
基于域适应互增强的多模态图像语义分割
2022-10-01 02:41谷小婧
计算机工程与设计 2022年9期
蓝 鑫,谷小婧
(华东理工大学 信息科学与工程学院,上海 200237)
0 引 言
语义分割已广泛应用于自动驾驶领域[1],无人车辆需要对周围环境进行感知、预测,然后计划并进行决策。仅利用可见光图像进行语义分割无法确保自动驾驶系统的鲁棒性,因为可见光图像的成像会受到周围环境的影响,例如大雾等能见度低的场景、夜间等光照亮度低的场景或强曝光的光照度过高的场景。
近年来,部分研究者引入红外(IR)图像以弥补仅使用可见光(RGB)图像造成的缺陷。红外图像根据高于绝对零度的目标发射的热辐射强度成像,具有不受光照影响、抗干扰能力强等优点。Ha等[2]提出基于编码器-解码器的MFNet,在解码器部分进行特征融合,由于并未采用预训练模型,虽然速度具有优势,但是精度较低。Sun等[3]使用预训练的ResNet[4]作为编码器,并将可见光模态和红外模态在编码器部分进行特征融合。Sun等[5]又使用DenseNet[6]作为编码器,进一步提升分割准确性。文献[3,5]都采用较大的模型作为编码器,因此参数量多,计算量大。Lyu等[7]在解码器部分使用分组卷积,减少了模型的参数量。
上述研究并未考虑不同模态间特征对不齐的问题。本文受域适应对齐特征[8,9]启发,提出了一种基于域适应互增强的RGB-IR图像语义分割算法。该算法首先利用高效特征增强模块(efficient feature enhancement module,EFEM)减少编码器与解码器之间的语义鸿沟,降低后续特征对齐的难度,然后使用多级特征聚合对齐模块(feature aggregation and alignment module,FAAM)聚合并对齐多尺度的模态内特征,再通过RGB和IR图像的相互转换来实现模态间的特征对齐并增强特征。最后,将生成的样本与真实样本混合作为新的输入再次送入分割网络,利用域判别器区分输入是何种组合,增强了训练数据,进一步优化分割网络。
1 基于域适应互增强的RGB-IR道路图像语义分割
1.1 模型整体架构
本文算法整体架构如图1所示,由3个主要部分组成:编码器-解码器网络M、判别器D和语义相似性网络S。图中实线表示训练的第一阶段,虚线表示第二阶段。其中编码器-解码器网络M包含编码器,分割解码器和转换解码器,RGB和IR支路具有相同的架构。使用ResNet-18作为M和S的编码器。测试时仅使用M中的分割编码器-解码器部分。Lce、 Ldomain、 Ladv、 Lfm和Lss分别表示网络中的不同损失函数。
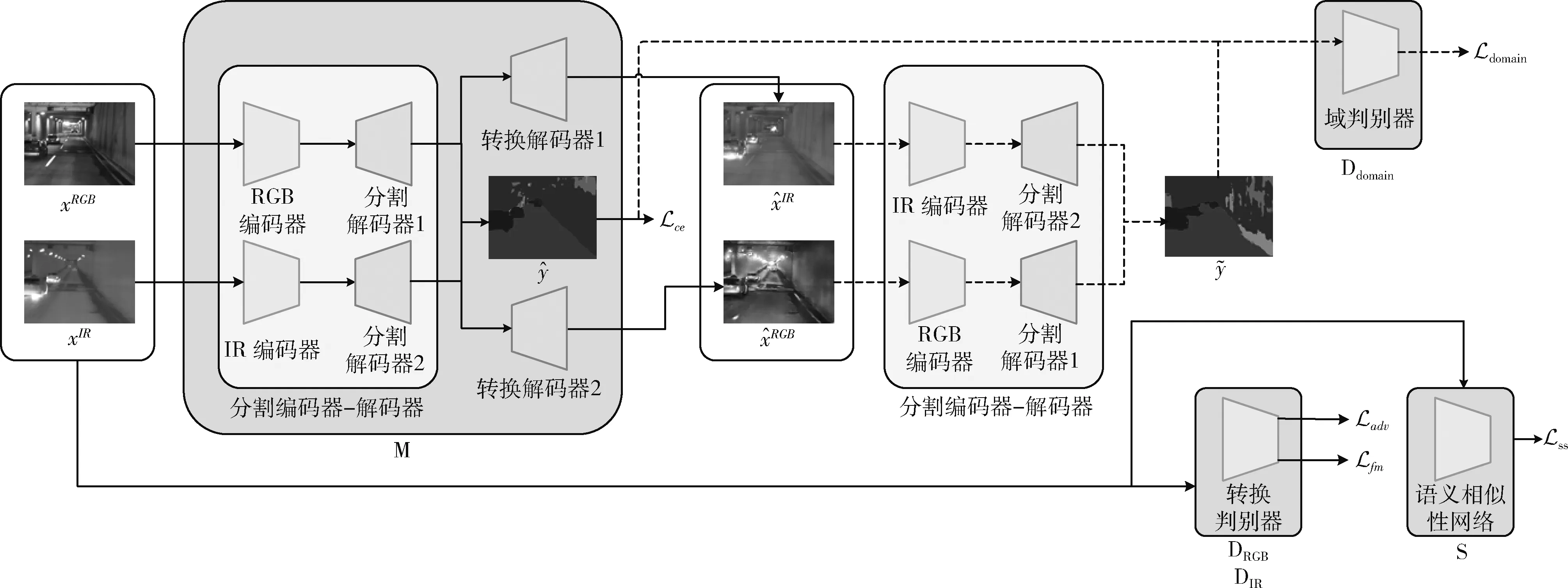
图1 模型整体架构
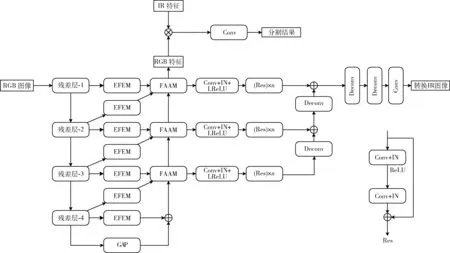
图2 编码器-解码器网络M架构
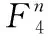
(1)
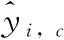
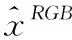
GAN可以生成高保真度和多样性的图像[12,13],因此,本文引入GAN来辅助图像转换。对于RGB输入图像,网络将其转换为IR图像,反之亦然。GAN通常利用判别器来区分输入来自真实图像还是生成图像,本文使用两个判别器分别对RGB和IR图像进行判别,GAN的训练过程可以看作生成器和判别器之间的零和博弈。
1.2 域适应互增强模块
由于RGB和IR图像之间存在域差异,部分融合方法需要经过精心设计,本文工作借鉴域适应方法,通过将一个模态的特征转换为另一模态的图像来强迫其学习互补信息,从而减少域间差异,并对齐和增强域间特征。
图像转换部分如图2所示,首先将FAAM的特征经过一组卷积进行变换,然后经过一系列残差块逐步学习图像细节,上采样使用转置卷积实现,最终生成转换后的图像。
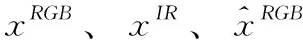
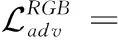
(2)
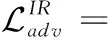
(3)
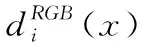
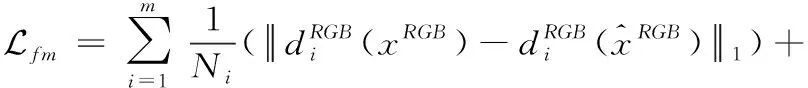
(4)
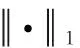
域判别器也采用PatchGAN,但是去掉了Instance Normalization,因为域判别器不用于生成图像。域判别器损失定义为
Ldomain=
(5)
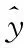
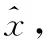
(6)
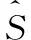
总损失定义如下
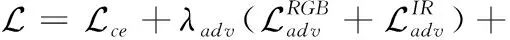
(7)
式中:λadv、λfm、λss和λdomain是各个损失的权重,用于控制损失之间的相对重要性。实验中,对抗损失使用最小二乘损失实现。
1.3 多级特征聚合对齐模块
本文模型为了保持轻量,在解码器部分采用了相加的特征融合策略,对于不同层级的特征,它们之间存在着特征对不齐的情况,直接相加可能会使得模型性能受到影响,因此,本节提出多级特征聚合对齐模块(FAAM),同时聚合并对齐来自不同层级的特征,具体结构如图3所示。
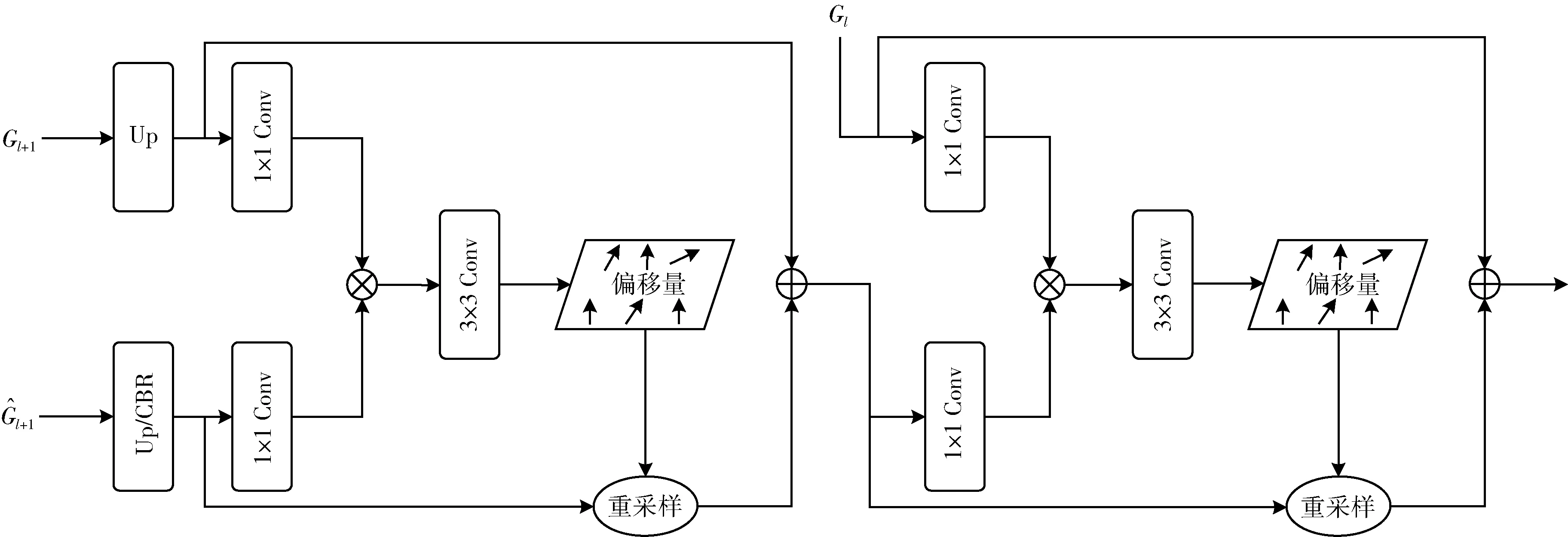
图3 多级特征聚合对齐模块
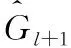
将偏移量加到原始坐标pl上从而得到新的映射后的坐标pl+1, 为了使训练稳定,偏移量使用长和宽进行归一化,公式如下
(8)
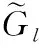
(9)
1.4 高效特征增强模块
本文使用了编码器-解码器架构,编码器和解码器之间通常采用跳跃连接。低层级特征包含高分辨率的纹理信息,高层级特征包含低分辨率的丰富语义信息。如果将编码器的低层级特征直接融合到解码器中,不同层级特征之间的语义鸿沟将限制特征融合的性能。
因此本节提出EFEM来解决该问题,EFEM可以缩短编码器和解码器之间的特征距离,保证特征融合的鲁棒性,模块结构如图4所示,图中Hl、Wl和Cl分别表示第l层残差块输出的特征图的高、宽和通道数,Conv表示卷积,DWConv表示深度卷积,BN表示批归一化。考虑到效率和有效性,EFEM首先使用1×1卷积将输入通道压缩到64维。利用深度可分卷积的优势,可以将特征先扩展到更高维的空间以增加网络容量[14]。再使用另一个3×3深度可分卷积以扩大感受野。最后,一个1×1卷积将深度可分卷积的输出投影回低维度,以支持跳跃连接。
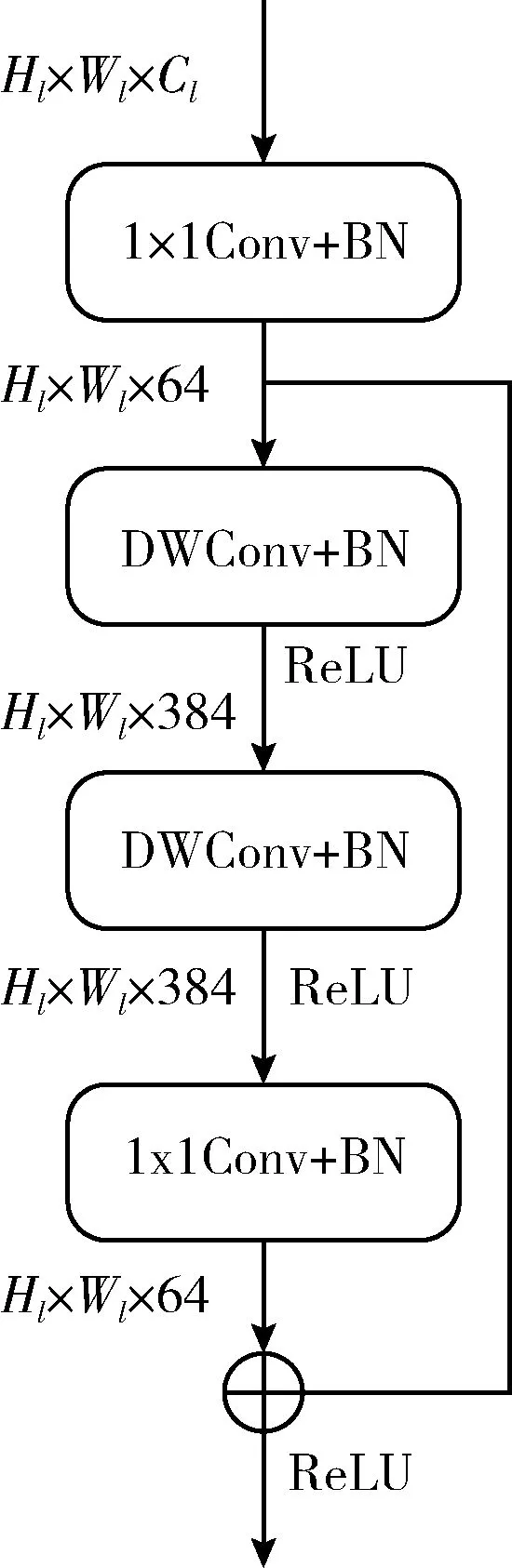
图4 高效特征增强模块设计细节
1.5 训练及测试策略
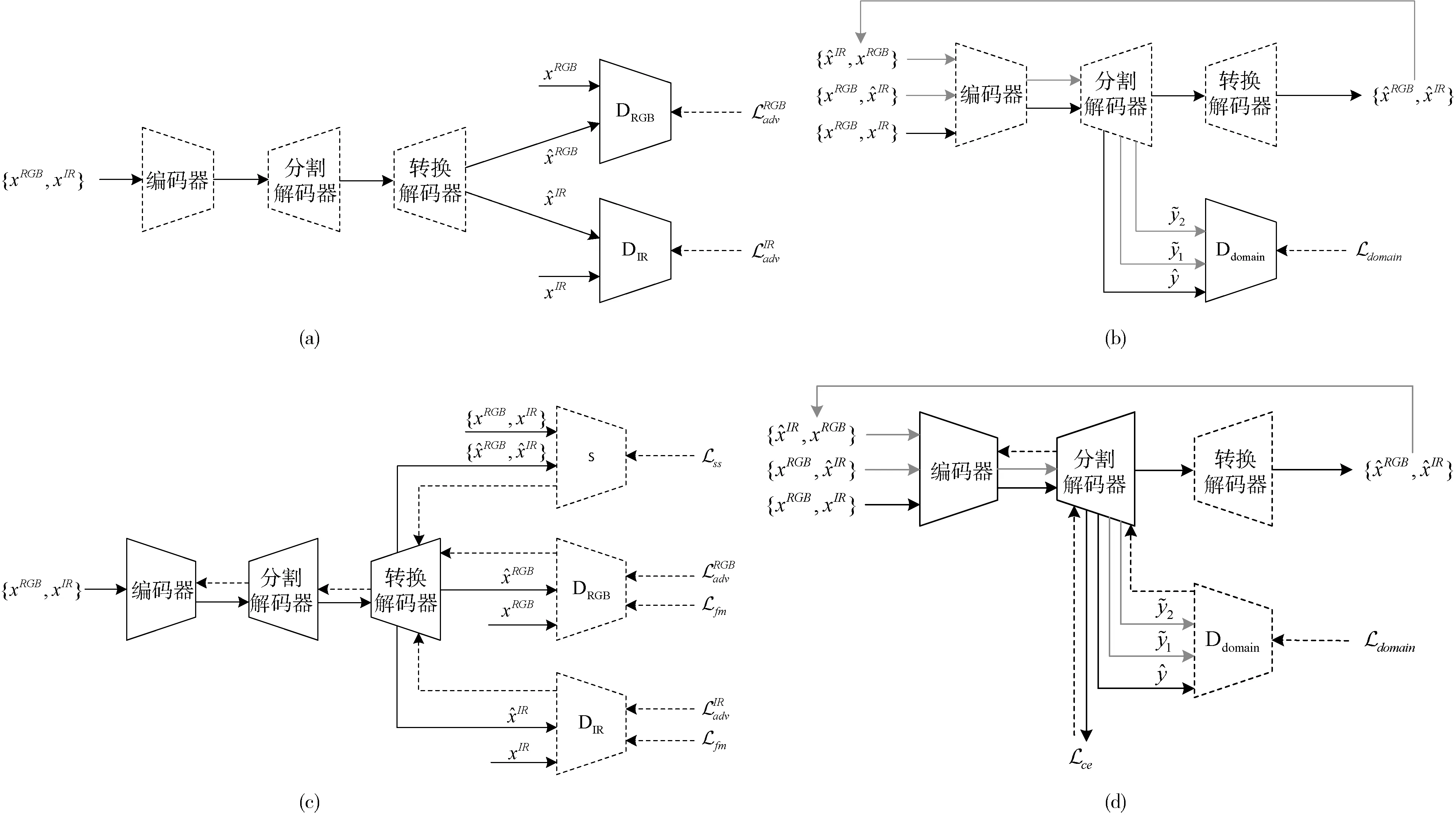
图5 模型训练流程
然后需要更新M的参数,此时冻结S和转换判别器D的参数,使用真实图像和转换图像计算损失并更新参数。最后利用分割结果计算交叉熵损失和域判别对抗损失更新分割网络参数。
由于本文目标是实现语义分割,图像到图像转换仅作为多任务中的辅助任务,因此,总损失中用于分割的交叉熵损失权重设为1,Dataset1的实验中其余损失权重设为0.1,Dataset2中λadv设为0.01,其余损失权重也设为0.1,以避免辅助任务对主任务造成过多影响,从而降低分割性能。
由于图像转换部分附加在分割部分之后,因此在测试时可以直接将图像转换部分直接去掉,在维持分割结果的情况下使得分割网络轻量化。
2 实验结果及分析
2.1 数据集介绍
本节实验主要在两个可见光-红外夜间语义分割数据集上展开。第一个数据集是Dataset1,是课题组自行构建的包含541张在夜间拍摄的城市街景图像的数据集,所用的可见光拍摄设备为索尼A6000微型单反,红外热像仪为FLIR Tau2336相机。图像的分辨率为300×400。该数据集中有13个类被标记,即汽车、自行车、人、天空、树、交通灯、道路、人行道、建筑物、栏杆、交通标志、柱子和公共汽车。对于场景中不属于上述物体或难以辨识的物体,将其设置为空类,即不进行标注。在模型训练与评估的过程中不包括空类。实验中将Dataset1分为两部分。训练数据集由400幅图像组成,其它141幅图像被分为测试数据集。
第二个数据集基于公开的KAIST多波段行人数据集,选择了行人和车辆较多的晚间的3组双模态图像视频流,从中选出200组RGB-IR图像对作为原始数据。图像的分辨率为300×400。该数据集中有13个类被标记,即汽车、自行车、人、天空、树、草地、道路、人行道、建筑物、栏杆、交通标志、柱子和障碍物。训练数据集由150组图像组成,其它50组图像被分为测试数据集。
2.2 实验设置及评价指标
本节实验在单个NVIDIA V100 GPU上进行训练、验证及测试,Pytorch版本为1.7,CUDA使用10.1版本,cuDNN使用7.6版本。使用PyTorch提供的预训练权重ResNet18初始化网络。使用Adam优化器训练网络,M中的编码器和分割解码器学习率设为0.0001,动量设为0.5和0.999,采用“poly”学习策略来逐步降低学习速率。M中转换解码器学习率为0.0002,动量设为0.5和0.999。转换判别器和域判别器的学习率都设为0.0001,动量分别设为0.5、0.999和0.9、0.99。训练周期设为100。在训练过程中,每个训练周期之前输入被随机打乱。使用随机水平翻转和随机裁剪来执行数据增强。图像输入网络前先使用镜像填充将图像扩大到320×416。本文实验采用常见的平均交并比(mIoU)来评估语义分割的性能。计算公式如下
(10)
式中:C是类别的数量,Pij是属于第i类被预测为第j类的像素数。该评价指标在分割结果中的得分越高,代表算法分割精度越好。对于图像生成质量的评价指标采用FID[15]分数,FID越低表示生成图像的质量越高。
2.3 实验结果及分析
2.3.1 先进算法对比及分析
本文先对比分析了不同先进算法的实验结果,对比算法包括本文提出的算法、MFNet、PSTNet、RTFNet-50、FuNNet和FuseSeg。对于RTFNet-50,采用ResNet-50作为骨干网络,因为比ResNet-50更大的骨干网络通常不适合自动驾驶。表1展示了不同网络在Dataset1上测试的定量结果。
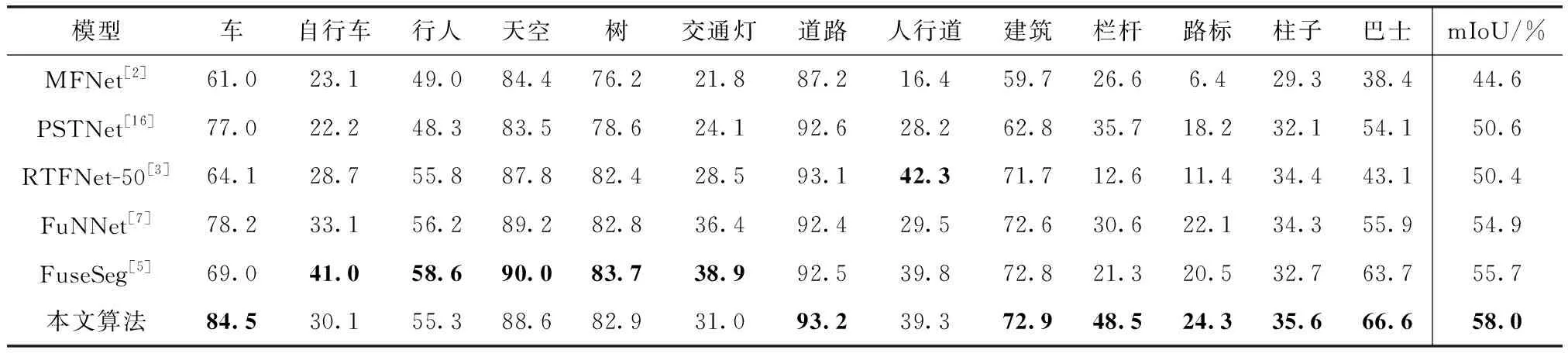
表1 不同分割算法在Dataset1上的对比结果
相比于采用了DenseNet的FuseSeg,本文算法仅使用ResNet-18就在Dataset1上取得了具有竞争力的预测结果,在“车”、“栏杆”和“巴士”类别上具有较为明显的提升。在该数据集中,本文算法有7个类优于FuseSeg,整体性能达到了最先进的水平。
此外,本文还对比了不同先进算法在Dataset2上的实验结果,以展示所提算法的泛化性。具体结果见表2。本文所提算法在“栏杆”、“路标”和“障碍物”等小目标上都有较为不错的分割结果。在大部分类别中也能取得有竞争力的结果,且mIoU一项在所有算法中达到了最高水平。图6展示了算法在两个数据集上的定性结果,图6(a)、图6(b)列展示了Dataset1的分割结果,图6(c)、图6(d)列展示了Dataset2的分割结果。
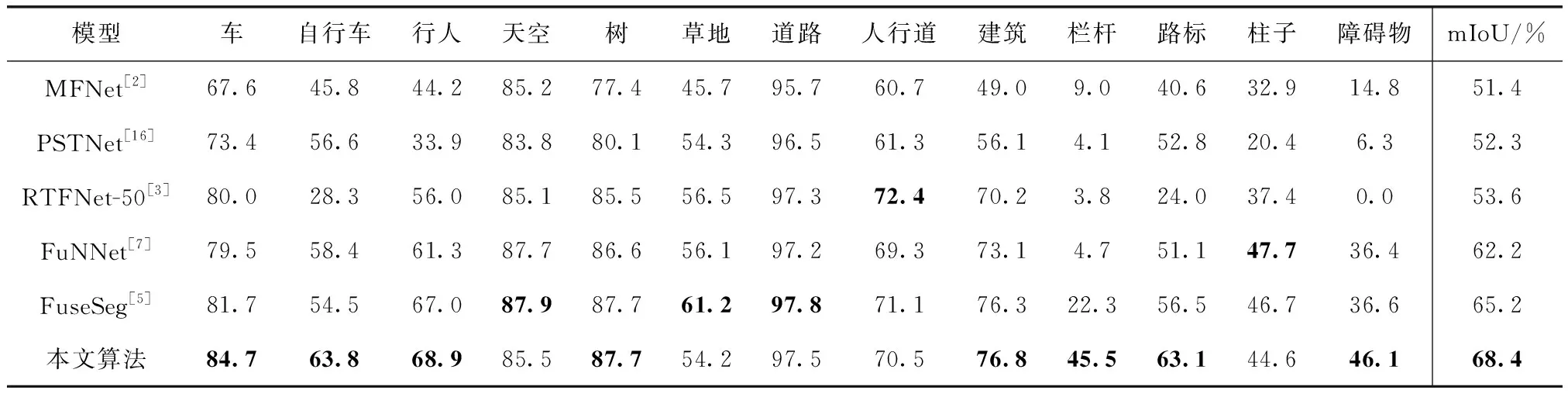
表2 不同分割算法在Dataset2上的对比结果
图7和图8展示了不同数据集通过图像转换生成的图像,可以看出,本节提出的模型可以转换较为明显的特征。对于夜间亮度过低的图像,由于图像本身特征较少,因此转换的图像质量也不高。

图7 Dataset1真实图像与生成图像对比

图8 Dataset2真实图像与生成图像对比
2.3.2 模型消融实验及分析
为了验证本文提出方法的有效性,本节对提出的模块在两个数据集上进行了消融实验,如表3和表4所示。基线模型表示不使用域适应、EFEM以及FAAM模块。

表3 Dataset1上的模型消融实验

表4 Dataset2上的模型消融实验
首先探究EFEM模块,EFEM模块分别在Dataset1和Dataset2上提升了0.6%和1.2%的mIoU,验证了前文讨论的编码器与解码器之间存在的语义鸿沟,EFEM减少了它们之间的特征距离,有利于特征在解码器中进行特征聚合的操作。
然后研究本节提出的FAAM,由表中数据可知,该模块为模型在不同数据集上都提供了明显的性能提升,Dataset1中提升了1.7%mIoU,在Dataset2中提升了3.1%mIoU。由此可见,特征对不齐对网络性能具有较大的影响。
接着,本节探究域适应对模型的影响,DA表示域适应过程,通过将其中一个模态转换为另一个模态,使得不同模态之间的特征进行对齐,从而优化分割结果。通过域适应,模型在不同数据集上性能分别提升了0.8%和1.0%。本节还探究生成图像再送入模型进行第二阶段训练的有效性,该想法使用域判别器实现,利用域判别器判别分割输出是真或假进一步提升分割结果,表中用DC表示,在Dataset2的实验中取得了3.2%的较大性能提升。因此,将生成图像再次送入网络可以取得进一步的性能提升,有效地利用了生成图像,在一定程度上实现了数据增强。
如前文所讨论的,FAAM用于特征对齐以及聚合。为了验证本节提出的FAAM是有效的,本节将FAAM替换为特征相加,再接1×1卷积或3×3卷积的操作,得到的结果见表5和表6。

表5 Dataset1上FAAM消融实验

表6 Dataset2上FAAM消融实验
可以看到,仅使用相加以及卷积的模型性能远不如FAAM,通过设计特定的特征对齐模块,可以更有效地对齐特征,提升网络的性能。
2.3.3 损失函数权重影响分析
由于本文实验使用了多个损失进行监督,因此设计对比实验验证损失函数权重对算法分割效果以及图像转换效果之间的影响。如图9和图10所示。
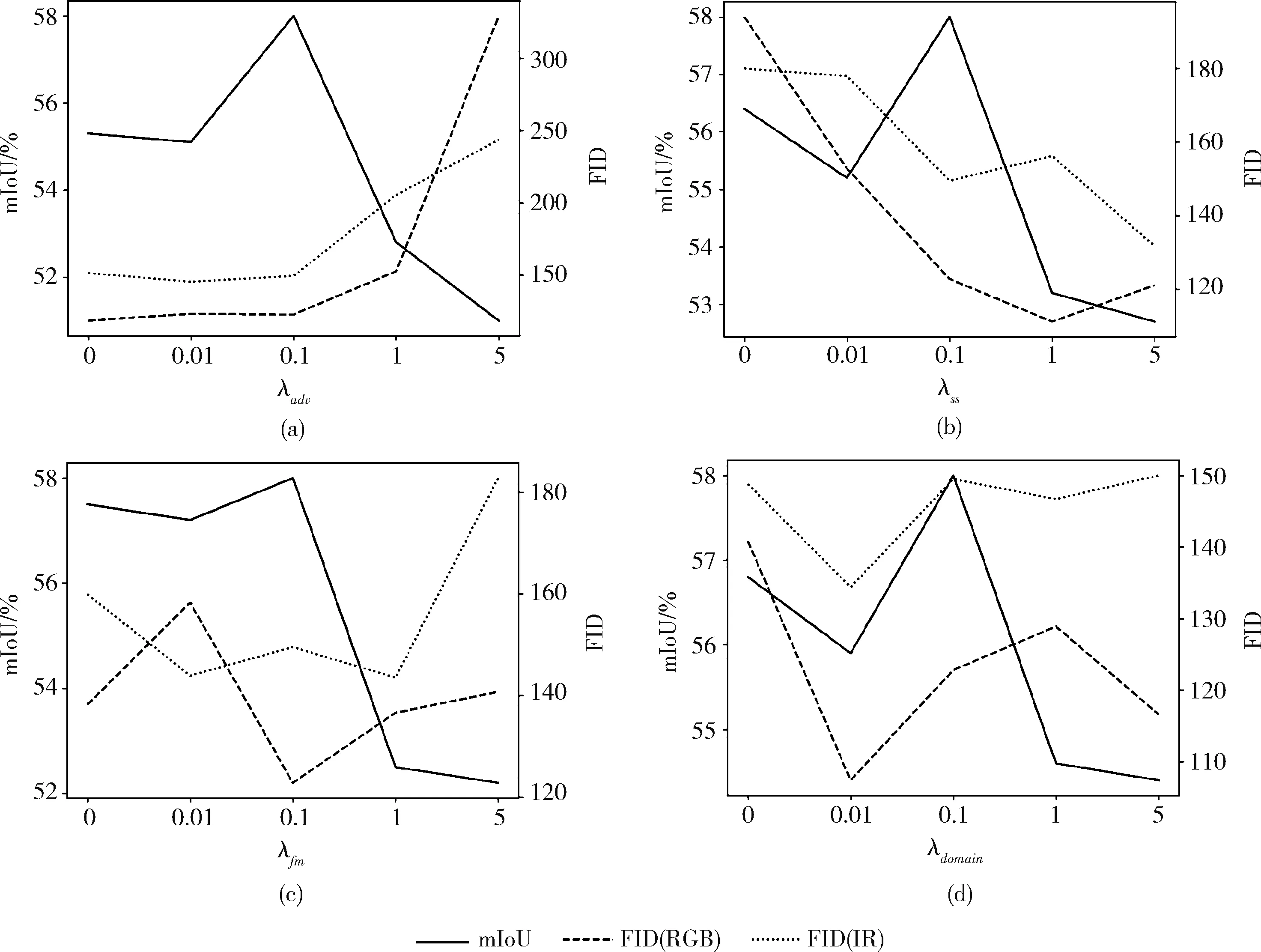
图9 Dataset1中损失函数权重大小对模型性能影响对比
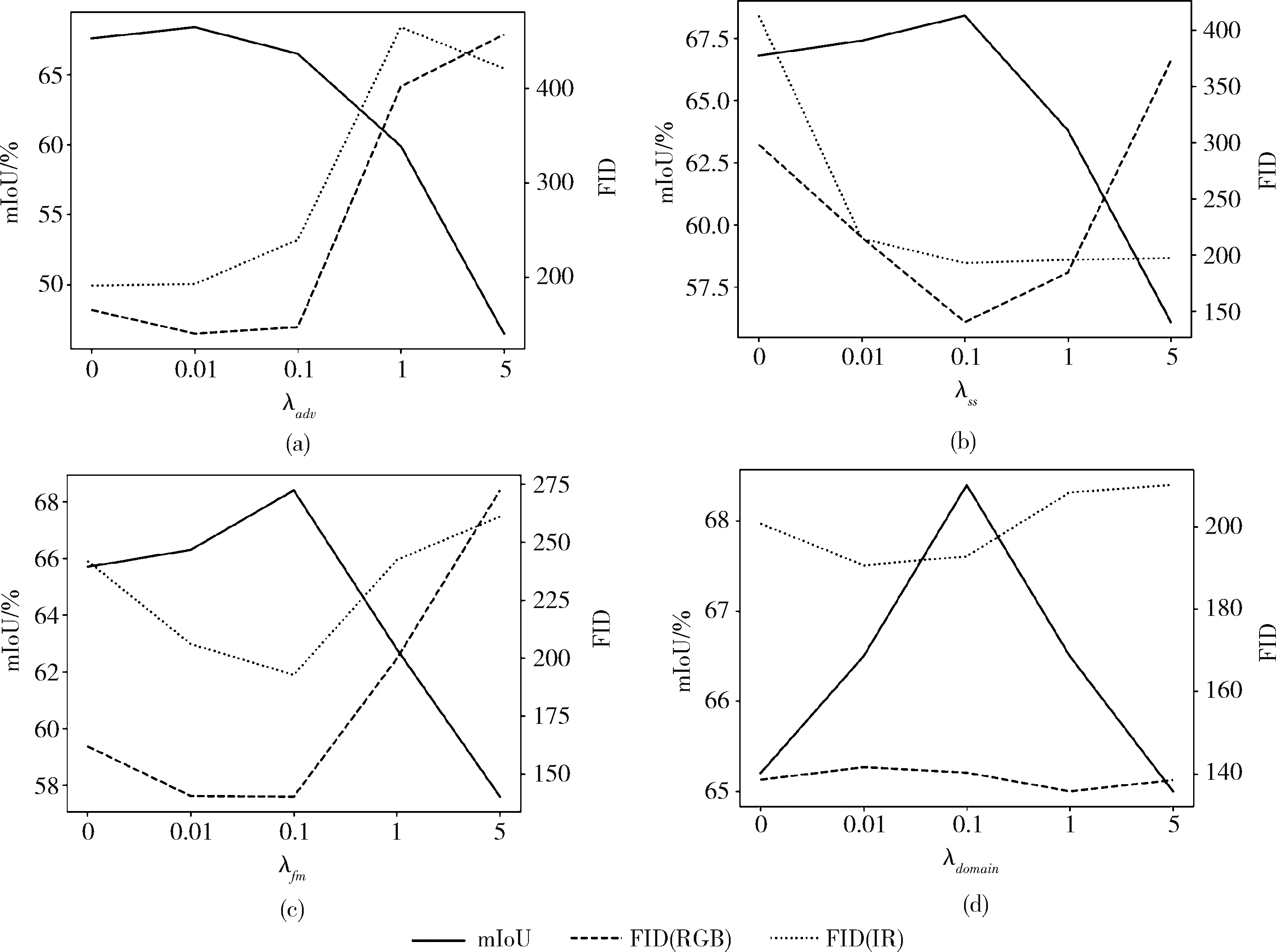
图10 Dataset2中损失函数权重大小对模型性能影响对比
图中展示了权重大小和分割性能以及图像生成效果之间的关系,权重使用了0、0.01、0.1、1、5这5个尺度,实线表示mIoU(越高越好),将其作为分割性能的评价指标;虚线表示FID分数(越低越好),将其作为生成图像质量的评价指标。由图中可以看出,整体来说,副任务权重比主任务权重小的情况下,分割可以取得较好的效果,当副任务权重过小,对主任务的帮助越小;当副任务权重过大,影响了主任务的训练,会导致分割性能下降。
一般来说,当分割任务性能最优时,图像转换质量也处于较好的水平,由此可以得出结论,图像质量优劣对分割性能有着正向影响。
2.3.4 模型复杂度分析
为了验证本文提出的算法的高效性,本节实验比较了本文算法和当前先进算法之间的FLOPs、FPS以及参数量,如表7所示。
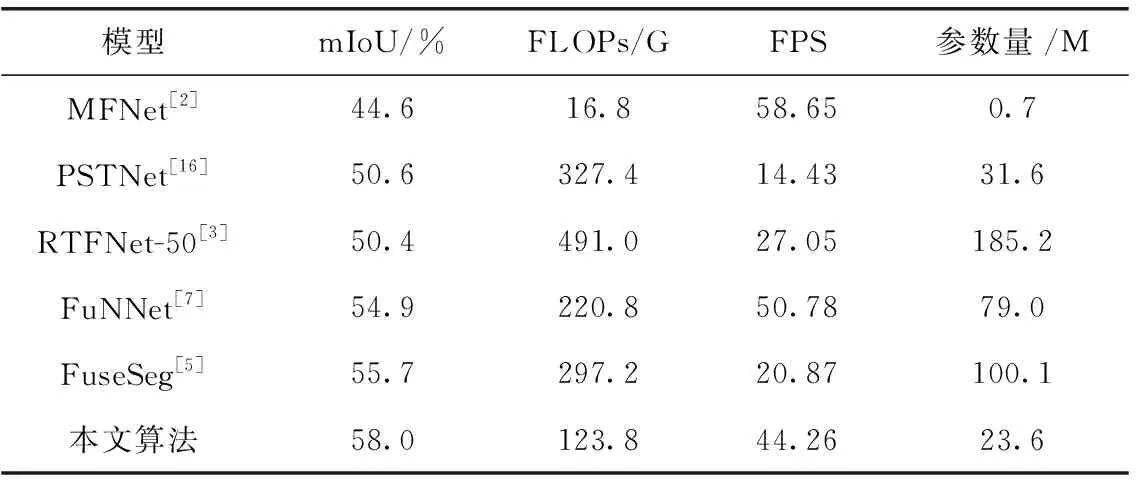
表7 不同算法复杂度对比
由于FuseSeg设计的特殊性,为了公平比较,本节选择480×640作为输入图像的分辨率。FLOPs、FPS以及参数量都在此分辨率基础上进行测试。FLOPs表示处理特定分辨率图像的浮点操作的数量。mIoU展示了不同算法在
Dataset1上的分割结果。从表中数据可以看出,本文算法相较于大部分算法都有更少的浮点操作数,参数量大大小于FuseSeg,且FPS也处于较高水平,实验结果表明了本文算法在准确性和复杂性之间取得了很好的平衡,在自动驾驶上相比于其它模型更具有适用性。
3 结束语
针对多模态图像语义分割模态内以及模态间特征对不齐的问题,本文提出了一种基于域适应互增强的RGB-IR图像语义分割算法。算法将语义分割和域适应相结合,利用域适应使分割模型学习到不同模态间的特征,实现特征对齐并增强特征。提出的高效特征增强模块有效地减少了编码器和解码器之间的语义鸿沟。此外,多级特征聚合对齐模块可以聚合不同层级的特征并对齐模态内的信息。生成的图像再次送入网络,增强了训练数据,进一步提升了分割性能。实验验证了本文算法达到了当前最优性能,设计的不同消融实验验证了所提出模块的有效性,另外还设计实验探究生成图像与分割性能之间的关系。本文算法相比于当前大部分模型降低了的复杂度,提升了实用性。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
网络安全与数据管理(2022年1期)2022-08-29
小学生必读(低年级版)(2021年10期)2022-01-18
科学技术创新(2021年5期)2021-03-17
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
——编码器
演艺科技(2020年7期)2020-08-13
开放教育研究(2020年2期)2020-03-31
家庭影院技术(2019年8期)2019-12-04
长江学术(2016年4期)2016-03-11
