
基于时间卷积网络的科技需求主题热度预测算法*
2022-10-09 11:47崔海燕李雅文
广西科学 2022年4期
崔海燕,李雅文,徐 欣
(1.北京邮电大学计算机学院,智能通信软件与多媒体北京重点实验室,北京 100082;2.北京邮电大学经济与管理学院,北京 100082)
研究科技资源信息的主题热度时间序列变化规律[1],并根据已有数据分析结果对未来的科技需求主题热度进行预测,对科研人员快速了解和掌握科技领域资源信息动向至关重要。时间序列具有趋势性、季节性、周期性和随机性4种特征,要找到一个适用所有场景的通用模型几乎不可能,因为现实中每个预测问题的背景不同,影响预测值的因素与程度也不同,针对不同的问题要采用不同的方法和模型进行统计分析。现有的时间序列预测方法多适用于平稳序列变化预测,很少有针对科技需求主题热度的时间序列预测方法。基于以上问题,本文提出一种基于时间卷积网络(Time Convolution Network,TCN)的科技需求主题热度预测方法(Subject Heat of Science and Technology Demand Prediction Based on Time Convolution Network,SHDP-TCN),该方法融入科技需求的主题特征,关注时序变化特征以外的主题因素,并使用自注意力机制处理输入特征,使得网络重点关注局部历史信息,然后输入TCN学习全部历史信息,从而更准确地预测未来,最后通过实验验证所提方法在科技需求主题热度时间序列预测方面的有效性。
1 相关工作
目前针对科技需求主题热度预测的研究主要体现在对主题强度和主题内容方面的分析,即语义分析和时序分析结合的主题演进规律分析[2]。主题演化的时序分析主要通过构建主题演化时间序列模型,以人工解读为主来分析主题演化时序变化趋势;主题演化的语义分析主要通过计算主题词间的语义关联情况辅助进行。主题演进规律研究的结合点主要有基于主题间关联关系的网络分析法[3,4]以及主题结合时空的时序分析[5]、地区分布分析等。其中,主题间关联关系[6]演化规律的研究主要基于共词分析,按照具体分析方法的不同,共词分析[7,8]可分为共词网络分析、共词聚类分析和战略图分析等;主题结合时空的时序分析和地区分布分析主要是结合时空特性将多种科技资源要素结合起来,从多维度考虑实现科技需求主题演化分析。
目前常见的预测算法包括传统的时间序列预测模型如自回归积分滑动平均(Auto Regressive Integrated Moving Average,ARIMA)模型[9],神经网络[10]模型如长短时记忆网络(Long Short-Term Memory,LSTM)[11,12]和TCN,以及Prophet模型。ARIMA模型的缺点是要求时序数据具有稳定性,或者通过差分化后是稳定的;对于数据中存在缺失值的情况,需要先进行缺失值填补,这在很大程度上损害了数据的可靠性。LSTM可以记忆历史信息的序列预测,常用于金融股票预测。LSTM与循环神经网络(Recurrent Neural Network,RNN)[13]的主要区别在于,LSTM在模型中加入了一个被称为“记忆单元”(Memory Cell)的“处理器”,这个处理器可以根据规则判断信息是否有用。LSTM分为单变量预测和多变量预测,可以引入注意力机制进行建模[14]。TCN是单向的结构,不是双向的,只能由因到果,是严格约束时间的模型,因此,基于卷积神经网络(Convolutional Neural Networks,CNN)的TCN由于因果卷积不能看到未来的数据[15]。残差链接[16]是训练深层网络的有效方法,其网络以跨层的方式传递信息,且需要构建一个残差块来代替一层的卷积,一个残差块包含两层的卷积和非线性映射,且在每层网络中还加入了WeightNorm和Dropout来正则化网络[17,18]。相比RNN,TCN具有并行性、灵活的感受野、稳定的梯度、内存使用更低等优势。Prophet是基于可分解(趋势+季节+节假日)模型的开源库,支持自定义季节和节假日因素的影响[19]。
科技资源主题在时间序列上的热度变化不像金融股票[20]有着多变复杂的时间特征以及多项数据因素影响,而是具有数据量大且只根据前期长久时间段内积累的数据预测未来热度的特点与需求,所以应该选择基于循环神经网络或者卷积神经网络的时间序列预测模型[21,22],通过对已有的神经网络预测模型的分析,找到适用于科技资源数据热度预测的改进方法,对科技需求主题热度进行准确预测。
2 科技需求主题热度预测算法
为了预测科技需求主题在时间序列上的未来热度,采用神经网络模型进行数据内部潜在规律发现,并给出发展趋势的预期判断。对于时间序列的主题强度预测,主要以基于卷积神经网络的TCN对为基础,融入自注意力机制[23]以及主题特征对时间序列热度进行预测。
2.1 SHDP-TCN算法总体框架
TCN同时使用一维因果卷积和扩张卷积作为标准卷积层,并将每两个这样的卷积层与恒等映射封装为一个残差模块(包含ReLU函数);再由残差模块堆叠起深度网络,并在最后几层使用全卷积层代替全连接层。TCN的残差链接即残差卷积的跳层连接(Skip-connection)与微软的残差网络 ResNet[24]一样是经典跳层连接,上一层的特征图x直接与卷积后的F(x)对齐加和,变为F(x)+x(特征图数量不够可用 0 特征补齐,特征图大小不一可用带步长卷积做下采样)。在每层特征图中添加上一层的特征信息可使网络更深,加快反馈与收敛。
TCN不学习序列内部的距离位置依赖关系,也不提取输入的内部相关信息。自注意力机制是让机器注意到整个输入中上下文[25]的不同部分之间的相关性。基于此,本文提出一种基于自注意力机制的神经网络预测算法SHDP-TCN,该算法在序列输入到TCN的因果卷积之前进行自注意力机制编码,使网络除了拥有所有历史记忆外,还要考虑历史的时间步中不同的贡献权重,以此结构为基础,对输入序列的特征进行优化,即在输入序列进行自注意力编码前,通过加入类别特征,即主题词特征,加强对该行业热度在该时间节点的影响,从而增强预测准确度。
SHDP-TCN主要包括3方面:对输入序列特征加入主题词,然后接入自注意力机制对有依赖性的时间步的贡献进行捕捉,最后将序列输入到TCN网络中记住所有历史时间步信息,从而达到最终的预测结果,具体框架图如图1所示。
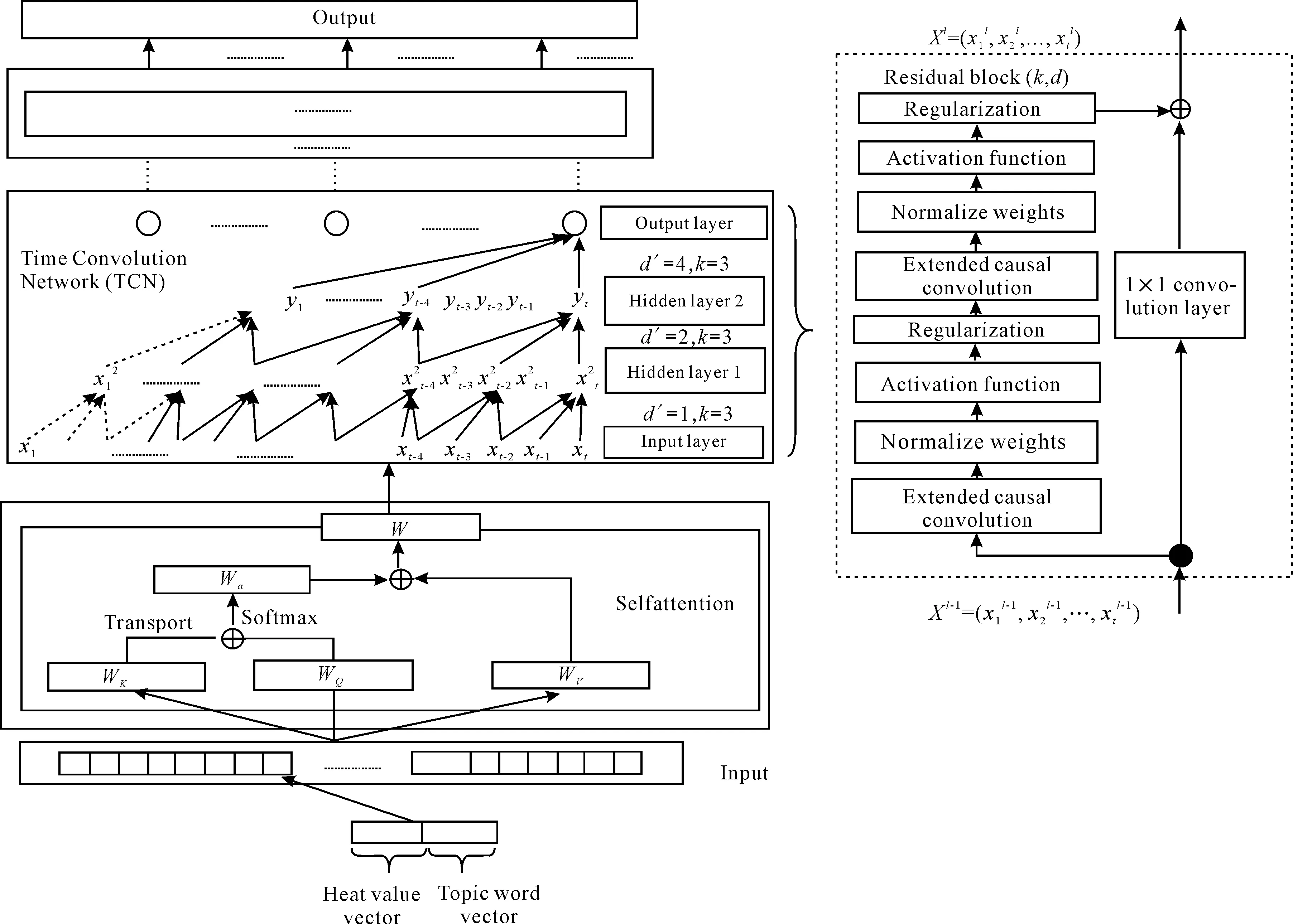
图1 基于时间卷积网络的科技需求主题热度预测算法框架图
算法流程:
基于时间卷积网络的科技需求主题热度预测算法
输入:科技需求主题热度在时间上的热度序列特征结合主题特征的输入向量
输出:科技需求主题热度预测结果
①输入向量线性映射到Q,W,V 3个不同空间;
②对映射的向量进行内积计算;
③将关注到重要信息的特征向量输入扩张视野的因果卷积,并进行权重归一化、激活函数、正则化操作;
④通过建立残差块形成多层网络训练;
⑤输出未来时间步热度预测值
2.2 基于自注意力机制的科技需求特征提取
将时间序列构成的向量输入到自注意力机制网络[26,27]中,自注意力[28]是针对序列内部不同位置进行关联计算,对于每个输入向量A,将输入信息线性映射到3个不同空间并建立查询和打分机制,计算句中字词之间的相关程度,通过偏向性地赋予较高的权重,使得模型更关注携带重要信息的字词。假设输入向量的序列长度为n,维度为d,通过3个不同的权值矩阵WK、WQ、WV将A映射到不同空间Q、K、V,权值矩阵维度均为Rd×d,使用缩放点积进行注意力计算的方式如下:
Q,K,V=AWQ,AWK,AWV,
(1)
(2)
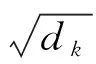
2.3 基于时间卷积网络的热度预测
TCN 的卷积层结合了扩张卷积与因果卷积两种结构,使用因果卷积是为了保证前面时间步的预测不会使用未来的信息,因为时间步t的输出只会根据t-1及之前时间步上的卷积运算得出。TCN的卷积和普通的一维卷积非常类似,最大的不同是用了扩张卷积,随着层数越多,卷积窗口越大,卷积窗口中的空孔越多。在TCN的残差模块内,有两层扩张卷积和ReLU[29]非线性函数,且卷积核的权重都经过了权重归一化(图1)。此外TCN 在残差模块内的每个空洞卷积后都添加了 Dropout 以实现正则化。跳层连接时直接将下层的特征图跳层连接到上层,对应的通道数channel不一致,所以不能直接做加和操作。为了两个层加和时特征图数量(通道数数量)相同,通过用1×1卷积进行元素合并来保证两个张量的形状相同。
TCN的因果卷积板块处理一个时间序列,需要根据序列X=(x1,x2,…,xt)预测出序列Y=(y1,y2,…,yt),设定滤波器为F=(f1,f2,…,ft),那么在xt处的因果卷积可表示为
(3)
其中,K表示一个视野中节点个数,k表示视野中第k个节点。
如果卷积的输入层最后两个节点分别是xt-1和xt,第一层隐藏层的最后一个节点为yt,滤波器F=(f1,f2),根据公式有
yt=f1xt-1+f2xt。
(4)
追溯的历史信息越多,就会有越多的隐藏层。如果第二层是输出层,那么最后的输出节点关联了3个输入节点;如果第4层输出层在最后一个节点输出,则关联了4个输入节点。
TCN的空洞卷积如图1所示,在xt处的扩张视野大小为d′的卷积计算公式为
(5)
第二层隐藏层最后一个节点yt,经过滤波器F=(f1,f2,f3),d′=2可以计算得到:
yt=f1xt-2d′+f2xt-d′+f3xt。
(6)
空洞卷积的感受野大小为(K-1)×d′+1,所以增大K或d′都可以增加感受野。一般情况下,伴随着网络层数的增加,扩张视野d′以2的指数增长,例如图1中d′依次为1,2,4。
TCN的残差模块主要通过输入序列,经过空洞卷积、权重归一化、激活函数、dropout作为残差函数,经历1×1卷积filter,作为shortcut连接。为了解决网络退化问题,通过让网络的某一层学习恒等映射函数,即把网络设计为H(x)=F(x)+x,只要F(x)=0,就有H(x)=x。随着网络深度越大,性能一直保持最优状态。
3 实验结果与分析
基于科技资源主题热度分布开展研究,主要是从时间角度分析主题热度随着时间变化的情况,同一领域同一应用方向的技术主题词热度分布情况,以及利用所采集数据中含有的科技需求信息的时间分布情况,由此进行时间序列的科技需求主题热度的变化分析。
3.1 数据集
收集并处理需求数据30 872条,经过数据清洗、规范化以及数据补全得到的企业技术需求可划分为多个行业领域,设定分类码进行区分(表1)。科技需求主题热度分析结果展示中,选择制造业在时间上的主题热度变化分析进行展示,并将主题热度变化作为预测原始数据。
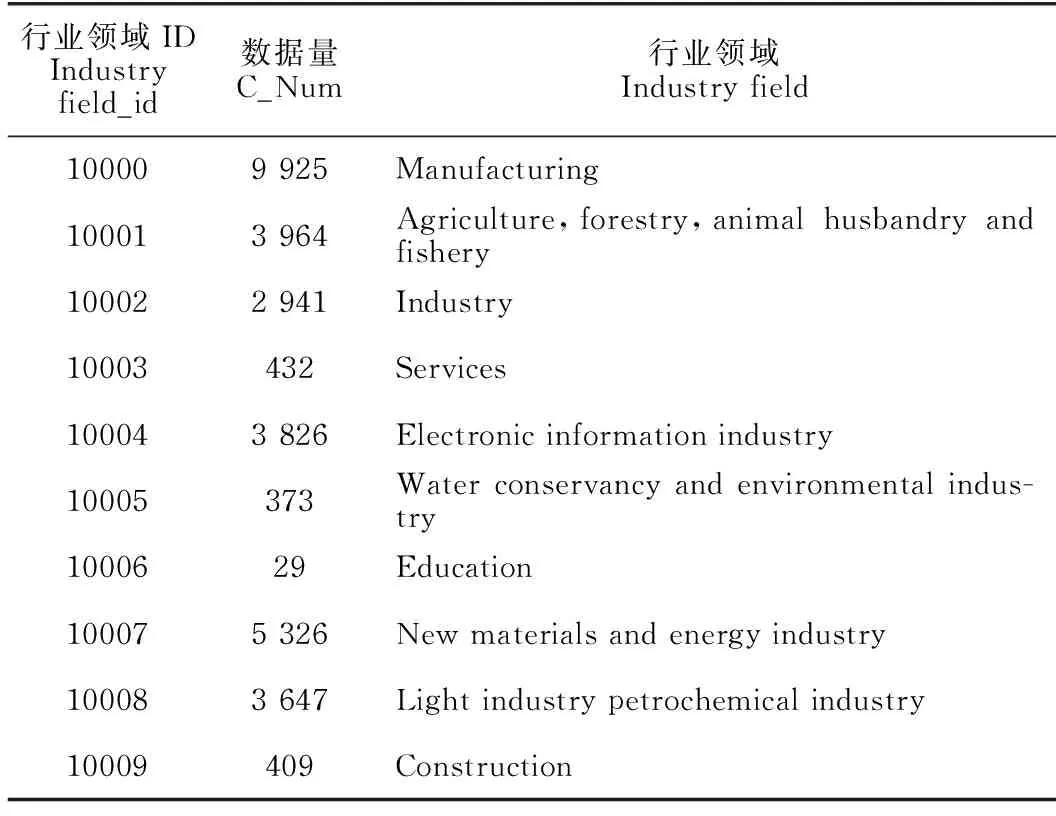
表1 科技需求所属行业领域分类表
3.2 对比方法
为验证本文提出的SHDP-TCN算法,选取ARAIM、LSTM、CNN[30]和TCN 4种相关算法进行对比测试。
3.3 科技需求主题热度分析展示
根据数据发布时间进行每个时间段的主题热度计算,热度值为该主题词在某个时间段出现的频次,用数据描述该行业领域企业技术需求中提取的每个热点主题的热度随时间的变化趋势,在指定时间段内主题热度值越高,代表在该行业领域中此应用热点在该时间段越热。
以“制造业”为例展示在2015-2020年期间二级主题热度随时间的变化趋势。由图2可知,制造业中的“自动化”整体处于最热门的技术应用点,“传感器”的热度值整体处于上升趋势,说明“制造业”正在向融入互联网技术发展。

图2 制造业科技需求主题热度随时间变化趋势图
3.4 基于时间卷积网络的科技需求主题热度预测实验
为了验证预测模型科技需求主题热度值在时间维度上的热度预测的有效性,使用真实的科技需求主题热度随时间变化数值序列数据对模型进行训练与测试。
原始数据是以月份为单位的时间序列,序列长度为126,时间跨度为2012.01-2021.06。数据集以2019年6月为窗口分界点,划分为训练集和测试集两部分。2019年6月之前的数据进入模型训练,并输出预测结果;2019年6月之后的数据为模型输出的测试集。第一组实验不加入主题特征,只对热度序列进行预测;第二组实验除了热度值外,还加入计算出的当月最高热度主题词。
设置ARIMA、LSTM、CNN、TCN算法参数:原始数值向量的长度设置为100维,加入主题特征的组合输入向量长度设置为150维,SHDP-TCN预测网络隐藏层的输出维度与输入保持一致;batch_size的大小设置为32,epoch的大小设置为32,学习率设置为0.000 01,训练时dropout设置为0.5;SHDP-TCN网络中隐藏层输出的激活函数使用ReLU函数。
为了评估本算法实体识别的效果,使用准确率(Precision)、召回率(Recall)以及F1-score等指标对主题热度时间序列进行预测效果评价,结果如表2所示。
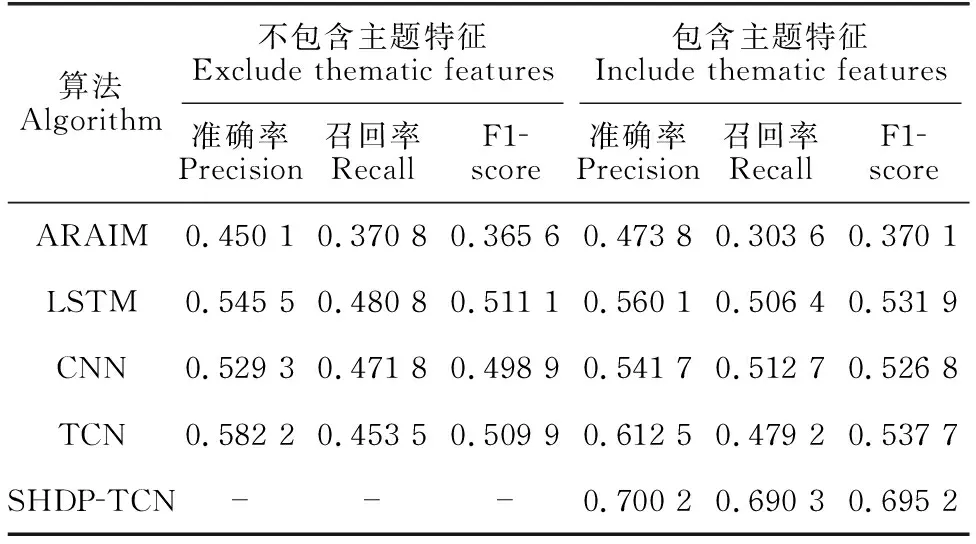
表2 5种算法对主题热度时间序列的预测效果对比
从表2的准确率和F1-score可知,传统ARMIA模型和深度学习模型LSTM、CNN表现均不如TCN模型,表明TCN结构在序列建模方面更具优势。因为ARMIA模型适用于平稳变化规律序列,LSTM只关注时间序列,未按时间步由因到果的特性预测,而TCN是在CNN基础上的改良,主要改进了算法运行过程中速度慢的问题,所以对于变化不稳定的科技需求主题热度,TCN能够捕捉全部的历史信息并学习,同时保证未来不会泄漏到过去,这两个特性使得预测效果更好。SHDP-TCN是在TCN融入时间步自注意力机制和主题特征,改进后的模型不仅关注序列历史规律,还加强了内部信息的联系以及主题因子的影响,所以SHDP-TCN的预测结果明显提升,模型性能优于TCN。
4 结论
本文提出了基于时间卷积网络的科技需求主题热度预测(SHDP-TCN)算法,利用科技需求数据主题的特点,针对数据的多维度特性,从时间序列角度对科技主题的热度变化趋势进行全面分析,发现科技大数据的科技主题热度变化特点。所提方法结合热度值以及主题词特征全面考虑预测相关参数,且通过自注意力机制对输入的特征进行局部重点信息提取,有效提高了预测的准确性。提炼后的科技需求主题热度序列经过TCN全面学习所有历史信息,实现对科技需求主题热度值的精准预测。所提方法能够把握科技需求的未来发展方向及科技需求主题热度的未来变化趋势,帮助科研人员更好地把握研究方向,实现社会企业需求与科研成果的衔接,促进科研成果的落地应用和转化。
猜你喜欢
黄河之声(2022年10期)2022-09-27
成都信息工程大学学报(2022年2期)2022-06-14
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
网络安全与数据管理(2022年3期)2022-05-23
中学生数理化·高二版(2022年4期)2022-05-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2020年10期)2020-11-14
电子制作(2019年13期)2020-01-14
北京航空航天大学学报(2019年9期)2019-10-26
