
基于NEZHA-UniLM模型的农业领域问题生成技术研究
2022-09-29 08:12黎芬费凡彭琳
湖北农业科学 2022年16期
黎芬,费凡,彭琳
(云南农业大学大数据学院,昆明 650000)
1 引言
农业作为第一产业,对社会稳定和经济发展起着至关重要的作用。农业生产中面临着许多挑战,其中农业知识的准确发现、筛选与应用场景一致的农业知识是永恒的主题。随着农业信息化的发展,农业在线问答系统以其可以跨越空间和沟通成本低廉的优点得到了广泛应用。农业领域问答数据集是实现农业在线问答系统的重要基础,制作农业问答数据集不仅需要大量的人力物力,更需要农业专家的支持,因此农业问答数据集的自动生成受到广泛关注。问题生成是一种根据输入文本自动生成问题的技术,可用于问答数据扩充。因此,如何在庞大的农业数据中就其语句形式的多样性匹配相关的语义丰富的问句、农业领域问题生成训练集的数据标注困难等问题,是近年来问题生成领域急需处理的难题。
目前,深度学习达到一个空前繁荣的时期,随着很多蕴含语义知识的预训练模型的发表,预训练语言模型和微调在问题生成的很多领域中取得了一定的成果。在问答系统领域,Liu等[1]从大规模的维基百科语料库中,使用自动化方法生成了大规模有质量的问答对;在阅读理解领域,Yang等[2]使用半监督的方法将模型生成的问题和人工生成的问题相结合,来训练阅读理解模型;在医疗领域,问题生成可以用于临床上评估人类的心理健康状态或提高心理健康水平[3];在农业领域,李岩等[4]针对农民用户在知识和技术上没有查询平台的问题,依托于自然语言处理和人工智能技术构建了基于知识图谱的农业知识问答系统。王郝日钦等[5]为实现农业问答社区提问数据的快速自动重复语义检测,提出了基于BERT-Attention-DenseBiGRU的农业文本相似度匹配模型,实现对农业问答社区相同语义问句自动、精确识别。这些领域的应用知识在应用层面的规模化、智能化、体系化等方面仍有很大的提升空间[6],基于农业领域的问题生成研究也未见报道。因此,如何有效利用现有碎片化的数据实现农业领域的问题生成仍是十分有挑战性的工作。
2 方法
随着各种预训练模型的提出,新一代的NLP技术给农业大数据领域带来更多可能和手段。BERT预训练模型[7]是第一个基于微调的表征模型,其原理是借助Transformer来提取特征,捕获语句间的交互信息。BERT也是第一个将无监督的预训练和有监督的微调结合起来,并应用到更深层的双向结构中的预训练模型,但是对于语言生成任务,如翻译、问题生成等效果达不到要求。目前,该模型在问题生成领域中的作用就是代替词嵌入或者直接替代序列到序列框架的编码器。
本研究在BERT预训练模型的基础上,提出了基于NAZHA-UniLM模型的农业领域问题生成模型,该模型结合预训练模型NEZHA与统一预训练模型UniLM的优势,首先利用NEZHA预训练模型实现农业源文本的词向量取,然后利用融合覆盖机制的UniLM模型作为解码器以实现问题生成。模型的总体架构如图1所示。
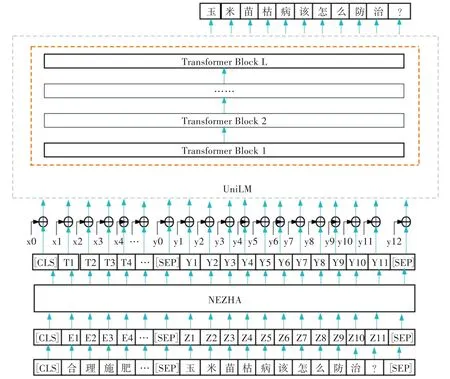
图1 NEZHA-UniLM模型架构
2.1 基于NEZHA预训练模型的词向量获取
NEZHA[8]整体上是基于BERT的改进,通过没有任何可训练参数的预定义函数对自注意中的相对位置进行编码,并将位置编码信息直接加到词嵌入作为Transformer的输入,对大规模未标记的纯文本语料库进行训练,以提高下游的NLP任务的性能指标。函数相对位置编码公式如下:
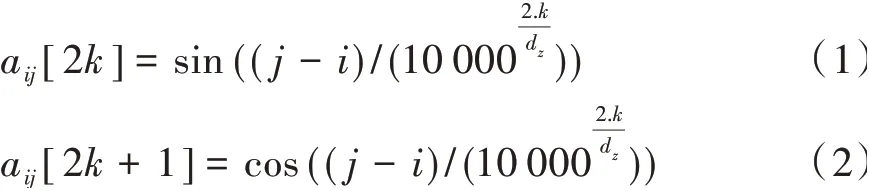
式中,k表示维度,i和j是索引位置,二者的差值相当于绝对位置的索引值,dz表示NEZHA模型每个Head的隐藏层大小。
NEZHA预训练过程使用全词掩码(WWM)[9]策略,有效提高了预训练模型效果;在预训练过程中使用了混合精确训练技术[10]和LAMB优化器[11]。其中,混合精确训练技术可以将训练速度提高2~3倍,同时降低了模型的空间消耗,从而可以利用更大的Batch Size;LAMB优化器通过使用非常大的Batch Size来加速模型的训练,而不会导致性能损失。
本研究使用NEZHA对源文本进行处理,输入语料表示“[CLS]合理施肥…[SEP]玉米苗枯病该怎么防治?[SEP]”,经过Word2vec词嵌入的方法计算生成特征向量得到“[CLS]E1,E2,E3…[SEP]Z1,Z2,Z3,Z4,Z5,Z6,Z7,X8,Z9,Z10,Z11[SEP]”,然后将该特征向量输入NEZHA模型进行训练,以获得文本序列的特征向量表示,从而得到解码器的输入序列。
2.2 基于统一预训练语言模型UniLM的问题生成
UniLM[12]是一种统一预训练语言模型,其网络结构和BERT一样,由24层Transformer组成,模型的参数使用BERT的参数进行初始化,输入由3部分拼接而成:词嵌入、位置嵌入、段嵌入。如表1所示,将UniLM与其他模型对比,UniLM能够进行有条件的语言生成任务。其中ELMO学习两个单向LM:正向LM从左到右阅读文本,而向后LM从右到左对文本进行编码。GPT[13]使用一个从左到右的Transformer来逐字预测一个文本序列。BERT使用双向转换编码器来融合左右上下文来预测掩蔽词。虽然BERT显著提高了各种自然语言理解任务的性能,但它的双向性特性使其难以应用于自然语言生成任务。

表1 语言模型预训练目标之间的比较
本研究使用融合覆盖机制的UniLM模型来进行问题生成。针对因曝光误差导致的累计误差现象,引入了对抗训练,使用FGM(Fast Gradient Method)对模型进行训练。将对抗样本(x0,x1,…,xn,y0,y1,y2,…,yn)加入NAZHA模型输出的特征向量中进行对抗扰动(其中x,y分别表示模型输入的原文本和原问题),然后一同输入UniLM模型进行问题生成。UniLM模型先对解码器中词进行随即掩码,然后再进行预测。该模型使用不同的Self-attention Masks矩阵控制不同语言模型的交互方式,结构如图2所示,其中白色表示屏蔽,蓝色为可见信息。
2.2.1 输入表征本研究输入的词序列为农业领域知识的问答对,开始处为特殊的序列开始标记[CLS],在每个段的结束处添加一个特殊的序列结束标记[SEP],用于模型学习在问题生成任务中表示何时终止解码过程。输入表示法遵循BERT的输入表示法。模型表征输入时将文本通过WordPiece进行子词标记。针对每个输入遮蔽,凭借与之对应的遮蔽嵌入、位置嵌入以及文本段嵌入进行求和运算得到相应的矢量表示。
2.2.2 模型微调模型微调部分采用UniLM模型中Seq2Seq框架结构处理问题自动生成任务。微调下游任务与预训练任务中使用自注意机制掩码相似。设定文本中源序列S1:“合理施肥,加强田间管理比合理施肥是减轻苗枯病的一项重要措施…”目标序句子为S2:“玉米苗枯病该怎么防治?”,将两个句子进行拼接,得到输入序列[CLS]S1[SEP]S2[SEP]。
本研究模型微调结构如图2中Seq-to-Seq LM所示。在微调过程中,在UniLM中随机加入一些[Mask]来屏蔽S2序列中70%的词,实现在输入部分进行MLM任务以提升理解能力,同时在输出部分做Seq2Seq以增强生成任务。微调时屏蔽词只能选取S2,并且提高比例以缩小微调时和预训练语言模型的差距,确保预测过程生成问题的质量。
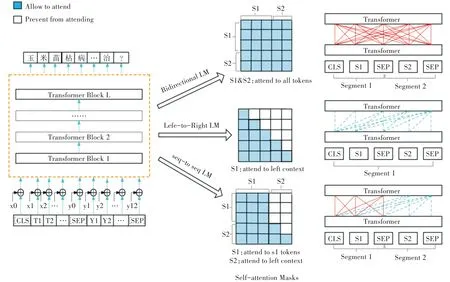
图2 UniLM问题生成模型框架
微调任务通过对目标序列中设置比例的遮蔽进行随机覆盖,使模型学习还原被遮蔽的词进行任务微调。基于前后文本被遮蔽的最大似然度得到生成问题[14]。
2.3 对抗训练
对抗训练属于对抗防御的一种。在预训练过程中,将对抗样本加入到原数据集中,以增强模型对对抗样本的鲁棒性,从而提高模型的表现,如式3所示。

式中,D代表训练集,x代表输入,y代表标签,θ是模型参数,L(x,y;θ)是单个样本的损失值,Δx是对抗扰动,Ω是扰动空间[15]。
在预训练过程中加入对抗训练,在Embedding层中添加小扰动,生成对抗样本,进行训练。本研究使用对抗训练方法Fast Gradient Method(FGM)[16],通过对抗训练生成对抗样本以缓解Exposure Bias问题,提升模型的泛化能力。
3 结果与分析
3.1 数据集与评价指标
目前,问题生成研究主要在英文语料数据集,对于其他语种存在语料缺乏的问题[17]。绝大多数研究基于SQuAD数据集进行文本问题生成,对于农业领域的文本问题生成研究不多[18]。本研究数据集从淘金地农业网的农业问答板块问答页面进行爬取,利用先进的Scrapy框架,Urllib、Requests等库,运用Python编程语言,从html页面的特定标签中爬取了问答页面所有问句对存入到csv文件中。
3.1.1 数据清洗数据清洗保证了输入模型的数据的质量,相比于不做处理,对模型有很大的提升。数据清洗处理方式包括剔除空白字符、剔除带括号的英文、处理部分不匹配数据。本研究共爬取了一万余条数据对,经过检查筛选对部分残缺、重复的问答对进行删除,对部分带有特殊格式和符号的字符经正则表达式删除;然后经人工随机校对,最终保留了5 920对问答对(表2)。本研究随机将80%数据集中问答对设为训练集,20%数据为测试集。

表2 农业领域数据集信息
3.1.2 数据处理根据问题生成任务对数据的要求,对划分的数据集进行文本截断。其中,问题文本的长度均未超过131个字符,所以相当于未做截断:对于答案文本,79.38%的长度是小于64的,答案长度可以取得较短。答案的部分内容可以精简,通常根据答案的前面部分,就已经能够推理出对应的提问。因此,选取答案的长度为64,大于64的进行截断,可以保留绝大部分信息,长度短可以加速训练和推理。对于数据集中每一个输入的序列、答案、问题3元组,经过分词后按照如下方式进行拼接。数据集的主要处理格式如图3所示。
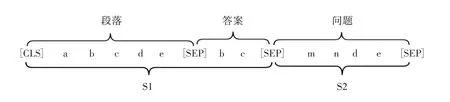
图3 数据预处理
其中,序列S1为序列和答案的拼接,其方式和BERT相同。S2由标准答案构成,在解码时,S2将拼接作为输入。
3.2 评价指标
ROUGE:本研究使用Lin等[19]报道的ROUGE自动摘要评价算法,主要是基于召回率(recall)的一种常用的机器翻译和文章摘要评价指标。构建标准问题集,将模型所生成问题与标准问题相对比,使用ROUGE-L作为评价指标。ROUGE-L中的L指最长公共子序列(Longest Common Subsequence,LCS),ROUGE-L计算的时候使用了机器译文C和参考译文S的最长公共子序列,生成问题相当于公式里的机器译文,标准问题相当于参考译文,计算公式如下所示。

其中,RLCS表示召回率,PLCS表示精确率,FLCS表示ROUGE-L,可以通过超参数β来控制对召回率和准确率的倾向程度。
BLEU:BLEU(Bilingual Evaluation Understudy)[20]意为双语评估替换,是计算生成的问题与地面真实问题的N-gram重叠分数,重合程度越高就认为生成质量越高。对于整个语料库而言,本研究中BLEU计算是基于句子进行的,通过计算BLEU-1、BLEU-2、BLEU-3和BLEU-4的累加得分来说明模型问题生成的性能。BLEU的总体评价公式如下:

其中,Wn指n-gram的权重,一般设为均匀权重。BP是惩罚因子,在问题生成中,lc表示生成的问题的长度,ls表示标准问题的有效长度。如果lc的长度小于lr,则BP小于1。
3.3 试验参数设置
NEZHA-UniLM模型参数主要包括NEZHA及UniLM模型的参数。本研究模型中NEZHA设置最大 序 列 长 度 为128,Train_batch_size为16,Learning_rate为5e5。模型参数如表3所示。

表3 NEZHA预训练语言模型参数
UniLM模型设置隐向量维度为768,微调学习率Learning_rate设为1e4,Epochs设为55。批处理大小Batch_size设 为16,Beam_search解 码 时 的Beam_size为5。本研究试验环境及配置如表4所示。

表4 试验环境及配置
3.4 结果分析
本研究引入了对抗训练,通过构造对抗样本加入到原数据集中,以增强模型对对抗样本的鲁棒性。使用FGM对模型进行训练,FGM算法epsilon值为1。通过设置对比试验来验证NEZHA-UniLM模型处理问题生成任务的优越性(表5)。
1)NQG。简单的Seq2Seq模型,使用LSTM进行编码解码,并在解码过程中引入了全局注意力机制。
2)BERT-LM。该模型使用BERT中的掩蔽语言建模对编码器进行预训练,并使用语言模型对解码器进行预训练。其中,LM是带有下三角的Attention Mask从左到右Transformer模型。
3)BERT+UniLM。该模型采用Seq2Seq基础架构,将Encoder替换为双向Transformer编码模块,Decoder采用UniLM。使用BERT模型对编码端参数进行初始化处理,解码端从初始状态训练。
由表5可以看出,与基线模型NQG相比,BERT+LM引入预训练模型BERT,由于BERT模型在海量语料上的训练,模型具有优秀的向量表征能力,进一步提升问题生成算法评测得分。BLEU-4和Rouge-L分别提升了0.053 5和0.093 6。与BERT+LM模型相比,BERT+UniLM模型的问题生成效果得到了提升。BLEU-4和Rouge-L分 别 提 升 了0.020 9和0.017 4。与基线NQG相比,BLEU-4和Rouge-L分别提升了0.074 4和0.111 0。与其他模型对比,本研究提出的NEZHA-UniLM模型的Rouge-L和BLEU1-4均取得了最好的成绩。与基线模型NQG进行对比,BLEU-4和Rouge-L分别提升了0.195 3和0.151 7。模型通过两阶段进行问题生成的算法能够有效地将NEZHA模型与UniLM模型的优势相结合,有效生成问题。

表5 模型评测对照表
同时,为了验证加入FGM对抗训练的有效性,对该模型进行消融试验,试验结果如表6所示。由表6可知,基于未加对抗训练的NEZHA-UniLM预训练模型,其BLEU-4和Rouge-L为0.314 1和0.470 1,加入对抗训练后的BLEU-4和Rouge-L分别提高了0.068 9和0.113 8。

表6 对抗消融试验
3.5 人工测评
利用人工评估来衡量生成的问题的质量,随机抽取50个问题对,并使用本研究预训练模型生成问题,通过5个方面指标来测评。自然度:表示语法性和流畅性;相关性:表示与答案主题的联系;连贯性:衡量生成的问题是否与对话历史一致;丰富度:衡量问题中包含的信息量;可回答性:即表示该问题是否可根据该答案段落来回答。然后,将每个帖子和相应的模型生成的问题发送给5个没有顺序的人类注释者,并要求他们评估每个问题是否满足上述定义的标准,对每个问题打分(1-5分),分数越高越好。所有的注释者都是研究生。
从表7可以看到,本研究方法在所有方面都优于其他模型。当模型生成既短又流畅的问题时,会使得其在自然度、相关性方面没有显著差异。在丰富度、连贯性和可回答性等方面,生成模型与人类注释之间存在着明显的差距,说明语境理解仍然是问题生成任务中一个具有挑战性的问题。

表7 人工测评结果
4 小结
本研究经过数据爬取、清洗、过滤和标注等工作,构建了问题生成的数据集,并研究了基于NEZHA-UniLM预训练模型的农业领域问题生成,其中,针对因曝光误差导致的累计误差现象,引入了对抗训练来生成扰动样本以缓解该问题。该模型不仅有效缓解生成问题与答案匹配度低、生成问题漏词或者多词和曝光误差等问题,还能有效提高生成问题的质量。
猜你喜欢
制造技术与机床(2019年10期)2019-10-26
青年生活(2019年23期)2019-09-10
电子制作(2018年18期)2018-11-14
电线电缆(2018年2期)2018-05-19
家庭影院技术(2017年10期)2017-11-23
小学教学参考(2015年20期)2016-01-15
中共南宁市委党校学报(2015年4期)2015-02-28
教育科学论坛(2014年8期)2014-03-01
语文知识(2014年1期)2014-02-28
中国音乐教育(2014年7期)2014-02-06
