
基于BERT的智能制造装备命名实体识别方法
2022-10-03 05:17傅源坤柳先辉赵卫东
制造业自动化 2022年9期
傅源坤,柳先辉,赵卫东
(同济大学 电子与信息工程学院,上海 201800)
0 引言
近年来智能制造行业受到广泛的关注,在构建智能制造装备分析领域时,命名实体识别是智能制造装备分析的基础工作。其中,对于智能制造装备来说,当中的命名实体不但涉及多个子领域,而且智能制造装备命名实体长度不一,种类复杂;智能制造装备描述中往往伴随多个意思相近的词,以及多个词并列的情况。命名实体识别的模型需要有足够的语料库来进行训练,使智能制造装备文本中的句子语法表述和语义信息能够被包含在词语的表示当中,进而提高实体识别的准确度。但由于该领域目前缺少已标注的专业语料库,针对上述的问题,本文以智能制造装备的专利为例,构建智能制造装备专利方面的命名实体识别语料库,提出了基于预训练模型的中文智能制造装备命名实体识别模型,并取得了较好的效果。
1 相关工作
命名实体识别技术(Named Entity Recognition,NER)[1]按照业务需求可以将特定的实体从非结构的文本中识别出来。在初期,命名实体识别需要专家根据不同实体的特征构建不同的配套规则模板来提取实体。该方法依赖于已有的知识库和字典,并且对于不同领域的表述而言,存在所需要的关键词不同和相同的词语表达意思不同的问题。因此,该方法所需的时间很长而且难以覆盖全部领域。之后,有人提出将命名实体识别看作序列标注任务,即将每个字词都看成待标签的向量,通过标签的形式将字词划分成不同的实体类型。该类方法通过大量语料来训练标注模型,使模型代替专家来做实体特征的表示,进而达到识别的效果。这类模型中较为代表的有隐马尔可夫[2]、决策树[3]、最大熵[4]、条件随机场[5]以及支持向量机[6,7]。随着深度学习的兴起,在命名实体识别中开始出现了神经网络的影子[8],长短期记忆模型(Long Short Term Memory,LSTM)[9]便是其中的代表之一,它的优势于其可以学习长距离依赖的信息,并将这些信息融入到当前词向量中,这对于词在句子中的学习有了更好的效果。在长距离学习的基础上,Guillaume[10]等人引入条件随机场来增强约束条件,使预测的序列结果更加合理。Chang[11]等人提出了一种预训练模型,该预训练模型采用Transformer,Transformer的attention机制对于语境中词语的特征抽取有较好的效果。杨飘[12]、赵平[13]、杨春明[14]、郭知鑫[15]等人将预训练模型应用到命名实体识别领域,提高了中文实体识别的效果。其中,郭军成[16]、王传涛[17]等人分别在简历实体识别领域做出了不少贡献。
在本文研究的智能制造装备领域中,以专利文本为例,主要存在以下几个问题:
1)由于部分智能制造装备名字由多个词语组成,在实体识别时这类名字便会被识别成多个单体词语从而导致结果不精确。例如,对于名字“基于面向对象技术的数控机床辅助装置智能控制系统”的识别会被拆分成“数控机床”、“辅助装置”、“智能控制”、“系统”,使整体实体被拆分。
2)一个智能制造装备通常由多个模块组成、每个模块实体之间的词法描述存在近似的情况,导致实体识别不准确。例如存在“套筒”、“双向套筒”、“套筒轴”只识别出“套筒”的情况。
3)目前专门针对智能制造装备专利领域的命名实体识别研究还十分稀少,相应的语料库也还未见到。
本文提出一种基于BERT预训练模型的神经网络结构,使用预训练模型获得智能制造装备专利领域的词向量,并将该词向量作为BiLSTM网络的输入,接着结合CRF来增添约束条件使得获得的标记序列更加合理,进而确定实体的类型。本文构建了智能制造装备专利领域的语料库共1838个文本、8685个句子,并在该语料上进行实验,对比分析基于LSTM的方法、基于LSTM-CRF的方法以及文本的方法。
2 BERT-BiLSTM-CRF模型
本文采用的模型由三部分组成:首先通过BERT表示文本中的字向量;然后将字向量输入到BiLSTM模型中得到双向的状态序列,获得的各状态序列的结合其位置关系得到更完整的状态序列,并映射到标签类别中,之后对每一个映射标签类别进行打分,选取最优的分数值作为输出结果,并根据这个结果来预测标签序列;最后结合CRF中的状态转移矩阵对BiLSTM模型的输出序列进行约束处理,根据相邻标签信息得到一个全局最优标签序列,其模型的整体结构如图1所示。

图1 BERT-BiLSTM-CRF模型整体结构图
2.1 BERT
BERT采用掩码机制对双向的Transformers进行预训练从而代替传统的单向语言模型或者对单项语言模型进行浅层拼接的方法进行预训练的方式。在文本建模方面,BERT采用基于注意力机制的方法,让输入序列中的每个词都聚焦到其他词中,更好地实现语义层面的理解。BERT采用双向编码的机制更好地将词的上下文信息填充到词向量当中,使该词向量的表示更为准确。该模型的具体结构图如图2所示。
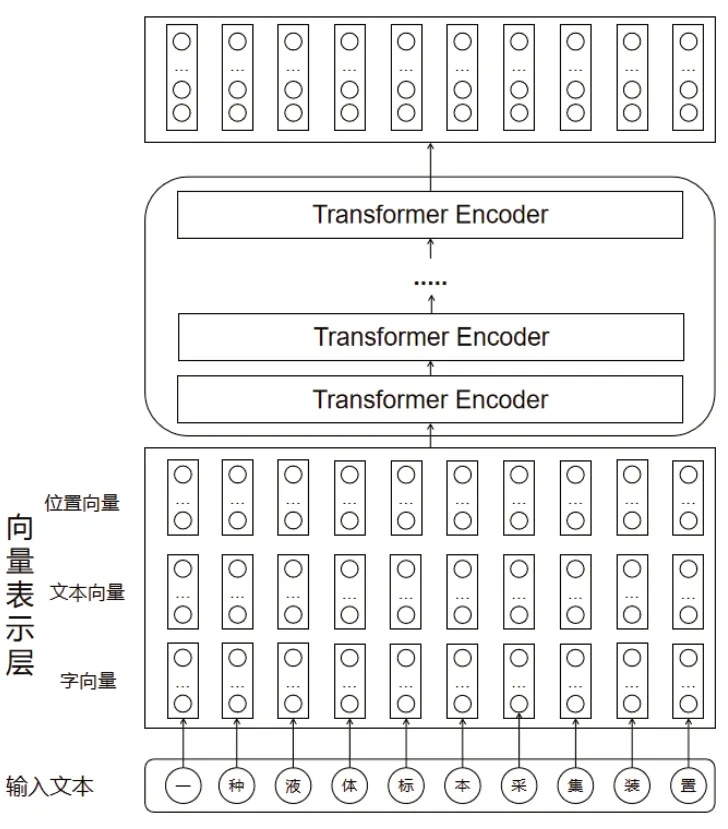
图2 BERT预训练模型结构图
2.2 BiLSTM
由于传统的RNN根据信息传递的机制,将之前神经元的输出信息作为当前神经元学习的一部分来表示当前字词与上文的信息关联特征,这种单线记录方式会导致RNN很难处理具有长期依赖的信息内容,在相同场景有类似词语出现在相同位置时很难做出正确的选择。LSTM通过引入“门”的概念来控制向后传递的信息量,从而可以达到筛选信息量的效果。门实质是一个σ函数,具体的有以下三种:遗忘门、输入门和输出门。如图3所示。

图3 LSTM细胞单元结构
1)遗忘门:选择要从传递过来的信息中丢弃哪些信息,其计算公式如式(1)所示:

2)输入门:选择与当前词相关的信息进行输入。式(2)表示上一个时刻输入的信息;式(3)表示细胞状态的候选值;式(4)表示当前细胞的状态:


3)输出门:根据细胞的状态来确定输出的值,其计算公式分别为式(5)和式(6):

上述式中,t表示时刻,h表示隐藏状态,x表示输入词,C表示细胞状态。
本文采用的BiLSTM是以LSTM为理论基础,通过采用双向传递的形式解决LSTM无法传递从后往前的信息的问题。
2.3 CRF
虽然BiLSTM通过判断每个标签的预测分数来选取最优的输出标签,但在正常的输出的标签当中,由于标签和标签中存在限制关系,单独根据BiLSTM输出的标签并不能完整的显示输出的标签情况,为此需要在BiLSTM输出的基础之上添加一层网络结构来引入标签之间的约束关系,形成最终的预测标签。
CRF(条件随机场)是一个序列化标注算法,作用为在输入标签序列的基础上增加约束关系来确保预测序列的输出更加合理。假设输入序列为X=(x1,x2,x3,...,xn),输出的标签序列为y=(y1,y2,y3,...,yn),则标签序列的分数如式(7)所示:
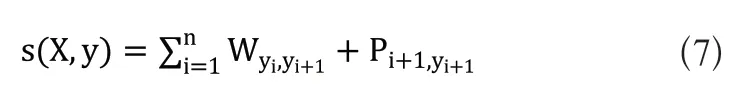
式(7)中状态转移矩阵为W,标签的状态转换分数值为Wyi,yi+1,对应位置为i+1的输入输出序列分数值为Pi+1,yi+1,则y的概率如式(8)所示:

式(8)中为真实值,Yx为所有可能的标签序列集合,通过极大似然估计法最终得到的标签序列,如式(9)所示:
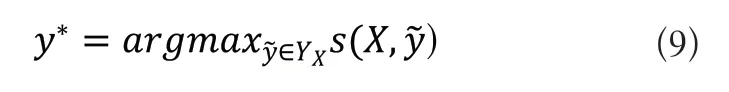
3 数据集及参数指标
3.1 数据集
本文采用的是自建数据集,所用的语料为自行收集的关于智能制造装备的专利摘要,通过对收集到的语料进行分析筛选,选取智能制造中具有一定代表性的类型(如数控机床、工业机器人等)进行实验,共得到有效摘要文本1838个。通过分析智能制造装备的专利摘要的特点,设置了三种实体类别,分别为智能制造装备的名称(NAM)、智能制造装备的应用领域(DOM)以及构成智能制造装备所涉及的模块部件(PAR)。各类实体的统计信息如表1所示。

表1 各类实体统计信息
本文构建针对智能制造装备的专利的命名实体识别数据集的标注处理采用的是BIO的方式,结合本文分类的实体类别,一共有7种待预测的标签类型,分别为:“B-NAM”,“I-NAM”,“B-DOM”,“I-DOM”,“B-PAR”,“I-PAR”,“O”。标注示例如表2所示。

表2 标注示例
按照实验要求,将数据集分为训练集、测试集和验证集,三者文本占比大致为71.11%、15.34%、13.55%,具体信息如表3所示。

表3 数据集组成情况
3.2 参数指标
本文采用的三个评价指标,分别为:准确率(P)、召回率(R)和F1值,这几项指标的值越高,表示模型的综合性能越好。各项指标的具体计算公式如式(10)~式(12)所示:


4 实验与分析
4.1 实验环境
本实验环境基于Ubuntu16.04,内存32G,GPU采用1080Ti(11GB)。软件环境包括Python3.6、Tensorflow1.12.0。
4.2 参数设置
本文模型参数设置如表4所示。

表4 模型参数
BERT-BiLSTM-CRF模型中,BERT采用谷歌的中文预训练模型,并对模型部分参数进行更新设置。本文根据对数据集中句子长度的分析发现,每个句子中的汉字数大概集中在200-300字左右,因此,最大序列长度设置为256个汉字,当句子长度大于256字时,从前向后截取前256个字作为输入,不足256个字的则采用padding的方法进行补齐,填充的内容为0。
4.3 实验设置
本文设置了与传统BiLSTM、BiLSTM-CRF的对比试验来进一步描述本文模型的有效性。
4.4 实验结果
4.4.1 模型实验结果
本文模型的识别结果如表5所示。

表5 各类实体识别的性能
从表5中可以看出,模型对于智能制造装备的专利领域的识别效果已经达到90%以上,对名字的识别达到了85%以上。由于智能制造装备的专利中,一个智能制造装备的组成部分往往有许多、部分专利中描述的组成部分占据了大量的文本内容,而部分装置的组成部分却比较简单,造成文本和文本之间存在一定的差异,其次智能制造装备专利中关于装置的组成部分含有一些不常见的部件表述,所以在识别起来存在一定难度,但本文所述的模型在组成部分方面也达到了80%以上的值。由于一个智能制造装备的专利文本中,包含的组成部分的数据往往大于名字和领域的数据,故最终结果会偏向于组成部分的性能。在现有有限的数据样本中,本文的模型结果仍能达到80%左右的识别水平。
4.4.2 相关对比实验
本文对下述模型在实验自建的智能制造专利数据集上分别进行多次实验,并对各个标签类型的实验结果进行汇总取平均值,具体的实验结果如表6所示。
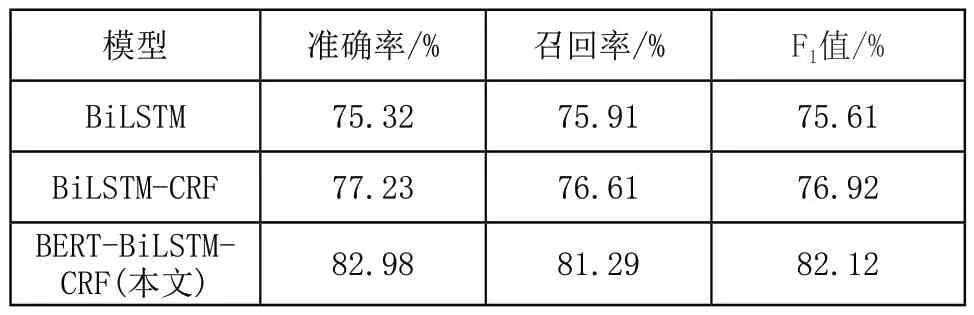
表6 各模型实验结果
根据对比实验分析,本文采用的基于BERT命名实体识别模型相比于其他模型在各项指标上都得到了一定的提升。
5 结语
本文针对智能制造装备的专利的分析,采用BERTBiLSTM-CRF模型,通过BERT预训练模型来表述文本的字向量,通过BiLSTM做上下文特征提取,最后采用CRF来达到增加约束条件的效果,使预测的标签序列更加规范合理。本文通过对智能制造装备的专利摘要进行命名实体识别,提取出专利的名称、应用领域和智能制造装备的组成成分。实验结果表明,本文的模型在自建的智能制造装备的专利数据集上与传统的方法相比,三项指标均占优势。这为后续智能制造装备的专利的进一步分析提供了基础,也为后续智能制造装备其余自然语言处理的工作提供了基础。在未来的工作中,该自建的数据集数据量还不足,后续仍需继续完善数据集;在数据集实体分类上,将增加组成部分的划分,平衡每个实体类别的数量。
猜你喜欢
军事文摘(2022年18期)2022-10-14
计算机系统应用(2021年11期)2022-01-06
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
华人时刊(2020年21期)2021-01-14
当代陕西(2019年5期)2019-03-21
海峡姐妹(2018年3期)2018-05-09
东方女性(2018年3期)2018-04-16
21世纪商业评论(2018年3期)2018-03-02
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
