
基于XGBoost模型的新型冠状病毒(COVID-19)疫情分析与预测
2022-10-15 13:17:10孙许可
现代信息科技 2022年14期
孙许可
(中国人民武装警察部队士官学校,浙江 杭州 311400)
0 引 言
新冠肺炎(COVID-19)疫情已成为国际关注的突发公共卫生事件,COVID-19 呼吸系统疾病的病毒株是一种名为严重急性呼吸系统综合征冠状病毒2(又称SARS-CoV-2)引起的。这种冠状病毒病具有极强的传染性。自最初确认以来,尽管受到严格控制,但仍已成为全球流行病,对世界卫生和经济发展构成了巨大的威胁和挑战。目前,该疾病已蔓延至全球100 多个国家。
至2020年6月16日,全球共报告8 044 683 例COVID-19 病例,死亡437 131 例,治愈3 883 243 例,总病死率为5.43%,其中,美国、巴西、俄罗斯、印度和英国是世界上感染人数最多的5 个国家。COVID-19 表现出非线性和复杂的性质,除了涉及传播的众多已知和未知变量外,不同地缘政治区域的人口行为的复杂性和遏制策略的差异极大地增加了模型的不确定性。
因此,建立基于XGBoost 的疫情预测模型,使用Jupyter 软件进行学习和训练,对2020年1月23日到3月1日全国和湖北的累积确诊病例数、累积死亡病例数、累积治愈病例数、累积正在治疗病例数进行分析、建模,进一步洞悉新冠肺炎疫情发展规律,为防控新冠疫情提供参考。
1 模型与方法
1.1 XGBoost 概述
该算法的建模思路:给出一个泛化的目标函数的定义,在每一轮的迭代中找到一个合适的回归树去拟合上次预测的残差,最小化目标函数,使估算值逼近真实值,如图1所示。

图1 XGBoost 原理
例如,数据([Δ,Δ,],SOH),([Δ,Δ,],SOH)…([Δ UΔ T,],SOH),=1,2,…,。其中Δ U,Δ T,,SOH分别表示第i 组数据对应的电压差、温度差、平均电压以及健康状态。
在本文中,我们定义树f(x)如下:

其中,表示每棵树的结构,它将使叶子节点与每个样本一一对应,是树中叶子节点的个数。每个f对应于一个独立的树结构和叶子权重。
将树的复杂度(f)定义为:

为叶子个数,w表示第个叶子的权重。
将目标函数定义为:


将目标函数进行展开,为:


新的目标函数可以定义为:
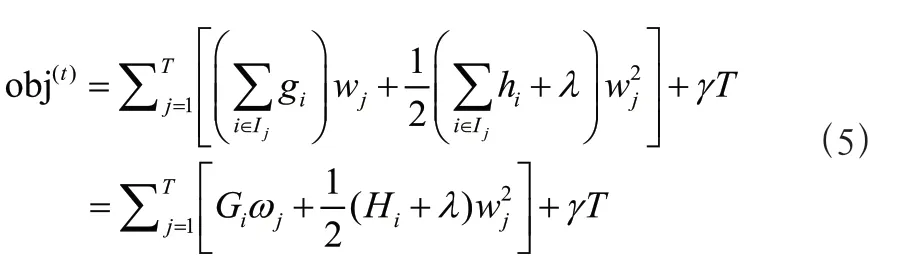
定义每棵树的分裂节点的候选特征集合为I,I={|(Δ U,Δ T,Δ)=}。
计算出最优权重 和最佳的目标函数解obj:
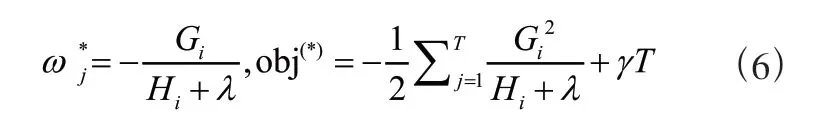
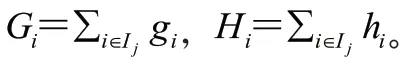
1.2 XGBoost 建模
如图2所示,本文所提出的方法主要分为两个部分:特征选择、XGBoost 估算。首先,从数据集里面提取特征输入,将累积治愈病例数、累积死亡病例数、累积正在治愈病例数作为特征输入,然后,利用XGBoost 算法实现对累积确诊病例数的估算,进一步提高累积确诊病例数的估算精度。

图2 XGBoost 模型构建
2 模型评估与预测
2.1 实验数据
本次实验所使用的数据是该网站数据是从国家卫生健康委员会网站整理成CSV 格式得到,该网站为:http://www.nhc.gov.cn/xcs/yqtb/list_gzbd.shtml。该数据包括2020年1月23日到3月1日国家卫生健健委员会公布的全国和湖北的累积确诊病例数、累积死亡病例数、累积治愈病例数、累积正在治愈病例数,该数据无缺失值。
全国和湖北的累积确诊病例数、累积死亡病例数、累积治愈病例数、累积正在治愈病例数,如图3所示。
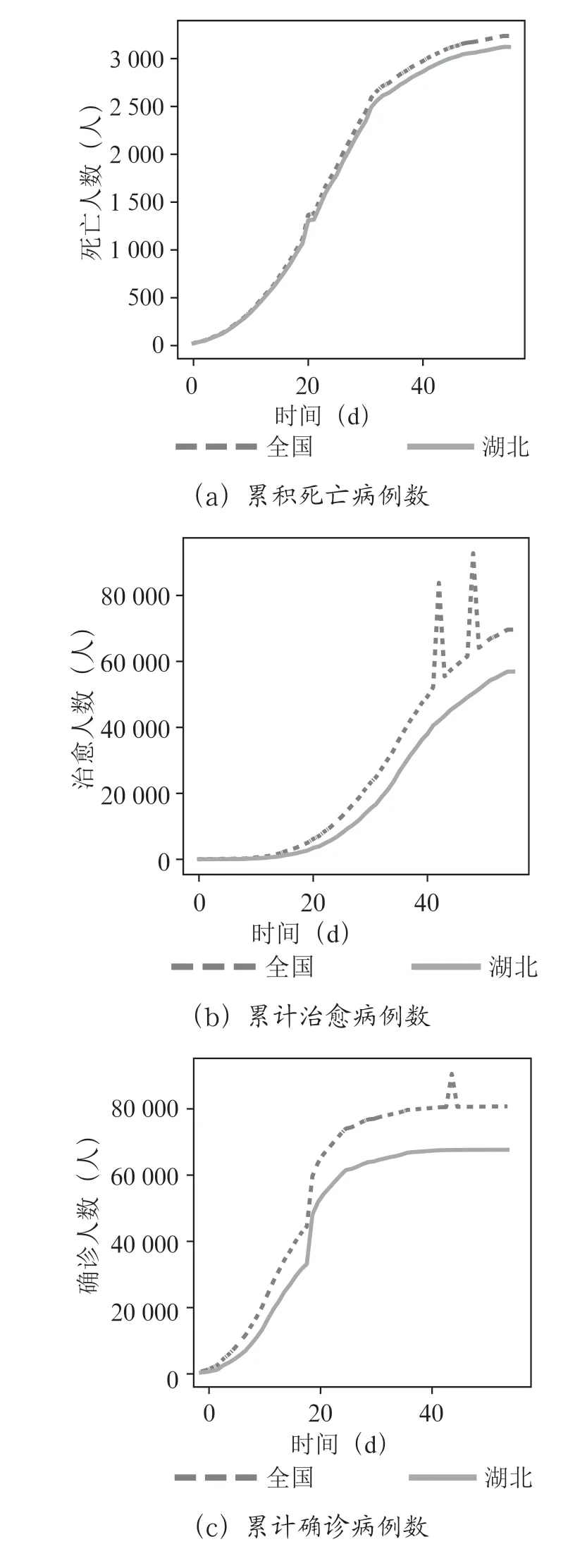

图3 数据分析
为了验证XGBoost 算法在COVID-19 估算上的普遍性,将学习率设置为0.2,最小叶子权重设置为1,树的深度设置为3(实验结果表明该模型收敛),并进行了两组实验:一组是将全国疫情数据作为模型的训练集,用于模型的训练,将湖北疫情数据作为测试集,用于测试模型的性能;另一组将湖北疫情数据作为模型的训练集,用于模型的训练,并将湖北疫情数据作为测试集,用于测试模型的性能。
2.2 实验评估标准
(1)平均绝对误差(MAE)
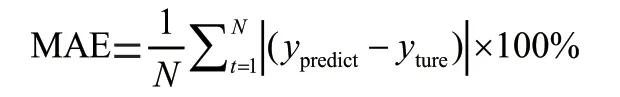
(2)均方根百分比误差(RMSE)

(3)最大估算误差(Maximum Error)

三项技术指标(MAE、RMSE、Maximum Error)的值越低,证明模型拟合的结果越好。
2.3 实验结果分析
为了验证基于XGBoost 算法的COVID-19 估算方法的准确性,将预测结果与随机森林、线性回归、KNN、SVM的预测结果进行比较。图4和图5显示了在全国疫情数据和湖北疫情数据上的累积确诊病例的预测结果和预测误差。


图4 预测结果对比

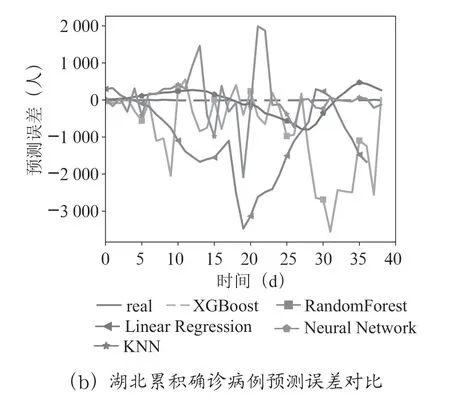
图5 预测误差对比
如图4所示,从预测结果上看:无论是在全国疫情数据上还是在湖北疫情数据上,XGBoost 比其他四种回归算法在估算值上更加接近真实值,估算精度更高。
如图5所示,从产生的残差上看:无论是在全国疫情数据上还是在湖北疫情数据上,其他四种回归算法所产生的残差曲线波动范围较大,而XGBoost 的残差曲线在0 附近上下波动。
从表1中可以看出,在全国疫情数据或湖北疫情数据上,三个技术指标中的XGBoost 值均低于其他四种算法的值,XGBoost 的性能均优于其他四种算法。
可视化表1中的MAE、RMSE、Maximum Error 数据,如图6所示。总之,无论在全国疫情数据还是湖北疫情数据上,XGBoost 具有更高的估算精度,在三个技术指标中,XGBoost 均优于其他四种算法。

表1 全国疫情、湖北疫情数据集预测误差对比
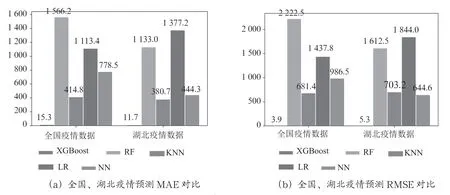
图6 误差可视化对比
特征重要性分析如图7所示。其中,贡献最大是累积治愈病例数,其次是累积死亡病例数,而累积正在治愈病例数最小。因此,在估算过程中,可以根据特征重要性等级,增加或减少某个特征比重,提高特征数据准确性,来进一步提高估算精度。
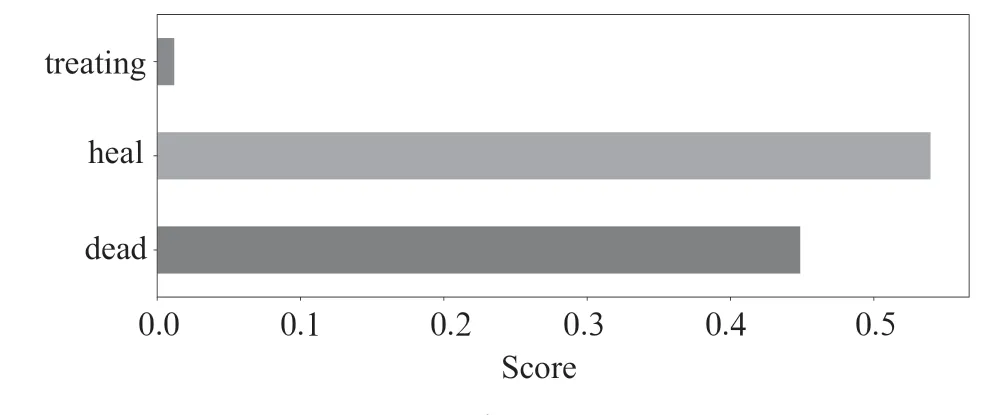
图7 特征重要性
3 结 论
利用Jupyter 软件对历史数据进行学习和训练,建立新冠肺炎病例XGBoost 预测模型,将累积治愈病例数、累积死亡病例数、累积正在治愈病例数作为特征输入,对2020年1月23日到3月1日全国和湖北的累积确诊病例数进行预测,将其预测结果与其他4 种预测模型进行比较,实验结果表明:与线性回归模型、随机森林模型、支持向量机模型、KNN 模型等四种预测模型相比,采用XGBoost 预测模型预测的累积确诊病例数更接近实际值,其平均绝对误差和均方根误差以及最大误差这三项技术指标均最小,预测精度最高,并且分析得出特征重要性等级,其中,贡献最大是累积治愈病例数,这为后期进一步提高估算精度指明方向。
猜你喜欢
疯狂英语·新读写(2022年7期)2022-11-22 15:49:20
哈尔滨轴承(2020年2期)2020-11-06 09:22:26
作文评点报·低幼版(2020年25期)2020-07-23 06:45:56
今日中国·法文版(2020年7期)2020-07-04 02:53:48
海峡姐妹(2020年2期)2020-03-03 13:36:28
学生天地(2019年30期)2019-08-25 08:53:20
中国特种设备安全(2019年1期)2019-03-13 01:06:26
澳门月刊(2018年1期)2018-01-17 08:49:15
湖南畜牧兽医(2016年1期)2016-06-05 08:37:49
山东青年(2016年2期)2016-02-28 14:25:41
