
一种基于DBSCAN和XGBoost的多模式雷达辐射源型号识别方法
2022-09-15 08:52陈歆普
中国电子科学研究院学报 2022年7期
陈歆普, 敖 庆
(电子信息控制重点实验室, 四川 成都 610036)
0 引 言
雷达辐射源型号识别通过分析侦察系统截获的雷达信号,将其分类成对应的雷达型号[1],进而确认雷达的功能用途、搭载平台以及威胁等级等重要信息,支撑电子对抗决策实施。传统识别方法主要基于人工建立的雷达数据库进行信号参数匹配[2],识别效果很大程度上取决于使用者的分析和建库经验,而且数据库及匹配规则的更新优化需要繁琐的调试工作。基于机器学习的雷达辐射源型号识别是一种数据驱动的人工智能方法,学习算法从数据中自动获得识别模型和经验,实现系统识别任务的性能提升[3]。在雷达辐射源识别中,常用的随机森林[4]、支持向量机[5]等机器学习方法,主要用于分类单一样式雷达型号。本文提出的辐射源识别模型结合了无监督聚类与集成学习,实现一种自动模板匹配和集成分类器联合识别的新方法,可提高分类的准确性并适用于区分多模式雷达。
在本识别模型中,首先,使用基于DBSCAN[6]的无监督学习为各型雷达自动生成识别库模板,完成类似传统方法的模板匹配,从背景数据中选择出待识别信号,该过程通过寻找信号样式内的相似性,聚合参数相近的信号;然后,采用有监督学习训练已知雷达型号的分类器。信号分选结果是一种以表格形式组织的结构化数据,其典型格式如图1所示,其中主要包括射频(Radio Frequency,RF)、脉冲重复间隔(Pulse Repetition Interval,PRI)、脉宽(Pulse Width,PW)等信号参数信息。集成学习中的梯度提升决策树(Gradient Boost Decision Tree,GBDT)[7]算法具备完善的理论体系[3],在结构化数据的应用领域具有显著优势,其中基于二阶梯度和正则化改进的XGBoost[8]模型框架具有良好的扩展性和效率,在Kaggle、KDDcup等数据竞赛中被广泛使用[9]。本文将采用XGBoost模型实现雷达辐射源分类器,通过寻找不同信号样式之间的差异,进一步精确区分不同的雷达型号。

RF最大值RF最小值PRI最大值PRI最小值PW最大值PW最小值
多功能雷达系统通常具有多种工作模式[10],如导航、对空、对海、成像等,同一型号雷达可能具有多种信号样式及参数,信号参数的组合存在一定的相关性[1],本文将对该类雷达信号进行识别验证。通过仿真实验表明,本文提出的智能化识别方法能有效分类多模式雷达信号,另外与常用的基线机器学习模型比较,基于XGBoost的方法具有更高的识别精度。
1 基于DBSCAN条件聚类的模板库形成
DBSCAN[6]是基于密度的聚类算法,能够将具有足够高密度的区域划分为相应的簇(类),具备判别离群点、无需指定聚类簇个数等优点。通过数据分析发现对于同一型雷达的同一种信号样式,其对应的样本数据在该信号样式参数附近具有较高的密度,因此可使用DBSCAN对信号样式的数据进行聚类,并通过统计生成样式模板。另外,该算法形成的聚类簇在理论上可以是任意形状,适合于拟合多模式雷达信号的不规则参数分布。本方法按雷达的型号分别对其信号数据进行聚类,将形成的聚类簇作为信号样式,自动生成对应的参数模板。模板库样式主要包含:PF最大值/最小值、PRI最大值/最小值、PW最大值/最小值,对于一种多模雷达型号可能包含多种信号样式。
DBSCAN算法流程主要如下:
输入:样本集D= {x1,x2,…,xn},核心邻域参数{ε,MinPt},其中ε为邻域半径,MinPt为领域的样本最小数,‖xi-xj‖为样本间的距离。
1)遍历样本集合D,当某个样本点在其ε半径范围内的样本数>=MinPt,将其加入到核心对象集合Ω。
2)在核心对象集合Ω中,随机选择一个未被访问的对象,选取该对象所有密度直达和可达对象,由此作为对应的聚类簇,并标记为已访问。当所有核心对象都被访问后,完成聚类。
在雷达的信号样式设计中,各参数之间的选择组合具有一定的相关性[1]。本文将依次对RF、PRI参数进行基于DBSCAN的条件参数聚类和参数统计,按信号样式生成雷达型号的模板,以体现不同参数之间的组合关系。主要步骤如下:
输入:已知一种雷达型号的信号样本数据集D={x1,x2, …,xn},其中xi表示分选结果参数。

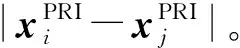
3)对RF-PRI聚类簇DRF-PRI的各个样本集Dij进行参数统计,分别得到其中的RF最大值和最小值、PRI最大值和最小值以及PW最大值和最小值。根据每个聚类簇Dij的统计参数,生成对应的信号样式模板,如表2所示。
2 基于XGBoost集成学习的雷达型号分类器原理

(1)
其中,
fk(xi)∈F
(2)
式中:fk(xi)表示回归树函数,属于CART函数空间F。fk(xi)回归树的每个叶子节点包含一个权重分数ωj,ωj为样本xi经过fk条件判断后落在该叶子节点上的预测值。图2是基于集成学习的雷达辐射源识别的示意图。
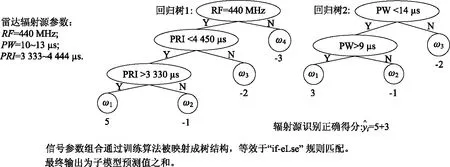
图2 基于集成学习的雷达辐射源识别示意图
XGBoost集成学习的目标函数定义为
(3)
其中,
(4)
目标函数由损失函数l和正则化项Ω两部分组成。在XGBoost中要求损失函数具有一阶、二阶导数,分类任务一般采用交叉熵;在正则化项中,T表示树模型的叶子节点数,γ控制树的分裂,λ平滑节点的权重分数。
梯度提升的模型优化在函数空间上进行,每轮迭代训练生成的对象是一个新的子模型函数。在第s轮迭代中,采用前向分步公式[7]如式(5)所示,将第s轮模型分解成第s-1轮模型加一个新的子模型fs(xi),fs(xi)即是本轮训练函数。
(5)
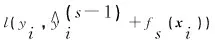
(6)
其中,
(7)
(8)
式中:gi、hi分别是损失函数的一阶导数和二阶导数(第s-1轮)。
(8)
(9)
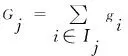
XGBoost子模型训练主要步骤的概述如下。
步骤1: 在第s轮训练中,计算每个样本第s-1轮的一阶、二阶导数。
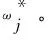
步骤3: 迭代更新集成模型,将训练得到新的子模型加入。
分裂增益计算公式为
(10)
式中:前两项表示分裂后左、右节点的目标值,第三项为分裂前节点的目标值。
3 仿真与实验
本文提出的基于机器学习的雷达型号识别由两部分组成。首先,使用DBSCAN无监督学习为每一类雷达型号分别生成对应的模板库,进行基于模板的型号匹配,该识别过程类似于传统数据库比较;然后,采用XGBoost集成模型训练分类器,进一步准确区分雷达型号。
DBSCAN和XGBoost中存在部分超参数需要通过模型评估[3]来确定,如DBSCAN中的邻域参数{RF容差εRF,MinPtRF;PRI容差εPRI,MinPtPRI},XGBoost中的学习率、树深度、最小叶子节点权重、列采样率、行采样率、正则化参数等。本文基于交叉验证[3],使用网格搜索在指定范围内自动寻找模型的最优超参数组合,实现了雷达型号识别的自动式高效调参,便于后续更新优化。
常用基线分类器有:逻辑回归、线性支持向量机、基于rbf核函数的支持向量机。逻辑回归(LR)[13]为线性模型,其损失函数为交叉熵,基于随机梯度下降训练;线性支持向量机(linear-SVM)[14]为线性模型,其损失函数为hinge函数,基于坐标下降训练[15];基于rbf核函数的支持向量机(rbf-SVM)为非线性模型,其损失函数为hinge函数,基于序列最小优化训练[16];随机森林(RFs)[17]是另一种集成模型,与XGBoost不同,RFs采用bootstrap抽样独立训练每棵子模型决策树。
根据已知雷达特性实验模拟生成4种雷达型号,其中2种型号为单信号样式,另外2种具有多种信号样式,一共具有9种信号样式,其信号参数较为相似,如表1所示。本文以雷达型号作为待识别的类别,多模式雷达的类别包含多种信号样式的数据,数据分布相较于单模式雷达更复杂。
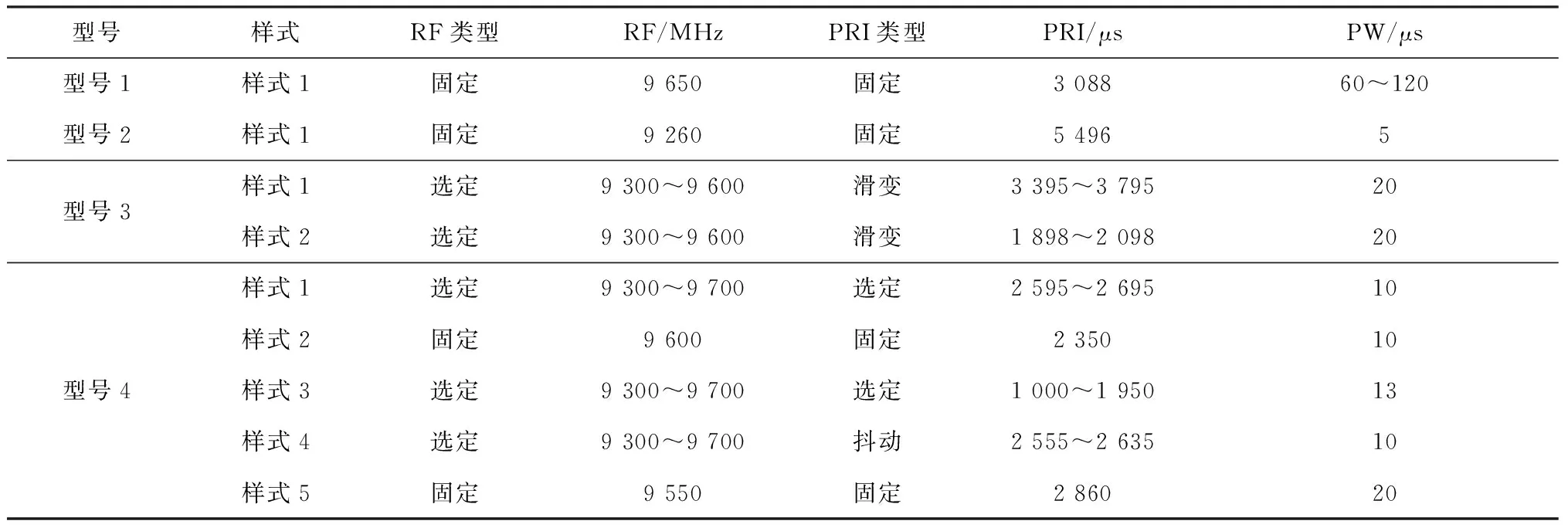
表1 典型雷达型号模拟参数
本文使用MATLAB仿真产生雷达辐射源数据,基于Python语言进行分类器识别实验。在实际条件下受复杂电磁环境、接收体制精度和数据处理方法等因素的影响,雷达侦察设备测量分析出的信号参数往往会存在一定误差,在仿真中将RF、PRI误差设置为1%,PW在2 μs~标称值内随机抽取。实验以分选结果中的RF、PRI、PW参数值数据作为模版/分类器的输入特征,如表1所示。通过仿真生成数据,每一种样式产生1 000个样本用于生成模板和训练分类器、1 000个样本用于测试识别。另外对于雷达信号样本,LR、SVM需要对其数据值进行归一化预处理,改善训练的收敛性,而基于树结构的XGBboost无需该类处理,使用相对简便。在测试过程中,本文将分类器识别的精度、召回率和F1分数[3]作为指标,以考察其识别能力的均衡性。
3.1 基于DBSCAN和XGBoost的识别效果分析
首先,使用基于DBSCAN的聚类进行模版匹配。仿真证明该算法能够拟合不同信号样式,自动生成对应参数模版,该算法结合了传统模板匹配与机器学习的方法,匹配识别的结果如表2所示。模板匹配能够实现100%的召回,但精度有待提高。其中,算法对单模式型号识别的精度高于多模式型号,说明多模式信号的正确匹配相对困难。
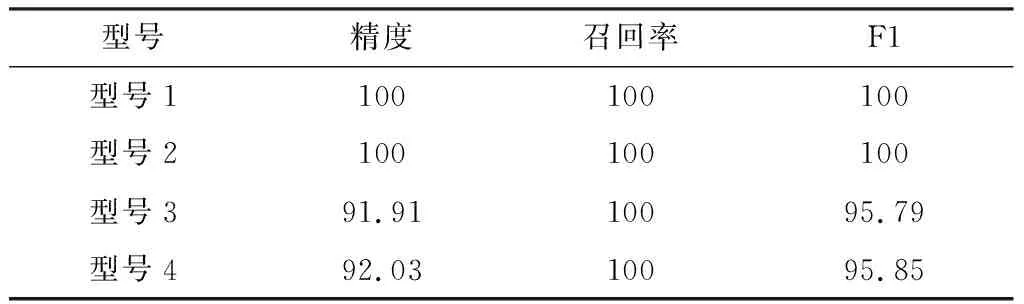
表2 DBSCAN模板匹配识别效果 %
然后,使用XGBoost进行分类识别,结果如表3所示。对于多模式雷达型号数据,SXGBoost的精度和F1指标均高于模板匹配,说明XGBoost分类器进一步提升了识别效果。可能的原因是:相较于单个模板匹配,在XGBoost中一个子模型的判断逻辑方式等效于一种“if-else”规则匹配,如图2所示,通过多个子模型的序贯训练和预测融合实现了多种组合规则(多模板)的联合决策,因此提高了集成模型总的分类准确性。另外,XGBoost更高的识别准确率导致了对型号4的召回率有所下降,造成部分样本漏判,模型的“查准率”和“查全率”存在一定的矛盾关系。XGBoost相对较高的F1指标说明模型的识别性能更加均衡。
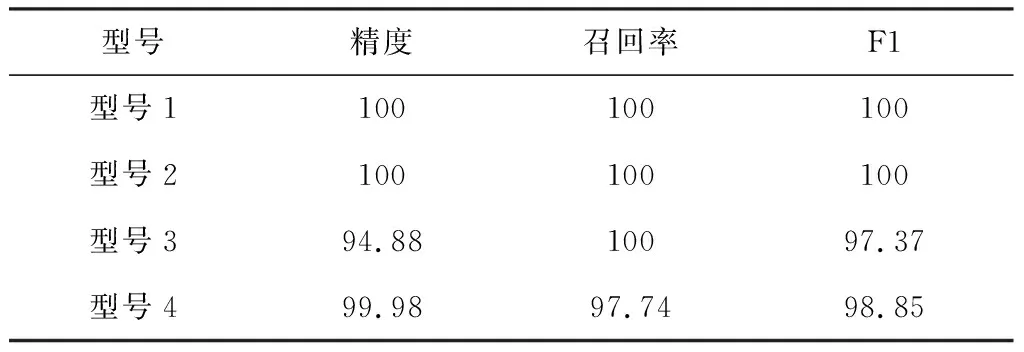
表3 XGBoost分类识别效果 %
3.2 分类器识别效果比较
多模式雷达型号分类识别效果如表4~表5所示。
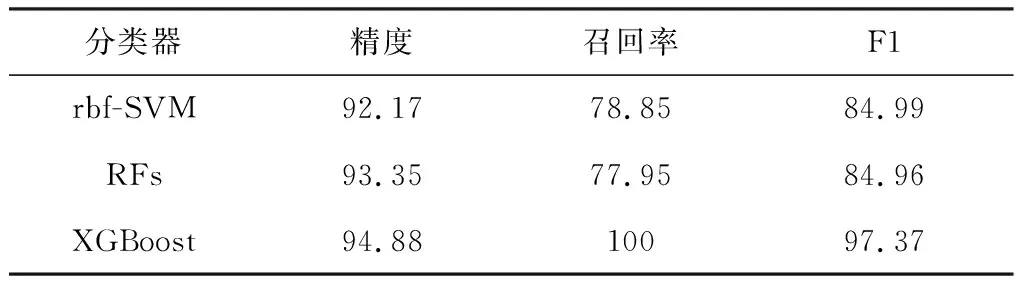
表4 不同分类器对雷达型号3识别效果 %
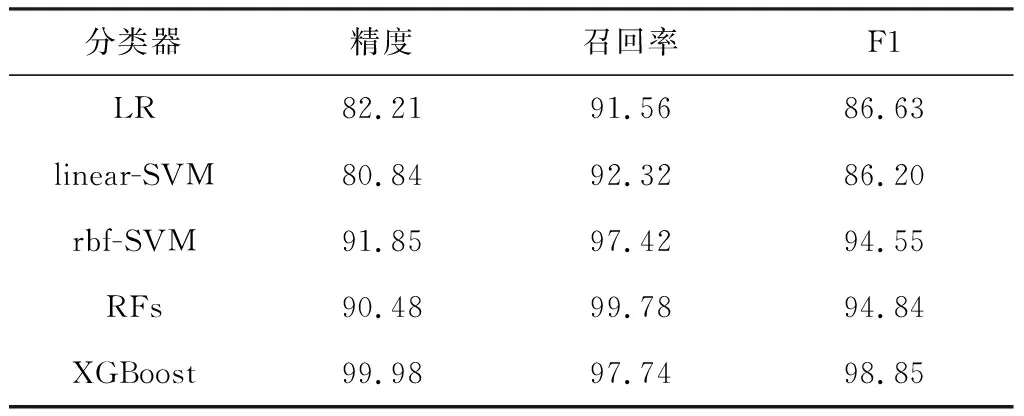
表5 不同分类器对雷达型号4识别效果 %
对于多模式雷达信号数据,LR、linear-SVM线性分类器识别精度较差,其原因可能是多模式雷达之间的信号参数分布具有间断交错的非线性,如图3所示,单一线性分界面不能按类型有效划分此类数据。仿真结果和特征分析表明基于上述常用分选结果特征,线性模型不适用于多模式雷达辐射源的型号识别任务。rbf-SVM和RFs具有非线性分类能力,其精度有所提升,但对多模数据分布的拟合仍有不足。
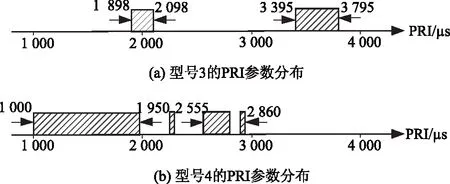
图3 多模式雷达之间的信号参数交错分布示意图
相较于其他分类器,XGBoost具有较好的识别效果,精度和召回率等性能指标相对均衡。根据该模型算法特点分析可能的原因如下:训练算法在前序损失函数的梯度上依次构建子模型函数,相较于子模型独立构建的随机森林,XGBoost的子模型之间具有前后相关的优化关系,具有更低的集成模型偏差;子模型的预测(路径)等效于多维特征组合的权重分数,如图2所示,该集成算法基于加权求和融合多个子模型的预测结果,从不同的子模型角度进一步挖掘雷达信号样式中的参数组合信息[1],相较于单一分界面的分类器,XGBoost更适合于识别多样式信号。综上所述,XGBoost具有多样性、相关性以及特征组合能力,因此能更好地区分多模式雷达信号。
4 结 语
本文提出一种基于机器学习的雷达辐射源型号识别方法,分别采用DBSCAN自动生成模板库和XGBoost进一步分类不同雷达型号,兼顾了传统模板匹配和机器学习算法的优点。通过仿真数据验证评估,本方法能够有效识别不同雷达型号,包括多模式雷达。为适应更复杂的雷达型号识别问题,需构建更多的信号特征。本文采用了常规的RF、PRI、PW参数值,后续可进一步研究更细致的信号特征,如脉间类型特征和脉内调制特征等[1,18]。对于大规模数据,还需要考虑XGBoost的分布式应用[19]。
猜你喜欢
天然气与石油(2022年4期)2022-09-21
电子产品世界(2022年4期)2022-04-21
天然气与石油(2021年5期)2021-11-06
军民两用技术与产品(2021年12期)2021-03-09
天然气与石油(2021年1期)2021-03-08
计算机系统应用(2021年2期)2021-02-23
航天工业管理(2020年11期)2021-01-04
航天工业管理(2020年9期)2020-12-28
航天工业管理(2020年4期)2020-06-16
电子技术与软件工程(2019年18期)2019-11-18
