
基于卷积神经网络的中草药推荐系统*
2022-10-15 04:26陈灿宇付阿敏李国伟余兆钗李佐勇
世界科学技术-中医药现代化 2022年6期
陈灿宇,付阿敏,李国伟,余兆钗,3**,李佐勇,3**
(1.闽江学院计算机与控制工程学院 福州 350121;2.山东科技大学电子信息工程学院 青岛 266000;3.福建省信息处理与智能控制重点实验室(闽江学院) 福州 350121)
1 引言
随着中国经济的跨越式发展,中华文化在世界范围内的影响力逐渐增大,作为中华文化代表的中医文化也越来越受到人们的重视[1]。习近平同志明确提出“着力推动中医药振兴发展”[2],党中央高度重视对中医药的研究,中医发展上升为国家策略。中医处方是针对病人症状为进行疾病治疗而开出的一组中草药集合,处方中的症状集合称为“症状组”,草药集合称为“处方组”。当前中医领域积累了许多真实有效的诊疗数据,文献[3]指出,现在的处方记录已经超过10万条。基于中医诊疗数据,建立模型挖掘症状之间的关系,预测患者的用药,成为当前中医辅助诊疗智能化的研究创新点,这给中药方剂的推荐带来了挑战。
运用计算机辅助诊疗技术进行中草药推荐,实际上是一种文本多标签分类问题,当前处方预测算法大多基于机器学习和深度学习模型[4]。比如,L.Yao[3]等人建立了主题模型,将中医知识归纳入模型,描述中医理论中处方生成的过程,进行中草药推荐,但准确率有待进一步提高。王斌[5]等人基于多标签k近邻算法设计了智能推荐模型,协助医生对患者病症证的关系判断,并智能推送适合病症的中草药和治疗方案。黄友[6]等人初步研究了五个推荐处方在治疗COVID-19全证型阶段的共性作用机制,为用中医药防治COVID-19提供了理论依据与参考,但COVID-19相关基因数据库不够完整。郭永坤等[7]引入人工神经网络拟合中药和方剂之间的非线性关系,量子化处理中医数据,设计了中药方剂预测系统。学者们不断尝试运用深度学习算法模拟医生诊疗过程,为医生在临床中开具中草药处方提供了参考方案。但是在提取病人症状特征方面还存在欠缺,没有明确的优良方法推荐出更准确的治疗处方。故本文基于更好的特征提取思想,提出了基于卷积神经网络的推荐系统。
卷积神经网络(Convolutional Neural Network,CNN)是一种常见的文本分类模型,是由卷积层、池化层、全连接层组成的人工神经网络结构[8]。相对于传统的多层感知神经网络,其卷积层具有局部链接、权值共享以及池化操作既能够有效地提取特征,又大幅度地简化了网络的复杂度[9],因此我们选择使用卷积神经网络模型拟合临床治疗和研究处方中症状和中草药之间的内在联系,提升预测准确率,增加辅助诊疗的实用性,为医生和患者推荐更加可靠的诊疗方案具有深远意义。
本文的主要贡献如下:①基于中医诊疗逻辑分析症状和相应治疗草药之间的联系,使用卷积神经网络算法建立了中草药推荐系统;②提供一种新的中医辅助诊疗方法,这对中医诊疗在人工智能方向的研究非常具有参考价值。
2 网络设计
2.1 数据来源
在本研究中,我们根据《中医临床必读丛书:伤寒论》[10]的相关内容,引用了赵文[11]构建的《伤寒论》诊疗数据集,提取了共计358组中医症状和中草药信息。再根据中医常用规则,对伤寒论的诊疗记录中的症状和中药处方信息进行汇总整理,统计数据集的特征和标签,本研究采用的《伤寒论》诊疗记数据集共计症状158种和中草药77种,具体的数据集信息如表1所示。

表1 数据集数据
我们收集的伤寒论数据集,症状和中草药信息有简短和维数多的特征,对数据进行multi-hot编码的方式处理。例如症状组,首先将所有的单个症状做独有的编号,按照其所带的编码值域,定义为1,其他值域为0(表2)。症状组“咽喉疼痛、呕吐、泄泻、脉紧”,编码后被表示为“11110000…”;草药组“人参、干姜、炙甘草、白术”,编码后表示为“1100000…011”(表3)。

表2 编码后的症状组数据表示

表3 编码后的中草药数据表示
2.2 算法设计
相比传统的深度学习模型,卷积神经网络通过感受野、权重共享和降采样三种方法降低了网络的复杂性[12]。它通常由输入层、卷积层、池化层、全连接层和输出层几个部分组成,一次训练过程,可以分为前向传播、损失计算和反向传播三个步骤。
2.2.1 前向传播
网络的输入可以定义为X=(x1,x2,…,xn),我们将输入症状的158位编码具体值当作卷积层的输入,通过12个卷积核进行卷积运算将其转化为12通道的一列78行的矩阵。我们将a定义为卷积层输出的神经元值,W为权重,b为偏置单元,m为卷积核的维度,则卷积层的神经元操作可以定义为如下公式(1):

其中σ为非线性激活函数,即ReLU函数,它可以使网络具有更好的拟合和泛化能力。
卷积层后面再用三个全连接层整合和归纳。我们设k为输入神经元维度,则第L+1个全连接层输出神经元值aL+1定义为公式:
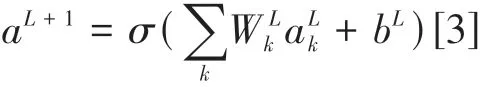
P是输出中草药的正确的概率值,定义为公式:

其中f函数用于输出预测概率,使最终输出归一化,被定义为公式:

2.2.2 损失计算
由于我们最终需要得到一组中药,即我们的模型需要输出多个标签,这属于多标签分类的范畴。预测输出值越接近真实样本标签0,损失函数L越小;预测函数越接近1,L越大。函数的变化趋势也完全符合实际需要的情况。因此我们在前向传播后,使用多标签交叉熵损失函数计算损失值L,如公式:

其中,H代表输出层的神经元数,即中药的种类数。th∈{0,1}和yh(0≤yh≤1)分别代表着实际标签和模型的预测值。
2.2.3 反向传播
在本算法反向传播过程中,定义一个δ误差表示损失函数对于当前层未激活输出zL的导数。使用δL(x)表示卷积层的第L层中坐标为x处的δ误差,假设我们已经知道L+1层的δ误差,根据链式求导法则可以得出δL(x)计算方式为公式:

根据第L层的δ误差,我们就可以等到该层的对权重和偏置的导数:
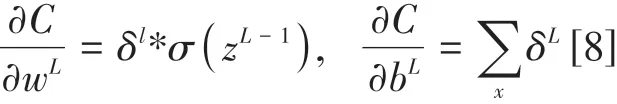
对于网络中每一个参数的更新,采用以下公式进行更新:
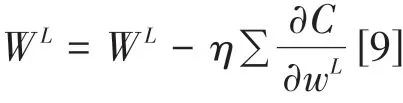
其中,η为神经网络的学习率。对于全连接层的反向传播可以相似的得出以下公式:
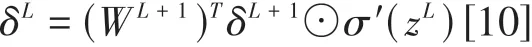
全连接层权重更新公式与卷积层相同[13],利用前向传播和网络自身的参数WL和bL对输入数据进行预测,接着将预测值和真实标签代入损失函数计算出实际输出值th与网络预测输出值yh之间的损失,最后将损失值反向传播回模型从而更新网络参数,不断提升网络预测出正确中草药的性能。
2.3 网络结构
依据中医诊疗逻辑原理和卷积神经网络的基本结构,本文将样本的症状和中草药处方分别作为网络输入和输出,设计了一个用于中草药处方推荐的神经网络模型(CNN-based Herbal Prescription,CNN-HP),其结构如图1所示,由一个卷积层和三个全连接层组成。将病症信息作为输入层,利用卷积层来实现对病症的特征提取,经过输出函数获得非线性表达能力,拟合中医诊疗过程。
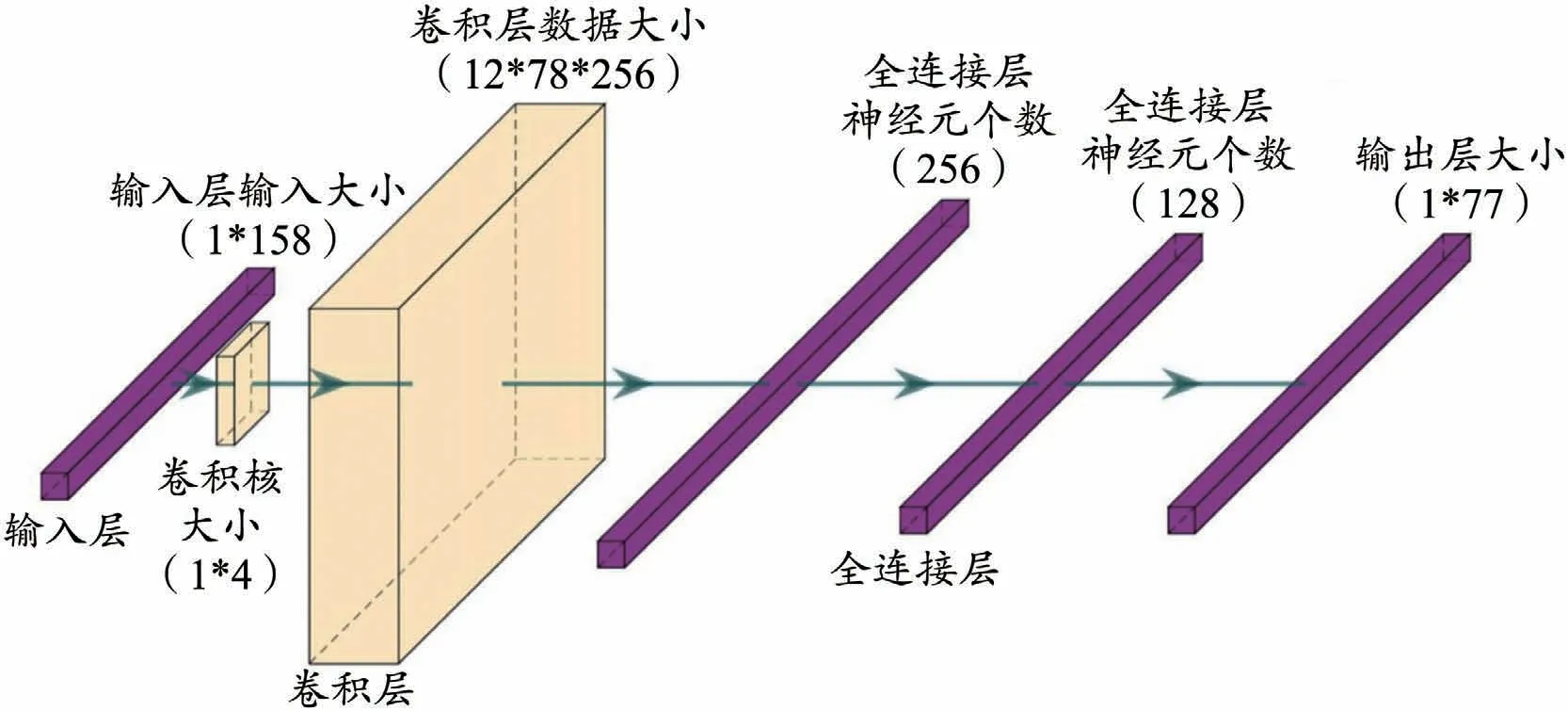
图1 卷积神经网络模型图
对于神经网络模型训练,首先由于本研究《寒伤论》诊疗数据集中共有158种症状以及77种中草药,因此我们决定设置网络输入层的特征维度是158,输出层维度是77,以更好的结合数据集数据。其次由于考虑到网络是对非线性的数据进行处理我们特地选取了ReLU(线性整流函数Rectified Linear Unit)作为每一层的激活函数,以使得网络对数据特征的提取更为精确,且最后一层网络由于要输出预测结果的概率因此需要特殊处理,将其设为sigmoid函数以便于将最后一层的高度抽象数据转为概率的形式呈现(表4)。
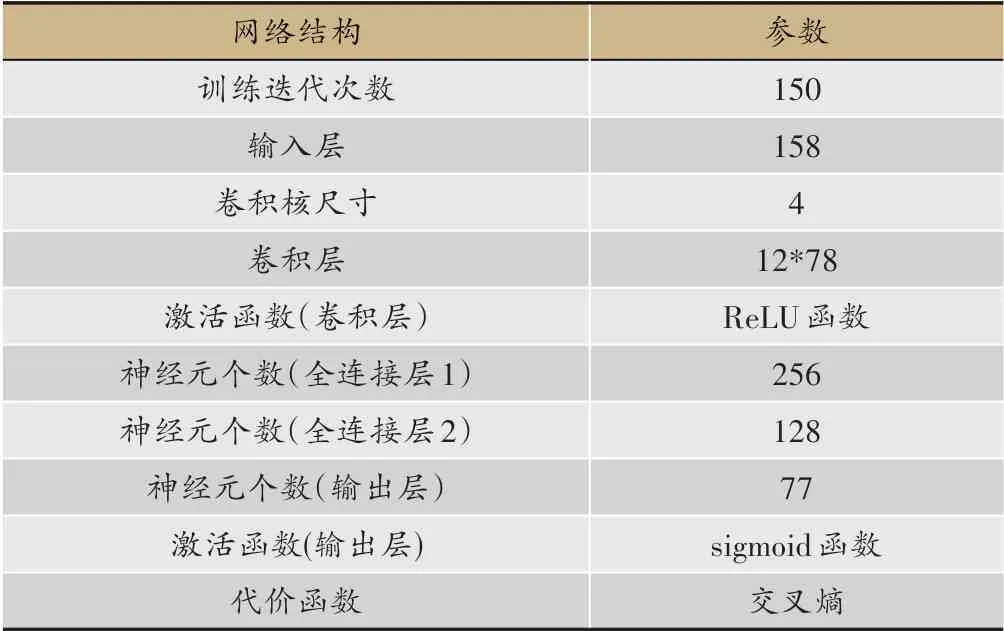
表4 网络结构的参数设置
对于网络模型中细节参数的设计,考虑到数据集的规模不大,且数据特征过于稀疏,太大的网络结构可能容易发生过拟合现象而小网络对数据特征提取的可能不够完整,所以经过一些实验与讨论我们决定卷积层的通道数定为12,再通过卷积层之间的计算公式[14]:
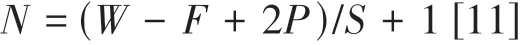
得到卷积后输出的大小为78,且最后的两层全连接层维度我们将之设置为256和128。而对于损失函数,由于本次实验使用的sigmoid函数为网络模型最后一层的激活函数,如果使用平方差损失函数的话会导致误差比较小时梯度过小使得网络无法进一步进行训练,因此我们采用交叉熵函数作为我们网络的损失函数完美的避免了这类问题的发生。
卷积层中的权重以及偏置,和全连接前馈网络类似,也可以通过误差反向传播算法来进行参数学习。神经网络层与层之间的传播过程,对应着从症状特征提取,到最后推荐出中草药的推理过程,网络的训练和测试不断地明确了这个映射关系。
3 实验及分析
为了更好的测试CNN-HP网络在伤寒论数据集上的性能,本实验分为三个部分:第一,不同K值比对(K值为最后输出的数据中概率最高的前K项),得出各评价指标进行对照。第二,相对数据均衡的切分不同训练集和测试集比例,进行实验。在最佳的K值条件下,与已有的先进的中草药推荐方法PTM[3]以及三个传统机器学习算法:支持向量机(SVM)、朴素贝叶斯分类器(NB)和逻辑回归(LR)的性能进行对比。第三,针对具体的测试集,对网络的推荐结果定性分析该网络的推荐效果。
3.1 实验参数设置
本实验中的卷积核大小,卷积层通道数以及两层的全连接层神经元个数这四个参数我们将通过网格搜索的方式去得到。我们在合适的范围内设置了一些预选的参数,卷积核大小取自集合{3,4,5,6,7}这个范围内,卷积层通道数取自集合{6,12,24,48,96},第一层全连接层个数取自集合{128,256,512,1024,2048},第二层全连接个数取自集合{128,256,512,1024,2048},接着枚举可能的取值进行网格搜索得出最优的参数。关于参数设定的细节,我们同样使用的按不同比例划分为五组的数据集进行实验,每组实验的都是相同的环境,分别枚举四个参数的预选范围对比结果后选择表现最优的参数,因为本实验结果数量较大,因此择优进行实验结果的展示。如图2所示,卷积核大小为4,通道数量为12,两层全连接层分别为256和128时,网络性能最佳。因此,我们将选择这些参数作为本文网络的参数。
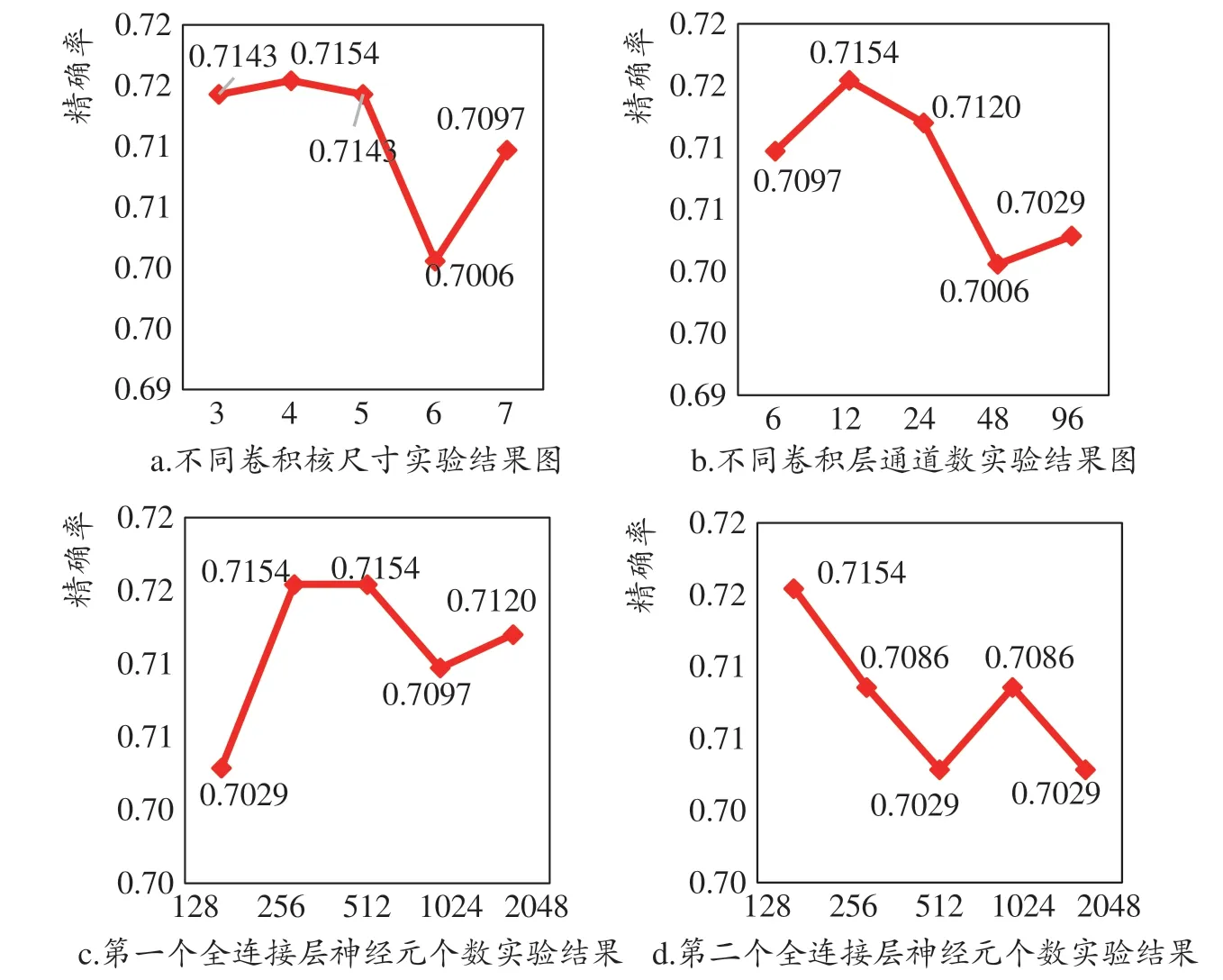
图2 参数设置实验结果图
对于迭代数的确定,我们是根据图3的验证损失和训练损失确定的,由图可以看出网络从20次迭代左右开始出现过拟合现象,且在100次迭代左右训练损失基本没有出现波动,验证损失还有上升趋势,说明模型已经出现过拟合现象,所以鉴于下图的结果,我们将迭代数设置成一个略大于100的值。因此,我们将迭代次数设置为150。

图3 网络训练损失函数结果图
除此以外,为了防止网络过拟合和加快网络收敛,我们为每层卷积添加了归一化层并选择以Adam(Adaptive momentum:自适应动量的随机优化方法)作为优化器进行训练
3.2 不同K值下的诊断结果
本研究以精确率(Precision)、召回率(Recall)和F1分数(F1-score)三个评价指标来对模型性能进行评价,三个指标的定义如下所示[15]:


其中公式中Precision@k精确度表示着预测结果中概率最大的K味草药集合与标签集合中相交个数除上K,公式Recall@k为预测结果中概率最大的K味草药集合与标签集合中相交个数除上标签集合的个数,不过这两种评测标准都不够全面,在数据样本不平衡的情况下,这两种测评标准便失去了意义。而公式F1-score@k是精确度和召回度的加权调和平均值,且数值越大越好,可以准确的反应模型的好坏(表5)。

表5 不同K值诊断结果
由于不同的K对实验定量分析的影响很大,应此我们在选定迭代数(epoch)150,且最小批次(minibatch)为32的条件下取不同的K值进行的多次实验。因为K值为预测结果种概率最大的K中,所以我们并不希望K值的选取过大或者过小,因为过大的K值,虽然有更多的中草药标签,召回率更高,但是会以牺牲精确度为代价,这样没有意义。而过低的K值虽然能够提升精确度却会损失大量的中草药输出,不利于最终的推荐效果。综合每个评价指标,最终我们在K值分别3,4,5,6,10的五次独立实验中决定以实验结果最为稳定的K值为5的方案作为下面定量分析的K值标准。
3.3 数据集定量分析
本研究将数据集切分了不同的训练集、测试集比例进行实验,为了尽可能使数据均衡,具体的切分数量如表6所示,训练集与测试集比例为9:1时,实际训练集样本323,测试集样本35。训练集含有数据集中所有158种症状的157种,并且包含了数据集中所有的77种中草药,保证了每种草药类别足够达到分类的目的。当训练集与测试集比例为8:2时,实际训练样本287,测试集样本73,其中训练集中含有症状146种,中草药74种,缺失的症状种类数为12种,中草药缺失3种。训练集与测试集的其他比例及其样本分布如表6的其他组别所示。对每组数据分别进行实验,得出三个评价指标分别如图4所示,在第1组实验数据中,精确率为71.54%,召回率87.09%,F1-score高达78.55%。相对于其他比例的训练集和测试集划分,这是因为此时训练集数据比较丰富基本涵盖了所有症状和中草药。而其他比例的实验组中,训练集中的症状和中草药都有一定的缺失,所以会导致中草药推荐的效果下降。从评价指标来看,第1组训练集与测试集比例为9:1的实验结果都是最高的,网络学习充分,所以会有较高的精确度和召回率,进而得到较为理想的F1-score。
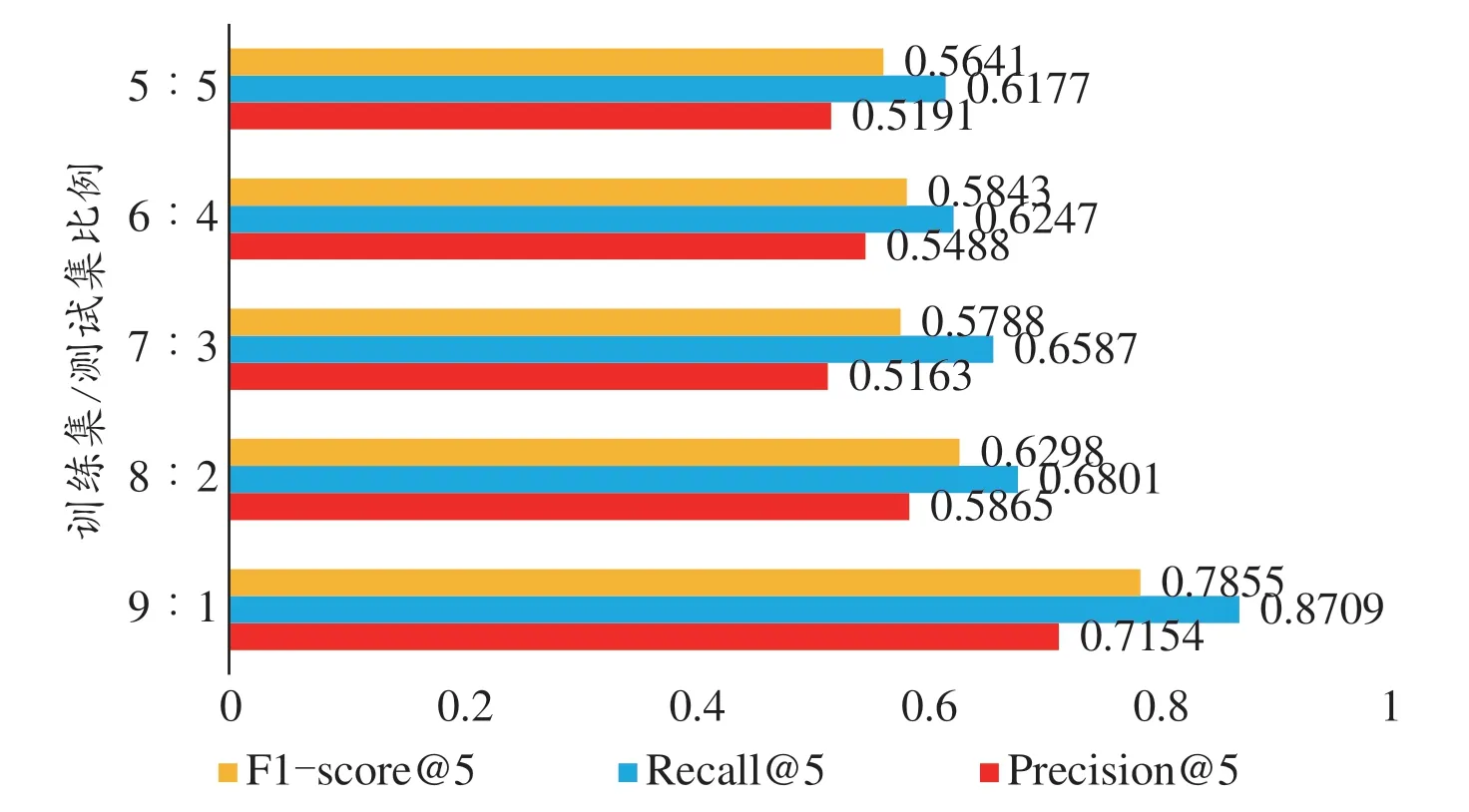
图4 不同训练集/测试集比例实验组上的各评价指标数据
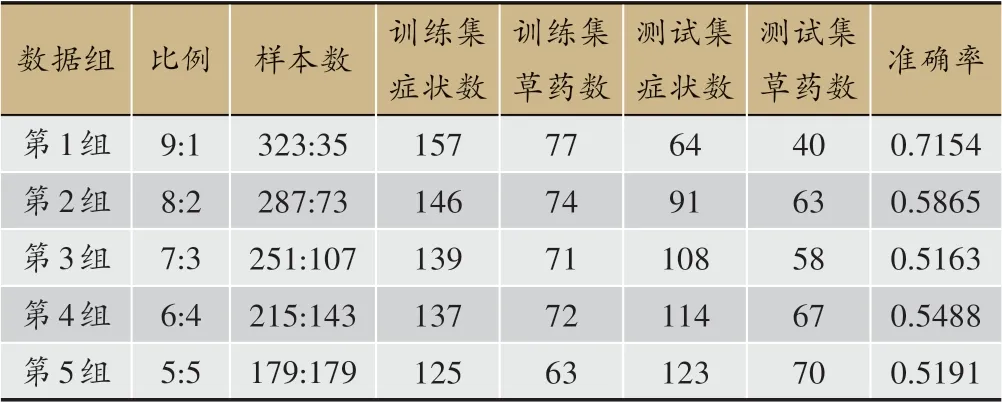
表6 不同比例数据集情况
3.4 与其他算法对比分析
本文提出模型(CNN-HP)是一种基于神经网络的模型。考虑到中草药数量庞大会使得网络参数过多,因此本模型通过权重共享技术,在保证网络稳定的前提下,大大减少了网络的参数,降低网络复杂性。并且本模型是通过局部感知的方式对数据的特征进行提取,较以往的方法相比,我们的模型避免的复杂的特征提取过程,只需要少量的人工参与,且可以拥有更高的精度和更为稳定的网络性能。为了证明我们模型的优良性能,我们的模型与L.Yao[3]等人提出的主题模型进行对比,该主题模型称为概率图形模型,采用了广泛应用于探索性数据分析,主题是在文档中显示语义模式的单词上的分布。每个文档都以不同程度(主题比例)展示这些主题。该方法将处方视为“文档”(一组“草药词”或“症状词”)和处方中的治疗模式视为“主题”。此外,我们还与其他机器学习算法比如支持向量机(SVM)[16]、逻辑回归(LR)[17]和朴素贝叶斯分类器(NB)[18]进行了对比实验,且所使用的数据集没有任何差异,都是将数据集按照训练集和测试集按照不同的比例分为五组,在相同比例的数据集之间进行对比,且都把症状作为输入,是完全相同的条件。
通过与以上四种算法用不同训练集、测试集比例对比实验,其精确度对比如图5所示。无论在什么比例的训练集、测试集比例划分,我们设计的CNN-HP模型都在精确度方面优于其他算法,尤其是在9:1实验组,优势最为明显。充分说明了卷积操作有效的提取了征状特征。
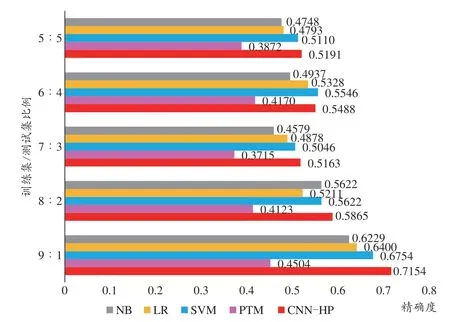
图5 不同训练集/测试集比例实验组上的各算法结果对比
此外我们还将训练集、测试集为9:1时,用其他评价指标进行了对比。如图6所示我们的模型无论是在精确度,召回度还是F1分数上都领先于三种传统机器学习算法,证明了我们在的算法在中草药推荐上有着突出的性能。

图6 不同算法的各个评价指标
3.5 定性评价及分析
由以上的实验对比结果可得,本模型(CNN-HP)的预测数据比较令人满意。本研究最后基于具体的测试集进行了推荐结果的分析,如表7所示,当病人出现“口苦、胸满、胁痛、咽干”症状时,实际的中医临床治疗需要用“黄芩、人参、柴胡、大枣、半夏、炙甘草、生姜”来治疗,我们的模型推荐的概率最高的五个标签结果是“炙甘草、人参、生姜、大枣、柴胡”,所有的预测结果都在实际需要用药之列,当推荐7味中草药时,黄芩和大枣也成功被预测出来。再比如,当中药标签是“干姜、附子、炙甘草”时,我们的模型也在前三个标签给出了正确的预测。再比如当实际的中草药标签是“干姜、白术、人参、炙甘草”,其中的“干姜、人参、炙甘草”都能够被正确预测,而“白术”始终没有被预测到,是因为数据不够均衡,这一味中草药出现频次非常少。可见我们的模型能提供较为准确的中草药处方预测结果,具有一定的实际应用价值。

表7 卷积神经网络中药推荐结果实例
4 结论
本文通过探索中医症状到药方之间的逻辑关系,设计卷积神经网络,实现了中医病症到中草药的自动推荐。此模型巧妙地解决了中医特有的诊断抽象思维、中草药配伍差异等复杂的非线性问题,实现了中草药处方的智能推荐。定量与定性的实验结果表明,本文模型实现中草药预测精确率71.54%、召回率87.09%、F1分数78.55%,均优于支持向量机、贝叶斯分类器和逻辑回归等传统机器学习模型以及现有的先进的中草药推荐模型,取得了更好的中草药推荐效果。
猜你喜欢
今日农业(2022年16期)2022-09-22
农业工程学报(2022年12期)2022-09-09
今日农业(2021年17期)2021-11-26
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
文苑(2020年6期)2020-06-22
恋爱婚姻家庭·养生版(2018年10期)2018-10-26
家庭用药(2016年9期)2016-12-03
祝您健康(2000年7期)2000-12-29
