
Autopilot研发总监Ashok:电动车如何检测障碍物并自动避让
2022-09-28 09:11
电脑报 2022年37期
8月底,伴随着FSD beta 10.69版本的发布,特斯拉自动驾驶Autopilot研發总监Ashok Elluswamy(艾什克·艾卢艾米,以下文章用第一人称表述)公布了一段视频,其中特别演示了一段智能电动车如何实时检测车辆周围的障碍物,并如何进行自动避让的影像。实际上,自动驾驶和避障、刹停,在国内一直是车迷们热议的话题,也是大家从油换电绕不开的关注点。
人们也许不知道,过去几年生产的每一辆特斯拉,都带有Autopilot基本功能。Autopilot基本功能允许车辆保持车道,跟随前车,弯道减速,等等。除了Autopilot基本功能,电动车还配备了标准安全功能,这些功能,如紧急制动、紧急转向,可以避免许多类型的碰撞。
目前大约有10万辆特斯拉拥有完全自动驾驶FSD beta软件,这是目前最先进的自动驾驶软件,它能够处理从停车场到城市街道,再到高速公路的所有驾驶过程。这个软件可以控制汽车在交通灯和停车标志前停车,合理避让横穿的车辆,并执行有交通灯保护和无保护的左转和右转,绕过停放的汽车和其他障碍物。
比如这些在旧金山密集的街区里开车的视频。你在视频里看到的所有内容,如道路边界、车道线、车辆,包括它们的位置、方向和速度,都是在我们车载计算机上,接收8个120万像素的摄像头数据,运行算法和神经网络生成的。

电动车在数据生成过程中,没有使用雷达、激光雷达、超声波或其他传感器。事实上,甚至没有使用高清地图。所有这些数据,都是基于实时摄像机视频流产生的输出,而汽车的规划技术栈只需要这些原始的实时输入,就可以在如此复杂的场景中进行导航
当开始搭建高级的技术栈时,我们想用某种方法来表示一般障碍物,一开始使用的是图像空间的分割方法,这几乎是个标准方法。这里,图像空间的每个像素,都被标记为可驾驶或不可驾驶。然后,我们希望规划技术栈可以使用这个信息来导航场景。
但这种方法有几个问题。首先,这些关于某个像素是否可驾驶的预测是在图像空间中完成的,基于图像的UV值,或者说,某个像素是可驾驶的像素,还是不可驾驶。但为了让汽车能够在三维世界中导航,它需要在三维空间中进行预测,这样才能建立互动的物理模型,并处理驾驶任务。
但在从图像空间转变到三维空间的过程中,如果采用这样的方式,像素分割会在系统中产生不必要的瑕疵或不必要的杂讯。
对一般障碍物进行建模的另一个方法,是使用密集的深度信息。在这个任务中,你可以以像素为基础,让网络预测深度,这样每个像素都会产生某个深度值。
但是,尽管这些深度图在颜色空间中进行可视化时,看起来非常漂亮,但把射线反向投影计算得到三维点,并可视化这些三维点云时,你就会发现随着距离的增加,它们就变得不一致,而且数据很难被后续流程所使用。例如,局部的深度变得不一致,因此,墙就不直了,可能是弯弯扭扭的。
这些深度图是基于每个摄像机的图像平面生成的,很难生成一个汽车周围统一的三维空间。
对于这个问题,我们的解决方案就是内部所称的占用网络(Occupancy Network)。

另外,这种表示方式也不能提供场景完整的三维结构,因此很难推理出所有悬空的障碍物,或者墙壁,或者其他可以遮挡场景的物体
占用网络,是一种基于学习的三维重建的方法,在应用层面,汽车接收所有8个摄像机流作为输入,并生成一个车周围空间体积化的占用值。汽车周围的每一个位置,网络都会生成是否被占用的结果。事实上,它生成了一个三维位置被占用或不被占用的概率值。
如我所说,它接收所有8个摄像头作为输入,并生成了一个单一的体积化的输出。这个输出的产生,并不是通过拼接各个独立的预测结果完成的,而是网络完成所有的内部传感器融合,并产生一个单一的一致的输出空间。
这些网络能生成静态物体的占用值,比如墙壁和树木之类的东西,也能生成移动物体的动态占用值,比如车辆(大多数情况下),但有时,也包括其他移动的障碍物,如道路上的碎片.由于输出空间直接是在三维空间中,我们可以通过遮挡来进行预测,你可以预测一条曲线的存在,尽管它可能暂时被汽车遮挡。
这个方法在内存和计算方面都非常高效,尽管表面上看可能并非如此,因为它生成了密集的三维的占用值,看起来可能体积过于庞大。但最终,在内存和计算效率上,这是一种更优的方法,因为它把分辨率分配在那些关键的地方。
密集的深度图或图像中的可驾驶空间,远处的分辨率非常低,而近处的分辨率非常非常高。但在占用网络中,在与驾驶有关的所有体积中,分辨率几乎都一致,这让它变得极其高效。例如在我们的计算平台上运行的时间小于10毫秒,这使得网络可以以100赫兹的速度运行,比摄像机产生图像的速度快得多。
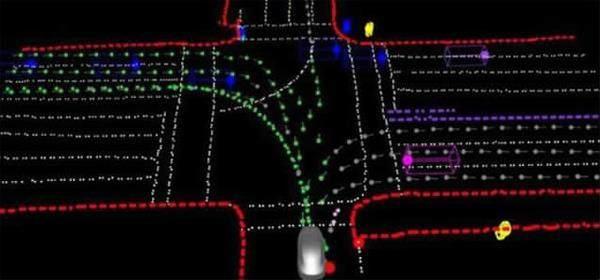
这些摄像头以每秒36帧的速度产生图像流,协同全面覆盖汽车周围360度的空间。每辆车都内置了144 TOPS(每秒万亿次操作)算力的计算平台,用于运行这些神经网络
当我们开始这个项目的时候,最初的目标是只处理静态物体,如墙或树。因为我们有很多不同的神经网络在车内运行,处理不同类型的障碍物,我们并没有继续搭建一个主要处理移动物体的网络,如车辆、行人、自行车手等。
而这时网络也生成了车辆的完整运动学数据,如速度、加速度、动力等。
当时我们想,好的,这里不需要处理移动物体,只需要处理静态物体,如树、墙等。但事实证明,这是有问题的,比如有一辆皮卡车看起来像一个栅栏。
当一辆车在高速公路上移动时,我们显然知道,它是一个移动物体,它被计算机正确判断为一辆卡车。但当车辆在红绿灯下停了好几分钟后,好吧,它看起来像个栅栏。但显然,任何人都不想开车撞上这辆车,我们想要绕过它,或者适当地放慢速度。
这显然是一场不可能打赢的仗,我们也不想打这场仗,我們只想避开这些障碍物,既不撞到移动的,也不撞到静止的障碍物,不撞到任何东西。我们解决这个问题的方法,是在同一个框架中同时生成移动和静止的障碍物,这样一来,就不会有什么东西在移动和静止之间的缝隙中逃脱。
为了说明这一点,举一个假想的例子,如果一辆汽车拥有无限的动力,它在高速公路上全速行驶,时速比如65英里。然后就在撞车前,在距离撞车前几厘米,它进行了猛烈的刹车,使用了几乎无限的制动力。显然,它会在撞上障碍物的那一瞬间之前停下来。
这样做,虽然说达成了安全的目标,但首先,这不现实,因为没有一辆汽车有无限的制动力。即使它有无限的制动力,我们也不想不必要地加以使用。例如,对于我们的特斯拉来说,它有每平方秒10到11米的制动力,但我们也不希望在不必要的情况下使用这所有的制动力。
其次,汽车可以开得很慢,比如汽车以1~2英里的时速低速“蠕动”。它可以在任何时候刹车,可以非常容易地避免碰撞,但开这么慢就太烦人了。这就是为什么我说,要以安全、舒适和速度合理的方式进行驾驶,驾驶员还需要一点点智慧。

对于行人,这可能会变得更加棘手。路边的行人,可能被判断为雕像,有些人还蹲着,因为姿势,汽车把他辨识成一堆垃圾
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
动漫界·幼教365(中班)(2020年3期)2020-04-20
中学生数理化·高一版(2020年1期)2020-02-20
铁道通信信号(2020年9期)2020-02-06
红领巾·萌芽(2019年8期)2019-08-27
中学生数理化·八年级物理人教版(2018年10期)2018-12-06
中国与非洲(法文版)(2017年10期)2017-11-23
CHIP新电脑(2016年3期)2016-03-10
科普童话·百科探秘(2015年4期)2015-05-14
城市道桥与防洪(2014年5期)2014-02-27
