
基于字词混合和GRU的科技文本知识抽取方法*
2022-10-09 11:47欧阳苏宇邵蓥侠杜军平
广西科学 2022年4期
欧阳苏宇,邵蓥侠,杜军平,李 昂
(北京邮电大学计算机学院,智能通信软件与多媒体北京重点实验室,北京 100082)
无论是专业科技资源平台,还是社交媒体场景,都有大量的科技文本数据[1-3],对这些数据进行知识抽取能更好地进行信息挖掘和利用[4,5]。知识抽取任务[6]是从非结构化的文本数据抽取三元组关系(头实体-关系-尾实体),现有知识抽取研究主要基于循环神经网络(Recurrent Neural Network,RNN)。RNN的同一层节点之间是相互连接的,对于每一个时间步长,都有来自前面时间步长的信息,并加以权重用以控制[7]。长短期记忆网络(Long Short-Term Memory,LSTM)用于解决RNN在训练过程中容易出现梯度爆炸和梯度消失的问题[8]。门控制单元(Gated Recurrent Unit,GRU)建立在LSTM的基础上,仅由重置门(Reset Gate)和更新门(Update Gate)组成[9]。
现有基于深度学习的知识抽取方法分为流水式方法和联合抽取方法。本文采用联合知识抽取模型,很好地保留实体和关系之间的关联,将实体和关系的联合抽取转化为序列标注问题。为了在最大程度上避免边界切分出错,选择字标注的方式,即以字为基本单位进行输入。但是在中文中,单纯的字Embedding难以存储有效的语义信息,因此为了更有效地融入语义信息,本文设计了一种字词混合方式。同时结合自注意力机制来捕获句子中的长距离语义信息,并且通过引入偏置权重来提高模型抽取效果。
1 相关工作
知识抽取是从文本中抽取结构化信息[10],文本实体关系抽取是信息抽取的一个子域,是指从文本关系提取语义关系,这种语义关系存在于实体对之间。定义文本S,关系集合R={r1,r2,…},文本关系抽取就是根据S和R抽取三元组(h,r,t)的过程,其中,h表示头实体,t表示尾实体,r表示h与t之间的关系[11]。一般来说,文本关系抽取的步骤分为命名实体识别(Named Entity Recognition,NER)[12]和关系分类(Relation Extraction,RE)[13]。在深度学习中,文本关系抽取主要基于有监督和远程监督两种方法进行研究。有监督的关系抽取方法主要包括流水式学习和联合学习两种。
流水式抽取通常将命名实体识别和语义关系分类独立进行,先识别出文本数据中存在的实体,再根据实体对判断之间的关系是否存在。早期的流水式学习方法主要基于卷积神经网络(Convolutional Neural Networks,CNN)[14,15]。Zeng等[16]利用CNN网络进行关系分类,设计基于词法级别(lexical level)和句子级别(sentence level)的特征提取网络,对两种特征进行融合得到编码向量,在编码器网络后接全连接层,利用softmax进行关系分类,在公开数据集上验证了方法的有效性。在此基础上,Nguyen等[17]加入了多尺寸卷积核,完全使用句子级别特征,能自动学习句子中的隐含特征。近年来,许多学者基于RNN开展了研究。Socher等[18]首次采用RNN对文本进行句法解析,句法解析树上的每个节点由向量和变换矩阵两部分组成,对于任意句法类型和长度的词语和句子,均可以学习其组合向量表示。LSTM是一种特殊的RNN。Xu等[19]提出了采用SDP-LSTM模型进行关系分类,基于最短依赖路径的思想,过滤文本无用信息,使用LSTM将异构信息进行有效集成,制定有效的dropout策略防止出现过拟合的可能。Zhang等[20]提出了双向递归卷积神经网络模型(BRCNN),基于最短依赖路径,使用了双向长短期记忆网络(Bi-LSTM),考虑实体之间关系的方向性,利用词语前后的信息进行关系抽取。
流水式方法将命名实体识别和关系分类视为两个独立的任务,忽略了任务之间存在的关系。同时,由于任务之间存在先后顺序,导致实体识别的误差影响到后续关系分类,出现误差传播现象。另外,由于缺乏关系的实体对无法两两配对,导致在关系分类中带来多余信息,出现实体对冗余的现象。近年来,许多研究尝试将两个任务联合进行学习,即将命名实体识别和关系分类融合为单个任务。联合学习方法主要包括基于参数共享的方法、基于序列标注的方法和基于图结构的方法。
①基于参数共享的方法是在命名实体识别和关系分类两个任务中间设计共享编码层,在训练中得到最佳的全局参数。Miwa等[21]首次设计基于LSTM的共享编码层,以获得单词序列和句法依存树上的子结构信息。Zheng等[22]在此基础上,设计基于向量嵌入层和Bi-LSTM层的共享编码层,命名实体名识别模块采用LSTM,关系分类模块采用CNN,有效捕获了长文本实体标签之间的距离依赖关系。
②基于序列标注的方法是将命名实体识别和关系分类两个任务融合成序列标注的问题。为了解决基于参数共享的方法容易产生实体对冗余的问题,Zheng等[23]提出了一种新的标注方案,将联合提取任务转换为标注问题,研究了不同端到端的模型[24]的关系抽取性能,另外使用偏置损失函数来增强相关实体之间的关联。Bekoulis等[25]利用条件随机场(Conditional Random Field,CRF)将命名实体识别和关系抽取任务建模为一个多头选择问题(Multi-Head Selection Problem),将关系分类任务看作多个二分类任务,从而使得每个实体能够与其他所有实体判断关系,有效解决了关系重叠的问题。
③基于图结构的方法是利用图神经网络(Graph Neural Networks,GNN)对关系进行抽取。Wang等[26]提出基于图结构的联合学习模型,同时使用偏置权重的损失函数削弱无效标签的影响,增强了相关实体间的关联。此外,Fu等[27]提出了一种端到端的关系抽取模型GraphRel,通过关系加权图卷积网络(Graph Convolutional Network,GCN)来考虑实体和关系之间的交互,将RNN和GNN结合起来提取每个单词的顺序特征和位置依赖特征,有效解决实体对重叠的问题。
基于远程监督的方法可以极大降低人工成本,耗时短,而且领域可移植性强。Mintz等[28]提出了DS-logistic模型,利用外部知识库,将大规模知识图谱与文本关联,对远程监督标注的数据提取文本语义特征,将其表征输入到分类器中进行关系分类。但是,由于采用自动标注,训练集数据出错的可能性大幅增高,导致目前远程监督实体关系抽取准确率偏低。
2 基于字词混合及GRU的科技文本知识抽取(MBGAB)方法
为提高抽取性能,同时解决基于流水式的方法所带来的冗余信息的问题,本节将三元组的抽取问题转变为多序列标签分类问题,设计了编码器-解码器的神经网络结构,使用端对端的模型预测输入文本序列的三元组标签序列。具体来讲,本文在向量序列层采用字词混合向量映射的方式,改善中文分词边界出错可能带来歧义的问题。采用门控循环单元机制对输入句子进行编码,引入自注意力机制来捕获句子中的长距离语义信息,使用带有偏置权重的目标函数来增强实体标签的相关性和降低无用标签的影响度。基于字词混合的文本关系联合抽取方法整体架构如图1所示。

图1 MBGAB方法架构
2.1 向量序列层
在向量序列层中,针对中文文本单纯的字向量难以存储有效的语义信息,同时为了最大程度上避免边界切分出错,本文设计了一种字词结合的向量混合映射方式。具体来讲,输入以字为单位的文本序列S,经过随机初始化的字Embedding层,得到字向量序列S=(c1,c2,…,cn)。将文本序列分词,通过Word2Vec词向量模型提取对应的词向量,为了将词向量序列与字向量序列对齐,使单个词向量wi重复k次,k即为组成该词的字数,得到词向量序列S=(w1,w2,…,wn)。例如对于“硕士研究生”,将该词所对应的词向量重复5次得到对齐的词向量序列。得到对齐的词向量后,将词向量经过一个随机初始化的变换矩阵T,得到与字向量相同维度的向量,并将两者相加。字词混合向量映射公式为
xi=ci+wi,
(1)
其中,xi代表融合后的字向量,字词混合向量即为两者加和。此时,文本序列转换成融合后的字向量序列S=(x1,x2,…,xn)。
2.2 编码层
在得到科技资源文本字词混合向量后,此时一个句子的字向量序列可以表示为S=[w1,w2,…,wn],其中wi表示该句子中的第i个汉字,n表示该句子由n个汉字组成。双向GRU(Bi-GRU)编码层利用先前的隐藏状态ht-1和输入单词序列的字向量表示wt,计算每个时间步长更新后的隐藏状态ht,具体计算公式如下:
zt=γ(Wzwt+Uzht-1+bz),
(2)
rt=γ(Wrwt+Urht-1+br),
(3)
(4)
(5)

2.3 自注意力层
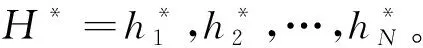
(6)
(7)
2.4 解码层
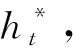
(8)
(9)
(10)
(11)
(12)
2.5 分类层
本文采用softmax分类器进行标签分类,根据标签预测向量Tt归一化计算实体标签概率。定义单词Tt在所有标签类型上的评分:
Yt=WYTt+bY,
(13)
其中,WY是参数矩阵,bY是偏置项。通过softmax层计算单词Tt为标签i的概率为
(14)

通过最大化对数似然函数
L=
(15)

MBGAB方法的整体步骤如下:
①固定词向量wword不变,对随机初始化的字向量wcharacter进行训练;
②得到字词混合映射向量wi=wcharacter+wword;
③通过双向GRU编码层后,将词嵌入向量序列W=w1,w2,…,wN转化为带有句子语义信息的词向量H={h1,h2,…,hN};
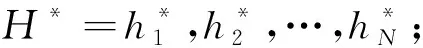
⑤GRU解码层经过计算输出得到单词wt的预测标签状态Tt。
3 验证实验
3.1 数据集
为验证模型对专家学者科技资源信息的知识抽取的可行性,使用部分LIC2019中文抽取语料,其中包含19种关系,将数据集分为24 851条训练集和6 212条测试集,其中训练集与测试集中标签占比基本一致,以保证数据的一致性。
3.2 评估指标
为评估所提算法的效果,本文使用准确率(precision)、召回率(recall)以及F1-score指标对知识抽取效果进行评价。
3.3 实验设置
ME-BiGRU:去除注意力机制和权重偏置。
ME-BiGRU-SA:去除权重偏置。
BIGRU-SA-Bias:去除字词混合Embedding。
ME-GRU-CRF:解码层用条件随机场CRF进行解码。
ME-BiGRU-Bias:去除注意力机制。
对于实验的参数根据算法的结构图进行以下设置,在编码层的输入是采用预训练好的Word2Vec模型生成的词向量,词向量维度为300,字向量使用随机初始化的字Embedding层。在模型训练中,固定Word2Vec词向量不变,只优化变换矩阵和字向量。Bi-GRU编码层的维度为300,GRU解码层的维度为600,偏置权重参数α设置为3。
3.4 MBGAB方法的有效性
使用以下算法进行对比。
①FCM:分别进行实体和知识抽取,是一种流水式抽取模型。
②Attention-BILSTM:使用Attention和双向LSTM对关系进行抽取,是一种流水式抽取方法。
③MultiR:远程监督算法,是一种联合抽取方法。
④Cotype:将实体、关系、文本特征和类型标签嵌入到两个向量空间,是一种联合抽取方法。
实验结果如表1所示。
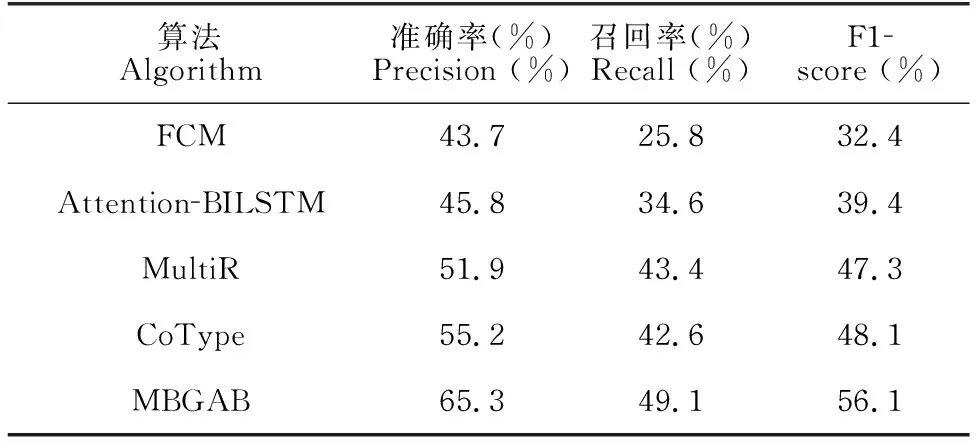
表1 知识抽取实验结果对比
从表1可以看出,MBGAB方法在相同数据集上的表现较其他方法有明显提升,证明了该方法的有效性。FCM方法和Attention-BILSTM方法召回率较低,表明传统的流水式方法在面对关系重叠问题时性能不佳。MultiR和CoType的性能较FCM和Attention-BILSTM方法更好,可能是基于流水式的方法将两个子任务独立执行,而联合抽取方法利用了两者之间的关联性从而尽可能减少误差传播。对比其他传统联合抽取方法,基于本文端到端的模型在准确率和召回率上有了显著提升,考虑到字词混合映射方式和双向GRU编码方式文本语义表示的有效性,同时结合自注意力层对数据的良好适应性,最终使得本文方法在F1值上总体提升。
3.5 消融学习
本文提出的算法架构中,核心部分是基于字词混合向量嵌入方式、Bi-GRU编码层、自注意力层以及GRU解码层,并且在目标函数上加入了偏置项。为了观察算法核心组成部分对于关系抽取的改善效果,对这些部分进行消融学习。本节使用以下变种作为对比。
①BiGRU-GRU-SA-Bias(c):去除字词混合嵌入方式,采用字嵌入方式,直接将以字为单位的文本序列经过随机初始化的Embedding层进行向量嵌入;
②BiGRU-GRU-SA-Bias(w):去除字词混合嵌入方式,采用词嵌入方式,将文本分词后,采用预训练好的Word2Vec模型进行向量嵌入;
③ME-BiGRU-GRU:去除注意力机制和偏置权重,以观察两者对算法性能的影响;
④ME-BiGRU-CRF-SA-Bias:解码层采用条件随机场CRF,将CRF应用于预测实体标签序列;
⑤ME-BiGRU-GRU-SA:去除偏置权重,以验证目标函数中加入偏置权重对性能的影响;
⑥ME-BiGRU-GRU-Bias:去除注意力机制,以验证自注意力层对算法性能的影响。
实验结果对比如表2所示。从表2可以看出,本文方法(MBGAB)与其他6个变种相比,召回率和F1值均为最高,证明了方法的各组成部分对于性能提升都有一定贡献。

表2 不同变种与原算法在知识抽取任务上的实验结果对比
对于变种1和变种2,去除了字词混合嵌入方式,采用字嵌入和词嵌入,本文方法在准确率和召回率上都有提高,在F1值上分别提高了1.1%和1.6%。考虑到本文方法使用更为适合中文文本的字向量,微调了预训练词向量,使得向量嵌入层学习了预训练模型所带来的丰富的语义信息,同时也减小了中文分词可能带来的错误,保留了字向量的灵活性。因此,字词混合嵌入方式可以有效改善中文文本的语义表示能力。对于变种3,去除了自注意力机制和偏置权重后,准确率、召回率以及F1值均为最低,表明了本文所用到的数据集对于长距离文本语义和关系标签较为敏感,证明了两者对于方法的性能具有一定影响。对于变种4,当解码层用CRF替换后,准确率下降程度较小,但召回率下降程度较大,考虑到CRF擅长计算标注的联合概率,而文本语句中相关联的两个实体标签可能距离过长,GRU能够更好地学习句子中长距离的依赖关系,因此模型性能效果较好。对于变种5,去除偏置权重后,准确率有一定提升,但召回率和F1值均降低。考虑到加入偏置权重的目标函数对于关系标签较为敏感,使无效标签的影响程度降低,因此提升了方法对于相关联实体的识别能力。对于变种6,去除自注意力层后,准确率、召回率以及F1值均降低,证明了自注意力层对于中文文本表示能力的必要性。
3.6 端到端的三元组抽取预测
为了进一步观察模型在知识抽取中的表现,对模型进行端到端的性能验证。即输入一个句子,然后输出该句子包含的所有三元组。其中三元组是(h,r,t)的形式,h是主实体,t是客实体,r是两个实体之间的关系,predicate代表关系预测的可能性。表3、表4展示了部分科技资源文本的三元组抽取预测结果。

表3 文本1的三元组抽取预测结果

表4 文本2的三元组抽取预测结果
从表3可以看出,关系是“毕业院校”的可能性最大,接近0.9,而关系“出品公司”和“出版社”由于两者语义较为接近,所以预测可能性差别不大。从表4可以看出,关系“目”的可能性达到95%以上,考虑到“目”可以算作专业词汇,同时后两者“作者”和“成立日期”由于语义相差过大,所以预测可能性几乎为零。通过以上内容,验证了模型在处理中文科技文本的知识抽取任务中的有效性。
3.7 偏置权重对模型的影响
模型引入偏置参数α来增强实体之间的联系。对于偏置权重参数α,当其取值为1时,表示目标函数没有使用偏置损失,对于包括“O”标签所有标签都使用一样的学习权重;当其取值较大时,表示倾向于忽视“O”标签的预测结果,但也可能带来精确率下降的问题。本文通过设置参数α的值为1.0,1.5,2.0,2.5,3.0,3.5,4.0,4.5,5.0,5.5,比较在不同取值情况下算法的准确率、召回率和F1值的变化情况,结果如图2所示。
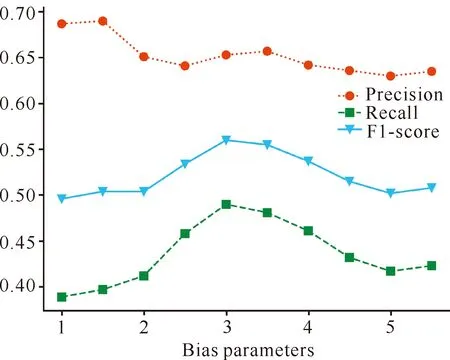
图2 不同取值下偏置权重的模型抽取效果
当α增大时,准确率呈逐级下降趋势;在α取值为3-4时,准确率达到最高。召回率整体呈先上升后下降的趋势,同样在α取值为3附近时,召回率达到最大值。F1值的整体变化情况与召回率类似。综上所述,当α取值在3附近时,模型能够获得准确率和召回率之间的平衡,从而得到最高的F1值。因此设置偏置参数α=3。
4 结论
针对中文文本语义特殊性和流水式抽取方法收敛较为缓慢的问题,本文提出了一种基于字词混合和GRU的科技文本知识抽取(MBGAB)方法,有效提升了针对中文科技资源文本的知识抽取的效果。采用一个基于GRU端到端的模型来生成标柱序列,双向GRU对输入句子进行编码,还有一个带有偏置损失的GRU编码层,最后使用带有偏置权重的目标函数来增强实体标签的相关性和降低无用标签的影响度。为了在最大程度上避免边界切分出错,同时为了存储更加有效的语义信息,本文设计了一种字词混合向量映射方式。同时,结合自注意力机制,针对中文科技资源文本进行知识抽取。实验结果表明,MBGAB在科技资源文本数据知识抽取任务中准确率、召回率以及F1值均有一定提升,验证了该方法的有效性。
猜你喜欢
智能计算机与应用(2022年9期)2022-09-28
北京航空航天大学学报(2022年8期)2022-08-31
汽车实用技术(2022年15期)2022-08-19
中国信息化(2022年5期)2022-06-13
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
北京汽车(2021年1期)2021-03-04
高中生学习·高三版(2016年9期)2016-05-14
长江学术(2016年4期)2016-03-11
新高考·高二数学(2015年11期)2015-12-23
