
基于滑动窗口的移动图书馆用户行为深度挖掘算法
2022-09-29 00:56周黎源
自动化技术与应用 2022年9期
周黎源
(上海城建职业学院 图文信息中心,上海 201999)
1 引言
随着无线网络的普及应用,移动图书馆作为一种新型的图书服务方式正日益受到关注。因此,对用户的行为意愿进行挖掘也逐渐成为热门研究问题。陈小平等人[1]提出一种基于区块链理念的图书馆移动用户行为大数据挖掘方法,对用户行为进行去信任处理,使区块链之间达成共识,同时结合智能合约实现用户行为大数据智能挖掘。仿真实验表明该方法能够成功将大数据挖掘从网络信息服务转变成价值服务,但是该方法的行为挖掘准确率较低,挖掘效果较差。高永梅等人[2]提出一种融入位置情景的移动用户行为挖掘方法,该方法对影响用户行为的情景集合进行分析,并且通过问卷调查得出主要的情景因素,然后根据情景属性对用户的行为模式建模,给出基于网络结构的用户行为模式的挖掘方法,实验证明该方法具有一定的可行性。吴熹[3]提出基于VSM 模型的移动互联网用户兴趣度挖掘方法,通过构建带权的VSM 模型,以用户每天的上网内容和行为建立文档向量空间,利用TF-IDF 算法进行兴趣度的数据分析处理,将改造后的VSM 模型与TF-IDF 算法紧密结合,实现用户内容兴趣度和行为兴趣度的统一,构成综合用户上网兴趣爱好的二维VSM 模型,实现对用户上网行为和上网内容的深度挖掘。但是以上两种方法存在算法复杂的问题,导致用户行为挖掘时间较长。
针对上述方法存在的问题,本文提出一种基于滑动窗口的移动图书馆用户行为深度挖掘算法,由于使用单一的模型来接收预测用户的行为,并不能获得较为全面的结果,因此采用技术接受和整合理论对移动图书馆的用户行为分析,得到8种不同的影响用户行为意愿的相关因素,最后使用特征指数直方图结构,以8种因素为变量,完成数据挖掘全过程。
2 移动图书馆用户行为模型
随着用户行为研究的不断深入,使用单一的模型来接收预测用户的行为并不能获得较为全面的结果。因此,本文采用技术接受和整合理论对用户行为进行分析,其模型如图1所示。
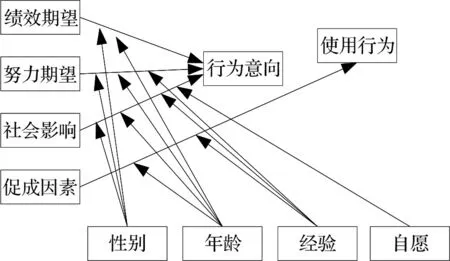
图1 UTAUT模型
UTAUT是一种以TAM(Technology Acceptance Model)模型为理论基础的高解释模型,在对不同领域解读时,能够对各个不同的外部相关变量进行整合,更准确的总结出用户的行为意愿,因此,本文根据移动图书馆用户行为的实际特点[4],对其进行完善,构造出适合的UTAUT分析模型。
从理论上来说,将用户使用移动图书馆的实际行为意愿作为客观的测定标准,能够使结果更为精准[5],然而其涉及数据量过大,不具操作性。因此,本文采用更便于操作的行为意愿来代替实际行为作为测定标准,加入8 种变量后,得出的UTAUT模型如图2所示。
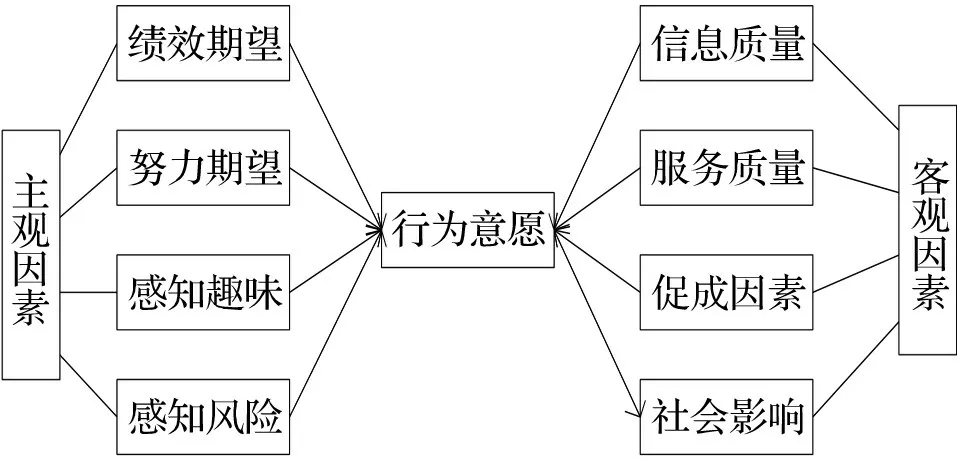
图2 移动图书馆用户行为模型
对图2中的各个变量进行解释如下:
(1) 绩效期望指的是用户对某个系统产生的预期效益估计,若某个系统能够提高工作绩效,则用户的使用意向更高。绩效期望对使用者的使用意愿有正向影响。
(2) 努力期望指的是用户在操作软件的过程中对使用难易程度的感知,它正向影响用户的行为意愿。
(3) 感知趣味性[6]是指用户在选择应用系统时,在考虑系统价值的同时还会关注使用过程中是否能够获得愉悦感。
(4) 感知风险是指使用者无法预判操作结果的正确性,在移动图书馆背景下,感知风险主要表现在用户使用过程中,其主观上预计需承担的信息安全风险,对用户行为意愿有负向影响。
(5) 信息质量为软件提供给用户的信息应具备有效性、完整性和准确性等,能够对用户的使用行为意愿产生正向影响。
(6) 服务质量为软件提供的服务是否能够满足用户的实际需求,正向影响用户的使用行为意愿。
(7) 促成因素指的是用户能够感受到系统对各类信息技术的支持程度。若软件系统能够提供较为完善的客户服务体系则会增加用户的使用体验感。
(8) 社会影响指的是用户被周围环境的影响程度,在移动图书馆的意境下,如果和用户具有亲密关系的人群向用户推荐移动图书馆,则用户的使用意愿很可能受到影响。
3 基于滑动窗口的深度挖掘算法
N-n窗口模型为滑动窗口的扩展模型,要求挖掘算法能够准确识别n(n≤N)个最先到达元组。将最先到达的N个元组定义为有效元组,同时将其时标定义为有效时标,而其余元组则为过期元组,不参与挖掘过程[7]。
假设纳伪误差为挖掘结果中包含最多过期元组的记录数据,拒真误差为挖掘结果中最多丢失有效元组数量。为提高挖掘的准确性,给出一种特征指数直方图的近似结构。通过判断直方图内的误差为纳伪误差还是缺少拒真误差,将其划分为纳伪特征指数直方图与拒真特征指数直方图。

(1) 当i<j时,Gi中的元组比Gj中的元组先到达。
(2) 假设V(G)表示组G的大小,则V(G)=1,即对于任意i(i>1),存在V(G)=V(Gi-1)。
(3) 当V(G)=2i时,称G的级别为i,除最高级别外,各级别含有个元组,其中ε表示用户指定误差参数,且0<ε<1。
最后对定义后的直方图进行增量式维护,完成纳伪特征指数直方图的建立。
拒真特征的定义方法和纳伪特征相似,区别在于拒真特征中的t项为最老元组时标,其定义如下:

同时拒真时间特征具有的可加性与纳伪特征相同,且拒真特征指数直方图(~EHCF)也与纳伪直方图类似,区别在于拒真直方图是局域拒真时间特征构建的,其形式化定义也与纳伪直方图相似,此处不一一赘述。
设挖掘特征指数直方图H的中心点c为H中所有变量的均值,其表达式可以表示为:

H中包含m个纳伪时间挖掘特征TCF,则可得:
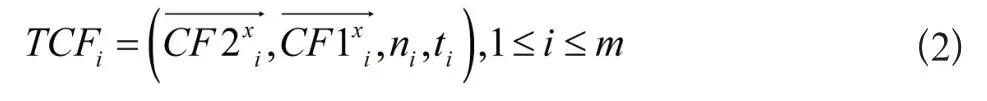
随后检查变量x是否能被离x最近的拒真时间挖掘特征EHCF(记作h)吸收,一个较为直观的评判方法就是比较x与h的距离dist(x,h)和h的半径R二者之间的关系,R可以通过h中的特征值获得。当dist(x,h)<βR(β 表示半径的相对阈值)时,x能够被h吸收,反之则证明x不能被吸收。
当挖掘请求到达时,根据当前内存中的EHCF完成聚类,对于每个Hi中的所有TCF被累加成一个TCF,从而得到了Hi中包含的记录和Hi的中心,根据用户行为变量完成挖掘算法,主要操作过程为将EHCF视为一个将Hi作为中心,且权重为Ni的虚拟点,其中Ni表示Hi中包含的记录数。使用加权k-means 算法对虚拟点进行挖掘,并且引入优化技术对算法进行加速,为降低算法的复杂程度,为每一个EHCF的增量附加一个TCF结构。当新的TCF(记为F')产生并加入到EHCF时,F被更新为F+F',并且当EHCF由于部分记录过期而被更新时,F可以通过如下规则进行增量更新:设EHCF H内含有m个TCF,F1,F2,…,Fm其中F是H中的所有记录构成的TCF,若F1过期,则H中新的TCF概要F'可增量生成。因此,只要对上述方法进行扩展即可实现支持N-n窗口的深度挖掘,当对系统数据挖掘请求时,附加输入一个代表窗口长度的窗口n(n≤N),系统根据EHCF概要获得挖掘结果时,从每个EHCF结构中筛选出n窗口范围内的所有TCF。由于EHCF结构内各个TCF的变量是有序的,因此可以采用二分查找法快速找出EHCF结构在n窗口内的所有TCF,并且根据查找出的TCF生成虚拟点,最后再一次使用加权k-means 算法对虚拟点进行挖掘,完成移动图书馆用户行为深度挖掘系统的构建。
4 仿真实验分析
为了验证算法在实际应用中的效果,进行一次仿真实验。为取得更好的挖掘效果,对EHCF的个数进行确认,为了方便分析,将平方距离作为度量标准,并且引入参数EHCF率来表示EHCF个数和自然簇个数的比率。EHCF率对挖掘效果的影响如图3所示。
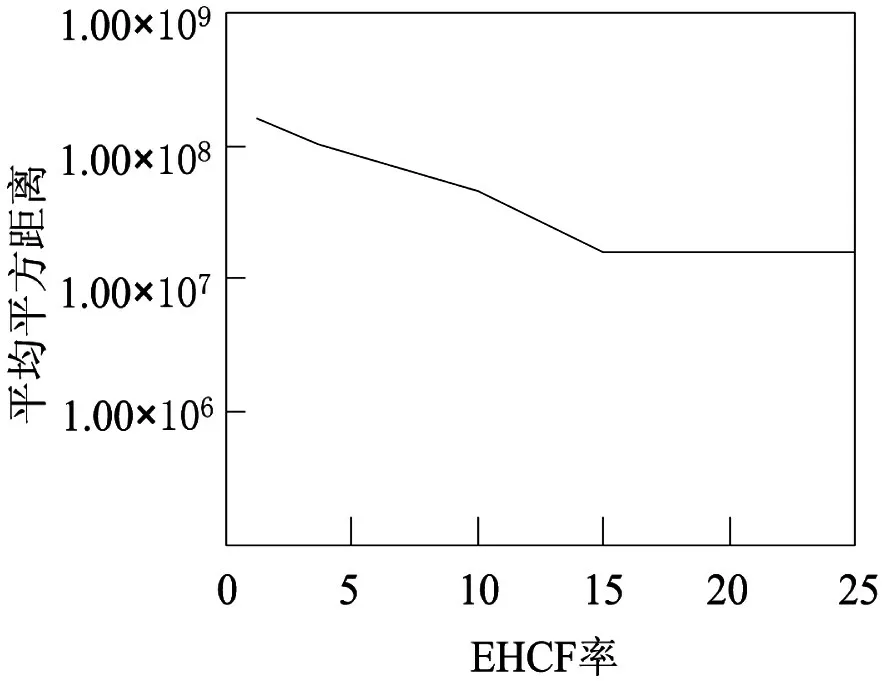
图3 率对准确度的影响
从图3中可以看出,当EHCF率为1时,也就是说EHCF个数和自然簇个数相同时,挖掘的效果较差,随着EHCF率逐渐增加,平均平方距离逐渐减少,当EHCF率等于15时,平均平方距离趋于稳定。即可以证明为了使挖掘效果较好,EHCF的个数应大于自然簇个数,EHCF率不需要设置过高。
挖掘准确率最能体现移动图书馆用户行为的挖掘效果,挖掘准确率越高,其挖掘效果越好,其表达式为:

式中,E表示挖掘到的正确样本数,Q表示挖掘到的样本总数。
通过上述EHCF个数确认,以挖掘准确率为实验指标,采用本算法、文献[1]系统和文献[2]系统,对移动图书馆用户行为挖掘准确率进行对比分析,对比结果如图4所示。
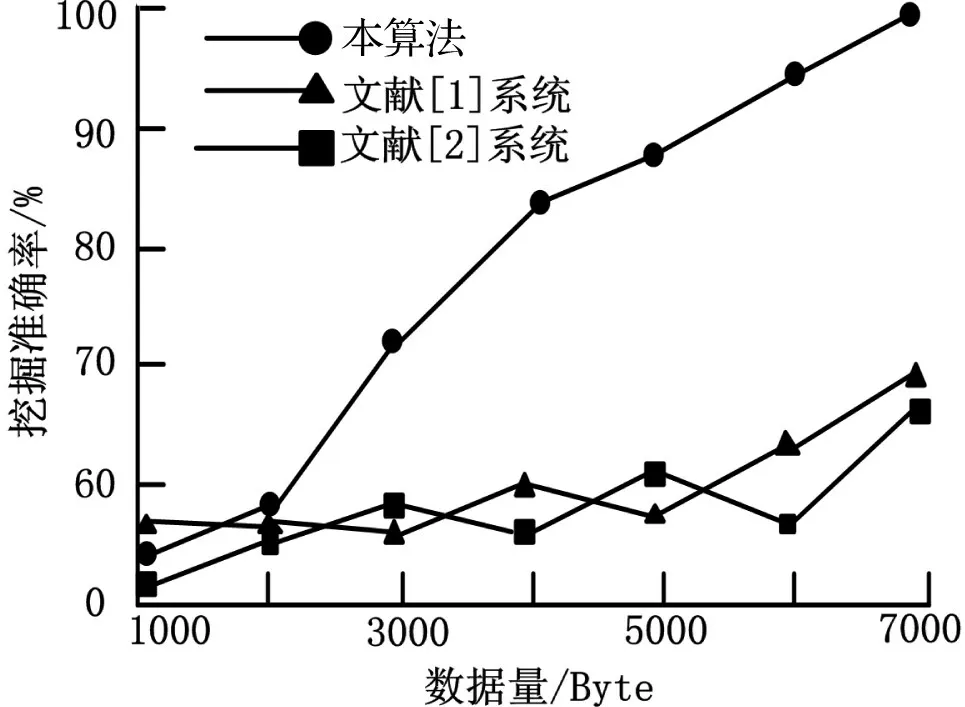
图4 用户行为挖掘准确率对比
根据图4可知,本算法的移动图书馆用户行为挖掘准确率最高可达100%,而文献[1]系统和文献[2]系统的移动图书馆用户行为挖掘准确率最高最有70%和67%,说明本算法的移动图书馆用户行为挖掘准确率较文献[1]系统和文献[2]系统的移动图书馆用户行为挖掘准确率高。
为了进一步验证本算法的有效性,对本文系统、文献[1]系统和文献[2]系统的移动图书馆用户行为挖掘时间进行对比分析,对比结果如图5所示。
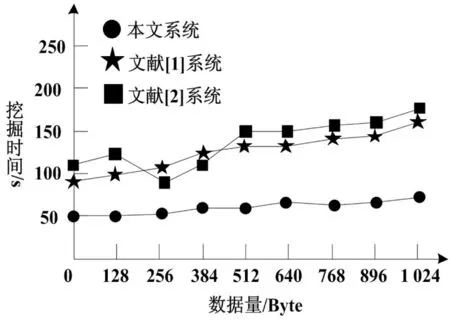
图5 用户行为挖掘时间对比
根据图5可知,本算法的移动图书馆用户行为挖掘时间在60s内,而献[1]系统和文献[2]系统的移动图书馆用户行为挖掘时间分别在160s 和170s 内,说明本算法的移动图书馆用户行为挖掘时间较短,用户行为挖掘效率较高。
5 结束语
本文设计了基于滑动窗口的移动图书馆用户行为深度挖掘算法。对移动图书馆用户行为的实际情况进行分析后,为了保存当前窗口中的数据分布,获得高质量的挖掘结果,采用两个特征索引直方图作为轮廓结构,并将其结合Agent技术完成深度挖掘模型的构建。实验证明本算法能够较好的完成移动图书馆用户行为的深度挖掘。
猜你喜欢
湘潭大学自然科学学报(2022年2期)2022-07-28
电脑报(2021年14期)2021-06-28
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
安徽电子信息职业技术学院学报(2020年5期)2020-11-13
计算机与生活(2020年8期)2020-08-12
软件学报(2019年11期)2019-12-11
计算机与生活(2019年5期)2019-07-18
