
营销组合视角下问答平台问题属性与问题回答关系研究
2022-09-24 04:00邓胜利夏苏迪胡树欣
信息资源管理学报 2022年4期
邓胜利 夏苏迪 胡树欣
(武汉大学信息管理学院,武汉,430072)
1 引言
社会化问答平台是公众获取信息的重要渠道[1],遵循着提问者提问、其他用户回答、产生最佳答案的“提问-回答-反馈”闭环问答模式[2],而问题得到回答是该模式承前启后并得以正常运作的基础。然而,当前问答平台中有大量问题都未得到回答。调查显示,在Yahoo! Answers中大约有1/5的问题未得到回答,而在百度知道中未得到回答的问题比例高达43%[3]。造成这一现象的重要原因即问题本身未能充分展现其价值和吸引力。有研究表明,问题的属性特征如长度、细节、可读性、复杂性等会显著影响答案的数量[4]。同时,这些属性也会彼此影响、相互关联。伴随着字数的增多,问题长度的增加在增强问题细节性、提供更多信息的同时,也会导致问题的复杂性增加,加大问题的理解成本。这也让问题能否得到回答受到不同因素以及因素交织关联的多重影响。问而无答的现状不仅会负面影响提问者的信息需求,还会降低平台内容的质量,甚至导致用户不再提问或放弃使用平台,对平台的可持续发展造成破坏性打击。
现有聚焦问答平台问题回答缺失的研究,较多采用方差视角探究问题属性对回答的独立影响。鲜有研究对问题属性组合与回答间的复杂关系进行探究,且在归纳问题属性因素、阐述问题属性与回答关系机制时缺乏理论支撑[5]。基于现实问题和现有研究困境,本文参考营销组合理论,构建问题属性和回答关系的组态研究模型,探讨问题属性的组合与回答间的关系,在理论上为问题属性与回答的关系提供组态视角阐释,并在实践上为平台信息服务和用户提问活动提供切实可行的建议。
2 文献回顾
2.1 问答平台的问题研究
该领域将问题作为主要研究对象[6],对问题的研究集中在问题分类和问题质量上。关于问题分类的研究,研究者主要从提问目的[7]、修辞学[7]、语言心理学[8]、主客观[9]等维度对问题进行分类。不同类型的问题在回答特征和对平台意义等方面存在差异,而这对了解用户行为偏好以及促进平台发展具有重要意义[10]。在问题质量研究上,现有研究集中在抽象定义和评价指标上。质量好的问题具备构造良好、易读、实用、有趣等特征[11],而不能复杂、不合适、不清晰[12]。同时,研究者根据问题文本特征,提取了禁忌词数目、内容易读性等10种文本特征作为质量评价依据,也有研究者参照回答结果,将回答数量、是否得到回答、用户评分等作为评价问题的指标[13]。
2.2 问题属性与问题回答关系研究
问题属性指能影响问题回答的相关属性[2],与提问者属性一同属于影响问题回答的外部因素。该领域相关研究可划分为四类,第一类致力于全面归纳外部影响因素,并尝试抽象构建一种系统化框架,如由Chua等[2]提出的包含元数据、问题结构和内容的 “Quest-for-Answer”框架;第二类关注影响问题回答的特殊特征,例如语言风格[14]、情感特征[15]等;第三类以特殊主题的社会化问答平台为情境,并据此发现一些外部影响因素,如Li等[16]和Deng等[17]以ResearchGate为情境,从不同视角提取了问题特征,分析问题特征与回答之间的关系;第四类使用控制实验法获取观测数据,研究了句式、句子数量、提问范围、表情等对问题回答的影响[18],相关研究概况如表1所示。
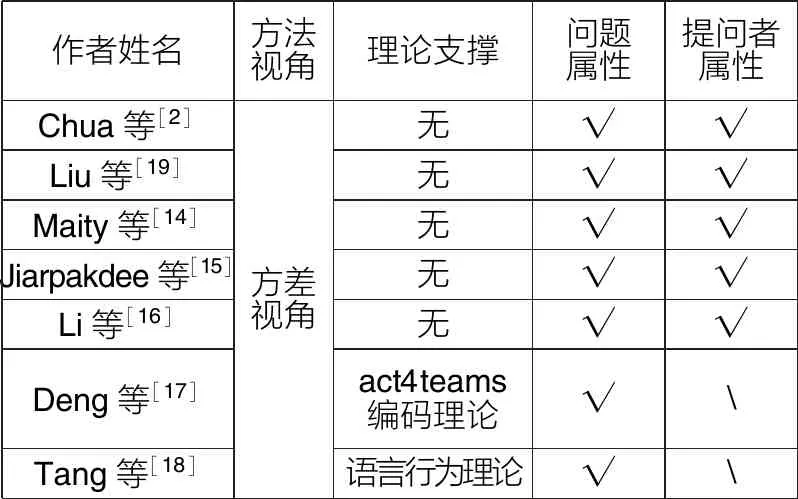
表1 影响问题回答外部因素的相关研究
2.3 研究述评
现有研究在探讨问题属性与问题回答的关系时,均从方差视角采用自变量相互独立和单向线性关系的统计方法,分析问题属性与回答间的净影响关系。但是,方差视角不能很好地解释自变量间相互依赖的复杂关系。用户是否回答问题取决于信息、技术和任务特征等因素相互匹配的共同作用,而组态视角的分析方法能得到影响问题回答因素的多种组态路径,弥补统计方法的局限,从类型学角度归纳出回归分析无法得到的结果[20]。同时,相关研究在提出假设、归纳问题属性影响因素时,较多基于经验归纳可能影响问题回答的问题属性,缺乏必要的理论支撑,亟待引入不同领域的理论来解析影响问题回答的关系机制。因此,本文基于营销组合理论,使用QCA方法探究影响问题回答的问题属性组合路径,揭示问答平台不同问题属性的组态与问题得到回答之间的关系机理。
3 理论基础与研究假设
Kotler[21]指出,营销活动是营销者通过社会物品为市场创造和提供价值的方式来追求市场做出期望回应的活动。在问答平台的提问活动中,营销者是提问者,市场是其他用户,社会物品是提出的问题,其他用户做出的回应是回答问题。问题得到回答不仅能满足提问者的信息需求,还能满足回答者的内在与外部需求[22]。可见,不同用户在提问活动中满足了各自的需求,从而实现了价值的交换。因此,问答情境中的提问活动属于营销范畴,营销理论能为提问活动提供有效指导。
3.1 营销组合理论
本文以Van Waterschoot改进后的营销组合理论为基础,借鉴其营销过程目标分类维度,它阐述了营销过程目标完成情况与营销能否成功的关系[23]。营销本质上是一种交换活动[24]。Houston[25]提出了一般交换活动发生的必要条件集,交换参与方可控的必要条件包括:①交换双方都有对对方有价值的物品;②交换双方都有能力将自己的物品信息告诉对方;③交换双方都有能力使对方得到自己的物品;④每一方都相信与对方交换是合适和值得期待的,即对双方来说,交换的预期收益必须大于预期损失[26]。作为一种交换活动,营销活动的完成也就必须具备这四个必要条件。为实现四个必要条件,Van Waterschoot提出营销者必须要完成四个营销过程目标:①配置目标——配置对潜在交换方有价值的物品;②定价目标——确定潜在交换方在交换中的成本;③便利化目标——实现物品传递,使潜在交换方在交换时可得到物品;④印象目标——实现物品信息的传递,使潜在交换方能注意到并持续注意我方提供的物品。这些营销过程目标适用于各类营销活动,包括问答平台中的提问活动。
营销过程目标完成情况能够影响潜在交换方对交换的预期收益和损失,其路径如图1所示。潜在交换方的预期收益指在交换中感知到的预期收益,预期损失指在交换中感知到的预期损失。预期收益正向影响交换意愿,预期损失负向影响交换意愿,潜在交换方的交换意愿正向影响营销结果(交换能否完成)。
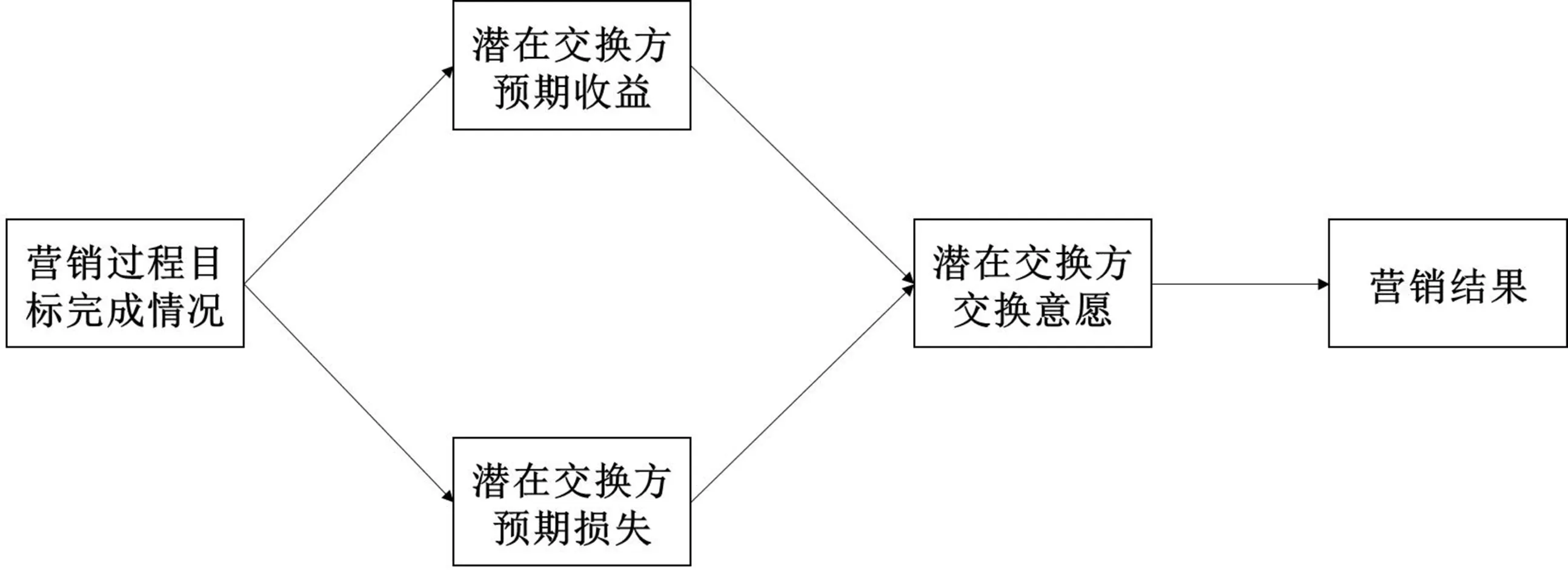
图1 营销过程目标完成情况对营销结果的影响路径
3.2 问答情境下的问题营销过程目标
本文基于改进后的营销组合理论的过程目标,提出了适用于问答情境下提问活动的营销过程目标。首先,将配置目标的定义调整为确定问题的价值属性水平,即指驱使用户回答问题相关需求的满足程度。配置目标原指配置对潜在交换方有价值的物品,而问题价值体现在满足用户回答问题的相关需求[25]。接着,调整定价目标为确定问题的代价属性。定价目标原指交换成本,在问答情境中,用户回答问题的成本是时间和精力,因此代价属性指影响用户回答问题的损失[22]。随后,将便利化目标和印象目标合并为传递目标。在营销中,便利化目标和印象目标彼此分离,例如供应链的建立能够实现商品交换的便利化目标,广告能够实现商品的印象目标。而在问答情境中,提问活动所提供的物品是问题,将问题传递给其他用户,一方面将问题的所有信息传递给其他用户(印象目标),另一方面也使其他用户能够方便回答该问题(便利化目标),可见这两个目标是同时完成的。因此,将两个目标合并为传递目标,通过问题对其他用户的可见程度来衡量问题的传递属性。综上所述,问题营销的过程目标即确定各个问题属性的水平,即配置目标确定问题价值属性水平,定价目标确定问题代价属性水平,传递目标确定问题传递属性水平。
3.3 问题获得回答的四个必要条件
在确定了问题营销的各个过程目标后,本文依据3.1节中营销成功的四个必要条件,结合问答情境的特征和问题营销的过程目标,提出了问题得到回答的必要条件集,将其作为构建问题回答组态研究模型的依据。问题得到回答需要具备四个必要条件:①完成配置目标,即确定好问题的价值属性水平;②完成定价目标,即确定好问题的代价属性水平;③完成传递目标,即保证问题的高传递属性。④用户对回答问题的预期收益超过预期损失,预期收益和预期损失分别受价值属性水平和代价属性水平的影响。当一个问题具备上述四个必要条件时,问题将会得到回答。
3.4 研究假设与模型
3.4.1 问题属性的确定
根据各类问题属性的定义并借鉴前人研究,本文对问题属性进行了归类(见表2),依照用户回答问题需求的满足程度提出问题紧急性和荣誉点奖励两种价值属性。有限利他主义模型指出,求助人在困境中的需求会唤起人们的同情,激发人们的助人意愿,从而获得愉悦感[22,27]。荣誉点的积累能为用户带来收益,提升用户的参与感。同时,依照用户回答问题的损失提出问题易读性、问题明确性和问题复杂性三种代价属性,并将问题可见性作为传递属性的具体化呈现。易读性较差的文本会施加额外的认知负荷,增加人们认知活动的时间和努力花费[28]。而问题所提供信息的完整性和准确性也会影响问题的理解难度[4],缺失信息使人们不能明确理解提问者意图是问题得不到回答的重要原因。对于问答平台用户而言,问题复杂性越大,克服信息所提供阻碍的难度就越大,提供该问题所需信息要付出的努力和时间也就越多。

表2 问题属性定义及其影响
3.4.2 问题-回答关系组态研究假设模型
在竞争性的营销环境中,目前还未识别出能确保营销成功的充分条件[25],因此本文进行理想化假设,默认其他因素均满足问题得到回答的要求,因此3.3节问题得到回答的四个必要条件同时具备就是问题得到回答的充分条件。
对于每项问题,必要条件①和②是默认实现的,这是因为每项问题在提问者提出之时,就已确定了价值属性水平和代价属性水平,各个问题仅在价值属性和代价属性水平的程度上存在差异,因此问题能否得到回答取决于必要条件③和④能否实现。对于必要条件③,问题要具备高传递属性,增强问题的曝光率,这是问题得到回答的基本前提。在此基础上需进一步满足必要条件④,通过调控价值属性和代价属性的水平,使用户对回答问题的预期收益超过预期损失。对于必要条件④,本文根据用户回答问题时产生的成本将各类代价属性分为三种情况。一是问题易读性高、问题明确性高和问题复杂性低,对应低理解成本和低信息提供成本(假设H1);二是问题易读性低、问题明确性高、问题复杂性低或问题易读性高、问题明确性低、问题复杂性低,对应高理解成本和低信息提供成本;三是问题易读性高、问题明确性高、问题复杂性高,对应低理解成本和高信息提供成本。
在情况一中,无论问题紧急性和荣誉点奖励水平高低都能实现必要条件④,因为助人成本和需求紧急性处于较低水平时,人们更可能选择帮助[28],说明此时回答问题的收益会大于损失。在情况二中,高荣誉点奖励能够实现必要条件④,有研究发现,外部奖励带来的收益能够弥补少量的时间和精力损失(高理解成本属于该类成本)[21]。由于高理解成本对应三种属性组合,即低问题易读性且低问题明确性(假设H2)、高问题易读性且低问题明确性(假设H3)、低问题易读性且高问题明确性(假设H4),因此,实现必要条件④也就对应这三种问题属性组合。当代价属性组合是情况三时,必要条件④很难实现,因为问题专业性过强,回答问题的收益不足以弥补投入的成本。综上,本文提出了问题回答组态研究模型,包含四种能使问题得到回答的问题属性组合假设,如表3所示。
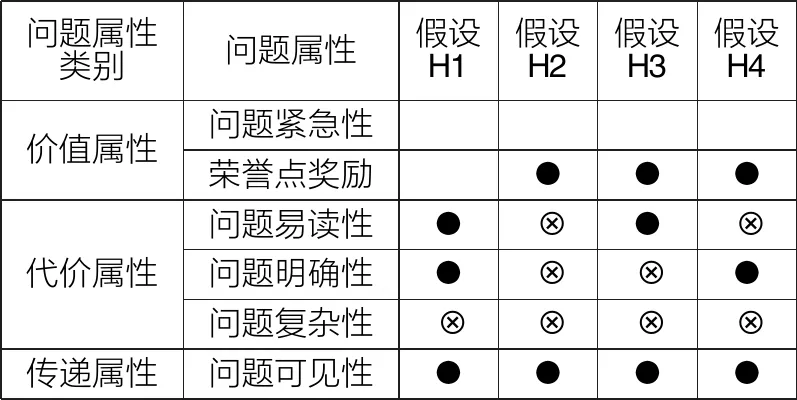
表3 问题回答组态研究模型
4 模型的检验与分析
4.1 数据收集与变量测量
百度知道是国内知名的互动知识问答平台,因其悬赏功能能够观测荣誉点奖励这一问题属性与回答之间的关系,本文因此选其作为研究情境,在百度知道“互联网”板块收集问题。关注这一板块的用户群体众多、差异性大,涉及不同年龄、性别、职业等,且对该领域的关注点和需求也存在差异,因而该板块的问题和回答数量较多,种类丰富,能为本文提供充足的数据样本。本文首先于2021年3月8日收集该板块的问题数据,利用Python爬取问题列表2000条,采集字段包括问题悬赏、标题、页面URL、标签、问题说明等,这些问题基本是在爬取时间点当天由用户提问的。接着,因在线问答平台中的问题大多能在七天内得到回答[36],为尽可能多地收集问题的回答信息,本文基于问题URL于3月20日爬取先前问题的回答数据,据此判断问题是否得到回答。结果显示,先前爬取的问题中,114个问题显示丢失,故对其做删除处理。剩余1886个问题中,有822个问题的回答数大于0,1064个问题的回答数等于0。在参考Chua等[2]研究的基础上,本文使用同等数量得到回答与未得到回答的问题样本用于数据分析,同时为降低人工编码工作量,随机抽取600个得到回答和600个未得到回答的问题用于后续分析。
本文研究模型共1个因变量和6个自变量(见表4)。在测量问题易读性时,本文借用黄敏[37]提出的含雾指数进行测量,其公式为:含雾指数=0.8×句均含字量+生僻字占比(生僻字占总字数的比例),句均含字量和生僻字占比通过Python编程计算获得。含雾指数反映了问题不易读的程度,因此本文将含雾指数取相反数来反映问题易读性。在对变量主观编码时,本文借鉴了Shotland等[27]的紧急需求判定方法、Chua等[2]对问题明确性的定义和Shah[12]提出的失败问题分类法,从1200个问题中随机抽取200个问题,由两位编码者分别对其进行编码。加权Cohen’s kappa一致性检验结果显示,各变量的kappa值均超过0.7,说明编码一致性较高[38]。最后将剩余的1000个问题对半均分,两位编码者分别编码500个问题。编码过程删除了78个广告问题,其中56个问题得到了回答,22个问题未得到回答,同时为保证得到回答和未得到回答的问题数量一致,额外随机删除了34条未得到回答的问题,最终留下1088个问题用于后续数据分析。
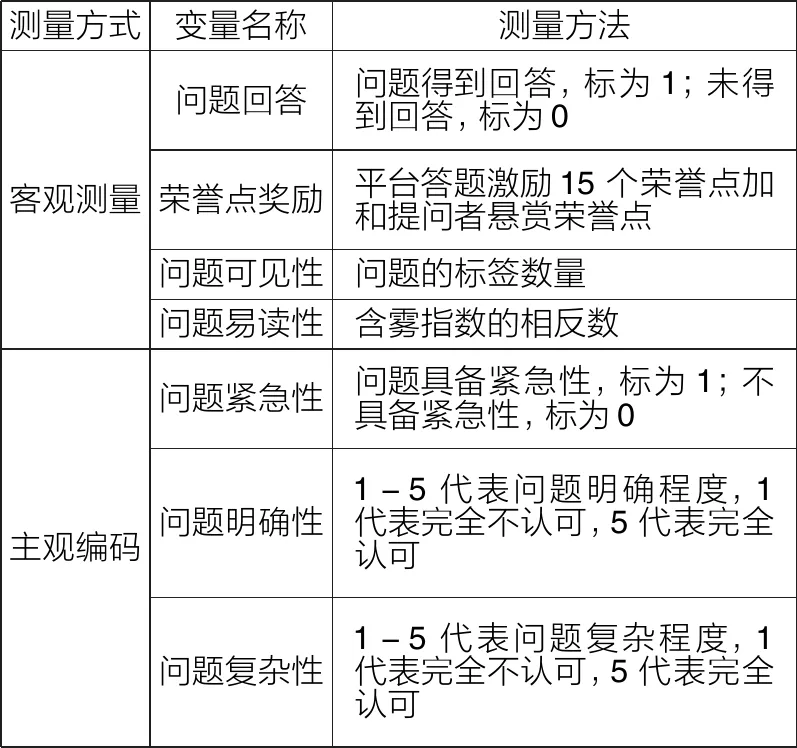
表4 变量测量方式及方法
4.2 基于fsQCA的问题回答组态研究模型检验
定性比较分析是目前运用最为广泛的组态分析方法[20],由于模型存在连续变量,所以本文选择模糊集定性比较分析作为检验方法。首先将非二值变量的原始数据转换为模糊集数据进行变量校准。通过设定0.95(完全隶属),0.5(最大模糊点)与0.05(完全不隶属)三个锚点,fsQCA3.0软件可以自动将各变量原始值转换为0-1区间内的模糊集隶属度数值。对于主观编码测量的变量(问题明确性、问题复杂性),二者用李克特5值量表测量,本文将最大模糊点设为3,同时将完全隶属锚点设为5,将完全不隶属锚点设为1。对于客观测量的变量,本文参考Paykani等[39]的研究,采用次序变换法校准,将覆盖20%样本的数值作为完全不隶属锚点,覆盖50%样本的数值作为最大模糊点,覆盖80%样本的数值作为完全隶属锚点。
在构建真值表的基础上,本文通过布尔计算得到能使问题得到回答的两种问题属性组合,以3作为最低样本数阈值,此时保留超过80%的样本[40];随后,本文根据每个组态与结果的模糊子集关系一致性确定二者间的充分关系,以0.75作为一致性阈值[41],将一致性大于等于0.75的组态结果取值为1,将小于0.75的组态结果取值为0;最后,借助fsQCA3.0软件得到具有较高可解释性的中间解,将其作为模糊集定性比较分析结果(见表5)。

表5 模糊集定性比较分析结果
一致性和整体一致性分别反映了单个蕴涵项和全体蕴含项与结果的充分关系程度,存在充分关系的最低一致性为0.65[39],表5中一致性指标均满足要求。蕴含项1指在高荣誉点奖励、高问题明确性、低问题复杂性和高问题可见性时,无论问题紧急性和问题易读性水平如何,问题都能得到回答。蕴含项2指在高问题紧急性、高问题易读性、高问题明确性、低问题复杂性、高问题可见性时,不管荣誉点奖励水平如何,问题都能得到回答。依据分解原则(见表6),蕴含项1可根据问题易读性高低分解为组合1和组合2。组合1与假设H4完全一致,故假设H4成立。组合2和蕴含项2部分覆盖假设H1,故假设H1得到部分验证,说明当问题易读性高、明确性高、复杂性低、可见性高时,若问题紧急性和荣誉点奖励都处于较低水平,则不能确保问题得到回答,而当问题紧急性高或荣誉点奖励高时,问题则能得到回答。假设H2和H3没有对应的蕴含项,故假设H2和H3未得到验证。
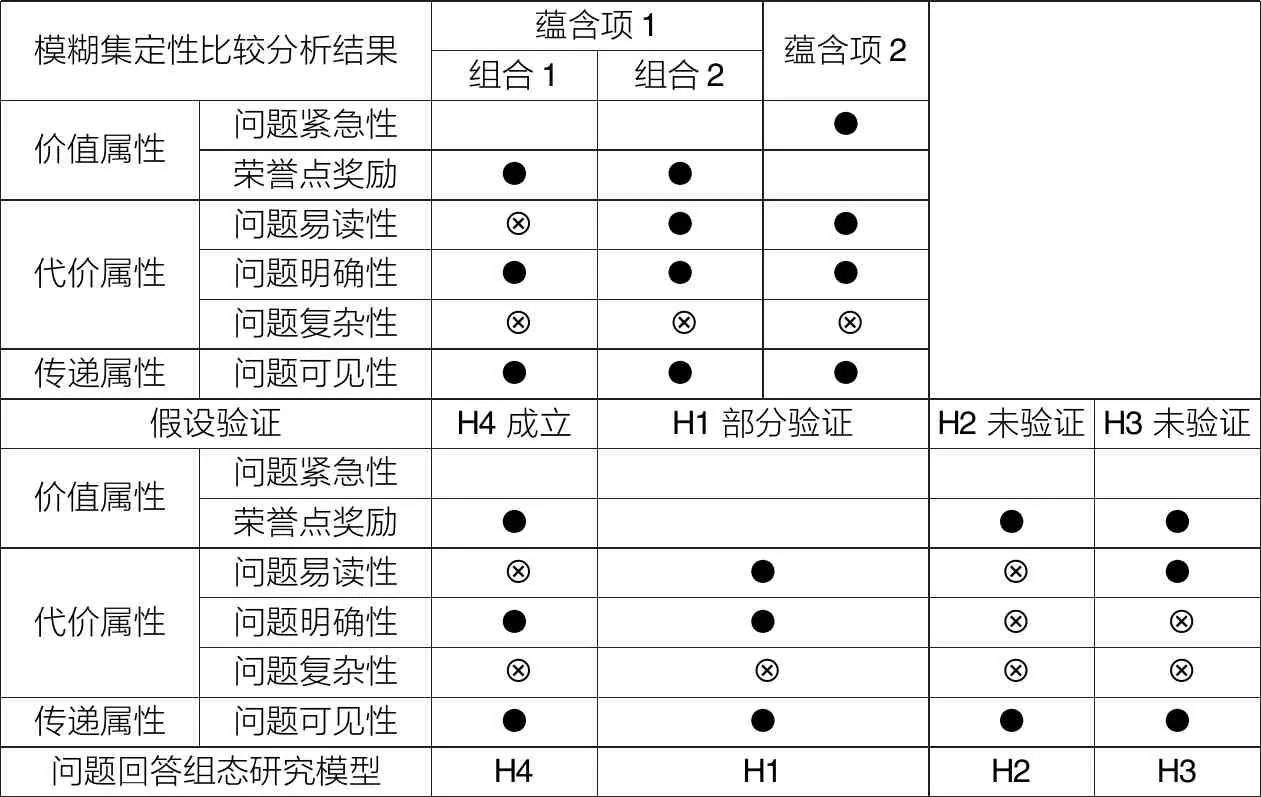
表6 问题回答组态研究模型验证说明
5 结果与讨论
5.1 问题属性组合对问题回答的影响
本文结合营销组合理论归纳出两种可促成问题得到回答的问题属性组合模式,即“高理解成本克服”模式(模式一)和“高传递-低代价-差异化价值”模式(模式二)。
在模式一中,不考虑问题紧急性水平高低,高荣誉点奖励带来的收益可以克服因易读性低导致的高问题理解成本,从而让问题得到回答。这是因为低问题易读性意味着问题表述艰深晦涩,需要耗费用户更多的认知努力理解问题,产生较高的问题理解成本。但是,这种理解成本较小,可以通过高荣誉点奖励克服。荣誉点作为一种带有经济属性的收益,能够克服低易读性带来的问题理解成本[42]。
在模式二中,高问题紧急性或高荣誉点奖励都能使问题得到回答。该模式要求问题能够被其他用户注意到,并且用户在理解问题及提供问题所需信息时花费时间和精力较少。在此基础上,为保证问题得到回答,还需要问题紧急性和荣誉点奖励这两个价值属性中的其中一个处于较高水平。因问题回答代价处于较低水平,此时高水平价值属性并不是为了克服问题代价,而是为问题提供“差异化价值”。问答情境竞争性强,“差异化价值”能让问题具备吸引力,使其在与其他问题的竞争中取得优势,最终得到用户的回答。
5.2 未得到验证的问题回答组态假设
假设H1结果显示,当问题可见性高、问题复杂性低、问题明确性高、问题易读性高时,即使问题紧急性和荣誉点奖励水平都较低,问题也不能得到回答。这可能是因为问答平台是一个竞争性环境,大量用户通过提问寻求帮助。许多问题虽然言简意赅、通俗易懂,但是这类问题在平台中大量存在,由于回答者的时间和精力有限,因此并不能对所有问题都进行回答,即这种问题属性组合也就不能保证问题一定得到回答。
对于假设H2和H3,本文在最初的假设阶段认为,低问题明确性和低问题易读性会给用户带来相同的损失水平,且两种问题属性造成的损失均处于较低水平,因此本文认为,高荣誉点奖励带来的收益能够弥补这种损失。但在现实情况中,问题的明确性低很可能是存在结构混乱、用词错误甚至信息缺失等问题,这些问题将会导致用户无法理解问题含义,增加问题的理解成本,以至于高荣誉点奖励带来的收益也无法弥补较高的问题理解成本。因此,假设H2和H3未得到验证。
5.3 理论贡献与实践意义
本文将营销组合理论应用于问答平台,建立了“价值-代价-传递”问题属性分类框架,阐释了问题属性对问题回答的影响路径,归纳了问题得到回答的四个必要条件。理论模型通过了组态视角的实证检验,可用于指导问答平台提问活动和问题回答的相关研究。同时,本文还发现了两种可促成回答的问题属性组合模式,一是“高理解成本克服”模式,一种是“高传递-低代价-差异化价值”模式,证明了问题回答影响机制中存在并发因果关系。两种组合模式也揭示了问题属性间的复杂关系。即使问题的某一代价属性较高(如较高的理解成本),其对回答的负面影响也会在较高价值属性和传递属性的联合作用下减弱,使问题最终能够得到回答,这一发现从构型层面揭示了问题属性间的复杂联系会对问题回答产生联合作用。
研究结果还能优化问答平台的信息服务,从营销组合视角帮助用户更好地规划提问活动。通过匹配可促成回答的问题属性组合来提高问题的回答概率。根据本文识别得到的两种问题属性组合模式,提问者可以调整匹配问题属性,使问题属性组合匹配其中一种模式,从而提高问题得到回答的概率。同时,提问者在构建问题时应多用简单词、简单句,确保问题表意明确,尽可能少地提问复杂性较高的问题。此外,平台还应设置荣誉奖励机制,使提问者在保证问题回答代价较低的基础上,使用荣誉点悬赏工具增强问题的差异化价值,让问题更具吸引力,促进问题得到关注和回答,优化平台问答内容的质量与生态。
5.4 局限与展望
本文样本量规模较小,致使样本部分类别数量较少,例如高紧急性问题仅有33个,这可能会导致研究结果的偏差。同时,因部分问题属性需人工编码,为减轻编码者负担,本文限制了样本数量。因此,未来需寻找合适的语义测量工具,实现对问题紧急性、问题明确性和问题复杂性的自动化测量,通过增加样本量以获得更坚实的研究结论。同时,本文提出的具体价值属性和代价属性仅依据用户回答时的几项重点需求和成本损失,而用户在回答问题时的个人需求和成本代价类型多样,对应着更多的具体价值属性和代价属性,这需要在未来研究中进一步探索。此外,未来需要多种问答平台的样本数据来检验本文构建的研究模型,进而验证本文研究结论的一般性。
猜你喜欢
科学与财富(2022年6期)2022-07-04
物理学报(2019年6期)2019-04-10
电脑知识与技术(2018年8期)2018-05-07
青年时代(2017年7期)2017-03-28
商用汽车(2016年11期)2016-12-19
商用汽车(2016年5期)2016-11-28
商用汽车(2016年6期)2016-06-29
商用汽车(2016年4期)2016-05-09
中学英语之友·上(2008年2期)2008-04-01
中学英语之友·上(2008年2期)2008-04-01
