
多模态语义协同交互的图文联合命名实体识别方法*
2022-10-09 11:47钟维幸王海荣
广西科学 2022年4期
钟维幸,王海荣,王 栋,车 淼
(北方民族大学计算机科学与工程学院,宁夏银川 750021)
关键字:多模态命名实体识别 图文数据 多模态注意力 图像描述 语义融合
自媒体的广泛应用致使互联网上的海量数据呈现图像、文本、视频等多模态交融态势,这些数据具有语义互补性,因此,多模态数据的知识抽取和应用成为研究热点,作为基础任务的多模态命名实体识别(Multimodal Named Entity Recognition,MNER)方法研究受到关注。
MNER领域的初期工作旨在将图像信息利用起来以提升命名识别的效果,通过将单词与图像区域对齐的方式,获取与文本相关的有效视觉上下文。Esteves等[1]首次在MNER任务中使用了视觉信息,将图文联合命名实体识别带入研究者的视野。随后,Zhang等[2]提出了一种基于双向长短时记忆(Long Short-Term Memory,LSTM)网络模型(BiLSTM)和共注意力机制的自适应共注意网络,这是首个在MNER研究上有突出表现的工作。同年,Moon等[3]、Lu等[4]也相继提出自己的MNER方法,前者提出一个通用的注意力模块用于自适应地降低或增强单词嵌入、字符嵌入和视觉特征权重,后者则提出一个视觉注意模型,以寻找与文本内容相关的图像区域。在之前的工作中仅用单个单词来捕捉视觉注意,该方式对视觉特征的利用存在不足,Arshad等[5]将自注意力机制扩展到捕获两个词和图像区域之间的关系,并引入门控融合模块,从文本和视觉特征中动态选择信息。但是在MNER中融合文本信息和图像信息时,图像并不总是有益的,如在Arshad等[5]和Lu等[4]的工作中均提及不相关图像所带来的噪声问题,因此,如何在MNER中减小无关图像的干扰成为研究重点。如Asgari-Chenaghlu等[6]扩展设计了一个多模态BERT来学习图像和文本之间的关系。Sun等[7,8]提出一种用于预测图文相关性的文本图像关系传播模型,其可以帮助消除模态噪声的影响。为了缓解视觉偏差的问题,Yu等[9]在其模型中加入实体跨度检测模块来指导最终的预测。而Liu等[10]则结合贝叶斯神经网络设计一种不确定性感知的MNER框架,减少无关图像对实体识别的影响。Tian等[11]提出分层自适应网络(Hierarchical Self-adaptation Network,HSN)来迭代地捕获不同表示的子空间中更多的跨模态语义交互。
上述方法学习了粗粒度的视觉对象与文本实体之间的关系。但粗粒度特征可能会忽略细粒度视觉对象与文本实体之间的映射关系,进而导致不同类型实体的错误检测。为此,一些研究开始探索细粒度的视觉对象与文本实体之间的关系。Zheng等[12]提出一种对抗性门控双线性注意神经网络,将文本和图像的不同表示映射为共享表示。Wu等[13]提出一种针对细粒度交互的密集协同注意机制,它将对象级图像信息和字符级文本信息相结合来预测实体。Zhang等[14]提出一种多模态图融合方法,充分利用了不同模态语义单元之间的细粒度语义。除了直接利用图像的原始信息,一些额外信息的加入也有益于MNER任务,如Chen等[15]在其模型中引入图像属性和图像知识,Chen等[16]则将图像的描述作为丰富MNER的上下文的一种方法。
当前,MNER仍面临两大挑战:一是无关的图像信息带来的噪声干扰,二是图文语义交互中有效语义信息的丢失。为此,本文提出一种新的多模态语义协同交互的图文联合命名实体识别(Image-Text Joint Named Entity Recognition,ITJNER)模型,引入图像描述以增强视觉数据的特征表示,建立多注意力机制耦合的多模态协同交互模块,通过多个跨模态注意力机制实现模态间语义的充分交互并过滤错误图像所带来的噪声信息,实现图文联合下命名实体的有效识别。
1 方法模型
ITJNER模型通过协同表示学习图像、文本的深层特征,使用自注意力、跨模态注意力、门控机制通过协同交互的方式实现跨模态语义交互,并加入条件随机场,利用标签间的依赖关系得到最优的预测标签序列。具体模型如图1所示。图1展示了本方法的核心处理流程,其主要包含多模态特征表示、多模态协同交互与序列标注两个核心模块。
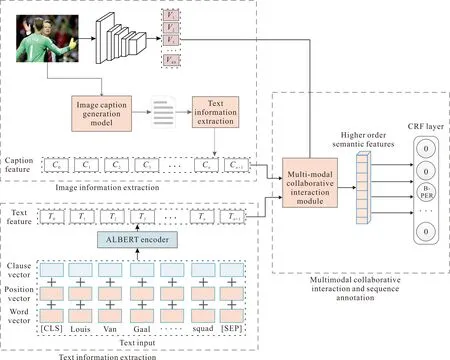
图1 图文联合命名实体识别模型的整体架构
2 多模态特征表示
对图像与文本进行多模态特征表示是图文联合命名实体识别工作的基础,大量研究表明,将文本表示和视觉表示作为多模态特征相结合,可以提高语义提取任务的性能[17,18]。为方便描述对图文特征的抽取与表示工作,将图文对数据集形式化地表示为
(1)
其中,I为图像,S为文本,N为图像-文本数。
2.1 文本特征抽取与表示
对文本特征的抽取是命名实体识别任务的基本,更加轻量化且不影响性能的模型有助于降低后续从算法模型到应用落地的难度,因此本文采用ALBERT模型[19]对文本进行特征提取。ALBERT是一个轻量级的BERT模型,其参数比BERT-large更少且效果更好,为了降低参数量和增强语义理解能力,其引入词嵌入矩阵分解和跨层参数共享策略,并使用句子顺序预测(Sentence Order Prediction,SOP)任务替换原先的下一句预测(Next Sentence Prediction,NSP)任务。在模型中使用多层双向Transformer编码器对输入序列进行编码,其模型结构见图2。图2展示了ALBERT模型的核心结构,包含输入层、编码层、输出层,其中每一个Trm对应一个Transformer编码器。
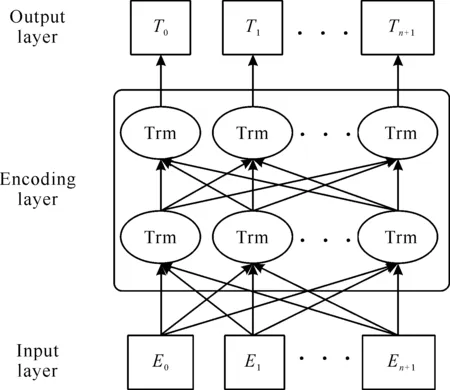
图2 ALBERT模型结构图
由于数据集文本可能存在无用的特殊字符,需要对数据进行预处理,对每个输入句子S进行标记处理,对不存在的字符使用[UNK]替代,并分别在每个句子的开头和结尾插入两个特殊的标记即[CLS]和[SEP]。形式上,设S=[S0,S1,S2,…,Sn+1]为修改后的输入句子,其中S0和Sn+1表示插入的两个令牌。设E=[E0,E1,E2,…,En+1]为句子S的标记表示,其中Ei为字符向量、分段向量和位置向量的和。将E作为ALBERT编码层的输入。
T=ALBERT(E),
(2)
T=[T0,T1,T2,…,Tn+1]为模型的输出向量,其中Ti∈d为Ei生成的上下文感知表示,d是向量的维数。在获得文本特征表示的同时,对图像与图像描述特征进行特征抽取。
2.2 图像及图像描述特征的抽取与表示
2.2.1 图像特征抽取
卷积神经网络(Convolutional Neural Networks,CNN)的最新研究进展显示,更强的多尺度表示能力可以在广泛的应用中对图像特征的提取带来性能增益,因此本文采用预训练过的Res2Net[20]来提取图像特征。Res2Net在粒度级别表示多尺度特征,并增加了每个网络层的感受野,相比于传统ResNet网络,其在不增加计算复杂度的情况下,提高了网络的特征表示能力。更深层次的网络已经被证明对视觉任务具有更强的表示能力[21],在综合考虑模型的性能与模型训练效率后,本文最终选择采用101层的Res2Net (Res2Net-101)用于图像特征的提取与表示。
不同图文对数据中的图像大小可能不同,因此首先将它们的大小统一缩放为224×224像素,并经随机剪切、归一化等图像预处理方法进行数据增强;然后将调整后的图像输入Res2Net-101,如式(3)所示。
U=Res2Net(I),I∈D。
(3)
本文在预训练的Res2Net-101中保留了最后一个卷积层输出,以表示每幅图像,遵循大部分研究对卷积核大小的设置,经Res2Net进行特征抽取后,获得7×7=49个视觉块特征U=(u1,u2,…,u49),其中ui是第i个视觉块,由2 048维向量表示。在将图文特征输入多模态协同交互模块前需保持图文特征向量的维度一致,因此对视觉块特征U应用线性变换得到V=(v1,v2,…,v49),如式(4)所示。
(4)
其中,Wu∈2048×d是一个权重矩阵。
2.2.2 图像描述特征抽取
为了加强图像与文本间的语义融合,本文加入图像描述,并将其视为图文间的过渡信息特征,描述可以帮助过滤掉从图像特征中引入的噪声,同时也可以更好地总结图像的语义。本文使用包含视觉注意力的编解码框架的描述生成模型来生成图像描述,如图3所示。
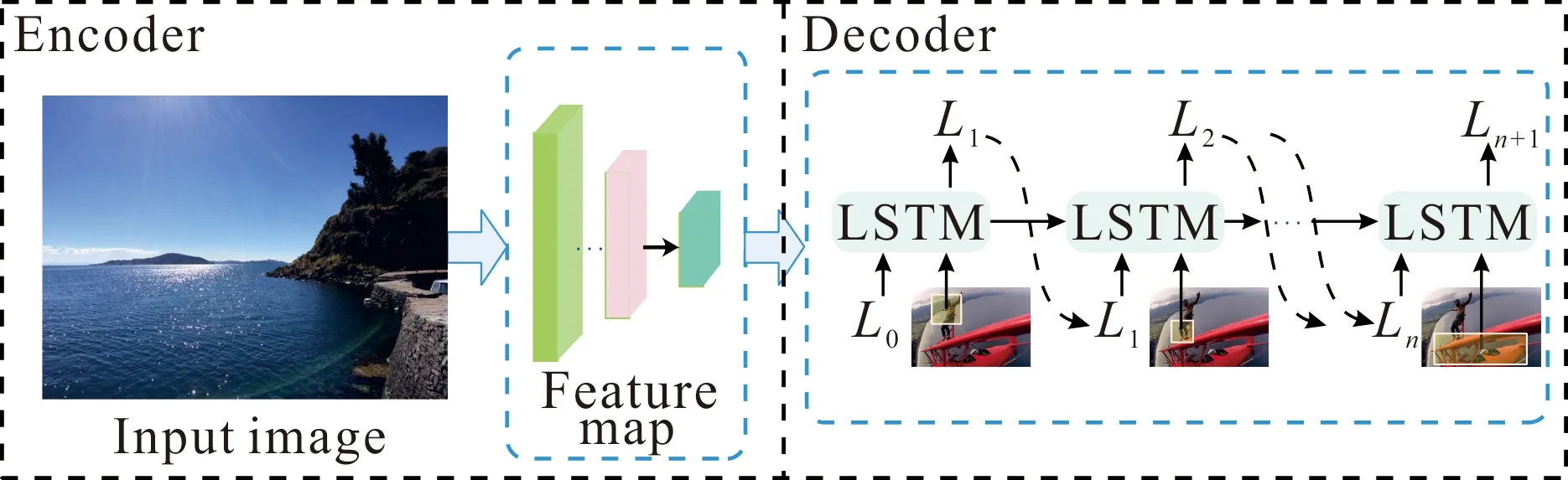
图3 图像描述模型
使用图像特征提取到的视觉块特征U作为长短时记忆(LSTM)网络的输入,LSTM网络通过动态地选择图像特征,提取句子内部单词之间的句法特征、单词位置编码信息,学习图像特征与句法特征、单词特征之间的映射关系,同时加入注意力机制,赋予不同视觉区域以不同的权重,以此缓解视觉噪声干扰。将加权图像特征输入LSTM,将图像信息逐字转换为自然语言,输出目标为
L=[L0,L1,L2,…,Ln+1],Li∈k
(5)
其中k是词汇表的大小,n是描述句的长度,Li代表句子中的第i个单词。再将描述L作为输入,使用ALBERT编码器,得到C=[C0,C1,C2,…,Cn+1],其中Ci∈d是Li生成的上下文表示,d是向量的维数。在得到多模态表示后将其作为协同交互模块的输入,实现多模态特征的语义交互。
3 多模态协同交互与序列标注
多模态协同交互模块获取图像、文本、图像描述特征,利用图像引导进行文本模态融合、文本引导进行图像模态融合,实现不同特征的语义交互,减少视觉偏差。图4展示了多模态协同交互模块的具体框架结构,其中包括了以文本向量为键值的跨模态注意力、以图像向量为键值的跨模态注意力、以原始文本向量为键值的非标准自注意力、视觉门控机制。
如图4所示,在ALBERT模型得到的输出后添加一个标准的自注意力层,以获得每个单词的文本隐藏层表示R=(r0,r1,…,rn+1),其中ri∈d为生成的文本隐藏层表示。对图像描述特征C和视觉块特征U线性变换所得的视觉块特征V各添加一个标准自注意力层,分别得到图像描述与图像的隐藏层表示:
O=(o0,o1,o2,…,on+1),
(6)
W=(w1,w2,…,w49),
(7)
其中oi∈d为生成的图像描述隐藏层表示,wi∈d为生成的图像隐藏层表示。
3.1 图像引导的文本模态融合
如图4左侧所示,为了利用相关图像学习更好的文本表示,本文采用多头跨模态注意力机制,先利用图像描述来引导文本融合,将O∈d×(n+1)作为查询,将R∈d×(n+1)作为键和值,将m设为多头数:
Ai(O,R)=
(8)
MHA(O,R)=WO[A1(O,R),…,Am(O,R)]T,
(9)
其中Ai指跨模态注意力的第i个头,MHA表示多头注意力,{Wqi,Wki,Wvi}∈d/m×d和W0∈d×d分别表示查询、键、值和多头注意力的权重矩阵。在跨模态注意层的输出后堆叠前馈网络和层归一化等,另外3个子层得到描述感知文本表示P=(p0,p1,…,pn+1),如式(10)-(11)所示:

(10)
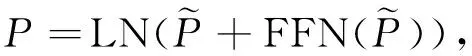
(11)
其中FFN表示前馈网络,LN表示层归一化。在利用图像描述填补了文本与相关图像间的语义空白后,再利用图像与描述感知文本做跨模态注意力,将W∈d×49作为查询,将P∈d×(n+1)作为键和值,与文本和描述的融合方法相似,叠加3个子层后输出Z=(z1,z2,…,z49),由于以视觉表示作为查询,所以生成的向量zi都对应于第i个视觉块,而非第i个输入字符,因此另外加入一个跨模态注意力层,以文本表示R作为查询,并将Z作为键和值,该跨模态注意力层生成最终的图像感知文本表示H=(h0,h1,…,hn+1)。
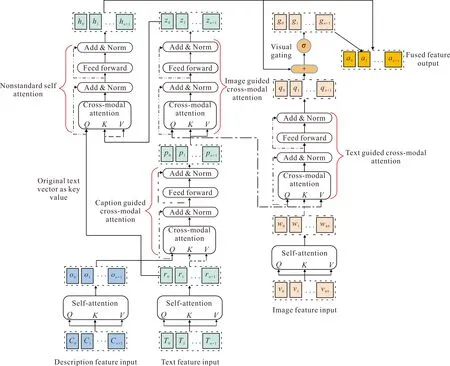
图4 多模态协同交互模块的框架结构
3.2 文本引导的图像模态融合
为了将每个单词与其密切相关的视觉块对齐,加入跨模态注意力层为视觉块分配不同的注意力权重。将P作为查询,W作为键和值。与图像引导的文本模态融合对称,文本引导的图像模态融合会生成具有单词感知能力的视觉表示,用Q=(q0,q1,…,qn+1)表示。
相关图像中,部分文本中的一些视觉块可能与单词没有任何关联,同时,文本中的一些单词如助词、数词等也与视觉块少有关联。因此,本文应用一个视觉门控来动态控制每个视觉块特征的贡献,如式(12)所示:
g=σ((Wh)TH+(Wq)TQ),
(12)
其中{Wh,Wq}∈d×d是权重矩阵,σ是元素级的S型激活函数。基于动态视觉门控,得到最终的文本感知视觉表示为G=(g0,g1,…,gn+1)。
在得到最终的图像感知文本表示H和最终的文本感知视觉表示G后,本文将H和G拼接,得到图像与文本最终融合的隐藏层表示A=(a0,a1,…,an+1),其中ai∈2d。
3.3 标签依赖的序列标注
在命名实体识别任务中,输出标签对其邻域有着强依赖性,如I-LOC不会出现在B-PER后。多模态协同交互只考虑了图文对数据中上下文的信息,而没有考虑标签间的依赖关系,因此,本文添加了一个条件随机场(Conditional Random Field,CRF)来标记全局最优序列,并将隐藏层表示A转化为最佳标记序列y=(y0,y1,…,yn+1),CRF可以有效提升此类任务的性能。本文对给定的输入句子S及其关联图像I的标签序列y计算如下:
(13)
(14)
(15)


(16)
经上述学习得到全局最优标注序列。
4 验证实验及结果分析
4.1 数据集和方法验证
为验证本文提出的方法,使用python语言,利用pytorch等技术在Ubuntu系统上搭建实验环境,在Twitter-2015和Twitter-2017两个公共数据集上进行实验,数据集信息如表1所示。
对于实验中比较的每种单模态和多模态方法,考虑到文本数据的实际输入范围,将句子输入的最大长度设置为128。考虑到训练速度的内存大小,将批处理大小设置为8。对于本方法,对预训练语言模型的参数设置大多数遵循原始论文设置。使用ALBERT-Base模型进行文本抽取初始化,使用预训练的Res2Net-101来初始化视觉表示,并在训练中保持大小固定。对于多头自注意力层和多头跨模态注意力层,考虑训练效率与精度,在经过调整训练后使用12个头和768个隐藏单元。同时,经过对超参数多次微调,将学习率、dropout率和权衡参数λ分别设置为5e-5,0.1和0.5,可以在两个数据集的开发集上获得最好的性能。

表1 数据集详情
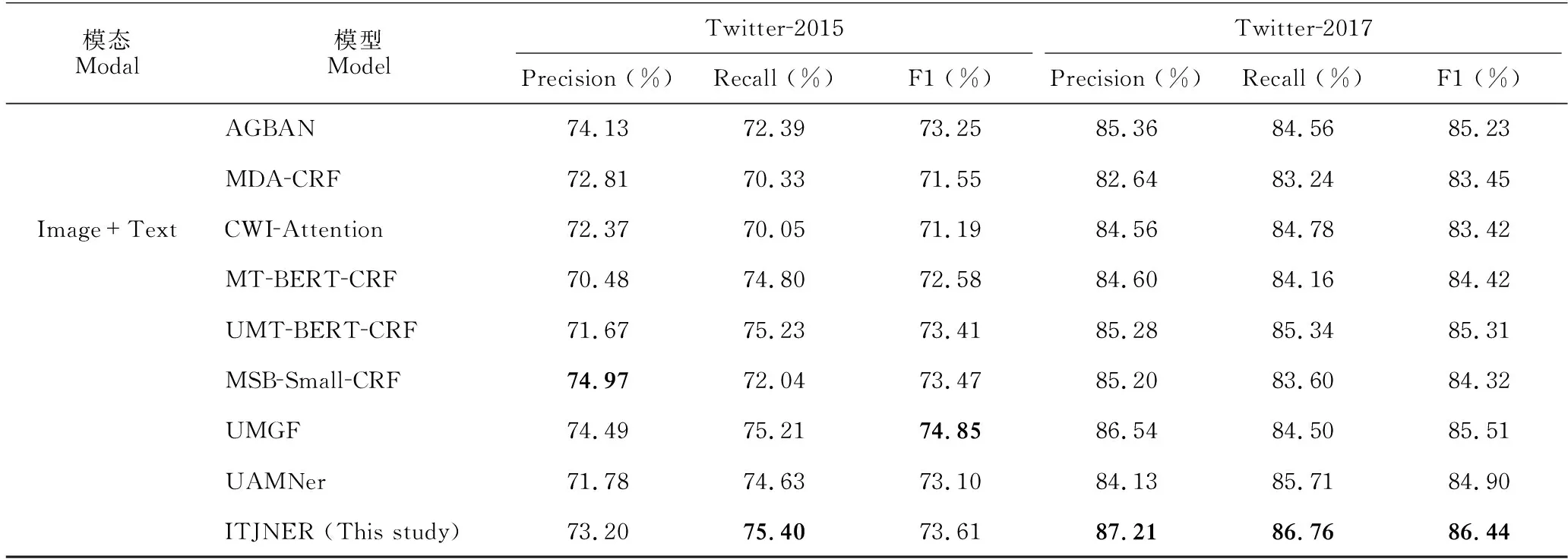
本实验使用召回率(Recall)、准确率(Precision)、F1值作为实验评价指标,与HBiLSTM-CRF-GVATT[5]、BERT-CRF-GVATT[5]、AdaCAN-CNN-BiLSTM-CRF[3]等12种方法的对比结果如表2所示。

表2 对比实验结果
续表
4.2 对比实验
实验结果表明,图文联合方法通常可以获得更好的性能,本文方法在Twitter-2017数据集上的准确率、召回率、F1值较对比方法中的最优方法UMGF分别提高了0.67%、2.26%和0.93%;在Twitter-2015数据集上,召回率提高了0.19%。
对于单模态方法,预训练的方法明显优于传统的神经网络。例如,BERT-CRF在Twitter-2017数据集上准确率、召回率、F1值的表现比HiBiLSTM-CRF分别高出0.29%、6.3%和3.34%,表明预训练模型在NER中具有明显的优势。使用CRF解码的BERT-CRF的性能优于使用softmax的BERT-softmax,说明CRF层对NER的有效性。通过对比单模态与多模态方法,可以看到多模态方法的性能明显优于单模态方法。例如,加入视觉门控注意力后,在两个数据集上HBiLSTM-CRF较之前的F1值分别提高了1.63%和1.5%。此外,相较于AGBAN、UMT-BERT-CRF等未使用图像描述的模型,本文方法的性能表现更好,表明结合图像描述有助于完成NER任务。
针对本文方法在Twitter-2015数据集上表现不佳的情况,本文对数据集的内容进行分析,统计两个数据集的实体分布状态,通过对比图文间实体分布的不同,反映出数据集的图文关联程度,并人工抽样统计数据集的图文关联度,如图5所示。
从图5可以看到数据集中文本实体分布与图像实体分布之间的差异,图像实体与文本实体并不是完全对应的,图像中的实体对象总量一般会多于其对应的文本所含的命名实体数量,这一差别也体现了数据集中图像文本对之间存在无关联或弱关联情况。对比数据集的图文内容后发现,Twitter-2015中图文无关联或弱关联现象比Twitter-2017中更多,而对本文所提出的方法,图像描述与图像本身有着更高的关联性,因此,在图文无关联或弱关联的图文对数据中,图像描述与文本的语义差距会更大,这也意味着在进行命名实体识别时,带入了无关的噪声数据。由此分析,本文提出的加强图文间融合的方法可以为图文存在相关性的MNER带来益处,但对于图文显著无关的情况仍有待改进。
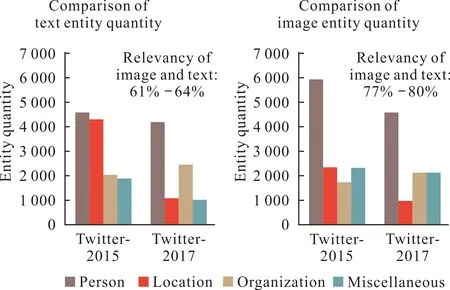
图5 数据集实体量对比图
4.3 消融实验
为了研究本文图文联合命名实体识别模型中模块的有效性,对模型的核心部件进行消融实验。如表3所示,图像描述、视觉门控、图像感知文本融合均对模型生效起重要影响,在去掉图像描述后,模型在Twitter-2017数据集上的表现明显变差,而在Twitter-2015数据集上的表现却并没有下滑甚至略有提升,这佐证了4.2节的观点,即加入图像描述所带来的影响会因图文数据关联度不同而不同,图文间关联度更大,可以为NER任务提供帮助;若图文间关联度不足则可能会起到相反的作用。在多模态协同交互模块中,去除图像感知文本表示后性能明显下降,显示它对模型有不可或缺的作用。而去除视觉门控也会导致轻微的性能下降,这体现了它对整个模型有着一定的重要性。

表3 消融实验
5 总结
本文针对现有MNER研究中存在的噪声影响和图文语义融合不足的问题,提出了一种多模态语义协同交互的图文联合命名实体识别(ITJNER)模型。以图像描述丰富多模态特征表示和图像语义信息的表达,减少图文交互中有效语义信息的丢失,提出一种将多头跨模态注意力、多头自注意力、门控机制相互耦合的多模态协同交互方法,可以在实现图文语义间有效融合的同时,抑制多模态交互中的不完整或错误的语义信息。实验结果表明,本模型有助于提取图文间的共同语义信息且在图文关联度更高的数据中表现更优,但本模型对于图文关联度较低的数据的准确率仍有待提升。
在未来的工作中,考虑增强模型对图文不相关数据的处理能力,能够排除过滤无关数据噪声对模型的影响,以获得一个更健壮的NER模型,同时考虑通过融合知识图谱实现多模态数据的语义表达,并反向推动知识图谱的构建。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
北京航空航天大学学报(2022年8期)2022-08-31
昆明医科大学学报(2022年3期)2022-04-19
文萃报·周二版(2022年3期)2022-01-20
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
长江学术(2016年4期)2016-03-11
人间(2015年21期)2015-03-11
长江学术(2015年1期)2015-02-27
电影新作(2014年1期)2014-02-27
海外英语(2013年9期)2013-12-11
