
基于Lasso回归及模型修正的双重回归缺失值插补方法研究
2022-10-14 06:10吴斌鑫周正南莫常春
机械与电子 2022年9期
吴斌鑫,刘 美,周正南,,莫常春,4,吴 猛,张 斐
(1.广东石油化工学院,广东 茂名 525000;2.吉林化工学院,吉林 吉林 132022;3.东莞理工学院,广东 东莞 523419;4.大连交通大学,辽宁 大连 116028)
0 引言
在多传感网络监测的过程中,由于工作环境的复杂性、传感设备失效等因素,监测数据有可能存在缺失。插补法是利用现有数据,通过统计学习方法挖掘数据信息并预测缺失值,避免了原始信息的丢失、保持样本容量,具有高效的优点[1-2]。其中,K近邻(K-nearest neighbor,KNN)插补法,寻找数据集中识别空间相似或相近的K个样本,并使用这K个样本估计缺失数据点的值,简单易行[3-4];单一线性回归插补法,利用完整数据建立模型,依据此模型预测插补缺失值[5];神经网络依据网络深度及反向传播,优化网络输出减小误差,最终做出预测[6]。机器学习算法在处理缺失值时速度快、特征表征能力强,因此应用广泛。
然而,KNN插补法的插补效果因受数据集部分异常值影响,导致预测效果浮动较大[7];单一线性回归插补法因信息表征能力有限而存在精确度不高的问题[8];神经网络预测插补法随着网络层数增加时间复杂度较高[9]。因而,本文提出了一种基于Lasso回归及模型修正的双重回归缺失值插补方法。
1 相关理论分析
Lasso回归、皮尔逊相关性分析及岭回归是本文方法的重要组成部分,对本文方法起支撑作用。
1.1 Lasso回归
对于多元线性回归模型[10],其模型表达式为
(1)
yi为第i个预测值;βk为第k个自变量对应的回归系数;xi,k为第i行第k个自变量;ε为偏移量;n为自变量个数。
为保证回归系数βk可求,在多元线性回归目标函数加上L1范数惩罚项,则Lasso回归目标函数[11]为
J(β)=∑(y-Xβ)2+∑λ|β|
(2)
y为观测集;X为由x1,x2,…,xn构成的集合;β为由β1,β2,…,βn构成的回归系数集;λ为正则化系数,且值非负。
由Lasso回归目标函数可知,其引入L1范数惩罚项,正则化系数λ的选取十分重要。因此,本文采用K折交叉验证的方式对参数λ进行求取。
1.2 皮尔逊相关性分析
为弥补单层回归存在的误差,将挖掘数据之间存在的相关性,反映各变量与目标值之间的相关信息,并在此基础上作为Lasso回归的特征。此处采用皮尔逊相关系数寻找相关系数[12],2个变量之间的皮尔逊相关系数计算公式为
(3)
ρX,Y为2个变量之间的皮尔逊相关系数;σX、σY分别为变量X、Y的标准差;μX、μY分别为变量X、Y的均值。
对获得的相关系数重新进行计算(权重分配),计算公式为
(4)
γi为新获得的系数;ρXi,Y为原始系数。
1.3 岭回归
在多元线性回归目标函数加上L2范数惩罚项,则岭回归目标函数[13]为
J(β)=∑(y-Xβ)2+∑λβ2
(5)
y为观测集;X为由x1,x2,…,xn构成的集合;β为由β1,β2,…,βn构成的回归系数集;λ为正则化系数,且值非负。
与Lasso回归相同的是,岭回归对于参数λ值的求取也非常重要,因此同样采用K折交叉验证的方式求取参数λ。
1.4 KNN插补法
K近邻(KNN)插补法,通过距离测量来寻找数据集中识别空间相似或相近的K个样本,并使用这K个样本估计缺失数据点的值,或者可以直接使用相邻观测值的完整值来估计缺失值,简单易行。其识别空间相似或相近使用欧氏距离度量,公式为
(6)
2 整体模型构建
整体模型以Lasso回归模型为基础,结合皮尔逊相关系数与岭回归模型并将两者输出作为Lasso回归模型的输入(特征),最终构建双重回归模型,提高整体预测插补的精度。
对于任意m×n结构的数据集,通过式(1)、式(3)和式(4)可得岭回归模型结构及权重分配后的皮尔逊相关系数。假设求得岭回归(第1层回归)系数β1,β2,…,βn、岭回归偏移量ε及权重分配后的相关系数γ1,γ2,…,γn。那么对于导入的数据,将会生成集成岭回归及相关性的数据集,公式为:
(7)
(8)

将生成的集成岭回归及相关性的数据集导入Lasso回归模型,最终确定回归系数及偏移量,即可确定整体模型表达式,即
(9)
ε′为Lasso回归的偏移量;α1、α2为Lasso回归系数。
3 算法设计及评估
3.1 算法步骤
a.对原始数据进行滑动窗口处理以制作数据集,并针对数据集进行随机剔除以模拟缺失值。将整个数据集分为完整数据集和残缺数据集。因2层回归的数据需要,因此再将完整数据集分为2组,即训练集1、测试集1、训练集2、测试集2。过程如图1所示。
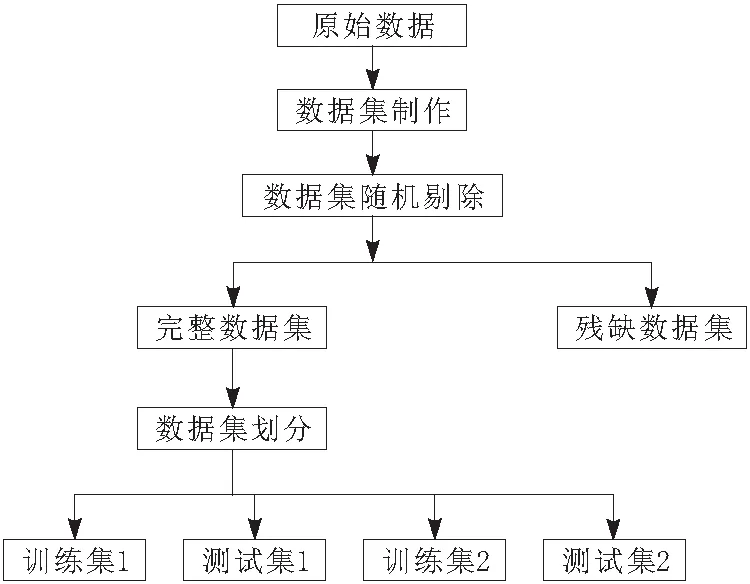
图1 数据预处理
b.划分后的数据集使用训练集1放入岭回归模型进行训练,并采用交叉验证对岭回归重要参数调优。进一步,使用测试集1对岭回归评估,与此同时,对训练集1进行皮尔逊相关性分析获得应变量与自变量之间的初步联系。最终得到岭回归模型及皮尔逊相关性模型。过程如图2所示。

图2 岭回归与皮尔逊相关分析
c.对已获得的岭回归系数、偏移量及相关系数结合训练集2进行计算,生成集成岭回归及相关性的训练集(双列),并将此作为Lasso回归的输入用以训练模型,后续通过K折交叉对Lasso模型参数调优。同理,测试集2通过岭回归模型及皮尔逊相关性模型生成集成岭回归及相关性的测试集,并对Lasso回归模型评估。最终初步确定整体模型。过程如图3所示。

图3 初步整体模型确定
d.将残缺数据集导入全局初步模型模拟插补,并根据计算而得的评估指标校正分块模型的参数,最终完成建模,为后续缺失值插补提供支撑。
3.2 评估指标
采用均方根误差ERMS、模型训练时间及决定系数R2来评估各方法在各缺失率下的插补效果。均方根误差的计算公式为
(10)

计算时间,即时间花费,该指标关注模型的时间复杂度,公式为模型训练结束时间减去模型训练开始时间,即te-ts。
决定系数反映了模型对数据的拟合能力。决定系数计算公式为
(11)
u为残差平方和,v为总体平方差,计算公式分别为:
(12)
(13)
由上述可知,R2的取值范围一般介于[0,1]。R2的值越高,说明自变量(特征)对因变量解释程度越高,观测点在回归线附近越密集。
4 试验及结果分析
本文采用西储大学轴承数据中正常状态下驱动端加速度数据。选择其中前5 010个采样点并使用滑动窗口法对数据进行处理,窗口长度为11,步长为1,即生成1个5 000×11的数据集。使用随机剔除方法对数据集处理,并划分为残缺数据集和完整数据集。在此基础上,将完整数据集分别按照0.35、0.15、0.35、0.15的比例随机地划分训练集1、测试集1、训练集2、测试集2。
经过数据集划分后,将数据集1导入岭回归、皮尔逊相关性分析训练模型并采用10折交叉验证求得最优岭回归参数λ。经求得,最优岭回归参数λ=1×10-6。获得岭回归系数、偏移量及皮尔逊相关系数如表1所示。

表1 岭回归系数及皮尔逊相关系数

表1(续)
将测试集1载入已训练模型,得到岭回归测试集分数(决定系数R2)为0.961,岭回归测试集均方根误差为0.01。数据表明,测试集1在岭回归模型中拟合较好,证明了第1层回归的可靠性。
随后,对得到的各自变量对应的皮尔逊相关系数进行权重分配,权重分配为式(4)。进一步,将训练集2导入已训练的岭回归模型和已权重分配的皮尔逊相关模型,对此将得到集成岭回归及相关性的训练集,如图4所示。其表示第1层回归(岭回归)的输出,将相关系数预测值作为辅助预测特征(列),同时也是第2层回归(Lasso回归)的输入。

图4 集成岭回归与相关性的数据集
为确切地拟合真实值,将集成岭回归及相关性的训练集导入Lasso回归模型并使用10折交叉验证得到最优Lasso回归参数λ=1×10-5。在此基础上,将测试集2导入已训练的岭回归模型和已权重分配的皮尔逊相关系数生成集成岭回归及相关性的测试集,后将其载入Lasso回归模型,以评估Lasso回归模型。经过上述步骤,得到的Lasso回归系数为[1.002 3,5.8×10-4],偏移量为0.000 41。Lasso回归测试集分数、均方根误差分别为0.972、0.01。数据表明,测试集2在Lasso回归中拟合较好,证明了第2层回归的可靠性。
建立可靠的模型后,为验证整体模型预测插补效果,使用残缺数据集用以比较不同缺失率、不同插补方法下各评估指标情况。
利用KNN插补法、Lasso回归插补法及基于Lasso回归及模型修正的双重回归缺失值插补方法(以下简称为双重回归插补法),对模拟缺失数据(残缺数据集)进行预测,并针对不同缺失率(4%、10%和20%)比较各方法在评估指标下的插补效果,如表2所示。表2中的数据皆为经过多次验证后的平均数,且各模型参数已由K折交叉验证取得最优参数,其中Lasso回归插补法参数λ=1×10-5,KNN插补法参数neighbors=5。
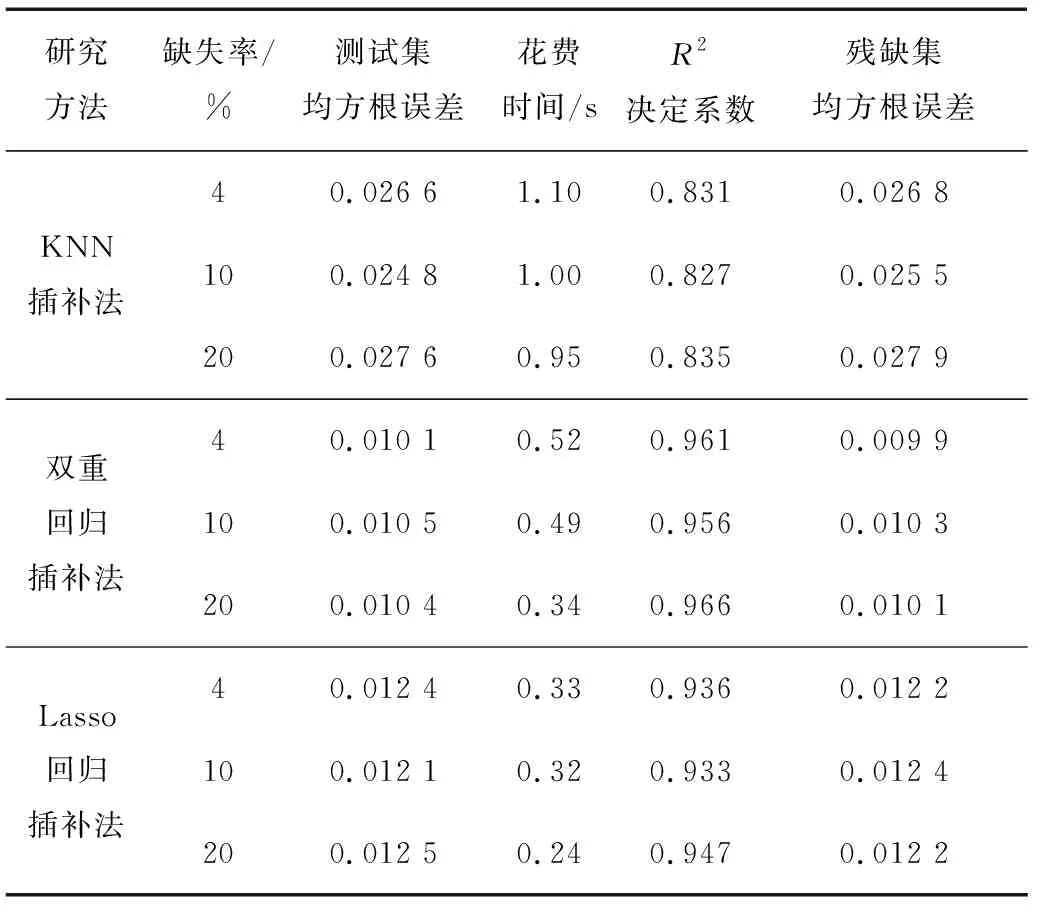
表2 各缺失率下研究方法及评估指标情况
由表2可知,双重回归插补法与单一Lasso回归插补法在各评价指标中相对于KNN插补法均有着不错的效果,可能由于数据的无规律性及空间距离的复杂性导致了KNN插补法效果较差。单一Lasso回归插补法凭借其模型简单,在时间复杂度上优于双重回归插补法,但也由此存在着相比于双重回归插补法更大的均方根误差、更小的决定系数。
以4%缺失率为例,3种方法预测插补如图5~图7所示。
由图5~图7可以知道,以4%缺失率为例,双重回归插补法略优于Lasso回归插补法,更胜于KNN插补法,但是依旧出现部分点略有偏离的情况。

图5 4%缺失率下残缺数据集双重回归预测插补图
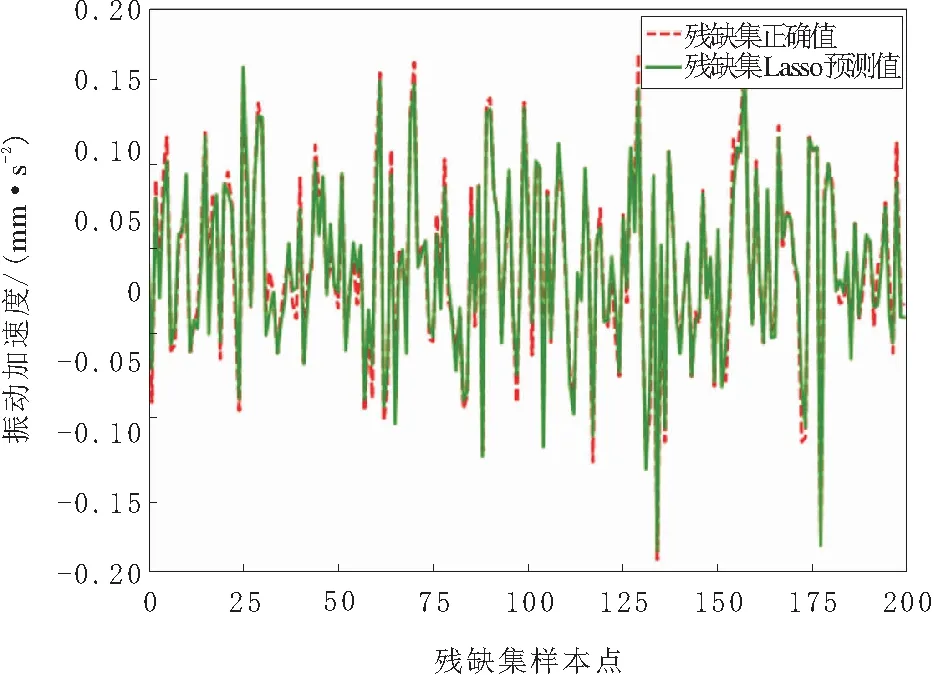
图6 4%缺失率下残缺数据集Lasso回归预测插补图

图7 4%缺失率下残缺数据集KNN插补图
双重回归插补法可以更好地拟合真实值,其建立的模型泛化能力较强,预测插补值与真实值相等或者接近,能够为后续的处理提供可靠保障。
5 结束语
本文提出了一种基于Lasso回归及模型修正的双重回归缺失值插补方法,并使用KNN插补法、Lasso插补法以均方根误差、决定系数、计算时间为评估指标进行横向、纵向对比。结果表明:基于Lasso回归及模型修正的双重回归缺失值插补法略优于Lasso回归插补法,更胜于KNN插补法;在测试集、残缺数据集方面,双重回归插补法有更好的表现,但是依然存在部分预测插补值偏离正确值的情况,若需要完善,可能需要对数据及算法做更深层次的处理。
猜你喜欢
江苏安全生产(2022年9期)2022-11-02
外语学刊(2021年1期)2021-11-04
阅读(低年级)(2019年2期)2019-04-19
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
现代商贸工业(2017年30期)2018-01-22
江苏农业科学(2017年10期)2017-07-21
江苏农业科学(2017年10期)2017-07-21
文理导航·科普童话(2015年6期)2015-07-29
小猕猴学习画刊(2015年2期)2015-01-22
