
面向时空特性的社会网络个性化隐私保护算法
2022-10-15 03:06:44夏秀峰尹伯阳刘向宇李佳佳宗传玉
小型微型计算机系统 2022年10期
夏秀峰,尹伯阳,刘向宇,2,李佳佳,宗传玉 ,朱 睿
1(沈阳航空航天大学 计算机学院,沈阳 110036)
2(新西兰惠灵顿理工学院 信息与商科学院,新西兰 下哈特 5010)
E-mail:boyang_yin@163.com
1 引 言
随着社交网络技术的发展,人们对社交网络信息发布的需求正由“无差异”逐步发展为“个性化”,具有个性化的签到数据导致了敏感关系隐私泄露问题.针对具有相同时间和地点的签到数据,不同用户对于完全公开、部分公开、还是不公开信息的需求存在巨大差异.由于用户个体对不同签到数据的敏感性并不一致,并且对于同一签到数据,用户在不同时期的敏感性不同,从而使用户对于签到数据的敏感性呈现动态化特征,会随着时间的变化而发生变化.因此,在发布签到数据时需要考虑用户的个性化隐私需求.综上所述,当前社交网络隐私保护研究忽视了基于签到数据的推演攻击,同时签到数据的时空特性增加了推演隐私攻击的难度,这些特点使社交网络隐私保护变得更加复杂、更具有挑战性.
k-匿名模型[1,2]经常被用于数据发布中的信息保护.在用户使用社交应用时,产生了个人隐私的泄露风险,无论用户是否具有主动保护个人隐私的想法与需求,大多数用户本身在隐私泄露面前都是难以察觉或者无法有效处理的.文献[3]提出攻击者会将其他方面的背景知识或者根据分析用户的背景知识,作为隐私攻击过程中的数据源.文献[4]考虑到只能防止具有相同背景知识攻击的单一模型,无法满足用户的个性化隐私要求.因此提出了一个基于用户个人隐私请求的隐私保护服务框架.根据攻击者逐渐增长的背景知识,定义了3个级别的保护需求.文献[5]提出了一种具有个性化差异隐私的概率矩阵分解推荐方案(PDP-PMF).文献[6]提出分别用一个特定区域和一组位置类型替换用户的真实位置和查询目标.文献[7]根据时间重叠相似性、轨迹方向相似性和轨迹间距离的不确定性,计算两条轨迹之间的相关性.文献[8]提出了通过匹配用户的共享位置与他们的真实移动轨迹,量化移动社交网络的引发位置隐私泄漏.文献[9]通过分析k-匿名模型的缺点,提出l-使用多样性来加强隐私保护.文献[10]提出了一种以用户为中心的混淆方法,称为KLAP,基于3个基本混淆需求:位置、多样性和隐私区域保存.文献[11]首先总结了k-匿名算法对标准标识符中敏感属性的影响,然后从匿名数据的隐私性和安全性的角度分析了改进的l-多样性算法.社交网络隐私保护常见的技术还包括数据扰动[12]、查询结果扰动[13]以及在统计学领域提出的其他解决方案.
针对社交网络中的个性化签到数据发布,从而导致用户的身份隐私泄露的问题,本文提出了一种面向时空特性的社会网络个性化隐私保护方法.本文研究工作主要分为如下几个方面:首先,采用泛化技术来防止用户的身份隐私泄露,避免发布的时空数据过于稀疏造成数据可用性的降低.通过背景知识的分级,分阶段泛化原始时空数据,得到泛化结果;根据泛化结果,结合用户自身的个性化隐私保护需求,对相应的敏感信息设定不同敏感程度值;采用泛化层次数规则评估每个敏感地点的敏感程度,实现攻击者不会通过签到数据发布中包含的背景知识匹配出用户的身份信息,从而保护用户的身份隐私,满足用户的个性化隐私保护需求.
2 时空数据敏感属性分级及相关定义
2.1 时空签到数据及相关定义
定义1.(时空签到数据元组):给定一个时空签到数据元组ti,则时空签到元组ti可以表示为
定义2.(时空签到数据属性):给定一个时空签到数据元组ti,则时空签到元组ti可以表示为
2.2 时空数据敏感属性分级及相关定义
定义3.(第1级别时空签到数据敏感属性):若在某用户已发布的时空数据表的签到数据集合中仅存在一条准标识符为
定义4.(第2级别面向时空特性的数据敏感属性):若已经发布的时空数据表的两个不同用户签到数据集合中分别存在一条标识符为
定义5.(第3级别面向时空特性的数据敏感属性):若已经发布的时空数据表的某用户签到数据集合中存在n(n=1,2,3…)个准标识符相同但敏感地点属性不完全相同的元组
定义6.(泛化词分类表):泛化词分类表中,所有敏感属性s组成敏感属性集合S,按照标记类型 (Type)、地点名称(LID)和地点类别(Category)之间的语义从属关系建立.每一个地点名称LID都会对应地点类别和标记类型,如表1所示.
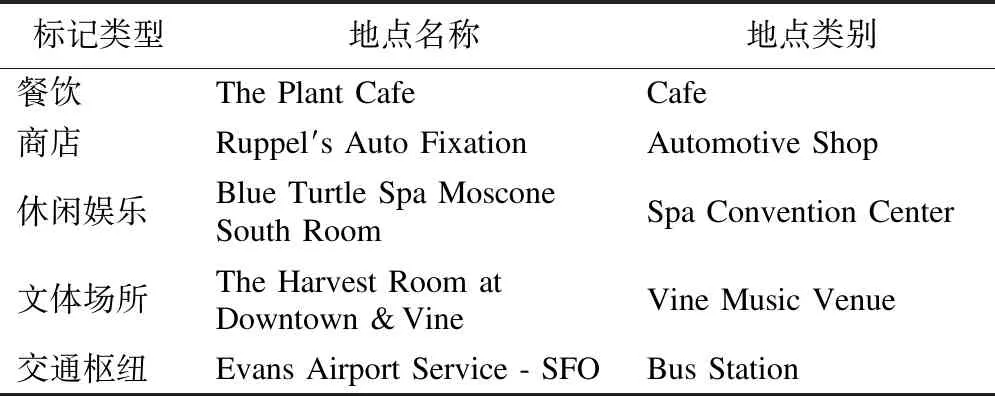
表1 泛化词分类示例表Table 1 Generalized word classification
定义7.(第4级别面向时空特性的数据敏感属性):若已经发布的时空数据表的签到数据集合中存在一条标识符为
定义8.(数值型属性元组间的距离):令N为有限数值域,元组中任意两个数值ti,tj∈N之间的标准距离定义为:
(1)
其中|D|表示域D的最大值与最小值的差值.
定义9.(泛化层次距离):设H为原始数据表中某一分类型属性可能泛化到的最高层次,其中D1为值域,D2到Dn为泛化域,j和j-1表示值域与泛化域之间的泛化权重.由Dp中的值泛化到Dq值的距离定义为泛化的加权层次距离:
(2)
定义10.(分类型属性元组间距离):设t1和t2为同一原始数据表中不同的两个元组,t12为t1和t1这两个元组的最近公共泛化元组,则t1和t2两个元组间的距离可以定义为:
HDist(t1,t2)=HDist(t1,t12)+HDist(t2,t12)
(3)
3 时空数据个性化隐私保护算法
PSTPP算法集成了个性化匿名的两种机制,能在对敏感属性设置了相应的约束条件的同时,满足个人对隐私保护的要求.即用户可以在系统提供背景知识分级保护的同时,为自己的敏感值设定隐私保护的级别.
3.1 设计思想
算法通过为敏感属性构造泛化层次树的方式,允许特定的用户为自己的敏感属性值设置隐私保护级别.同时构造泛化词分类表,依据语义信息把相同类别的敏感地点进行分类,通过层次泛化树中搜索敏感地点结点的父亲结点对该结点进行替换,这样不但泛化了敏感地点的语义信息,使攻击者无法准备匹配出用户的隐私信息,同时保留了签到数据的语义特征.
那么为敏感属性s构建一个泛化层次树GHT(Generalization Hierarchy Tree),树中的每一个结点包括根节点和父亲节点,都有一个敏感地点属性值SID与其一一对应,如图1所示.敏感地点属性的原始值作为树的叶子节点,对应的树层次级别为1.根据泛化查询层次的偏移量,计算每条数据泛化的平均高度求出信息损失.
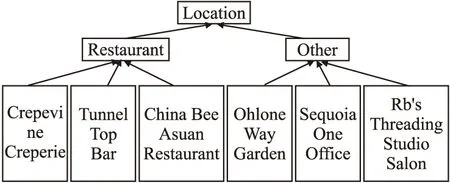
图1 泛化层次树Fig.1 Generalization hierarchy tree graph
在泛化层次树中,越接近根节点,泛化的程度越高.用户可以在系统提供基于背景知识分级保护的同时,为自己的敏感属性设定隐私保护敏感值.依据泛化层次数,允许用户个性化设定敏感属性的敏感属性值.
定义11.(个性化敏感属性值PPL):给定敏感属性s和其对应的地点类别和标记类型,每一个敏感地点属性值都对应SID中唯一的一个敏感属性值PPL(Privacy Preservation Level).
表2是用户指定的隐私保护级别表,其中PPL值为空的元组表示用户没有为自己的敏感属性设置个性化敏感属性值.

表2 个性化敏感属性值示例表Table 2 Personalized sensitive attribute values
若PPL≤SID,则对敏感值的签到数据不进行处理,对PPL>SID的数据,则使用泛化层次树中与PPL的值对应SID所在的原始值的父节点代替当前的敏感地点属性.
3.2 算法描述
算法1是对PSTPP的描述.在发布的签到数据集满足隐私保护级别参数约束的前提下,对用户设置的个性化敏感属性值进行判定,并对不能同时满足约束的数据进行相应处理.运用泛化操作,查询泛化树中对应的结点,替换原有的敏感属性信息,使得数据集满足输入的参数约束.最后依据个性化的隐私保护规则,生成可发布的安全数据集.
算法1.时空数据个性化隐私保护PSTPP算法
输入:数据集D,匿名参数(k,l,α),敏感属性s,等价类C,元组t,敏感地点属性值SID,GHT,部分用户指定的个性化敏感属性值PPL;
输出:安全发布的满足约束条件匿名签到数据集D′;
1.D←φ;
2.For CreateCforD
3.According totiandtmax,partitionCintoC1,C2
4.SuchC1,C2are more local than T and eitherC1,C2has leastktuples
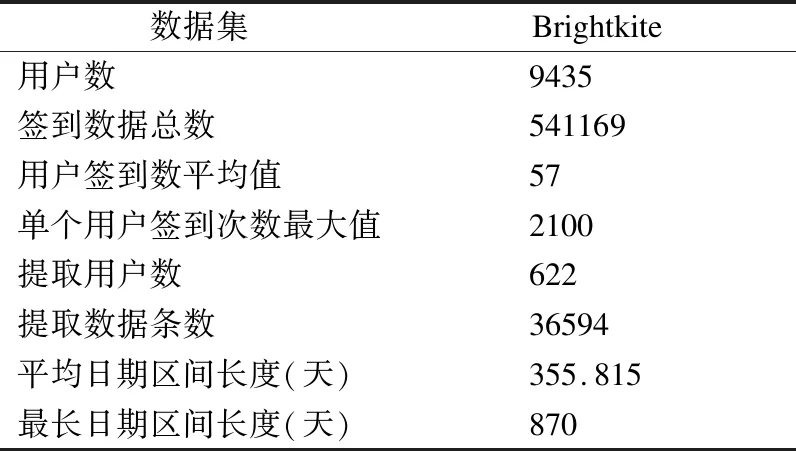
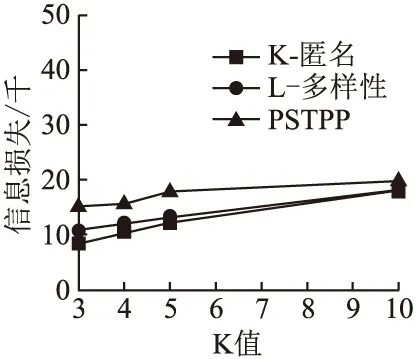
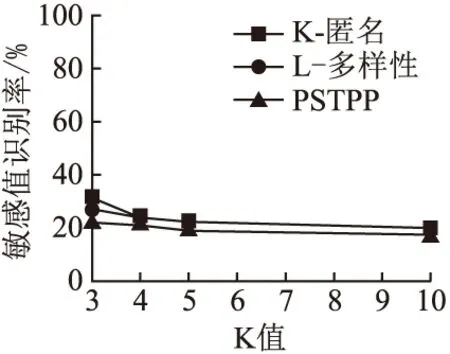
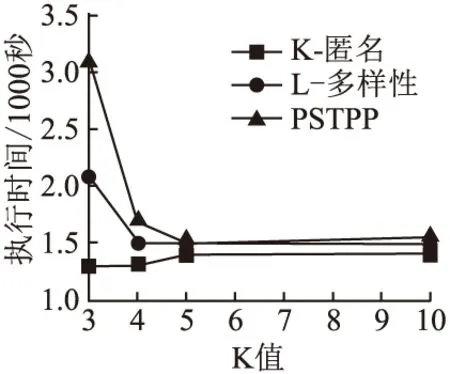
5.IfC1 6. Recursively partitionC1 7.Else partitionC2 8.For Merge thoseCinD; 9.IfG≠φthenD←Gand return up code then 10.GetD* 11.ElseDgenerateC 12.IftinD*thatPPL>SIDthen 13. Findnodetin GHT thenD′←nodet 14.ElseD*←nodet 15.ReturnD′; 本文中的实验数据来源于现实的Brightkite数据集(Brightkite datasets: Network datasets: Brightkite stanford.edu),表3给出了实验数据集的构成.收集了用户从2008年4月份至2010年10月份的签到数据,并且通过预处理选出美国加利福尼亚州的数据.Brightkite数据集包含9435名用户和541169个签到点.由于数据过多,因此提取Brightkite数据集中2008年4月1日至2009年5月1日的36594条数据,总共包涵622个用户.将签到数据集中的签到位置进行了统一的编号,并通过爬虫和地理信息API得到了每个位置的名称和类别. 表3 实验数据Table 3 Experimental data 为了验证PSTPP算法的性能,在相同的实验条件下将其与k-匿名算法、l-多样性算法进行比较,所有实验的l的比值都固定为(l=4,α=0.8).从数据集中随机抽取数据记录,并为他们随机设置隐私保护级别PPL.此外,为数据集中的每一个属性都构造层次泛化树. 基于所选择的实验数据,从算法的信息损失量、敏感值识别率以及运行时间来验证PSTPP算法的可行性. 4.2.1 信息损失量分析 定义12.(信息损失量):设等价类C中的元组个数为n,公共泛化元组为t,其中(A1,A2,…,Ac)是等价类C中的数值型标识属性,那么元组t在属性Ac上的信息损失为: HILAi(C)=n×HDist(t) (4) 设安全发布的数据表T中等价类个数为m,表T中所有元组在各个属性上的信息损失为: IL(T)=mNILAi(C)+mHILAi(C) (5) 信息损失通过使用公式(5)进行计算,验证数据36594条.k取值的分别从3、5、7到10依次递增.对平均泛化高度产生的信息损失进行归一化处理后得到的隐私保护算法的信息损失量如图2所示. 图2 信息损失量与k值Fig.2 Information loss with different k 由图2可知,随着k取值的增加,数据集信息损失量不断增加,因为k的大小直接影响数据中的等价类的大小.即k值越大,同一个等价类汇总需要泛化的准标识符数据的值的越多,所以信息损失量越大.当k值增加至一定程度时,l-多样性模型与k-匿名模型信息损失量差异不大,这是因为固定的l的取值在k值增加到一定程度时对数据集的约束不明显.综述所述,PSTPP算法的信息损失量相对其他两种算法更大,这是由于其增加了对敏感值的个性化保护所导致的. 4.2.2 敏感识别率分析 定义13.(敏感属性值的识别率):给定数据集D和等价类C,s是等价类C中的某条数据t的敏感属性值,则C中t的敏感属性值s的识别率计算公式为: (6) 其中,|(s,C)|为等价类C中的敏感属性值s的个数,|C|为等价类的大小,|f(s)|等于敏感属性泛化层次树泛化后的父节点所在子树的叶节点个数.若敏感值没有进行泛化,保留匿名化后元组中原地点名称,则|f(s)|=1. 数据集的敏感值识别率使用公式(6)进行计算,k取值分别为从3、5、7到10依次递增.图3给出了在图2中相同数据下,当k值变化时,隐私模型的敏感值识别率. 图3 敏感属性识别率与k值Fig.3 Recognition rate of sensitive value with different k 如图3所示,随着k值的变化,模型的敏感值识别率不断降低,最终趋近于平缓.其中PSTPP算法相较于其他两个模型,敏感值识别率是最低的,隐私保护效果最好. 4.2.3 运行时间分析 图4给出了根据k值变化的模型运行时间. 图4 运行时间与k值Fig.4 Running time with different k 如图4所示,当k值变化时,算法的运行时间会有一定的变化.当k=4时,l-多样性模型与PSTPP算法会随着隐私参数l和α的设置增加了划分等价类时的判定时间,因此运行时间较长.而随着k值的增大,算法的运行时间差别不大,所以PSTPP算法能更好的防止隐私泄露. 针对基于时空特性的社会网络中敏感属性的隐私保护问题展开研究,提出了一个时空数据发布的个性化隐私保护算法(PSTPP),该算法为敏感属性构造泛化层次树,允许特定的用户为自己的敏感属性值设置隐私保护级别,满足用户的隐私保护需求.同时,按照时空签到数据敏感属性对时空数据进行分级保护,允许不同的用户设置不同的敏感属性值约束,提高了签到数据的可用性.最后,基于实际数据集对算法的信息损失量、敏感值识别率以及运行时间进行测试.测试结果表明,提出的算法能够针对不同层次的敏感属性泄露应对不同的保护策略,以此来满足用户的个性化选择,证明了该算法的有效性.4 实 验
4.1 实验环境设置
4.2 实验结果及分析
4 结束语
猜你喜欢
中国设备工程(2023年16期)2023-08-29 07:10:58
计算机应用(2022年8期)2022-08-24 06:30:36
四川党的建设(2022年8期)2022-04-28 21:29:35
电脑报(2021年14期)2021-06-28 10:46:22
小学生学习指导(低年级)(2020年11期)2020-12-14 07:28:10
计算机系统应用(2020年8期)2020-03-22 07:41:52
计算机与生活(2019年5期)2019-07-18 01:08:56
作文大王·低年级(2018年10期)2018-12-06 06:22:44
吉林大学学报(理学版)(2018年2期)2018-03-29 04:58:03
中国美术馆(2016年6期)2017-01-19 08:44:24
