
谷歌再次发布文字生成图像模型 新系统帕蒂根据文本输出各种风格、更高质量图像
2022-09-22 09:45
海外星云 2022年17期

近日,谷歌介绍了一种自回归文本到图像生成模型Pavti(帕蒂),可实现高保真照片级图像输出,并支持涉及复杂构图和丰富知识内容的合成。
比如,用文字描述“一只浣熊穿着正装,拿着拐杖和垃圾袋”和“老虎戴着火车售票员的帽子,拿着一块滑板”,就能分别生成类似图片。
除了细节栩栩如生外,对于各种风格,帕蒂也是驾轻就熟,能够根据描述生成梵高、抽象立体主义、埃及墓象形文字、插图、雕像、木刻、儿童蜡笔画、中国水墨画等多种多样风格的画作。
2022年6月22日,相关研究论文以《缩放自回归模型以实现内容丰富的文本到图像生成》提交在arXiv上(编者注:一个专门收录科学文献预印本的在线数据库)。
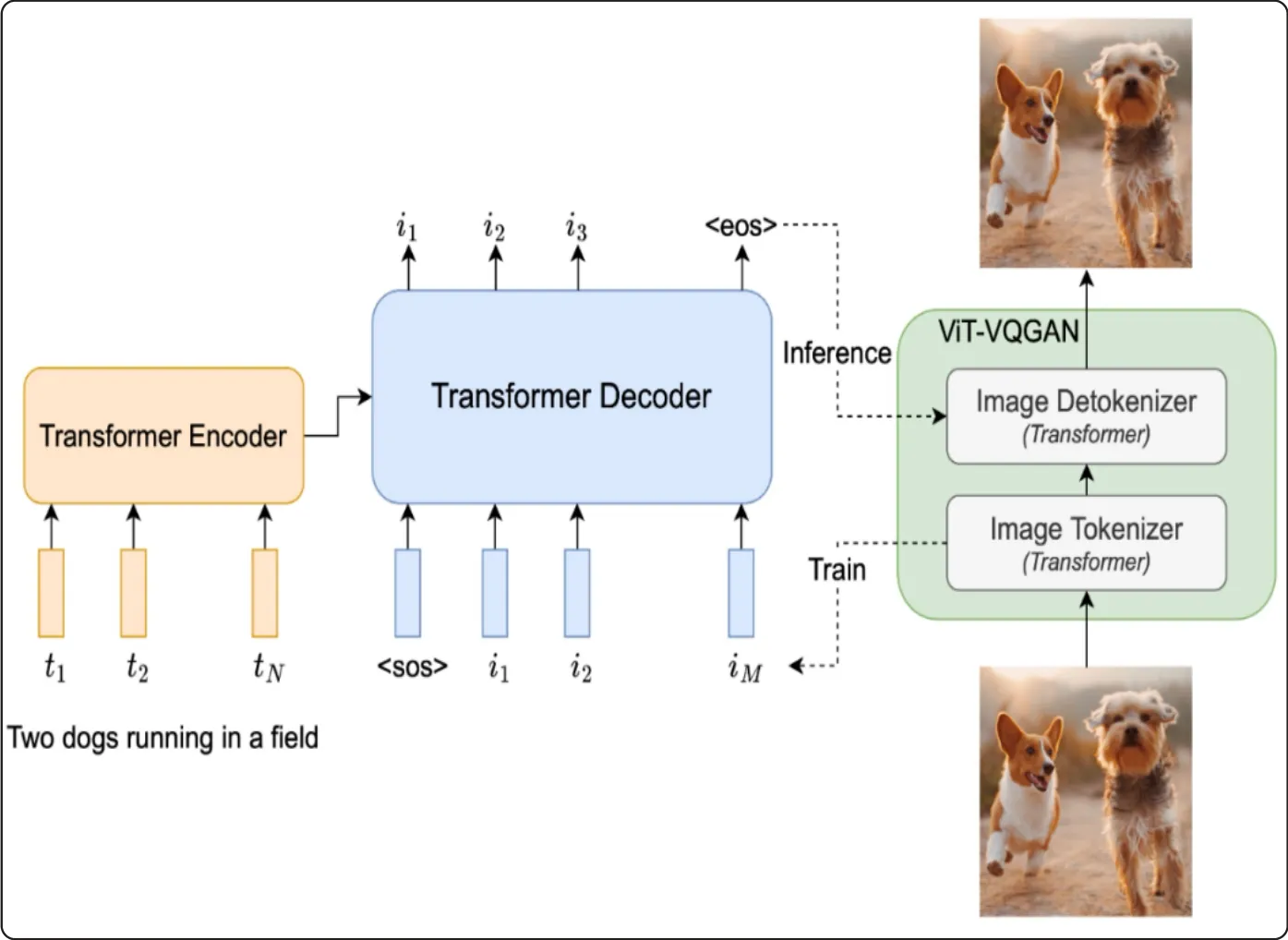
研究人员在谷歌官方博文表示:“用帕蒂输出图像是一个序列到序列的建模问题,与机器翻译相似。因此可受益于大语言模型的进步,特别是通过扩展数据和模型大小来解锁的功能。此外,目标输出是图像标记序列,而不是其他语言中的文本标记。并利用图像分词器ViT-VQGAN将图像编码为离散标记序列,以重建成高质量、风格多样化的图像。”
值得一提的是,谷歌在一个多月前推出的另一个文本到图像生成模型Imagen,在研究基准上也表现得十分亮眼。帕蒂和Imagen分别是自回归模型和扩散模型,两者不同但互补,代表了谷歌的不同探索方向。
此外,研究人员还探索并突出了帕蒂模型的局限性,给出了进一步改进的关键示例重点领域。
然后,他们还训练了3.5亿、7.5亿、30亿和200亿参数四个版本的帕蒂,并将它们进行了详细比较,参数越大的模型在功能和输出图像质量方面有着实质性改进。在比较30亿和200亿参数的帕蒂时,发现后者更擅长抽象的提示。
下面是四个模型对“一个绿色的标志,上面写着‘非常深度学习’,位于大峡谷的边缘,天空中有浮起的白云”的图片生成效果。
帕蒂要想识别冗长而复杂的提示,需要它准确反映世界知识、遵守特定的图像格式和样式,并通过细粒度的细节和交互组成众多参与者和对象,进而输出高质量的图像。但该模型存在的一定局限性,仍会让其生成一些故障示例。

比如说按照如下文字生成图像:“一幅阿努比斯雕像的肖像,穿着一件黄色的 T恤,上面画着一架航天飞机,背景中有一面白色的砖墙。”输出的图像中航天飞机在墙上,而不是T恤,颜色也有所渗出。

故障图像
值得一提的是,本次研究人员还采用一种新的测试基准帕蒂2(简称P2),该基准可从各种类别和挑战方面来衡量模型的能力。
然后,研究人员表示,用文本生成图像非常有趣,它允许我们创建从未见过甚至不存在的场景。但这带来许多益处的同时,也存在一定风险,并对偏见和安全、视觉传达、虚假信息以及创造力和艺术产生潜在影响。
此外,一些潜在的风险与模型本身的开发方式有关,对于训练数据尤其如此。像帕蒂这样的模型,通常是在嘈杂的图像文本数据集上进行训练的。这些数据集已知包含对不同背景的人的偏见,从而导致帕蒂等模型产生刻板印象。比如,在将模型应用于视觉传达(例如帮助低识字率的社会群体输出图片)等用途时,会带来额外的风险和担忧。
文本到图像模型为人们创造了许多新的可能性,本质上是充当画笔创造独特且美观的图像,可助力提高人类的创造力和生产力。但模型的输出范围取决于训练数据,这可能会偏向西方图像,并进一步阻止模型表现出全新的艺术风格。
出于以上原因,研究人员在没有进一步保护措施的情况下,暂时不会发布帕蒂模型的代码或数据供公众使用。并在已生成的所有图像上添加了“帕蒂”水印。
接下来,研究团队将专注于进一步研究模型偏差测量和缓解策略,例如提示滤波、输出滤波和模型重新校准。
他们还认为,有望使用文本到图像生成模型来大规模理解大型图像文本数据集中的偏差,方法是明确探测它们是否存在一套已知的偏差类型,并可能揭示其他形式的隐藏偏差。另外,研究人员还计划与艺术家合作,使高性能文本到图像生成模型的功能适应其作品。
最后,相比前段时间Open AI发布的DALL-E2和谷歌自家的Imagen(两者都是扩散模型),研究人员提到,帕蒂表明自回归模型功能强大且普遍适用。
猜你喜欢
小天使·三年级语数英综合(2022年4期)2022-04-28
商界评论(2022年1期)2022-04-13
数学大王·趣味逻辑(2019年10期)2019-11-06
初中生世界·九年级(2018年12期)2018-12-22
草原(2018年2期)2018-03-02
汽车导报(2017年5期)2017-08-03
求学·理科版(2017年1期)2017-03-02
中学生数理化·高二版(2016年4期)2016-05-14
读者(2015年9期)2015-05-04
初中生世界·八年级(2014年2期)2014-03-15
