
基于图卷积神经网络的学生课堂不规范行为实时检测方法
2022-09-27 02:22蔡博深孙岳麓骆思宏崔茹云马国洋姬星宇田利隆王朋珍
系统仿真技术 2022年2期
蔡博深, 赵 玲*, 周 容, 孙岳麓, 骆思宏, 卢 仲, 冯 帅, 崔茹云, 马国洋, 姬星宇, 田利隆, 王朋珍
(1.东北石油大学计算机与信息技术学院黑龙江大庆 163318;2.大庆油田设计院有限公司信息技术中心黑龙江大庆 163712)
在教学过程中, 课堂教学是很重要的一个环节。学生在课堂上的表现以及学生的听课状态都是衡量课堂教学效果的重要方式。课堂中的行为是评价听课效果的重要指标。因此, 无论是授课教师还是管理层, 对学生课堂的不规范行为都极为关注。然而在传统的课堂教学中, 学生的听课状态及不规范行为主要依靠授课教师的观察, 当发现不规范行为时, 只能做到口头提醒。该方法不仅影响了教师授课环节的流畅性, 同时由于教师是在授课过程中观察的, 对学生的评价难以做到全面准确。因此, 通过计算机视觉的方式对学生课堂不规范行为进行检测逐渐受到关注。
随着视频监控的普及, 许多多媒体教室都安装有视频监控, 但是视频监控功能多用来进行视频回放或人工查阅。人工查阅不能够及时地反馈信息, 且需要耗费大量的人力。随着计算机视觉技术的发展, 人体行为检测技术得到广泛关注。文献[1]使用红外视频进行人体行为识别, 与可见光图像进行融合判断。文献[2]针对课堂环境的行为识别, 使用隐马尔科夫模型(SCHMM)实现人体形态特征识别。文献[3-4]针对逐帧的识别失去帧间的连续性, 使用时序网络对视频场景下连续性信息进行识别。文献[5-6]使用骨骼信息作为学生课堂行为的表征, 使用Kinect传感器套件完成骨骼坐标提取, 并使用图卷积网络进行行为识别。文献[7]使用Open Pose和改进的VGG16、SSD算法完成课堂行为识别, 文献[8]提出了基于Open Pose的异常行为检测系统, 该模型可以对考场中多名考生同时进行骨骼关键点检测, 根据关键点信息提取有用的特征向量进行训练, 可较好地检测出探头、伸手、站立3种异常行为, 文献[9-10]针对真实课堂环境易受遮挡问题, 对比了Alpha Pose和Open Pose算法, 结果表明Alpha Pose算法在教室这类有遮挡物场景下的关键点估计比Open Pose算法准确率高出2.54%。文献[11]提出了将ST-GCN用于人体行为识别, 提高了识别效率和准确率
关于行为识别的方法很多, 但将人体行为识别方法应用在课堂环境, 实现对学生课堂的规范行为识别不多, 而且实时性差, 因此本文提出了一种基于图卷积神经网络的学生课堂不规范行为实时检测方法。首先采集学生课堂图像, 然后对视频监控的学生使用YOLOv5进行定位, 对其骨架进行提取, 最后利用图卷积网络分类识别。算法流程如图1所示。
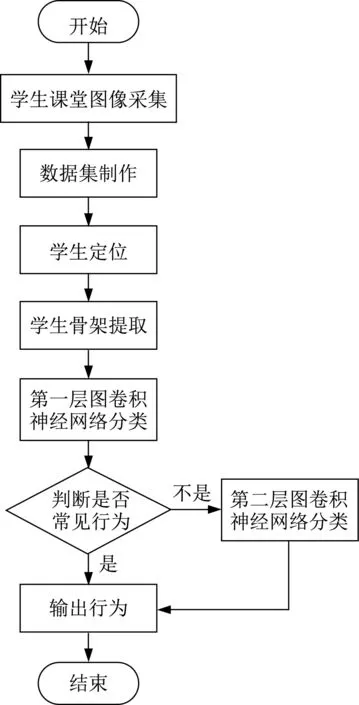
图1 算法流程图Fig.1 Algorithm flow chart
1 课堂学生定位
因为课堂环境背景复杂, 所以为了减少不必要的检测和提高效能, 需要对学生进行定位, 减少后续骨骼提取和行为识别带来的计算量。本文使用YOLOv5网络作为学生的定位基础模型。其针对输入端, 使用了自适应锚框计算等操作, 使得对于教室监控中的学生这种小型目标的检测具有非常好的效果。预测框来自初始锚框的输出, 与真实框进行比对, 计算差距, 反向更新迭代, 使得效果更加稳定;它融合了其他算法中的一 些 结 构, 如Focus和CSP(Cross Stage Partial Network)等;增加了FPN(Feature Pyramid Network)和PAN(Path Aggregation Network)的结构, 修改损失函数为GIOU_Loss, 非极大值抑制采用DIOU_nms。
2 Alpha Pose人体骨骼识别
Alpha Pose姿态估计算法采用自上而下的策略进行人体骨骼识别。其主要采用仿射变换调整检测框, 附加单人姿态估计(Single-Person Post Estimator, SPPE)用于训练拟合, 以及采用参数化非极大值抑制解决冗余问题。
2.1 仿射变换
由于卷积神经网络并不具备标度不变性和旋转不变性, 只有最大池化才具有不变性。越大的池化层, 感受野就越大, 所允许的平移就会越大。本文采用对称空间变换网络(Symmetric Spatial Transformer Network, SSTN), 通过仿射变换, 实现了映射转换功能, 其给每一种变化都提供了2个参数, 最后使用6个参数用于表征对原图的变化。SSTN由空间变换网络(Spatial Transformer Network, STN)和空间反变换网络(Spatial Detransformer Transformer Network, SDTN)2个部分组成, STN的结构主要分为参数预测、坐标映射、像素点采集。
本文使用STN和SDTN自动选取ROI, 使用STN去提取一个高质量的人体区域框, 如式(1)所示:
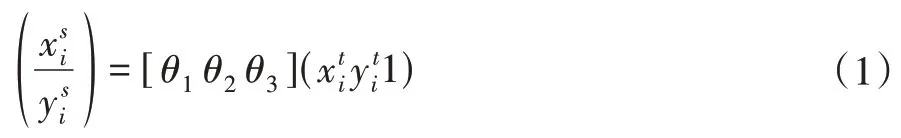
其中,θ1,θ2和θ3都是二维空间的向量,xi和yi分别表示某一点的x和y坐标,t表示变换前的坐标,s表示变换后的坐标。
在经过单人姿态识别之后, 使用SDTN将估计的人体姿态反射回原图坐标中, 如式(2)所示:
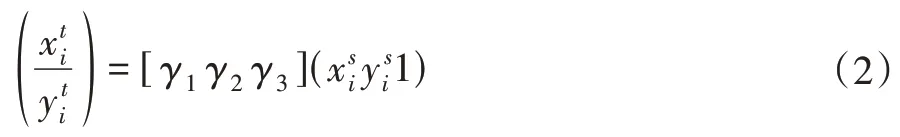
其中γ1,γ2和γ3为反向转换需要的参数。
STN和SDTN的结构为反向结构, 有以下关系:
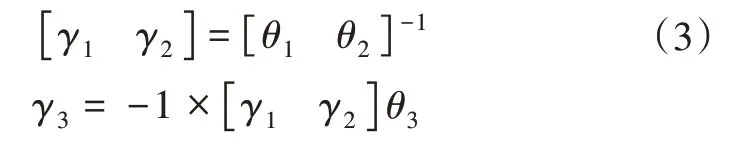
因此STN和SDTN是被同时更新参数的。
2.2 参数化非极大值抑制
相较于传统的两步法, 本文采用新的姿态距离函数Dpose来比较姿态之间的相似程度, 从而消除冗余的识别结果。非极大值抑制, 即抑制不是极大值的元素, 在本文上一步的检测中, 会产生非常多的目标检测结果框, 其中有很多重复的框都定位到同一位学生中, 需要去除这些重复的框, 获得真正的目标框。
值得注意的是, 即使使用较小的阈值Nt, 附近的检测框也会受到较多的抑制, 因此有很高的错失率, 而使用大的Nt, 将会增加假正的情况。当目标个数远小于ROI个数时, 假正的增加将会大于真阳的增加, 因此高的NMS不是最优的。
本文使用距离函数Dpose来判定姿态距离。如式(4)所示:
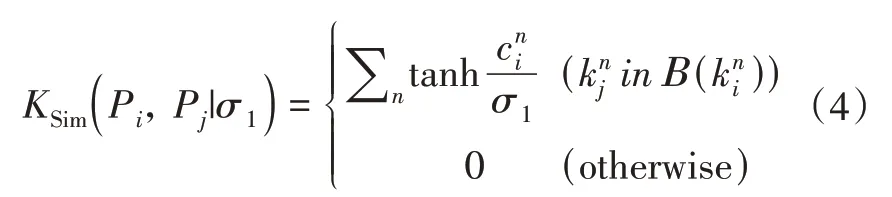
其中Β(kni)表示部位i的区域位置,knj表示第j个部位的坐标位置,cni表示第j个部位的置信度分数, tanh函数可以过滤掉置信度低的姿态, 当2个姿态的置信度都比较高的时候, 上述函数输出接近1。这个距离表示姿态之间不同部位的匹配数。
因此最终可定义为

3 图卷积神经网络行为识别
本文采用时空图卷积网络[14]分析学生课堂骨架数据中的行为。时空图卷积网络(Spatial Temporal Graph Convolutional Networks, ST-GCN), 是基于图卷积神经网络加强时空联系的一类模型, 使得人体行为识别方法得到了极大的改进。其中输入来自Alpha Pose提取的骨架关键点, 在骨架序列中构造时空图, 利用分区和跨时间连接等方式, 再联合利用帧序列控件信息来提取骨架信息, 从信息中提取高级别的特征来聚合图像。
ST-GCN最后使用softmax函数完成分类操作。
3.1 骨架数据准备
来自Alpha Pose的学生骨架序列由骨骼关键点的二维坐标表示。在此使用时空图G=(V,E)表示关节点之间的时间与空间之间的连接关系。V表示骨架序列中的所有节点, 对于来自Alpha Pose的数据为13个关键点。E包括2种连接, 分别为不同时间之间的连接和同一时间不同关节点之间的连接。
3.2 采样函数
在图像中, 采样函数是相对于中心位置的近邻像素, 也就是围绕中心位置的卷积核大小的一块区域。在图卷积中, 可以类似地定义为对于节点vti其邻近节点集合B(vti)={vtj|d(vtj,vti)≤D}上的采样函数, 其中d(vtj,vti)表示从vtj到vti的最小长度(最小跳数)。因此采样函数p:B(vti)→V可以被写作

本文选取D=1, 也就是最近邻。
3.3 权重函数
在二维卷积中, 相邻像素的空间顺序是固定的, 因此权重函数可以按照空间顺序建立索引, 按元素乘法计算。而对于图却没有这样的排列顺序, 所以本文认为邻近节点的空间顺序由根节点周围邻居图中的图标记过程定义, 通过划分某一关节点vti的邻居集B(Vti)到固定数量的K个自己来简化这一过程, 其中每个子集共用一个标签。因此映射为
lti:B(vti)→{0, …,K-1}, 权重函数为
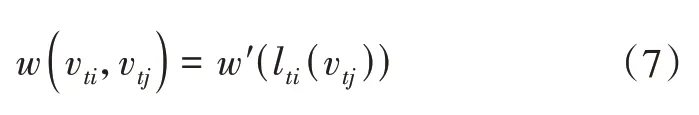
4 实验结果与分析
本文实验执行环境为:Intel i5-9300H 2.4GHz CPU、NVIDIA GTX 1660ti GPU, 操作系统为Windows 10 20H2, 编程语言为Python3.9, 使用PyTorch进行训练。
4.1 数据集准备
本文以学生课堂作弊视频为数据集, 包括玩手机、打瞌睡、走神等17种行为。
4.2 课堂学生定位结果分析
学生定位选择YOLOv5框架, 使用上述的自制数据集, 其中包括33669个训练视频和5611个验证视频, 将图像归一化到528x528像素, 使用Adam优化器, 置信度阈值为0.7, 非极大值抑制阈值为0.4, 学习率为10-4。随机抽取训练样本进行1400次迭代, 每次迭代样本数为2个。
本文以精确度(P)和平均精度(mAP)来衡量模型, 计算公式如式(8)所示:

其中,TP(true positive)表示被正确分类的正例;FP(false positive)表示本来是负例, 被错分为正例。
在测试集上, YOLOv5的检测精度为98.9%, 平均帧率可以达到18帧/秒。检测效果如图2所示。

图2 学生检测结果Fig.2 Results of students detection
4.3 Alpha Pose人体骨骼识别实验及结果分析
经过课堂学生定位分析得出学生边框过于紧凑, 可能存在信息损失, 本文实验中, 无视长宽比统一尺寸。本文分别采用Open Pose[12]、DSTA-net[13]和Apha Pose进行人体骨架提取。实验结果如表1所示, Alpha Pose和DSTA-net的效果如图3所示。
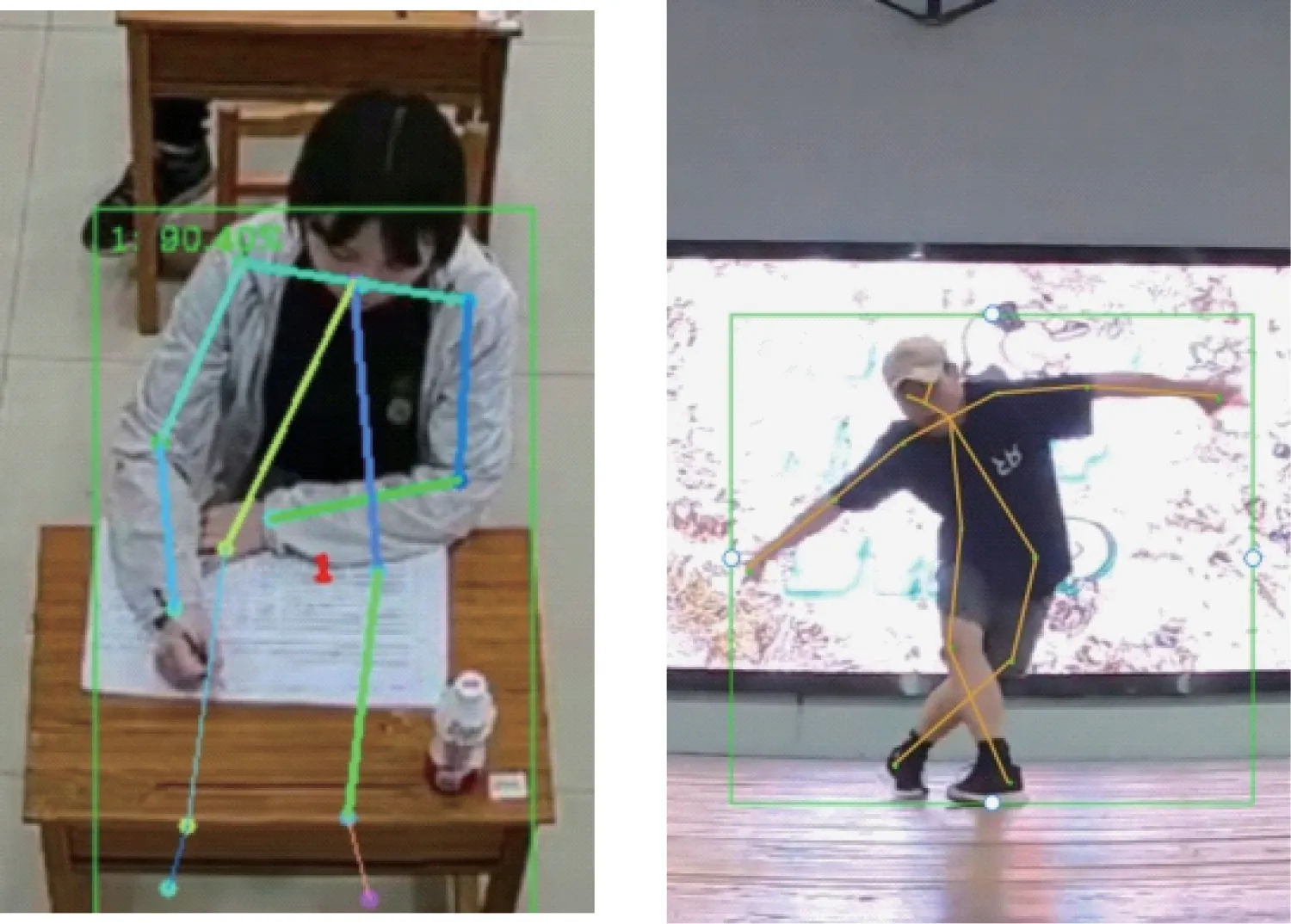
图3 Alpha Pose(左)和DSTA-net(右)识别结果Fig.3 Result of alpha Pose(left)and DSTA-net(right)
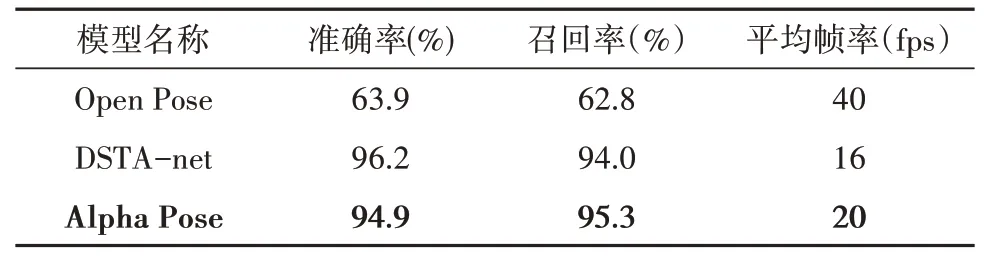
表1 单人关键点提取结果Tab.2 Result of single persion key point extraction
根据实验结果, 可以看到Apha Pose的效果比较突出, 且性能也比较优秀。按照上述流程, 本文在不同场景下对人物不同行为的骨骼数据进行分析和检测, 结果显示, 测试准确率为94.9%, 其中影响识别结果的原因是人体关节的部分遮挡、不常见行为和非学生的误识别。因此又对样本中的困难样本进行了剔除, 保留了完整的人体信息, 去除了舞台跳舞等动作, 测试准确率为97.0%。
4.4 图卷积神经网络行为识别实验及结果分析
图卷积神经网络是深度学习神经网络, 原则上也可以基于图像进行识别, 但是由于没有在图像中标识出骨骼姿态, 因此识别精度并不高, 识别效率也会降低, 影响实时性, 而ST-GCN是用于识别骨骼关键点信息的网络[15], 该网络设计的输入和输出均为骨骼姿态, 输入骨骼姿态可以达到较好的精度和效果。
根据模型详细设计流程, 为了测试图卷积神经网络对于骨骼数据的分类效果, 本文选择了骨骼提取效果进行识别, 并与标注的结果进行对比, 通过实验结果可以看出, ST-GCN可以很好地学习人体骨架数据所包含的动作信息, 很好地用于人体行为识别中。
本次训练所使用的数据集中, 训练集有33669个骨架, 验证集有5611个骨架。本次训练每次随机采样10个, 迭代2000次, 学习率为0.0001, 使用Adam优化器和交叉熵损失函数。最终的图卷积模型在训练集上的分类准确率为100.0%, 在验证集上的分类准确率为96.0%。行为识别结果如图4所示。

图4 行为识别结果Fig.4 Result of behavior detection
5 结 语
本文针对现有方法在学生课堂环境下的行为检测不能实时准确地识别学生行为的问题, 提出了一种基于Alphap Pose和ST-GCN的学生课堂行为检测模型。首先对课堂摄像视频进行切割, 降低计算量, 然后使用Alpha Pose提取人体骨架, 最后使用图卷积神经网络进行学生行为识别。
实验表明, 该方法在真实课堂场景下检测速率可达20帧/秒, 行为识别准确率可达94.9%, 能够及时发现学生课堂的不规范行为。但是, 该模型对于动作幅度较大的行为依旧存在着识别错误的情况。因此, 在今后将针对特殊动作情况下行为识别存在的失误进行研究。
猜你喜欢
电子乐园·上旬刊(2022年5期)2022-04-09
中老年保健(2021年5期)2021-12-02
中老年保健(2021年5期)2021-08-24
学生天地(2020年3期)2020-08-25
中国新技术新产品(2020年5期)2020-05-06
汽车观察(2018年9期)2018-10-23
农业工程技术·温室园艺(2017年3期)2017-07-13
汽车零部件(2016年6期)2016-07-18
诗选刊(2015年4期)2015-10-26
少年科学(2009年12期)2009-07-07
