佳隐藏单元数量并将其固定;第2 步,增加一层隐藏层,在第一步基础上搜索该层最佳隐藏单元数;以此类推,预测误差最小时所对应的层数及隐藏单元数量为LSTM 模型最终参数。不同学习参数的模型均方误差如图6 所示,可以看出模型层数为2,隐藏单元数量分别为200,150 时模型效果最佳,将其双向LSTM模型作为最终的台区线损率计算模型。

图6 不同模型参数下的预测结果
为进一步验证分析本文模型的精确性,将线性回归模型、支持向量机回归模型、回归树模型与本文所提出的双向LSTM 网络的预测结果进行对比分析,各种模型计算结果如图7 所示,容易看出,本文方法计算的台区线损率与真实线损率最接近。

图7 各种算法的台区线损率计算结果对比
同时,采用十折交叉验证比较上述各种模型计算结果的均方误差(Mean Squared Error,MSE)、均方根误差(Root Mean Squared Error,RMSE)、平均绝对误差(Mean Absolute Error,MAE)及R-Squared,结果如表2 所示。可以看出,本文提出方法各种指标都是最优的。

表2 各种算法的台区线损率计算模型对比
5 结论
在低压台区中,由于分支线路复杂,节点多,量测点少,台账数据不全,线损率计算困难。提出了一种基于台区聚类划分与双向LSTM 网络的台区线损率计算方法。基于城农网、变压器容量、运行年限等影响线损率的静态属性特征,采用K-medoids 聚类算法将海量台区划分为不同类别;然后对于每一类台区,基于台区静态参数特征和运行参数特征采用双向LSTM 网络构建台区线损率计算模型,提高了线损率计算的精准度。对某公司台区样本数据进行仿真计算,结果验证了本文所提算法准确性明显优于支持向量机、回归树、线性回归等模型的准确性。
猜你喜欢
出版人(2022年11期)2022-11-15
电气技术(2022年2期)2022-02-24
今日农业(2021年19期)2021-11-27
数学小灵通(1-2年级)(2021年10期)2021-11-05
中国电气工程学报(2019年25期)2019-09-10
人大建设(2018年7期)2018-09-19
电子制作(2017年2期)2017-05-17
电子制作(2017年2期)2017-05-17
电子制作(2016年1期)2016-11-07
电子制作(2016年1期)2016-11-07
