
基于多层次特征的RoQ 隐蔽攻击无监督检测方法
2022-10-09 12:48:56赵静李俊龙春万巍魏金侠陈凯
通信学报 2022年9期
赵静,李俊,龙春,万巍,魏金侠,陈凯
(1.中国科学院计算机网络信息中心,北京 100083;2.中国科学院大学计算机科学与技术学院,北京 100049)
0 引言
随着当前网络安全防护方法和能力的升级,拒绝服务(DoS,denial of service)等常见攻击已可以被轻松识别。然而,一类新的隐蔽攻击悄然而生,即降质(RoQ,reduction of quality)攻击。与传统DoS 相比,RoQ 攻击的原则不再是使目标系统完全丧失对正常请求的服务能力,而是利用互联网广泛采用的确保网络公平性、稳定性的自适应机制,通过周期性地在短暂间隔内突发攻击数据包,降低目标主机的服务质量。这种攻击流量与正常流量几乎没有区别,很容易绕过常规的入侵检测系统。
具体分析,RoQ 攻击主要有以下特点。
1) 从流量特点上看,RoQ 攻击呈现出脉冲式的特征。在一个攻击周期中,只有大约的时间存在攻击流量。因此,RoQ 攻击也称为脉冲式隐蔽攻击[1]。
2) 从攻击方式上看,RoQ 攻击广泛分布的攻击者在目标路由器的末端聚合攻击流量,使攻击流量的分布在整个网络中更加分散,平均流量更低。
3) 从攻击行为上看,RoQ 攻击可以使用从网络层到应用层的任何协议合法流量,与普通应用具有相同的行为特征,能够完全隐藏在海量网络流量中。
4) 从攻击目的上看,RoQ 攻击主要是为了使系统运行速度减慢,服务质量下降。因此,大部分网络管理员往往将此类情况归因于系统故障或网络线路故障,忽略了攻击的可能性而导致处理延后。
仅利用流特征不能完全准确地区分RoQ 攻击流量和正常流量。但是,从包特征上看,异常流量整体分布的形态差异与正常流量相比具有一定的区分度(例如,将两段不同的流量从时域转换到频域,就能发现其中的不同)。因此,利用时序特征对这类攻击进行检测更合适。再者,真实环境中RoQ 攻击样本稀少,且每次攻击都具有独立性、特殊性,不容易使用监督学习方法来学习隐蔽的攻击特征。因此,要求检测方法在零先验知识或极少先验知识的情况下发挥作用。综上,本文在完成大量攻击试验,并梳理RoQ 攻击相关特征之后,提出了一种基于多层次特征的RoQ 隐蔽攻击无监督检测方法,主要创新点如下。
1) 提出了基于多层次特征的RoQ 隐蔽攻击检测的两阶段方法。根据目标在不同阶段使用不同层面的特征,整体上达到了较好的效果。
2) 为了筛除大部分正常流量,减少对后续结果的干扰,研究了基于正样本监督信息的半监督谱聚类方法。利用流特征,构造少量正样本监督信息以修正样本中偏离过大的离群点。同时构造标签损失算法来评价算法损失度以便调整参数,使筛除正样本的准确率接近100%。
3) 考虑到RoQ 攻击流量特征不明显,为了提高检测率,将经典Shapelet 时间序列算法修改为多维算法,利用流量时序包特征构造了最具辨识度的n-Shapelet 基序列空间。经过空间投影后的特征能够最大限度体现相似序列差别最大的局部特征,提高了RoQ 攻击特征的识别率。
4) 考虑到RoQ 攻击样本稀少无法训练检测模型但仍需实现高精度检测,构造了无监督分类优化模型。该模型能够根据检测结果多次迭代直至收敛到最优解,实现了无学习样本的高精度检测。
1 相关工作
一直以来,很多研究者着重研究RoQ 攻击如何绕过检测系统,以期更好地解决RoQ 攻击检测问题。Guirguis 等[2]最早提出了一种利用TCP 协议的低速率拒绝服务攻击,这种攻击没有明显的异常特征,利用传输控制协议(TCP,transmission control protocol)中自适应机制造成信道阻塞,从而达到攻击目的。紧接着,Luo[3]介绍了一种短时间内阻塞链路的脉冲式拒绝服务攻击;Guirguis 等[1,4]提出了利用动态负载均衡机制的RoQ 攻击和针对内容自适应机制的脉冲式攻击。近几年的主要研究包括利用KeepAlive 机制占满服务器等待队列的攻击[5]、强效的Shrew 变种FB-Shrew 攻击[6]、利用物联网设备之间消息队列遥测传输(MQTT,message queuing telemetry trandport)协议漏洞的攻击[7]、隐蔽漏洞扫描等其他脉冲探测类攻击[8]。总体来讲,RoQ 攻击隐匿性高,缺乏已知样本,是一种极难发现的新型攻击。
现有针对RoQ 隐蔽攻击的检测方法大致可以分为基于信号处理、基于统计分析、基于数据建模及基于人工智能技术这4 种类型。
基于信号处理的检测方法是最常用的,其核心思想是将流量时域特征转换成频域,来增加正常流量和异常流量的区分度。Chen 等[9]采用了2 个新的频域特征:傅里叶功率谱熵(FPSE,Fourier power spectral entropy)和小波功率谱熵(WPSE,wavelet power spectrum entropy),提高了检测率。Agrawal等[10]将流量从时域变换到频域上,通过功率频谱分布判断攻击。基于信号处理的检测方法能够从一定程度上检测出RoQ 攻击,但是在检测深度伪装、特征不明显的攻击时效果不佳。
基于统计分析的检测方法根据流量偏离正常状态的特征行为来进行识别。吴志军等[11]根据低速率拒绝服务(LDoS,low-rate denial of service)攻击周期性的小信号特征构造出特征值估计矩阵来判断是否发生了攻击。Tang 等[12]提出了一种自适应指数加权移动平均算法,根据加权值的变化检测攻击。在之后的研究中又基于脉冲流量离散特性提出一种新的统计方法来进行检测[13]。为了进一步提高检测率,Tang 等[14]提出利用用户数据报协议(UDP,user datagram protocol)流量与传输控制协议(TCP,transmission control protocol)流量的比值(UTR,ratio of UDP traffic to TCP traffic)能够更准确区分攻击流量和正常流量。基于统计分析的检测方法在设立阈值的过程中需要大量的专业领域知识和工程技能,烦琐复杂,很难大规模使用。
基于数学建模的检测方法是利用数据方法对网络流量进行分析,区分出正常流量中的隐蔽RoQ攻击。如Wu 等[15]研究了RoQ 攻击对网络流量的多重分形特性的影响,提出了MF-DFA(multifractal detrended fluctuation analysis)算法,计算正常情况和攻击情况下的网络流量Hölder 指数的差值来判断是否发生了攻击。
考虑到隐蔽RoQ 攻击的特征提取困难,一些研究者开始考虑使用人工智能技术。例如,Koay 等[16]基于熵特征集成了循环神经网络、多层感知网络、交替决策树3 个分类器形成投票系统,共同判断流量异常。Tang 等[17]基于SADBSCAN(self-adaptive density-based spatial clustering of applications with noise)算法提出了在多密度数据集中自适应识别聚类的解决方案。根据网络流量受到RoQ 攻击的特点,对网络流量进行分组。然后使用余弦相似度来确定每个组中是否包含攻击数据。特征工程是基于人工智能技术的检测方法中重要的一环,为了提高攻击检测率,Tang 等[18]提取了RoQ 攻击中包括信息熵在内的28 个特征,并提出改进的MF-Adaboost算法,能够更准确地检测RoQ 攻击。吴志军团队近几年着重研究了利用路由器队列管理机制漏洞的RoQ 攻击的检测方法。2018 年,吴志军等[19]提取了路由器瞬时队列和平均队列作为数据特征,利用核主成分分析(KPCA,kernel principal component analysis)进行特征处理,并利用反向传播(BP,back propagation)神经网络进行训练和检测,效果较好。2020 年,该团队[20]提出了基于序列确认号(ACK,acknowledge number)、报文大小和队列长度的多特征融合的路由器降质攻击检测方法。每种特征分别输入K 邻近(KNN,K-nearest neighbor)分类器得到综合的决策轮廓矩阵,并定义融合决策指标D 作为检测RoQ 攻击的依据,在一定程度上提高了检测率。利用路由器漏洞的攻击属于众多RoQ 攻击的一种,在检测时比较容易提取路由器队列特征。而传输层和应用层的攻击因流量特征与正常流量区别很小,很难提取有效特征,隐蔽性很强。
综上,现有RoQ 攻击检测方法大部分假阴性率较高,仅适用于小规模数据,或只能在仿真集中实现,在真实环境中应用有一定的局限性。目前,基于人工智能技术的检测方法研究进展较慢、实用性不强。大部分方法在训练模型时需要大量已知的训练样本支撑,这与缺少真实样本的现实情况相悖。其次,部分研究中的实验是基于NS2 等模拟软件的,实验条件理想、数据单一,不具有说服力。此外,目前大部分研究没有考虑到RoQ 攻击的伪装性,在海量流量中的识别性较差。
2 基础知识
2.1 谱聚类
谱聚类是一种聚类算法,相较于传统聚类算法,它对数据分布的适应性更强,聚类效果更好,计算量更小,在攻击检测中常常被用作聚类算法[21]。在对相似攻击行为的聚类方面,谱聚类比K-means、(DBSCAN,density-based spatial clustering of applications with noise)等聚类算法轮廓系数更高,识别效果更好[22]。
谱聚类的主要思想是基于图谱分割理论,主要流程如下。
目标:输入n个数据点集,获得k个聚类。
1) 利用距离公式计算每个点集的相似度,形成相似矩阵。
2) 利用相似矩阵构建邻接矩阵N和度矩阵G。
3) 由步骤2)得到的邻接矩阵N和度矩阵G计算得出拉普拉斯矩阵
4) 选取拉普拉斯矩阵的前k个最大特征值对应的特征向量。
5) 标准化特征向量,形成k×n维特征矩阵。
6) 将特征向量的每一行作为一个k维的样本,共n个样本,使用K-means 等聚类算法进行聚类。
2.2 Shapelet 时间子序列
2009 年,Keogh 等[23]在数据挖掘顶级会议上首次提出了时序数据中的Shapelet 的概念。Shapelet 是时间序列的子序列,是相似时间序列中最不相同的一段序列,在区分相似度很高的序列方面稳健性更强,准确性更高。它可以较充分地说明各个类别之间的差异,使分类结果具有更强的可解释性。
Shapelet 子序列各概念定义如下。
定义 1时间序列及子序列。时间序列是按时间顺序采样的数据点构成的序列,t i(i∈1,2,…,n)是任意实数。子序列是从某一位置开始、长度为k的一段连续序列,
定义2时间序列的距离。将长度为m的2 条时间序列看作向量,它们之间的距离
定义3子序列和时间序列的距离。对于长度不同的子序列S和时间序列T,距离定义为S与T中长度与S相同的子序列的距离的最小值,即表示T中长度与S相同的所有子序列。
定义4信息增益。设数据集D被划分为数据子集D1和D2,则其信息增益可表示为

其中,n、n1和n2分别表示数据集D、D1和D2的大小。E(D) 表示D的熵,表示为
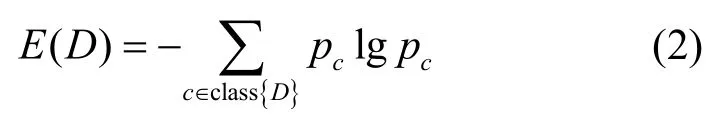
其中,pc表示属于数据集D的元素c的概率。
定义5Shapelet 子序列。定义分裂点为一个二元组 <S,δ>,由子序列S和距离阈值δ组成,根据S与数据集中每一条时间序列之间的距离是否大于δ,将时间序列数据D分为DL和DR,当信息增益最大时即Shapelet,此时的距离阈值
Shapelet 子序列在网络安全领域是一个较新的概念,但是已经在其他领域被用于时序异常检测和预测[24-25]。在现有的研究中,Shapelet 可以与图论[26]或神经网络[27]结合完成分类。
3 RoQ 隐蔽攻击无监督检测模型总体框架
本文提出的RoQ 隐蔽攻击无监督检测模型包含2 个阶段,分别使用了不同层面的流量特征。首先,利用流特征对流量进行初筛,筛除大量可能会干扰检测效果的正常流量,保留正常流量与异常流量相对均衡的样本。因此,要求筛选速度快、效率高,且筛除的正常流量的精确率接近100%。其次,利用时序包特征,在没有先验知识的情况下,对筛选后的流量进行无监督精准分类,要求分类模型具有局部特征差异的辨识能力。RoQ 隐蔽攻击检测模型整体框架如图1 所示。其中,网络流量通过数据平面开发套件(DPDK,data plane development kit)进行采集过滤,进入后续处理流程。

图1 RoQ 隐蔽攻击检测模型整体框架
第一阶段为基于流的聚类检测算法,主要实现大量正常流量的筛除。该阶段的输入是去噪声、去冗余格式化后经过特征提取后的网络流特征,核心算法为改进的半监督谱聚类算法。为了提高正样本分类的精确度,利用极少数已知的攻击样本构造正样本强化监督信息。同时,为了最大化利用这些已知攻击样本,使谱聚类算法有最优的迭代次数限制,设计基于极少已知标签的算法调整机制,根据调整机制评价结果调整参数和聚类次数。
第二阶段为基于n-Shapelet 子序列的无监督自学习算法,主要实现剩余流量的准确分类。该阶段的输入是按时间排列的数据包,称为时间包序列。首先,利用Shapelet 子序列的特点构造Shapelet 序列空间,该空间代表了样本间差距最大的局部特征。其次,将每一个时间包序列映射到Shapelet 序列空间内,转换为S空间特征,使用聚类算法进行聚类。为了使分类结果更准确,构造无监督目标优化函数来调整算法参数。
4 基于流的聚类检测算法
通常,距离比较远的数据被认为是不同类的,而距离较近的数据则是同类的。但在一些特殊情况下,存在一些距离较大但属于不同类的、或者距离较小但属于同类的离群点需要被修正。因此,本节提出一种基于半监督谱聚类的正常流量筛除方法,尽可能保证筛除的正常流量的精确度接近100%。在具体方法上包括3 个部分:正样本强化监督信息构造主要实现去除正样本侧的离群点;半监督谱聚类算法主要实现数据流的聚类;基于极少已知标签的算法调整机制主要实现聚类结果的合理评价。
4.1 正样本强化监督信息构造
构造正样本强化监督信息对,包括距离很大的正样本信息对、正样本与其他类型样本距离很小的信息对。具体方法如下。
1) 关注的正常类别。初始化监督信息限制数目M,集合A为空,利用简单专家知识规则在Qint中确定一定数量的正样本,加入集合S中;初始化当前监督信息数目m=0 。
重复步骤2)和步骤3),完成正样本监督信息集构造。监督信息集包括2 个集合,集合1 中都为正样本,但彼此距离较远;集合2 中一个为正样本,另一个为其他类型样本,但距离很近。
4.2 半监督谱聚类算法
本文提出的改进后的半监督谱聚类算法具有对正样本修正的能力,具体算法R如下。
4) 选取P矩阵最小e个特征值对应的特征向量组成特征矩阵F,对F进行标准化后再聚类,得到聚类结果为正样本的类别。
4.3 基于极少已知标签的算法调整机制
基于半监督谱聚类算法通过监督信息消除了正样本侧的离群点,提高了分类的精度。在聚类过程中,数据集带有极少已知的标签信息。为了提高这部分信息的利用程度,得到更精确的聚类分配结果,使算法结果可评价,收敛速度可控,本文提出基于极少已知标签的算法调整机制。
首先,定义p(yi,q)为样本yi与类别q的相似度,也可以看作样本yi属于类别q的概率。

算法调整机制具体方法如下。
1) 对数据集使用算法R进行首次聚类,得到聚类结果,统计每类结果中标签数据量最大的那一类作为该类的标签c。对于已知标签的部分样本经过聚类后被划分为代表不同的类别,*为任意整数。
2) 使用标记列表A′标记正样本点的划分正确与否,标记列表A′中元素ai的含义为

则已知标签的正样本聚类损失为
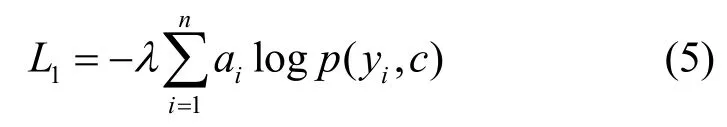
3) 使用标记列表B′标记负样本点的划分正确与否,标记列表B′中元素bi的含义为
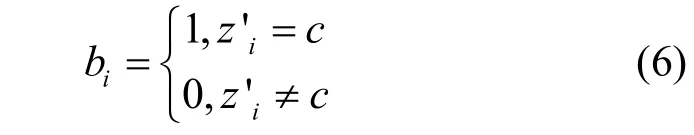
则已知标签的负样本聚类损失为
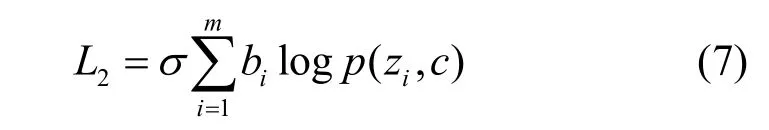
则整体损失为
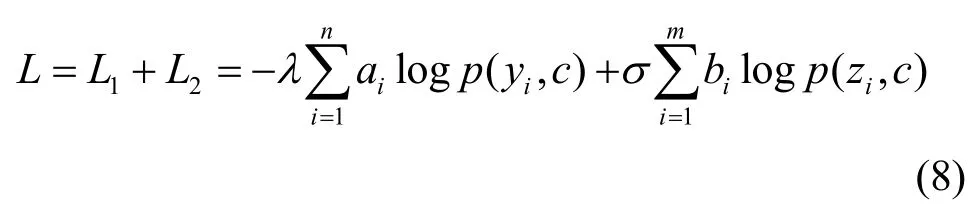
5 基于n-Shapelet 子序列的无监督自学习算法
第一阶段的初步分类旨在精准地筛除大部分正常样本,第二阶段将完成更准确的分类。不同于第一阶段基于流特征的方法,第二阶段将剩余的流还原成数据包,按照时间顺序排列形成时间序列,一条流表示为
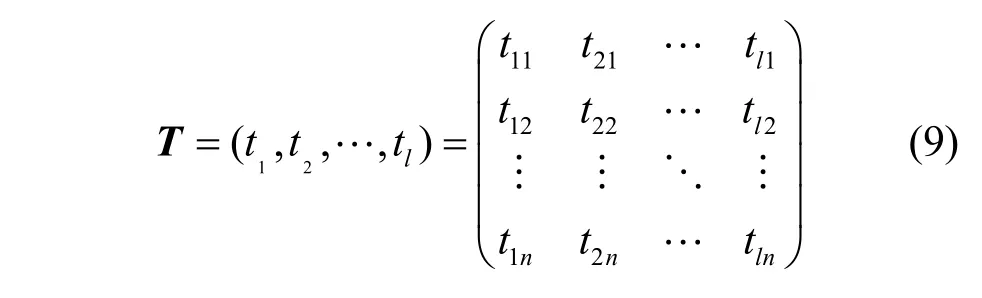
其中,l表示时间序列的长度,n表示每一个数据包的特征维度。
5.1 Shapelet 空间特征映射
为了找到局部更具有区分度的特征,本节利用Shapelet 子序列完成特征提取。在待检测的流量中寻找到时序包序列中的若干个最优Shapelet,构成S空间。将时间包序列投影到新空间,转换为新特征再进行检测。
根据Shapelet 定义[23],n维包序列的Shapelet子序列表示为

其中,k(k<l) 为Shapelet 子序列的长度,子序列的每个元素保持n个维度,用于表示序列短时间内(即长度k内)在所有维度上的综合变化特征。选取若干个 Shapelet 子序列,构造 S 空间为
定义时间序列T与子序列S的距离为

为了方便后续的最小化求解,距离函数连续化为


至此,原始包序列各特征投影到新空间形成新的特征矩阵X,新特征是在不同Shapelet 子序列上的投影,具有最佳辨识度,可以使用聚类算法对X进行聚类。
5.2 无监督分类优化模型
S空间的Shapelet 子序列可以最大程度地学到各个时间序列的最大区分局部特征,因此,需保证各个Shapelet 子序列的相似度最低。定义Shapelet相似度矩阵表示为

X经过聚类之后得到分类结果Y,并根据分类优化函数对参数W和S进行迭代优化,迭代过程如下。
1)Y的迭代
根据分类优化函数中的第1 项
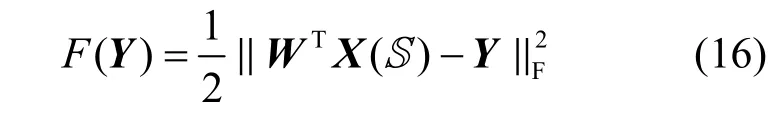
对Y求导并令其为0,有

2)W的迭代
根据分类优化函数中的第1 项和第3 项

对W求导并令其为0,有
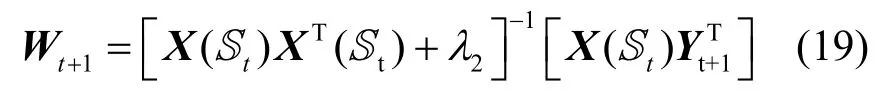
3)S的迭代
根据分类优化函数中的第1 项和第2 项
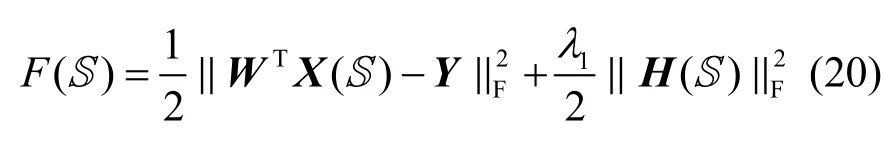

其中,c为类别数目。
将W、Y、X、H代入F(S),展开得

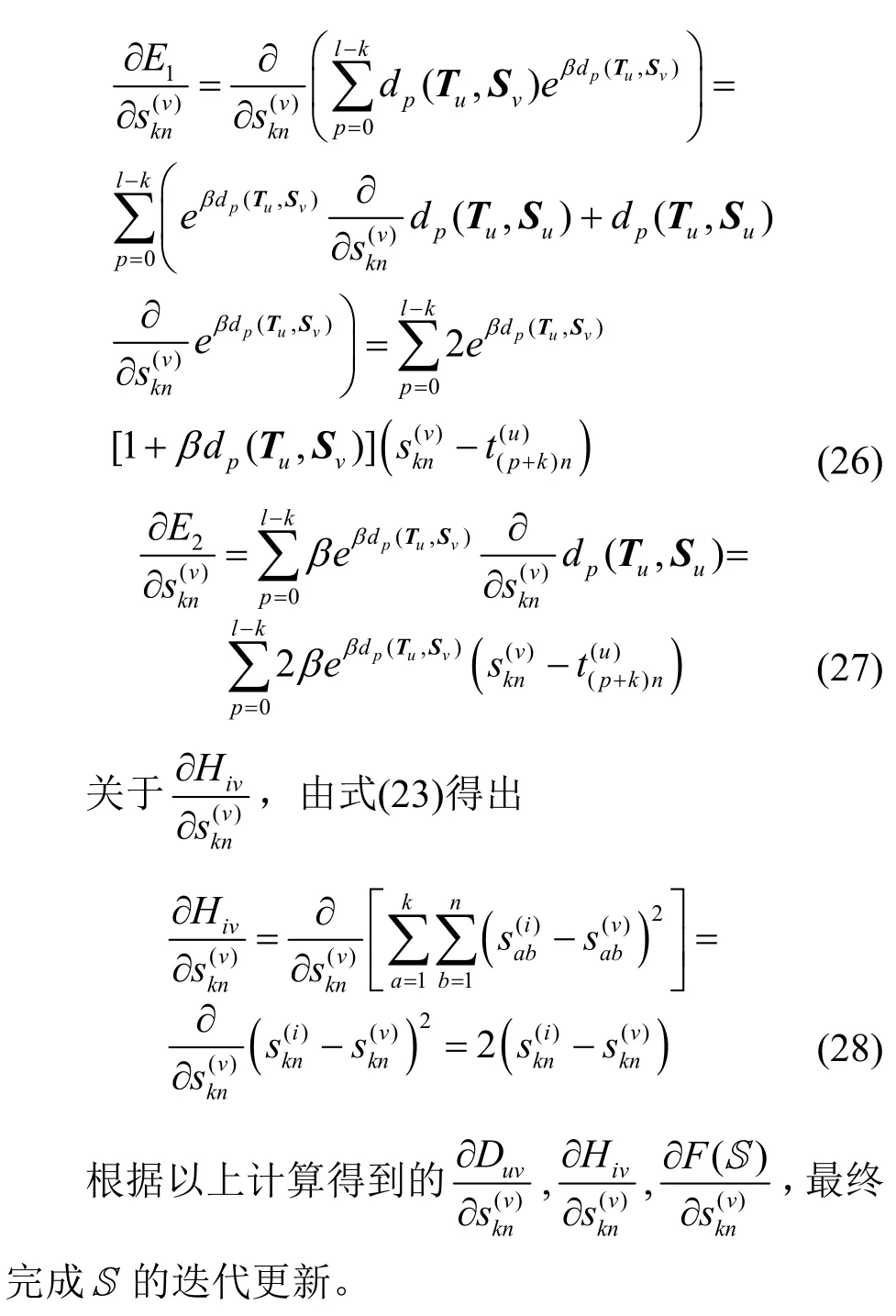
5.3 时间复杂度评估
在无监督学习和推理过程中,经过参数的初始化后,目标函数需要多次迭代直至收敛。每次迭代过程都包括2 个矩阵的计算阶段以及3 个参数矩阵的更新阶段。根据5.2 节的定义,包序列数据集,一条时间序列T长度为l,每个包有n维特征;S空间Shapelet 子序列长度为k,大小为v;聚类类别为K。那么,在矩阵X,H的计算阶段,根据式(13)和式(14)可得计算X的时间复杂度为O(uvkln),计算H的时间复杂度为O(v2kn)。在参数矩阵(Y,W,S)的更新阶段,根据式(16)可得更新参数矩阵Y的时间复杂度为O(Kuv),根据式(18)可得更新参数矩阵W的时间复杂度为O(v2u+vuK+v2K+v3),根据式(24)~式(28)可得更新参数矩阵的时间复杂度为O(uvlk2n2K+v2kn)。因此,无监督聚类算法的总体时间复杂度为O(I(uvkln+v2kn+Kuv+v2u+v2K+v3+uvlk2n2K)),I是迭代次数,又因为参数中k≪l,v≪u,K≪u,因此,时间复杂度可表示为O(I(uln2))。
6 实验分析
6.1 实验环境及数据说明
由于目前开源数据集中没有TCP 拥塞控制等攻击样本,且在真实网络数据中也较难捕捉到这类攻击,因此,实验搭建了简单的模拟环境,模拟部分攻击来采集攻击数据。实验环境配置如表1 所示。

表1 实验环境配置
为了从不同角度验证本文方法的合理性,实验基于模拟场景使用开源数据集,模拟攻击流量和真实网络流量构造了多种数据集。攻击类型覆盖了利用HTTP 自适应机制的攻击、新型隐蔽攻击、逃避攻击等多种组合。
本文实验中使用的部分开源数据集来自ISCX-SlowDoS-2016[5]、CIC-DDoS-2019[28]、CIRA-CIC-DoHBrw-2020[29],详细描述如表2 所示。ISCX-SlowDoS-2016 数据集包含了应用层各种DoS攻击,包含大量的应用层的小容量隐蔽攻击。CIC-DDoS-2019 数据集中包含了WebDoS、Port Scan 等多源的DDoS 变种隐蔽攻击。CIRA-CICDoHBrw-2020 中的恶意流量包含了针对网站的隐蔽攻击样本。这3 个数据集均提供了原始的包捕获文件(.pcap 文件),数据完整。
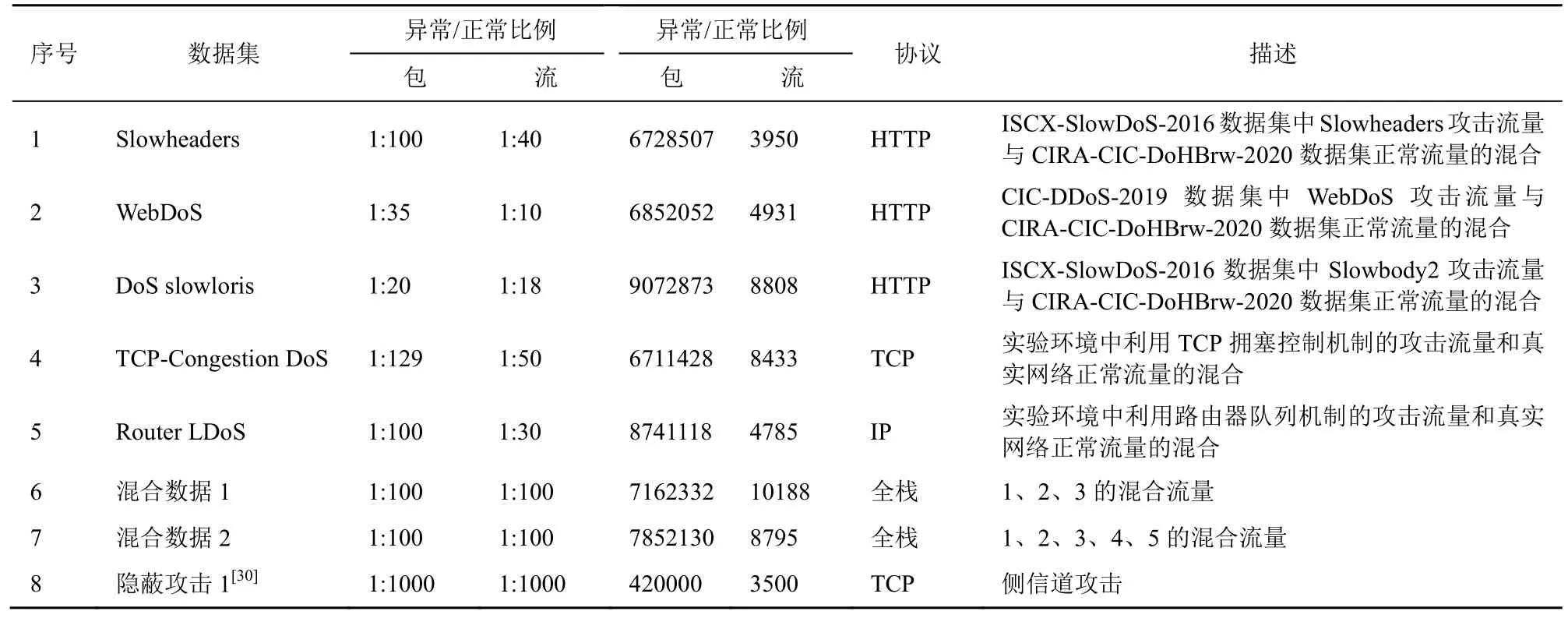
表2 本文实验使用的数据集详情
6.2 特征提取与参数设置
6.2.1 流量特征提取
本文方法在实验过程中需要提取2 个层面的特征。首先是基于流特征的初步筛选,需要在原始流量中提取一段时间内流量的宏观特征。其次是基于时间包序列的精确分类,需要将剩余流量还原成按照时间排列的包序列,提取每一个包的具体特征。流特征和包特征描述分别如表3 和表4所示。

表3 流特征描述

表4 包特征描述
为了能够直观看出多层次特征使用的意义,本文选取部分具有代表性的数值化特征绘制了对比曲线。本文方法第一阶段的正常流量与攻击流量的部分流特征对比如图4 所示,从图4 中可以看出,流特征在正常流量和攻击流量中有明显差异,能够使用聚类算法完成大部分流量的分类。
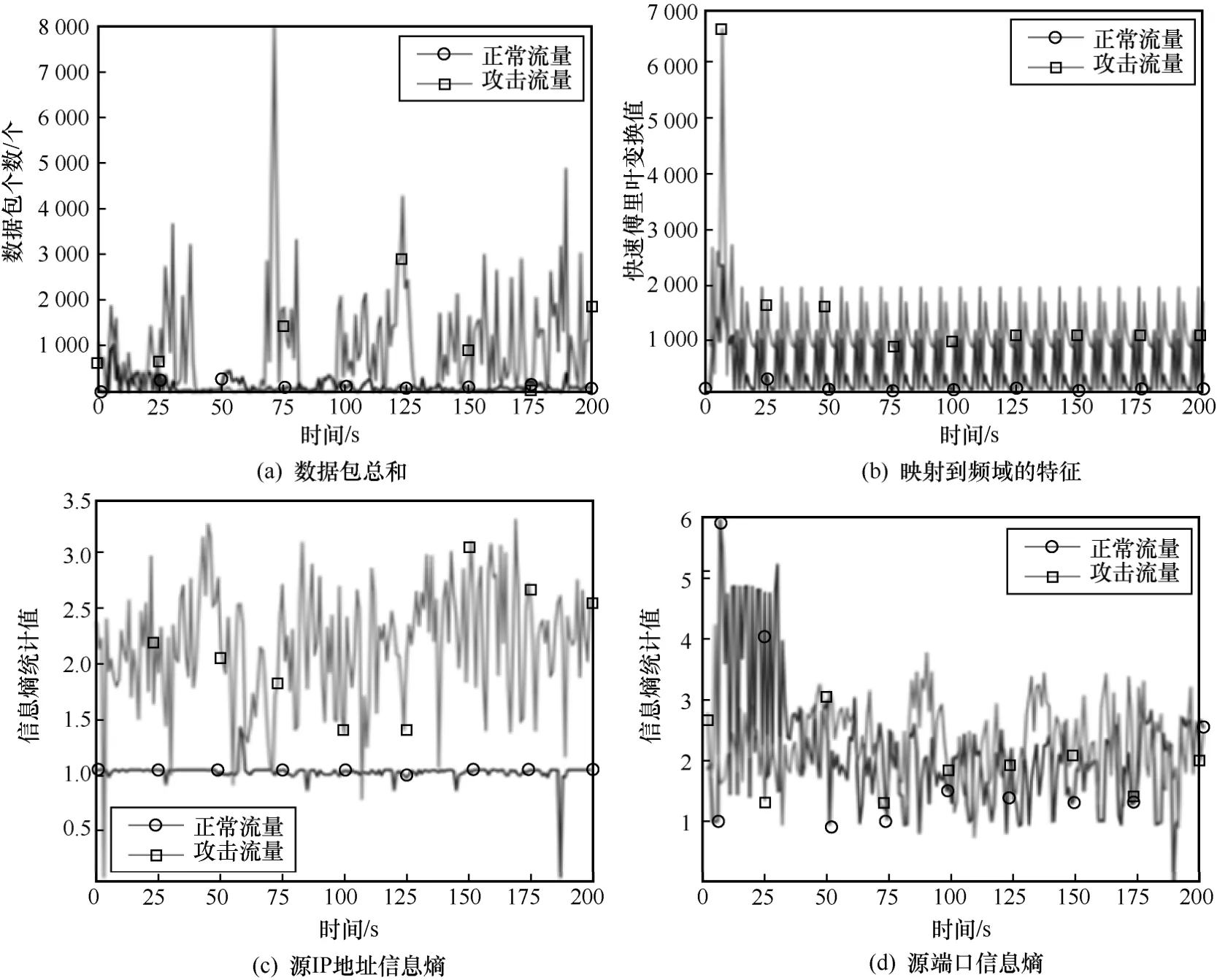
图4 正常流量与异常流量的部分流特征对比
本文方法第2 个阶段的正常流量与攻击流量的部分包特征对比如图5 所示。从图5(a)和图5(b)中可以看出,正常流量和攻击流量的独立的包特征差别较小,很难用可视化的图分辨。从图5(c)中可以看出,正常流量和攻击流量的包的前序包特征有较明显的差别。因此,在这一阶段提取时间序列特征对流量进行分类比较有效。

图5 正常流量与异常流量的部分包特征对比
6.2.2 参数选择
本文方法2 个阶段的算法需要确定超参。在第一阶段中,聚类类别数K与拉普拉斯矩阵的最小特征向量个数e取值一致,均可以根据实验数据集本身的标签获得。监督信息的数量M则通过正样本的聚类纯度P来确定。
监督信息数选择如表5 所示。从表5 中可以看出,有0.5%的监督信息比无监督信息精确率提高了4.4%。为了使实验结果有明显区分度,选择0.5%为增长间隔。当监督信息占比进一步增加至1%时,精确率提升至99.7%。从表5 后两行可以看出,随着监督信息的继续增加,精确率并没有明显提升,当监督信息占比增长至2%时,精确率只比1%时提升了0.1%,回报率低。因此,监督信息占比1%为最佳平衡点,可在尽量少的监督信息下获得尽量高的精确度。

表5 监督信息数选择
第二阶段中,S空间的大小即Shapelet 子序列的长度k和v-S空间中Shapelet 的个数v为待确定的参数,通过聚类纯度P、兰德系数(RI,Rand index)及F1 值确定。
在TCP-Congestion Dos 数据集中,数据的长度范围为100~4 000,参考Zhang 等[31]实验中的参数选择,本文实验分别选取最短序列长度的5%、8%、10%、15%、20%进行对比。需要说明的是,经过前期的实验,当Shapelet 子序列长度k选取5%以下时,信息量过少会影响区分度,因此最短序列长度从5%开始。为了方便实验,选择Shapelet的个数为2,不同Shaplet 长度的性能表现如表6所示。从表6 中可以看出,在k从5%增长到20%的过程中,性能呈现先上升后下降的趋势,可以推断,在TCP-Congestion Dos 数据集中,最具辨识度的k在5%~20%,也说明在这个区间内存在局部最优解。进一步分析,k在10%~15%时P、RI 和F1 值均较高,因此最优的Shapelet 子序列长度应在10%~15%。为了计算方便,后续实验选取最短序列长度的10%为k的最优值。
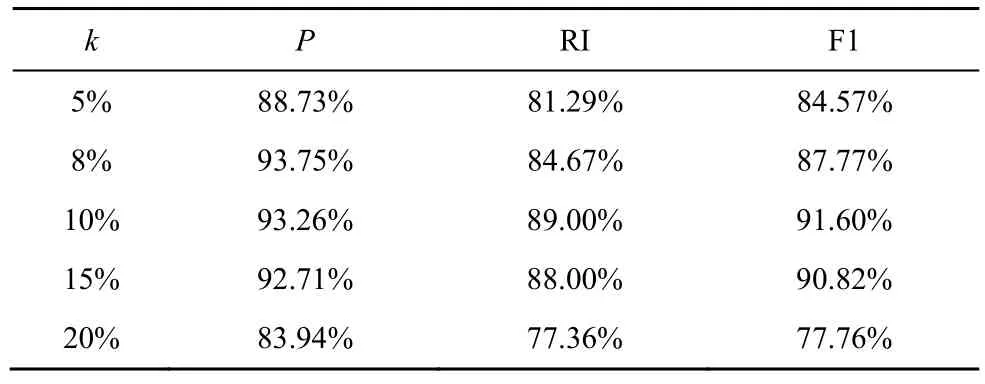
表6 不同Shapelet 长度的性能表现
S空间中Shapelet 的个数v的选择同样重要,v过大会影响计算速度,过小又会使区分度不够明显。因此,实验分别选取v为2、3、4、5、6、7、8,在计算效率可接受的情况下选取最优值。
不同Shapelet 个数的性能表现如表7 所示,从表7 中可以看出,随着v的增加,聚类纯度P总体呈上升趋势,在RI 和F1 值上的表现也相对较好。综合考虑性能和计算速度,v=3 是本文实验的局部最优取值。同时需要说明的是,经过实验发现,当v=8 时,所用时间是v=3 时的2 倍,因此,不再考虑v超过8 的情况。综上,Shapelet 个数v最佳取值为3。

表7 不同Shapelet 个数的性能表现
至此,本文方法的超参分别确定为:监督信息占比为1%,Shapelet 长度为最短序列长度的10%,Shapelet 空间子序列个数为3。
6.3 实验结果分析
6.3.1 检测性能评估
为了验证本文方法的先进性,实验选取了部分具有代表性的无监督异常/攻击检测方法进行对比。这些方法主要分为以下三类:第一类为经典的基于原始流量的经典无监督聚类方法——K-means;第二类为专门针对隐蔽攻击的检测方法,包括自动编码器(Autoencoder)[32]、Whisper[33]模型;第三类为基于Shapelet 的无监督检测方法,如u-Shapelet[23]等。
由于K-means 和u-Shapelet 没有针对样本不平衡的处理,本文中的数据集正负样本数量差距大,直接使用会影响后续结果的计算,因此这2 种方法使用的是经过本文方法第一阶段处理筛除大量正常流量后的数据。具体的对比结果如表8~表10 所示。
首先,从表8~表10 的第一列和第二列中可以看出,K-means 对于RoQ 隐蔽攻击基本起不到聚类的作用,平均聚类纯度在50%左右,相当于随机归类。Autoencoder 对于Slowheaders、DoS slowloris等特征较明显的攻击检测效果较好。同样地,在混合数据1 上的表现也比较好,这是因为混合数据1中含有大量Slowheaders、DoS slowloris 攻击数据。除此之外,Autoencoder 在其他数据集上表现一般。
其次,从表8~表10 的后三列中可以看出,Whisper、u-Shapelet 和本文方法各具优势。Whisper最主要的特点是将时域数据转换成频域数据,因为攻击者不能轻易干扰频域特征,所以即使是手段复杂隐蔽的攻击在转换为频域特征后也具有一定的识别率。从实验结果上来看,在攻击比较隐蔽的混合数据2和隐蔽攻击1数据集中,Whisper的聚类纯度最高;在频域特征最明显的DoS slowloris 数据集中,Whisper的F1 值最高。这说明该方法有较强的隐蔽攻击识别能力,并且可以看出频域特征是该算法所依赖的一个重要特征。
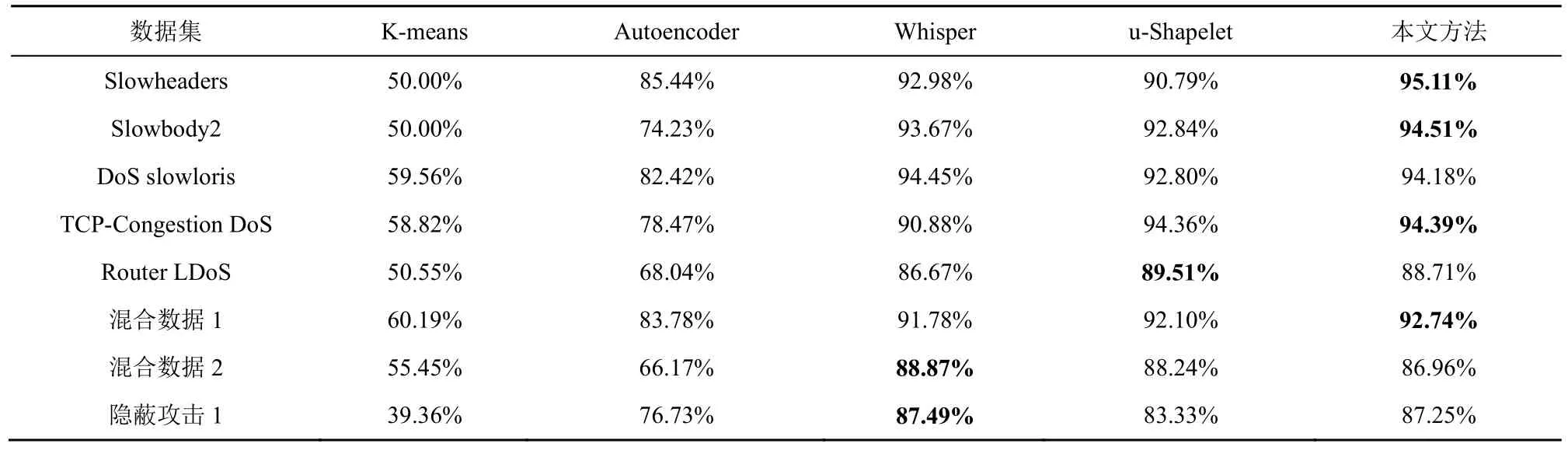
表8 不同方法在不同数据集上聚类纯度P 的性能表现
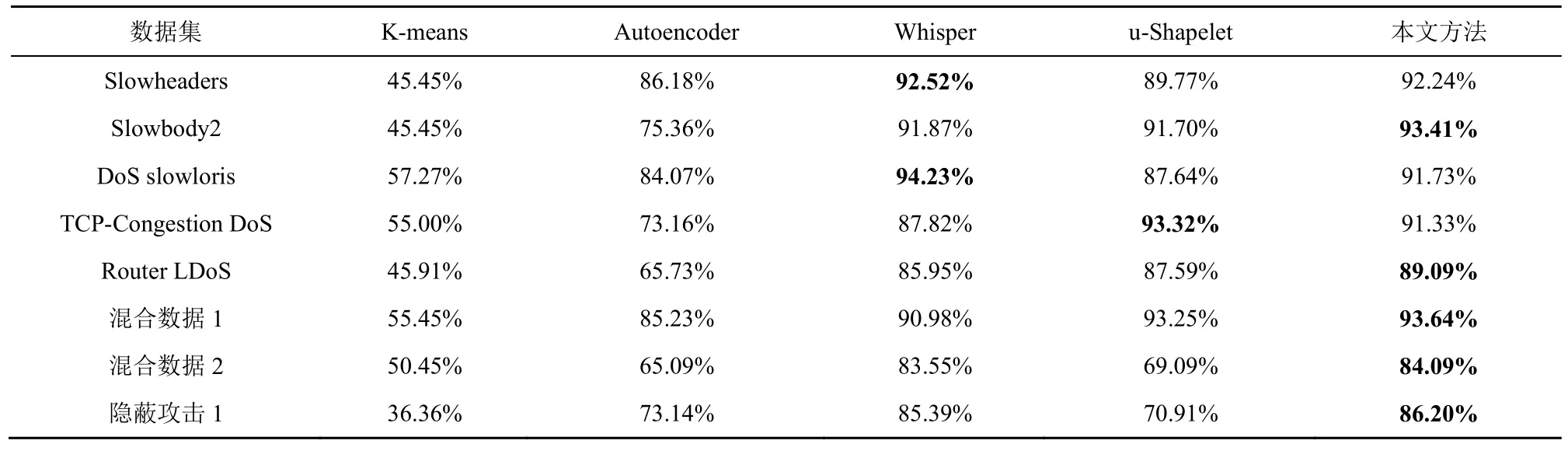
表9 不同方法在不同数据集上兰德系数RI 的性能表现
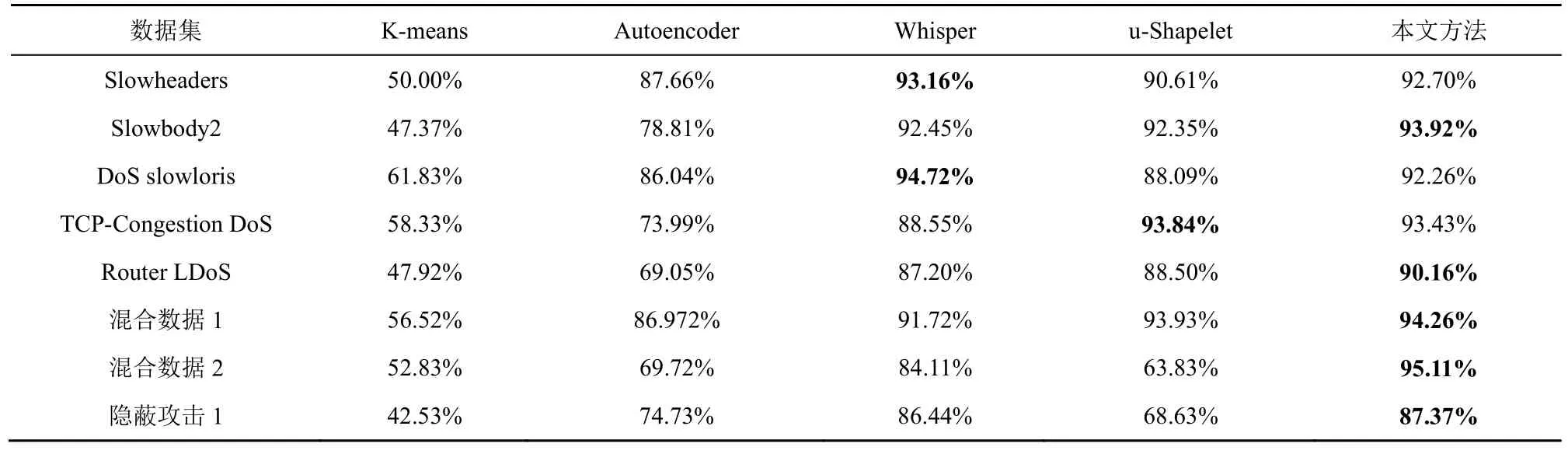
表10 不同方法在不同数据集上F1 值的性能表现
u-Shapelet 只适合一维时间序列,因此在实验时只选取了包大小随时间的变化特征。从实验结果来看,在5 种方法中,u-Shapelet 在Router LDoS数据集中聚类纯度最高,在TCP-Congestion DoS中RI 和F1 值最高,在其他数据集上的表现也相对均衡。这表明使用Shapelet 子序列辨识流量中的变化是可行的。
本文方法在4 个数据集上具有最优的聚类纯度,在5 个数据集上具有最优的RI 和F1 值。对比Whisper,本文方法在时序特征的分辨上更细致,因此在检测时序特征明显的隐蔽攻击时表现更好。对比u-Shapelet,本文方法使用了流量中更多的有效特征,检测性能更好。综上,本文方法在针对RoQ隐蔽攻击的检测时最具优势。
谱聚类算法筛除了大部分正常流量,仅留下比较难以识别的少量流量使进入第二阶段。修改后的基于正样本的半监督谱聚类算法进一步提高了筛选精度。为了验证本文提出的半监督谱聚类的优势,实验分别选取了经典的聚类方法K-means、围绕中心点的划分(PAM,partitioning around medoid)及DBSCAN 替换谱聚类进行实验对比,并依旧保留了原本的半监督机制,分别记为方法A、方法B 和方法C。实验数据选择混合数据1,结果如表11 所示。从表11 中可以看出,方法A 方法、B 方法、C 的性能逐渐提升,这是由于PAM 在获取新的聚类中心时策略较K-means 更佳。基于密度聚类的方法C 的召回率能达到94.17%,说明了RoQ 攻击流量在全流量中的分布也具有密度稀疏的特点。综合来看,本文方法总体性能表现优异。

表11 不同聚类方法的性能表现
为了更加形象地表示本文方法的学习过程,实验在Slowheaders 数据集上将分类过程进行了数值可视化,如图6 所示。从图6 可以看出,随着迭代次数的增多,分类效果越明显,当迭代次数达到6 次时,已经可以很明显地区分出正常流量和攻击流量。
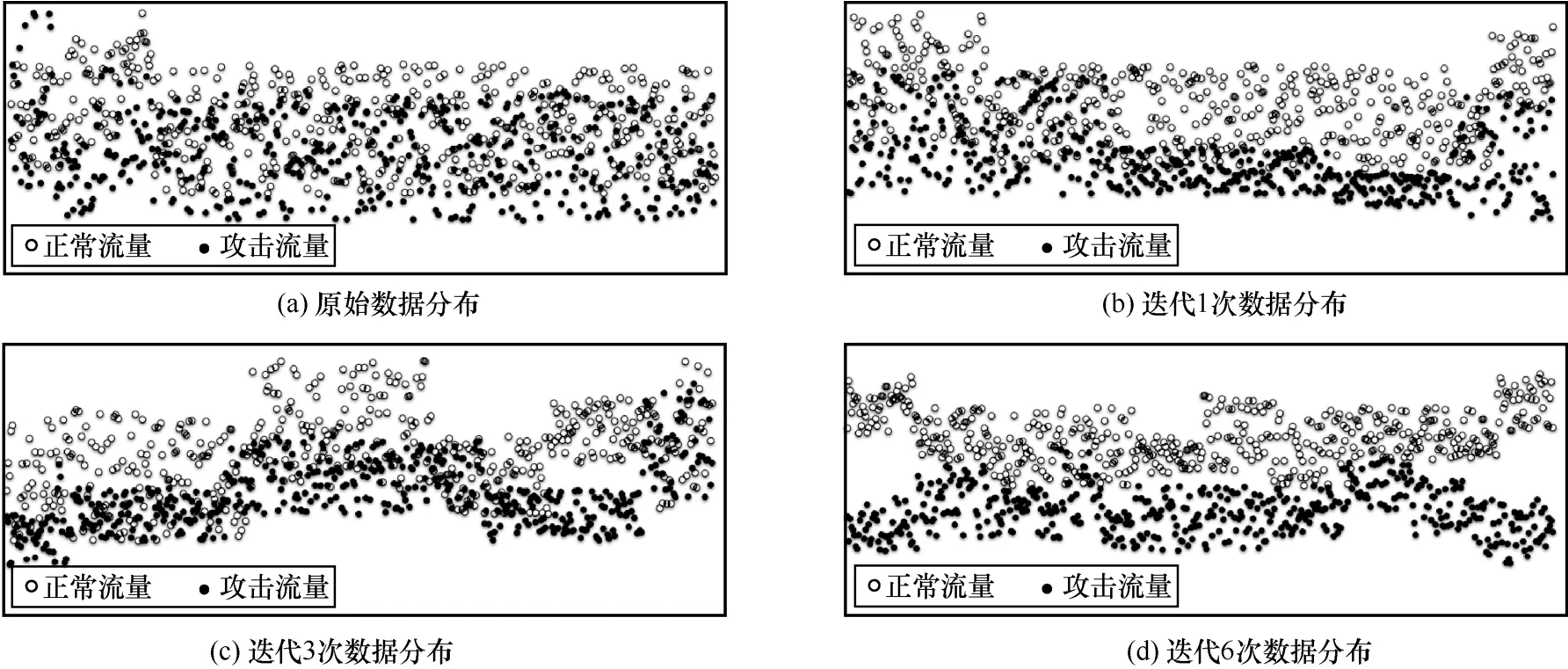
图6 分类过程可视化
6.3.2 稳健性评估
本节将验证本文方法的稳健性。实验假设攻击者知道恶意流量检测的存在,可以构造规避攻击,即通过注入各种良性流量将恶意流量伪装成正常流量来逃避检测。
在实验中,选择5 种恶意流量模式,并混入不同比例的良性流量,恶性流量和良性流量的比例在1:1 到1:8 之间。表12 显示了不同方法在不同比例(恶意流量/良性流量)时对5 种攻击的(AUC,area under curve)值。
从表12 中可知,K-means 的稳健性较差。在TCP-Congestion DoS 攻击采取不同注入策略时,AUC 值最多降低了0.694,在大部分攻击使用不同策略伪装后检测性能不稳定,部分AUC 值甚至低于0.5。对比K-means,Autoencoder 受规避攻击的影响较小。在Slowheaders 伪装攻击上的AUC 值最多降低了0.229,推测这与自动编码器本身在特征方面的处理优势有关。u-Shapelet 从检测结果来看,当良性和恶意流量为1:1 时,AUC 值较高,能够达到0.879。当良性和恶意流量比例逐渐增加时,在WebDoS、Slowbody2 和Router LDoS 这3 种规避攻击检测中有比较明显的降低,最多降低了0.311;但对于另外两类规避类攻击稳健性较好,可以推测Shapelet 子序列起到了关键作用。对比上述3 种方法,本文方法在Router LDoS 规避攻击中AUC 值最多下降了0.136,在Slowheaders 规避攻击和WebDoS 规避攻击中保持了较高且较稳定AUC 值。以上结果说明本文方法稳健性较强,且本文方法的第一阶段基于半监督谱聚类的正常流量筛除起到了重要的作用。
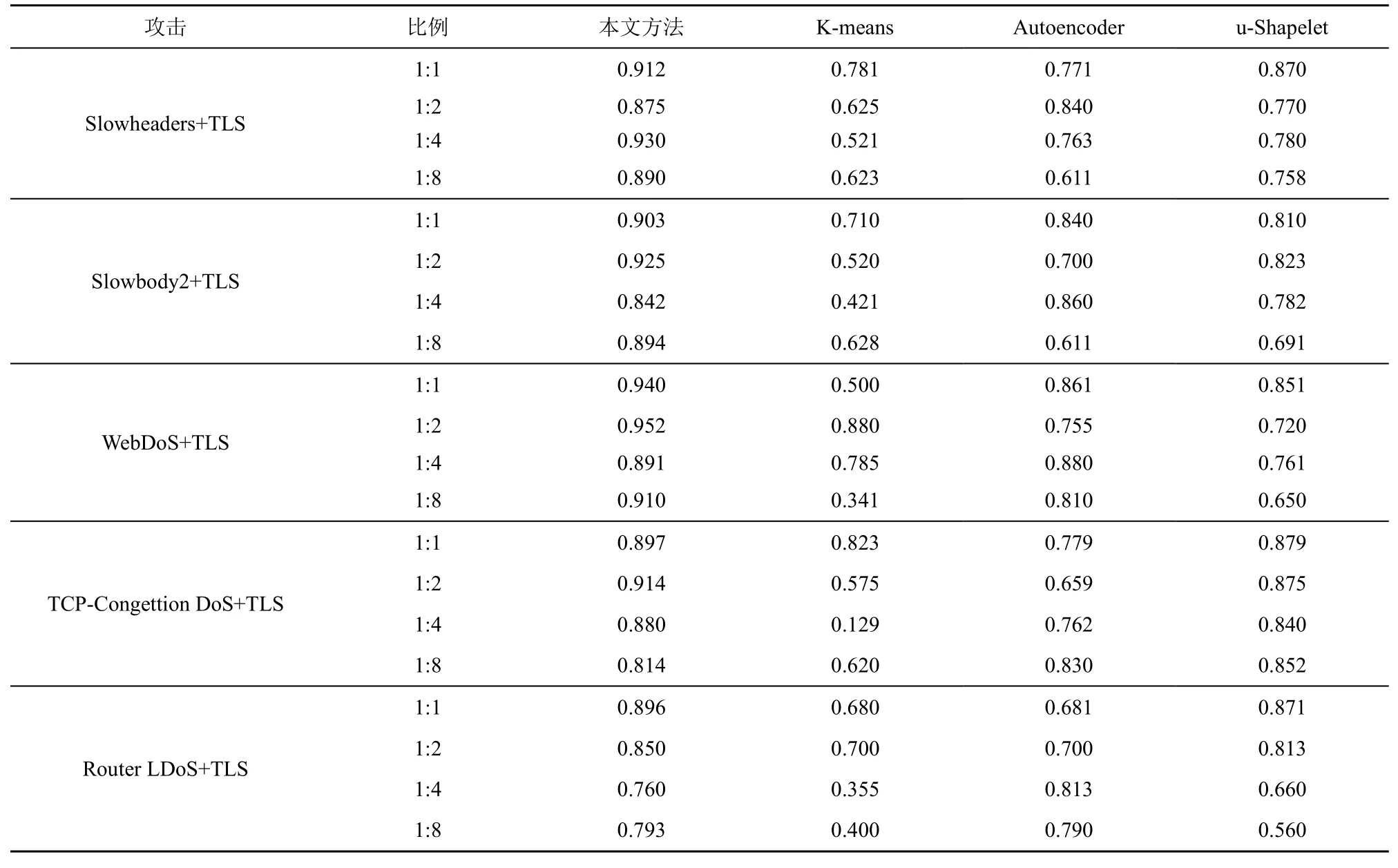
表12 不同方法在不同比例(恶意流量/良性流量)时对5 种攻击的AUC 值
图7 为不同方法的AUC 平均值对比,从图7中可以看到,本文方法的 AUC 平均值最高,K-means 最低。在WebDoS 攻击检测中本文方法分类能力最突出。

图7 不同方法的AUC 平均值对比
7 结束语
本文针对RoQ 攻击特征不明显,高质量学习样本稀少等问题,提出了一种基于多层次特征的无监督隐蔽攻击检测方法。首先研究了基于半监督谱聚类算法,利用第一层流特征实现了正常流量高精度筛除,减少了对后续结果的干扰。其次,基于第二层时序包特征构造了基于n-Shapelet子序列的无监督攻击检测模型,实现了RoQ 攻击的高检测率。实验结果表明,相较于现有方法,本文方法能够保持较高的检测性能,且对规避攻击具有稳健性。但是,本文方法的无监督学习模型中有3 个超参,这3 个超参的迭代计算增加了整体方法的复杂度。因此,未来将研究无监督学习模型,使其达到更快的收敛速度。
猜你喜欢
玩具世界(2022年2期)2022-06-15 07:35:36
房地产导刊(2021年8期)2021-10-13 07:35:16
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
出版人(2020年4期)2020-11-14 08:34:26
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
电子测试(2017年15期)2017-12-18 07:19:27
数学学习与研究(2017年3期)2017-03-09 18:12:42
中国老区建设(2016年1期)2016-02-28 09:32:00
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
