
基于场景图谱的室内移动机器人目标搜索
2022-10-10 06:04周方波赵怀林刘华平
智能系统学报 2022年5期
周方波,赵怀林,刘华平
(1.上海应用技术大学 电气与电子工程学院,上海 201418; 2.清华大学 计算机科学与技术系,北京 100084;3.清华大学 智能技术与系统国家重点实验室,北京 100084)
近年来,随着在移动机器人定位、建图、路径规划等关键技术上显著性的发展[1],制造出能够在室内环境中执行日常任务的机器人持续受到了研究人员的关注。一般来说,对于服务机器人自主执行“去厨房拿个杯子过来”这一日常任务来说,首先依据环境中的信息来明确自己的位置;其次机器人需要自主移动,并依靠自身携带的视觉传感器识别出物体的类别与位置信息,即需要到达能够检测到杯子的位置。当前国内外研究者们大多在仿真环境中提高机器人对目标搜索的正确率[2-4]。但是在现实场景中,由于环境的复杂,机器人在导航的过程中往往遇到障碍物的阻挡,仅依靠局部的视觉信息,机器人往往无法避开障碍物。当前目标搜索所用的方法大多是采用端到端的学习方法进行的,该方法是在不断试错的基础上实现的,但是实际机器人的试错成本非常高,在实际的机器人运行过程中将带来很大的问题。
人类在寻找一个杯子的时候,并不会盲目地对房间的每个位置都进行探索。人类倾向于回顾以前杯子可能出现在了哪些大型物体旁边,例如桌子、水槽等,并且清楚地知道桌子和水槽这些地标物体的位置。换句话说,人类依靠丰富的搜索经验和对物体位置和关系的常识知识,可以有效地缩小搜索的范围。我们受人类寻找物体的启发,使机器人来模仿这种搜索方式。机器人接收到任务后,首先要思考两个问题:1)目标物体当前可能在哪些位置?2)如何规划路径到达这些位置?例如,机器人在房间中寻找一个苹果,虽然事先并不知道苹果的位置,但是机器人知道桌子和水槽等地标物体的位置,并且苹果出现在桌子的概率比较大,出现在水槽的概率次之,因此机器人可以先到桌子附近寻找苹果,如果找不到,再到水槽旁寻找。
本文提出一种基于场景图谱的室内移动机器人目标搜索方法,可以有效地在室内场景中找到目标,缩短搜索的路径长度。机器人预先建立起包含地标物体位置信息的语义地图,因此对于地标物体,机器人在依靠导航地图情况下,规划一条能够到达该目标物体附近的导航点。本文使用语义关系图谱来表示动态物体与地标物体的并发关系,例如杯子出现在桌子旁的概率比较大。对于动态物体,机器人的搜索策略是从当前位置出发,优先到与目标物体关系强度比较大的地标物体附近寻找,然后逐渐靠近动态物体。
1 相关工作
1.1 基于学习的方法
当前很多导航方法都是使用深度强化学习[5]和模仿学习[6]来训练导航策略。Zhu等[2]提出了目标驱动导航任务,并使用一对共享参数的孪生网络分别提取当前观测的图像信息和目标图像信息的特征,之后使用Asynchronous Advantage Actor-Critic (A3C)强化学习算法[5]进行决策。然而这种端到端的学习方式[3-4],需要机器人学习目标检测,语义先验、避障以及路径规划等一系列能力,尽管在模拟环境中取得了很大的进步,但是仍然无法有效地适应复杂多变的物理环境。在物理环境中,极容易出现机器人因避障能力的缺陷而撞到人或其他物体的情况[7-8],其决策错误的代价是非常昂贵的。
1.2 基于建图的导航方法
经典的导航方法将问题分为两个部分,建图和路径规划,一张几何地图一般是通过同步定位和建图 (simultaneous localization and mapping,SLAM)[9-11]来构建导航地图。一旦环境的地图构建完成,路径规划算法,例如A*[12-13]或者RRT*[14]可以在障碍物存在的情况下来生成一个无碰撞的轨迹到达目标位置。但是这种几何地图只能满足移动机器人避障、路径规划等简单的任务。在机器人智能化操作任务中,不仅需要对所处环境建立几何地图,还要知道地图中物体的语义类别信息。机器人在导航图的基础上构建包含地标物体位置信息的语义地图,机器人可以清楚知道地标物体的位置。
1.3 语义关系图谱
很多研究者们已经注意到了一些物体之间存在着并发(concurrence)关系[15-17],例如遥控器经常出现在电视机旁边,鼠标会在电脑旁边。通过使用这种关系,机器人可以缩小搜索区域,提高目标搜索的效率。Qiu等[17]提出了一种层次物体关系学习方法,通过理解语义上下文的作用来学习目标驱动导航问题。并提出一个上下文向量嵌入到图卷积神经网络中,代替了ResNet[18]表示的图像特征。虽然这种利用物体关系方式能够在一定程度上引导机器人在相关的地标物体旁寻找目标,但是寻找地标物体对于机器人来说依然是个难题,并且机器人面对复杂的现实环境,因导航能力的不足,机器人仍然不知道如何行走。
2 问题描述
针对物体位置的可变性,将房间中的所有物体O={o1,o2,···,on+m}分为地标物体B={b1,b2,···,bn}和动态物体D={d1,d2,···,dm}。地标物体是房间中大型且不易移动位置的物体,例如,冰箱是厨房场景的地标物体,然而床是卧室的地标物体。动态物体的位置因某些原因而发生变化,例如房间中的苹果在桌子和水池旁都有可能出现,这类物体因位置不定和体积较小的原因,相比于地标物体增加了搜索难度。
给定所要寻找的目标物体 ta rget∈O,例如杯子,该任务的目标是使机器人规划一条路径,在这条路径上能以较短的距离发现这个物体。
假定该实验是已知场景,这允许机器人在执行目标搜索任务之前,提前建立辅助地图,包括导航地图Mnav以及语义地图Msem。其中导航地图由若干导航点组成,每个导航点与其相邻导航点之间的距离为0.25 m,在此基础上,机器人不仅可以获得准确的姿态xt∈R3,还可以实现从一个导航点到任意导航点的路径规划。在语义地图中包含了房间中所有地标物体的空间分布。机器人可以获得语义关系图谱 S RGt=(O,E),其中,每一个节点o∈O表示一个物体的类别,每一个边e∈E表示两个物体之间的语义关系值 R el(d,b)∈[0,1]。
3 搜索方法
如图1所示,可以通过交互式界面告诉机器人所要寻找的目标物体 target。当 ta rget∈B时,机器人利用导航地图和语义地图直接到达距离目标物体最近的导航点。当 ta rget∈D时,机器人再结合语义关系图谱,规划出一条最有可能以最短的距离发现目标物体的全局路径。这条路径由机器人的起点、目标物体关系值不为零的地标物体附近的导航点以及终点组成,机器人可以在全局路径中相邻点之间进行局部的路径规划。机器人沿着路径对目标进行搜索的过程中,对局部视野的图像进行目标检测,以便寻找到目标物体。
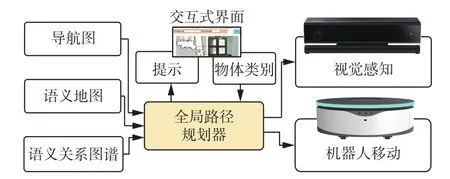
图1 目标搜索整体结构Fig.1 The architecture overview of our proposed navigation method
3.1 导航地图的建立
在物理环境中,SLAM对于移动机器人导航来说是一项基本问题。机器人使用激光雷达和ROS gmapping SLAM软件包构建一个稠密的几何地图。在此基础上,机器人不仅可以获得准确的位置信息,还可以实现从一个位置到另一个位置的路径规划。如图2所示,机器人对每个房间中可行走区域构建了一个稀疏的栅格地图,其栅格的大小为0.25 m。机器人可以到达栅格上的任意点,命名为导航点。在所有导航点的每一条边界上,按照该边界上所有导航点的坐标中位数来选择该边界中间的导航点作为采样点,机器人将在这些采样点上采集图像数据,用于三维语义重建。

图2 导航地图Fig.2 Navigation map
3.2 语义地图的建立
机器人在每个采样点上每隔45°采集该视角的RGB图和深度图,以此来捕获房间的信息。如图3所示,机器人首先针对单个采样点的单个视角进行局部的三维语义重建。机器人可以通过SLAM获取到机器人此刻的姿态xt∈R3, 它代表机器人在导航地图上的坐标和朝向。然后便可将深度图的像素坐标转化为世界坐标,得到点云数据。并通过现有的Mask-RCNN[19]算法预测当前观测的语义类别和掩膜,并映射到点云中。
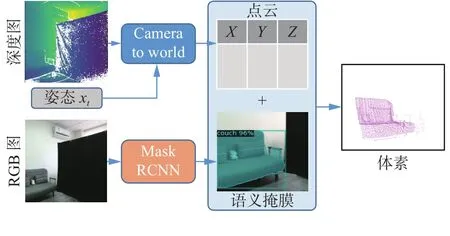
图3 局部3D语义重建Fig.3 Local 3D semantic reconstruction
如图4所示,机器人在每个采样点的每个视角下都进行局部的三维语义重建,为克服单一视角获取环境信息不足的缺点,采用多视角连续性,将多个采样点和视角生成的语义点云整合在一起,完成局部到全局的语义重建。并通过自上而下的投影,机器人可以得到一张带有地标物体信息的语义地图。

图4 全局语义重建Fig.4 Global semantic reconstruction
3.3 语义关系图谱的生成
与文献[17]相同,同样从视觉基因组[20](visual genome,VG)数据集的图像标题中提取动态物体与地标物体之间的关系,但不同的是本文中的关系图谱有明确的值来表示两者之间的关系强度。对于一个动态物体d和地标物体b,其语义关系可以表示为 R el(d,b)∈[0,1],关系值越大,表示两者之间的关系越密切。本文中将在该数据集中任意一个动态物体与某个地标物体在图像标题中同时出现次数与该动态物体出现在图像标题总次数的比值作为该动态物体与该地标物体的关系强度。此外,还对物体的别名进行了合并,例如“cellphone”与“phone”。图5给出了动态物体苹果与其地标物体对应的语义关系图谱。
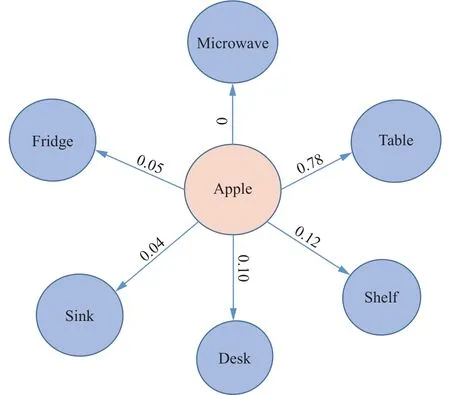
图5 语义关系图谱Fig.5 Semantic relationships graph
3.4 全局路径规划器
给机器人下达任务所要搜寻的目标物体,机器人首先判断该目标物体是地标物体还是动态物体,然后执行相应的步骤。
3.4.1 地标物体寻找
为了方便机器人到达地标物体最近的导航点,机器人在已经建好的语义地图中查询距离该地标物体最近的导航点,以及以何种角度可以观察到物体,这个导航点和对应的角度就是机器人下一步所要先到达的目标点及朝向。机器人的找朝向计算包含以下过程:1)根据目标点(即查询得到的导航点)的位置 (xn,yn),地标物体的位置(xt,yt)得到两点组成的向量a,2)计算向量a与向量(1,0)之间的夹角 θ,即机器人在目标导航点的朝向。
3.4.2 动态物体搜索
对于动态物体的目标搜索,机器人的搜索策略是从当前位置出发,先在地标物体区域进行探索,逐渐靠近可移动物体。机器人通过语义关系图查询与该物体关系最密切的地标物体,并计算导航地图中距离地标物体最近的导航点。机器人依据建立好的导航地图,到达所选择的导航点,左右分别旋转45°,来寻找目标物体。
因为检测速度和节约电量的原因,寻找物体阶段进行目标检测方法并没有用两阶段Mask-RCNN,而是使用一阶段的YOLOv5[21],这种设置在仅使用目标检测方面,其速度和精度相比于Mask RCNN都会有所提高。
虽然在导航点可以看到目标物体,但是由于机器人在导航点有可能并没有真正地靠近目标物体,因此还需要进一步靠近物体。这一步骤首先通过目标检测的方式定位目标物体的边界框,然后利用检测结果中目标物体的边界框坐标计算该物体的中心坐标,再映射到获取的深度图中,计算该物体中心坐标点周围121(11×11)个深度距离的平均值,并将其作为机器人到目标物体的当前距离。
如果机器人到目标物体的距离大于或等于1.2 m,则机器人沿当前朝向前进一步,然后重新获取深度图并更新机器人到目标物体的距离;在本实施例中,机器人的一步是0.1 m。倘若机器人到目标物体的距离依然大于1.2 m,则继续前进。采用这种递归的方式,直至机器人与目标物体的距离小于1 m。
如果寻找不到该目标物体,则走到与该物体关系次密切的地标物体附近的导航点,重复此步骤继续寻找,直到找到该物体或者遍历所有地标物体所对应的导航点。图6给出了移动机器人在寻找动态物体的详细流程图。
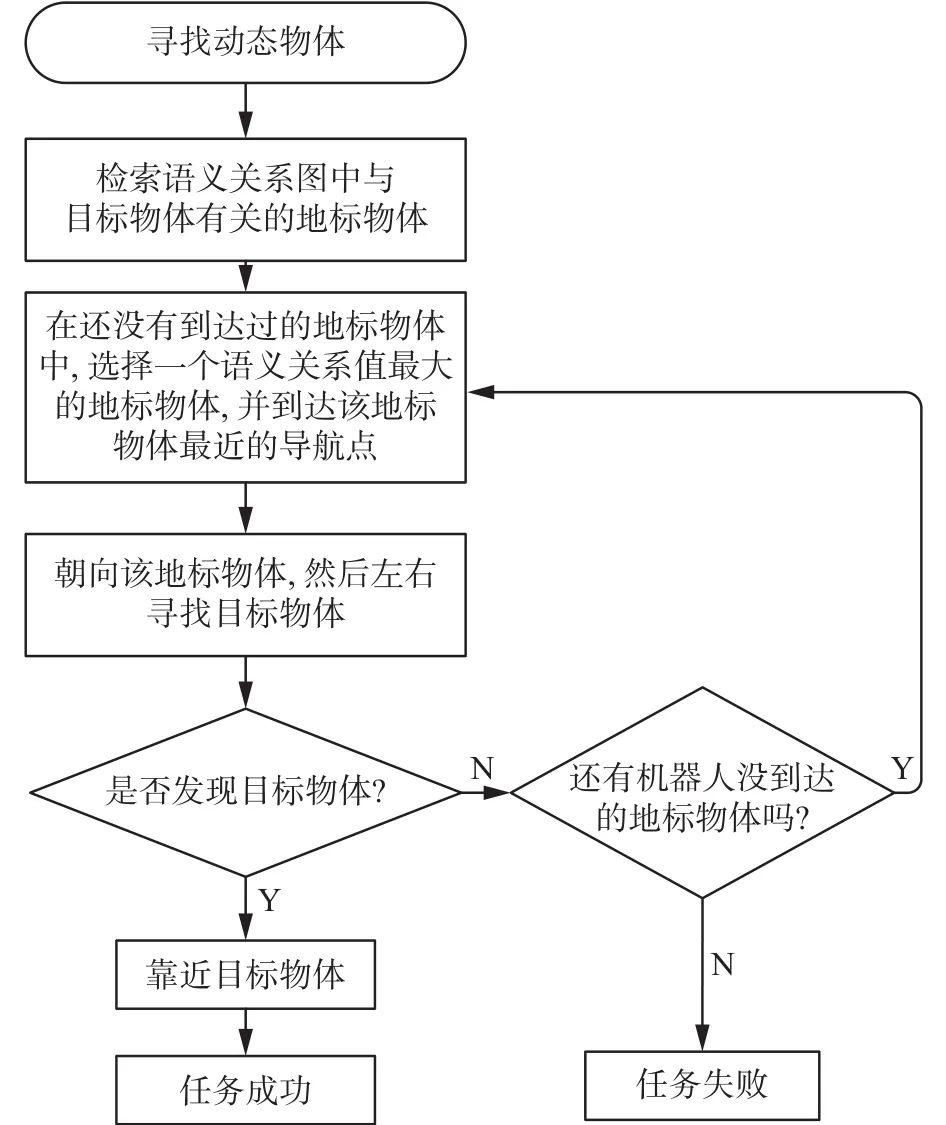
图6 动态物体搜索流程图Fig.6 Dynamic object search flowchart
4 实验与结果分析
为了验证本文提出的室内环境下目标搜索方法的有效性,在一个办公区域构建了一个约60 m3的实验场景,其中包括两个房间和一个卫生间。整个实验环境区域及其导航点如图7所示,此外,还在可导航区域内增加了一个障碍物。在实验过程中,采用的语义分割和目标检测相关配置如表1所示。
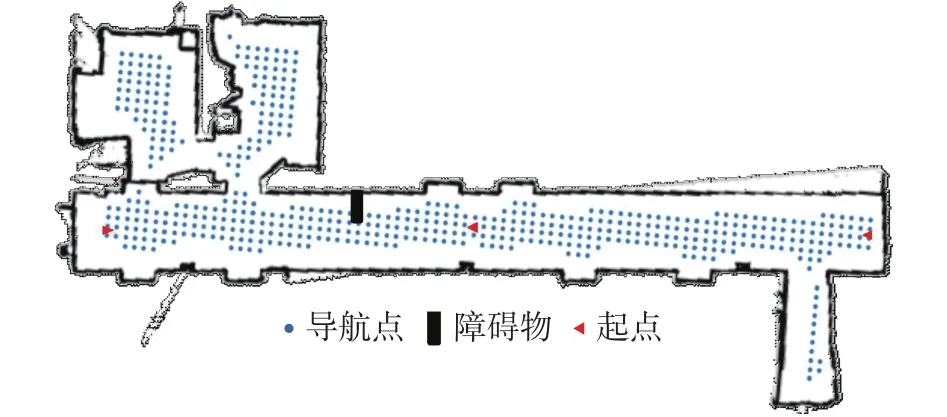
图7 实验场景的全局导航地图Fig.7 Global navigation map of the experimental environment
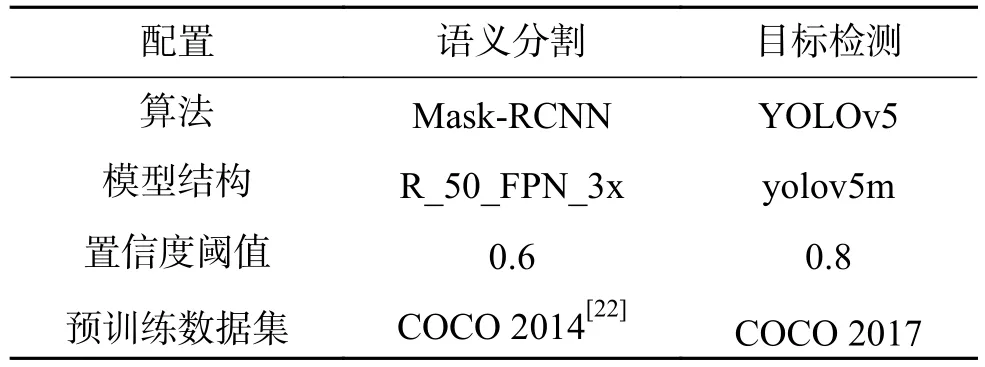
表1 检测平台配置Table 1 Detection platform configuration
4.1 实验场景的语义地图
4.1.1 语义分割结果
根据采集的图像信息,机器人对图像进行了语义分割。如图8给出了机器人从不同角度、不同导航点上采集到的图像信息,经过语义分割后的结果。

图8 语义分割可视化结果Fig.8 Semantic segmentation visualization results
4.1.2 语义地图生成
如图9所示,机器人根据采集的图像信息进行重建语义地图,基本上能够表现地标物体的空间位置分布,地标物体包括冰箱、微波炉、电视机、餐桌、长椅、水池。值得注意的是,由于导航地图为语义地图建立的过程中提供可精确的定位,语义地图中左边的水槽的位置依然能够准确的建立下来。

图9 整个实验场景的语义地图Fig.9 Semantic map of the entire experimental environment
4.2 寻找地标物体
在机器人搜索的实验中,首先进行了寻找地标物体的实验,机器人分别从起点出发沿途绕过障碍物,通过语义地图,机器人可以清楚地知道地标物体的位置,因此,机器人寻找目标物体只需要到达距离目标物体最近的导航点即可。图10给出了机器人在寻找地标物体的路线,以及机器人局部视野。在寻找电视机的过程中,机器人穿过两道打开的门,迅速地找到了电视机。在寻找长椅和微波炉的过程中,机器人可以绕过障碍物,达到目标位置。

图10 地标物体的寻找Fig.10 Look for landmark objects
4.3 寻找动态物体
参考按照语义关系图中地标物体与动态物体关系图谱进行了物体的摆放,我们将遥控器放置在电视机旁,泰迪熊放在长椅上,并将杯子分别放置在餐桌和水池上。对于微波炉和冰箱这种容器类物体,虽然需要打开容器,寻找目标物体,但是机器人并不具备操作的能力,仅考虑位于表面的物体。
为了验证提出方法的有效性,本文中设置了以下3种目标搜索方法:
方法1导航地图:机器人随机地选择导航点对目标物体进行寻找,并可以使用导航地图进行局部路径规划和避障,直到找到了目标物体;
方法2导航地图+语义地图:机器人在导航地图的基础上,每次随机地选择到达还没到达过的地标物体附近;
方法3导航地图+语义地图+语义关系图谱:机器人使用完整的目标搜索框架,机器人优先到语义关系图谱里与目标物体关系值最大的地标物体旁寻找。
为了保证实验数据的客观性,执行每项目标搜索任务,机器人都会分别从3个不同的起点出发,并将路线长度的平均值作为寻找该物体的路径长度。由表2中数据可得,在机器人盲目地随机选择导航点寻找目标的情况下,其消耗的路径长度是最长的,平均路径长度达到了305.97m。在语义地图的帮助下,机器人倾向于到地标物体旁边寻找目标物体,相比于方法1,平均路径长度降低了81.2%。方法3中,在语义关系图谱的帮助下,机器人先到最有可能出现目标物体的地标物体旁寻找,再次降低了搜索的路径长度,平均搜索的路径长度仅为22.06 m。
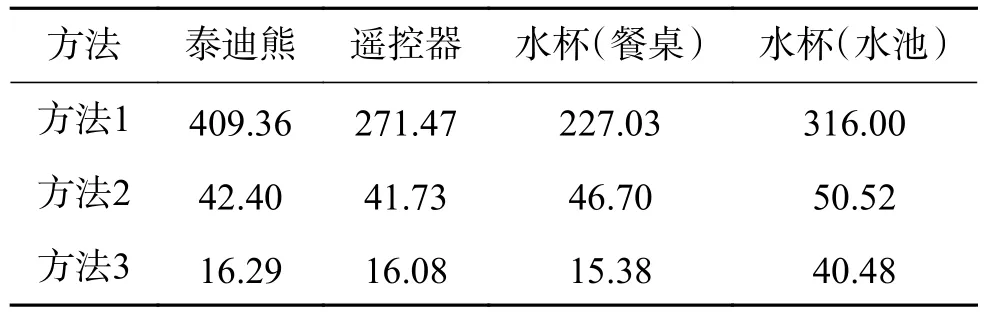
表2 不同方法的路径长度比较Table 2 Comparison of different methods of path length m
图11给出了机器人寻找动态物体的路径。在寻找泰迪熊和杯子的过程中,机器人首先会到与目标物体最近的物体旁寻找。然而,在第二次寻找杯子的过程中,移动了杯子的位置,将杯子放置在了水槽中。机器人在桌子上没有发现杯子后,便直接到水槽旁寻找,最终在水槽旁寻找到杯子。
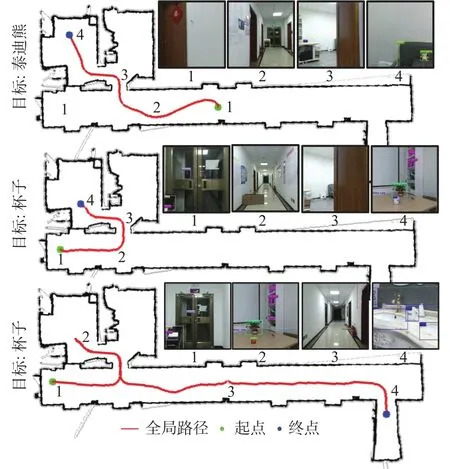
图11 动态物体的寻找Fig.11 Look for dynamic objects
5 结束语
本文针对室内环境下的目标搜索问题进行了研究,受人类寻找在房间中寻找物体过程的启发,设计了一种结合导航地图、语义地图、语义关系图谱目标搜索框架。实验表明,该框架能够有效地缩短机器人搜索范围,寻找到地标物体和动态物体。本方法尚存在的缺点是仅能对未被遮挡的物体进行寻找,对于藏在容器内的物体,例如在冰箱内的苹果等,需要机器人打开冰箱的操作,才能看到目标。在未来的工作中,将加强机器人对环境的交互能力,例如打开冰箱,拿起苹果。
猜你喜欢
少先队活动(2020年12期)2021-01-14
开放教育研究(2020年2期)2020-03-31
中学生数理化·高一版(2020年1期)2020-02-20
中学生数理化·八年级物理人教版(2018年10期)2018-12-06
中成药(2017年3期)2017-05-17
中国社会历史评论(2016年2期)2016-06-27
领导科学论坛(2016年9期)2016-06-05
现代语文(2016年21期)2016-05-25
长江学术(2016年4期)2016-03-11
科普童话·百科探秘(2015年4期)2015-05-14
