
云边协同区域能源互补决策模型与算法
2022-10-08 08:09:56唐帅庞凝李光毅彭婵贾宇琛郁五岳
智能电网 2022年5期
唐帅,庞凝*,李光毅,彭婵,贾宇琛,郁五岳
(1.国网河北省电力有限公司经济技术研究院,河北省 石家庄市 050021;2.河北农业大学机电工程学院,河北省 保定市 071000)
0 引言
在以新能源为主体的新型电力系统建设中,为了提高清洁能源利用率,借助信息技术实现各种能源之间的互动,以区域特色构建综合能源系统已成为能源转型过程中的一种重要方式[1]。所构建的综合能源系统称为“区域能源”,是指在某个特定区域内,根据能源结构和负荷需求,优化配置各种形式、各种品类的能源,从而实现节能减排目标的一套供用能解决方案。
为了实现区域能源的高效利用,必须建立科学的管理机制,数据收集和分析处理是需要重点研究的问题。随着物联网的兴起,利用各种感知器件和通信技术进行数据采集在电力系统中已被逐渐应用。针对综合能源系统用户侧负荷多样化、清洁能源利用效率低等问题,美欧各国相继展开了对综合能源系统数据获取的研究[2-4]。对应用物联网技术进行数据收集,以及探究大数据方法进行数据分析和处理,更多可借鉴的方法来源于对电力物联网的研究[5-7]。随着能源和用户的多样化发展,电力供需领域之间传递的信息量不断增大,导致的数据丢失和网络拥塞等通信问题,通过边缘计算的有效应用可得到解决[8]。实践中,基于边缘计算的能源管理已经在家庭用电方式中应用,其架构、关键技术和实现方法已被阐述[9-11]。边缘计算的作用是信息的本地化收集和数据断网续传,以保证信息完整性和数据可靠性,其强调的是通信低时延、算法轻量级、存储分布式,无法完成电力系统调度和综合能源系统的供用能决策建立。调度和决策还需借助云平台,边缘计算的分布式和云平台的集中式相结合,可以构建分布-集中式的联合控制系统[12]。利用边缘计算就近收集数据和预处理以达到数据的实效性,云平台则进行复杂数据的处理,实现电力系统“源-网-荷”的互动[13],而数据质量的优化和各个边缘之间的互动则主要由云来完成[14]。云边协同方法使边缘和云平台各自发挥通信和计算优势,实现能源之间的有效互动。
综上所述,区域能源数据获取与互动决策方法的研究主要集中在边缘计算算法和云边协同架构上,实践应用和模型规划大多局限于智能家居等较小的范围之内。含有众多微能网和用能多样化用户的区域能源系统运行优化,需要更完善的云边协同架构和云平台决策模型。
1 区域能源互补决策模型
区域能源要达到经济、稳定、高效运行,需要构建有效的优化调度算法[15],加强多个综合能源系统之间的互连互济[16]。区域能源系统内含有众多类型各异的用户以及各类微能网。
模型构建的条件包括:
1)区域能源中的微能网满功率出力。
2)微能网的售电和售热价格低于配电网和热力网。
3)区域内的用户具有优先选择新能源的权利和偏好。
4)区域内各个微能网具有内部互补机制。
5)区域内可调动的通信网络均畅通。
在满足以上条件的情形下,按照微能网的地理位置,区域能源被划分为n个子区域。每个子区域设置边缘计算控制网关,负责收集本子区域的数据,经过预处理后,周期性地将关键数据送至云平台。云端区域能源动态决策单元根据整个区域的能源盈亏情况,分类计算得到能源交互方案集,并以距离为主要参数计算能源交互收益,从而形成能源交互决策,下发指令到边缘计算控制网关。盈余子区域的边缘计算控制网关根据云端的指令,与能源短缺子区域通信,并输送能源到该子区域,实现区域能源系统的能源互补。区域能源决策与边缘计算控制网关构建的云边系统架构如图1所示。
云平台的动态决策单元,负责产生能源互补的决策规则。若以此为根节点,那么子区域边缘则为叶子节点,叶子节点的下一层是微能网,包含电源、热源和负荷。依据自上而下的规则,云平台建立周期性更新的动态区域能源互补决策池,并选择相关决策下发至子区域,子区域边缘解析后下发至所管辖的电源和热源,并根据指令与其他子区域进行信息和能源交互。具体步骤如下:
1)取t1为初始时间,所有叶子节点的数据,包括源荷特征、时空分布、初始储能、交互耦合等,汇总到根节点并转化为标准化知识,形成原始知识库。
2)对储存的知识进行属性、关系抽取,依据目标函数进行计算推理,构建初始决策池,将决策池中的规则分类筛选并下发到子区域。
3)子区域收到规则后解析并与本地目标进行匹配,匹配成功则执行根节点的决策,开启规则中设定的通道,与其他子区域进行信息交互;同时,开始计时并发ACK,并收集子区域叶子节点的数据;如果匹配失败,子区域向云平台发送拒绝该决策的ACK至根节点,按照其本地目标函数管理叶子节点,并开始计时。
4)当计时到根节点与子区域叶子节点约定的周期T时,子区域将收集的信息发送至云平台,新数据代入目标函数,形成新的规则放入决策池;在规则下发之前需要确定该规则的运行周期,同时新数据与原数据融合,进行关联度分析,预测出该规则的运行周期Tx,下发指令到子区域。
5)子区域解析并转发指令到E或者H节点,最下层叶子节点关联的物理设备开始能源的输送,并开始计时。
区域能源知识拓扑结构如图2所示。
在知识拓扑结构中,子区域边缘计算控制网关起到至关重要的作用,它不仅是决策的转发机构,在解析到规则信息不匹配时,这个子区域就成为整个网络中的一个“孤岛”,根据自己的目标函数,管理与之关联的叶子节点,实现孤岛内的能源调度,实现边端自治。
2 区域能源动态决策生成方法
2.1 子区域分类及功率盈亏分析
设一个区域能源系统划分为n个子区域,每个子区域内部含有电能和热能的互换装置,在周期Tx初始时刻有m个可再生能源盈余子区域,其盈余功率为
式中:Psp为盈余功率;Pes为盈余电功率;Phs为盈余热功率。
k个子区域可再生能源短缺,与负荷相关联,短缺的功率为
式中:Pst为短缺功率;Pel为短缺电功率;Phl为短缺热功率。
子区域之间进行能源输送以消费盈余子区域的能源,从而减少能源短缺子区域向电网和热力网购买能源的支出,共S种方案。
很显然,这种穷举的方法是不合理的,这些组合中有的方案是无法实现的。例如,当Pesi=0时,其仍然参与到Pelj的能源传输方案中,这一方案可以通过预处理剔除掉,从而降低后续的计算压力。预处理方法为
1)将盈余子区域按照盈余功率分为3类。
式中:Pes-only为只盈余电能;Phs-only为只盈余热功率;Pes-hs为电热功率均有盈余。
2)同理,能源短缺子区域按短缺功率分为3类。
式中:Pel-only为只短缺电能;Phl-only为只短缺热功率;Pel-hl为电热功率均短缺。
3)根据分治原理,遵循算法时间复杂度最小的原则,将能量转移关系分为5类,按照优先级别排序如表1所示。
考虑到能源传输过程中的损耗,应尽少占用线路,由于子区域本地电能转化热能比较容易,在定义优先级别时电能盈余为最高级别;其次为热能传输,因为很多微电网会产生余热,优先进行子区域内多能互补;子区域内部互补优化后,才进行子区域之间的互补;最后考虑电热同时输送,这种情况下的线路损耗最大。
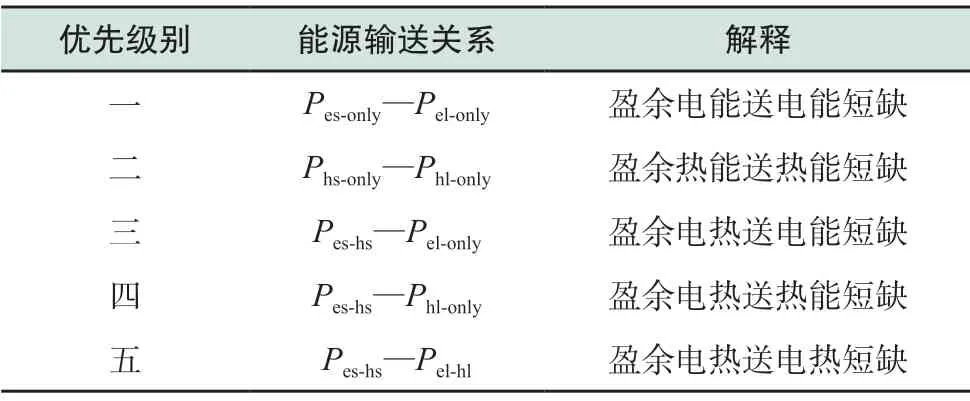
表1 能量转移关系分类表Table 1 Classification of energy transfer relationship
4)计算每一种组合中两个集合元素的个数,从而形成以下能源输送方案集合。
2.2 云端决策池的构建
云端区域能源动态决策单元根据边缘传输过来的数据进行计算,结合历史数据算出各子区域的能源输送决策,称为“云端决策池”。云端决策的依据包括能源传输距离、子区域能源出力原始成本、价格机制等因素。
首先计算能源传输距离,根据盈余子区域优先的原则选定第i种能源转移方案,其中含有ai个盈余功率子区域,bi个短缺功率子区域,计算这种方案的距离矩阵。
然后,设定能源输送周期为Tx,计算该方案下子区域新能源建设平均到每个周期所需的成本。
能源输送过程中无论是电还是热,都会有线路上的损耗。设输送电能每千米线路平均损耗为Pekm,输送热能每千米线路平均损耗为Phkm。假设只有子区域之间的能源交换损耗,电网和热力管道网只是桥梁的作用,并不收取任何过网费用,因此子区域之间能源交互所获得的收益关系可表示为
式中:ρesell为盈余子区域的电能售出价格;ρhsell为热能售出价格;ρebuy为能源短缺子区域的电能购入价格;ρhbuy为热能购入价格;ρnetwork为电网售电价格;ρheat为官方热能价格。Ti≤Tx为第i种方案的能源转移时间,小于设定的周期。当>0时,说明这种方案对于整个区域来说是有盈余的,所以这种方案放入决策池,否则丢弃该方案进入下一组计算。以此类推,形成第i种方案的决策池。
第i类子程序算法流程如图3所示。
依据表1所示的5种方案,总的决策池为
云端决策池中的计算和构建的算法流程如图4所示。
2.3 云边协同的决策下发规则
当子区域边缘计算网关上传数据完毕后即向云端请求下发指令,开启云边协同的决策下发流程。云端在根据边缘数据形成决策池后,以盈余子区域优先的原则,根据边缘子区域的请求,对决策池中的决策进行搜索,将关联该子区域的r条决策筛选出来;将r条决策的 bf进行降序排序,排在第一的作为首选进行下发;设置 bf阈值,若首选决策出现故障,则启用备用决策;云端将选择的决策同步下发到盈余子区域和短缺子区域,促使两个子区域之间构建通信链路。
两个子区域接收到决策指令之后建立通信链路并各自发送认证信息完成握手,并开启能源输送。边缘控制器将能源输送的指令下发到本地的电源,借助公共网络进行能源传送和接收。同时,边缘计算装置开启新一轮的数据收集和计算,待能源输送完毕或者计时周期完成后开启新一轮的数据传送。图5所示为一个能源盈余子区域和一个能源短缺子区域与云端协同进行能源互补的示意图。
3 云边协同区域能源决策关键技术
3.1 子区域信息收集关键技术
子区域信息包括与供用能相关的气象信息,各种计量表的信息,新能源出力与储能相关信息,以及控制装置信息等。图6所示为风光互补微电网边缘控制系统示意图。
此系统为边缘控制器为主站,各类采集和执行设备为从站的结构,主从之间采用Modbus协议通信。以此系统为例总结边缘数据收集、计算、控制的关键技术:边缘控制器通信、边缘数据处理、从站协调器信息感知、边缘控制节点定位等技术。
边缘计算是云计算本地化的一种方式,以达到业务剧增时减轻云平台的压力,节约时间和保护隐私,以及物理分散性提高平台运转效率[17]的目的。常用的边缘控制器通信协议主要有TCP和MQTT[18]两种,在阿里云、腾讯云、OneNet等云平台均有相关的SDK,以便于云边协同的开发。边缘计算的核心是数据本地化AI智能分析,但是由于对边缘需求的信息实效性、设备经济性、本地联动性等,因此边缘控制器所搭载算法的时间和空间复杂度受到限制。一般的排序、筛选算法,轻量级的粒子群算法、神经网络构成边缘软件平台[19]。分布式存储以备断网续传是边缘控制器的另一重要功能,边缘数据是一种海量小数据[20],传统的关系型数据库不再适用。并且边缘数据大多为传感器数据,具有很强的时序性,基于时间戳索引的时序数据库是边缘数据库的首选[21]。本例中,边缘控制器需要与其他边缘进行信息交互,云平台要获取边缘的位置用于决策收益的计算,边缘定位技术必不可少,简单的方法是在边缘计算控制器上搭载GPS、北斗等定位模块采集位置信息。
3.2 云端决策生成关键算法
云端决策的第一步是对子区域送上来的关键数据根据关键字进行广度优先搜索。从图2所示的区域能源知识拓扑结构可以看出,数据源本身为星形网络的(n,k)图,第一步从图中搜索到能源盈余子区域和短缺子区域,优化原始图的结构,涉及到的关键算法是独立生成树算法[22]。从边缘层来看,搜索过后的数据可以分为两类:能源盈余和能源短缺。要达到能源互补的目的,需要将盈余子区域与短缺子区域进行排列组合,若将所有盈余与短缺进行排列显然不合理,因此第二步是对数据矩阵分类。模型中涉及电、热两种能源形式,又分为盈余和短缺两种状态,属于多类分类。目前比较先进的算法是多源在线迁移学习多类分类算法[23-24],对于区域能源系统这种不平衡数据源的数据分类比较有效。
能源盈余子区域与能源短缺子区域构成联盟进行能源互补,实际上属于微能网联盟与配电网之间的博弈,必然需要进行功率的协调和收益的计算,目标是达到两个子区域微能网系统的优化运行[25-26]。基于博弈理论的多微能网的优化运行控制是云平台计算的第三步,进行不同联盟收益的计算,涉及到子区域之间的距离计算、成本计算、收入计算、损耗计算等,最后算出每一种联盟的收益,形成以收益为衡量标准的决策池。
最后一个步骤:云平台决策指令下发。这一步骤中最重要的是对决策进行排序,根据数据量选择不同的排序算法。模拟了长度分别为103、104、105、106、107的数组,针对常用的8种排序算法进行实验比较,结果如表2所示[27]。
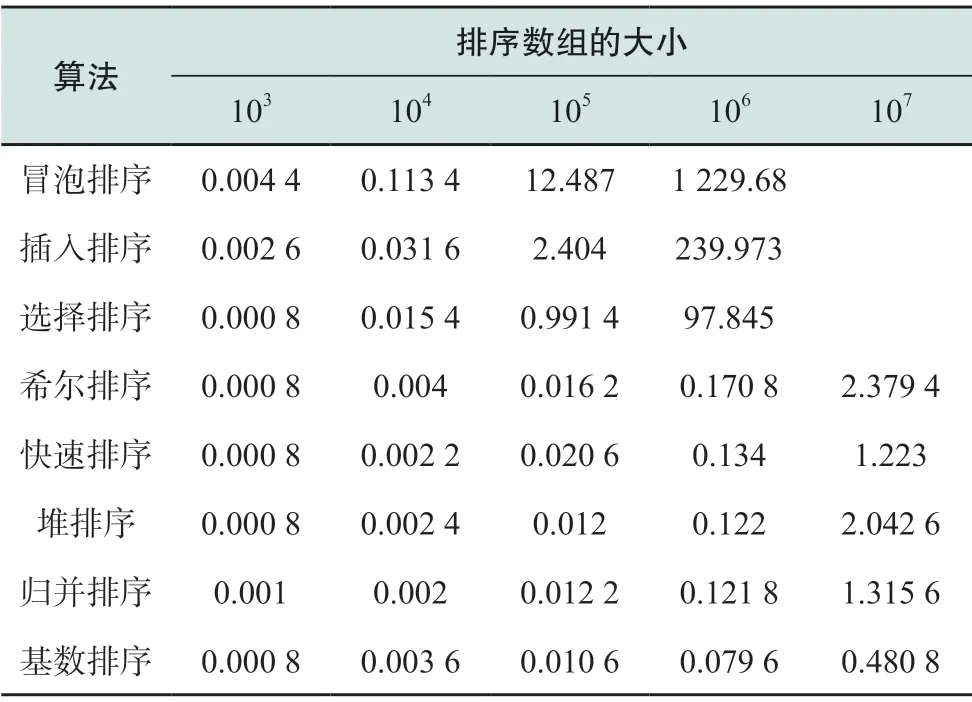
表2 依据数组大小的排序算法执行时间比较Table 2 Comparison of execution time of sorting algorithm based on array size s
可以看出,数组规模小于104时,各种排序算法的执行时间相差不大。随着数组规模的增大,希尔排序、快速排序、堆排序体现出优越性,但是冒泡排序、插入排序和选择的算法复杂度小。因此,云平台选择排序算法时可根据数据规模自适应选择合适的排序算法,达到执行时间与复杂度的平衡。
4 结论
本文提出的云边协同架构和云平台决策模型,为提高区域能源互补水平和新能源利用效率提供了一个可行方案。
1)构建了基于物联网、边缘计算、云计算的云边端信息收集和处理模型,并提出了边缘子区域数据收集的关键算法。
2)重点阐述了云平台的区域能源动态决策单元的知识结构;根据边缘子区域的关键数据,以距离为依据、收益为条件,在云平台构建了能源盈余子区域和短缺子区域的能源交互决策池。
3)根据对能源决策池中的收益排序结果和收益阈值制定了指令下发规则,分析了边缘之间的信息和能源互动策略,为实现云边协同的信息和能源互动提供了可行的方法。
由于目前数据量不足,未来将进一步收集数据进行模型和算法的优化。
猜你喜欢
现代计算机(2023年20期)2024-01-08 12:14:06
中国注册会计师(2021年9期)2021-10-14 07:13:54
中国交通信息化(2021年6期)2021-08-13 09:03:50
青年文学家(2020年28期)2020-11-02 13:20:37
东坡赤壁诗词(2020年3期)2020-07-04 02:50:05
现代装饰(2020年5期)2020-05-30 13:01:58
中国外汇(2019年10期)2019-08-27 01:58:00
丝路艺术(2017年5期)2017-04-17 03:11:50
初中生(2017年3期)2017-02-21 09:17:43
小学生优秀作文(趣味阅读)(2017年3期)2017-02-11 03:11:31
