
一种复杂背景下的智能手势识别模型
2022-09-09 00:45肖洒贺盼博崔强
电子技术与软件工程 2022年14期
肖洒 贺盼博 崔强
(联通(上海)产业互联网有限公司 上海市 200050)
1 引言
近年来,随着手部姿态估计技术的发展,很容易获得精确的手关节坐标。因此,基于骨骼架构的手势识别已经成为一种流行的动作和手势识别方式。各种努力集中于预测手关节和手势类别序列的三维坐标。与图像相比,骨架对变化的背景噪声具有更强的鲁棒性。此外,由于骨架的数据量较小,因此更容易设计轻量级的手势识别模型。因此,本文主要研究基于骨架的手势识别方法。
受计算机视觉任务深度学习取得巨大成功的推动,最近的研究旨在将深度神经网络应用于基于骨架的手势识别。在这些研究中,一些文章将手骨骼序列作为伪图像,其中帧被视为图像的列,手关节被视为行,3D坐标对应于图像的三个通道。因此,基于2D CNN的神经网络可用于提取空间和时间特征,用于手势或动作识别。最近,许多方法将骨架序列嵌入到时空图中,其中每个帧内的关节通过身体骨架的底层结构连接,相邻帧中的相同关节也连接。然后设计了图卷积网络来捕捉动作识别的辨别特征。尽管这些方法已经取得了优异的性能,但它们在捕捉交互式关节的局部特征方面仍然存在固有的局限性。由于骨架序列嵌入到具有固定结构的预定义图像或图形中,交互关节可能彼此不相邻。因此,只有深层才能聚合这些交互关节的信息。刘建议将骨架序列建模为3D体积,利用基于3D CNN的网络提取骨架动力学。通过对骨骼进行体积建模,上述缺陷得到了缓解。然而,在计算资源有限的设备上部署基于3D CNN的网络的代价非常昂贵。
准确定位手部21个主要骨节点,包括指尖和各节指骨关节,返回每个骨节点的坐标信息,输出4个辅助关键点(食指中关节、食指根、中指中关节、中指根)的坐标信息复杂的手势通常涉及五个手指之间的互动。因此,捕捉每个手指的动态以及交互手指的聚合特征对于手势识别至关重要。然而,使用固定关节排列的卷积运算动态地组装交互式手指的特征是困难的。为此,本文引入了自注意机制来代替卷积进行特征聚合。通过动态注意权重,自我注意模块能够灵活捕捉交互式手指的特征。与卷积相比,自注意机制可以直接捕获全局特征,而无需堆叠深度网络,从而可以设计轻量级的手势识别网络。
本文的主要贡献如下:
(1)对数据集进行了优化和扩展。手势图片包括5个拍摄角度、多个年龄组、多个个体、多个背景环境和各种照明条件,更接近现实中AR/VR中使用的实际手势识别环境。构建的数据集样本分布更为均衡。便于模型训练,提升模型识别准确率。
(2)在yolov5模型的基础上,引入了注意力机制模块,提高了计算效率和精度。通过引入Pixels-IoU解决定位框不准确的问题,提高了损失值对处理标注框的敏感性。将优化后的模型与原yolov5和yolov3进行了比较,得到了具有竞争力的结果。
(3)改进后的模型与原始YOLOv5相比,均值平均精度提升了3.2%,对于复杂图片背景,强弱光照下的图片识别,分别获得了94%、98.2%、92%的识别准确率,证明了改进后模型的优势。
2 相关工作
这一部分主要是论述了国内外对基于骨架的手势识别的最新相关工作。由于基于骨架的动作识别任务类似于基于骨架的手势识别任务,因此本文也对基于骨架的动作识别的研究进行了总结。同时也简单的描述了将注意力机制引入计算机视觉领域的最新研究成果。因为YOLOv5是一个比较成熟的模型,这个部分简单的做了一下介绍。
2.1 基于手部骨架的关键点手势识别
在手势识别中,一种比较流行的方法是先对手的形状进行分割,通过检测手的位置或手的形状,再进行手势识别。在基于视觉的系统中,另外一种流行的分割方法是肤色检测,它的核心思路是从杂乱的背景中提取手的部分。云等人提出了一种多特征融合方法,通过结合不变矩特征提取角度计数、肤色角度和非肤色角度来提高识别结果。其中一些手势识别系统借助廉价的彩色手套简化了从背景中提取手的过程。而在文献中使用了一种手套,提供六种独特颜色的颜色编码。王和Popovi使用了一种普通的布手套,但是上面印有一种定制图案,便于特征提取和手势检测。手势识别的另一个方法是使用通过深度传感器拍摄的3D图像,如Microsoft Kinect深度相机和Leap Motion。3D相机在前平面中查看对象并生成对象的深度图像,深度图像用于背景去除,然后生成对象的深度轮廓。使用Kinect的手势识方法见文献。而Molina等人使用了另一种称为飞行时间范围相机的深度相机,该相机提供每像素的实时深度信息。就适用性而言,这种基于视觉的手势分割方法是可取的,因为它只需要大多数笔记本电脑上可用的传统摄像头,并且不需要特殊的深度传感器,从而大大的减少了成本开销。
相对来说,静态手势识别可以通过应用标准模式识别技术(如模板匹配)来实现,而动态手势识别需要时间序列模式识别算法(如隐马尔可夫模型(HMM)或动态时间扭曲(DTW)算法)。HMM是一种统计马尔可夫模型,其中建立的模型被假定为马尔可夫过程。HMM是一个双重随机过程,其基本随机过程是不可观测的,但可以通过另一组随机过程观察到,该随机过程产生一系列可观测符号,并且该模型因其在各个领域的应用而闻名,包括手势识别,如文献。使用HMM进行手势识别的问题在于,如果手势转换过程中的行为没有得到精确训练,其识别精度会降低。DTW是测量两个时间序列之间的相似性的算法之一,这两个时间序列的速度可能不同。
复杂的手势通常涉及五个手指之间的互动。因此,捕捉每个手指的动态以及交互手指的聚合特征对于手势识别至关重要。然而,使用固定关节排列的卷积运算动态地组装交互式手指的特征是困难的。为此,本文引入了自注意机制来代替卷积进行特征聚合。通过动态注意权重,自我注意模块能够灵活捕捉交互式手指的特征。与卷积相比,自注意机制可以直接捕获全局特征,而无需堆叠深度网络,从而可以设计轻量级的手势识别网络。
2.2 自我注意力机制
自我注意机制是Transformer的一个基本模块,它最开始被提出用于机器翻译和自然语言处理。基于Transformer的方法引起了研究者的注意,并且出现了大量基于transformer的方法,并在NLP任务中取得了优异的性能。受Transformer在NLP领域的成功启发,科研人员开始将Transformer引入计算机视觉任务。Vision Transformer将Transformer应用于图像块序列以进行图像分类,并与最先进的卷积网络相比实现了优异的性能。
2.3 YOLOv5网络模型
YOLOv5 网络结构按照处理阶段分为 Input、Backbone、Neck、Prediction 4个部分,如表1所示。Input部分完成数据增强、自适应图片缩放、锚框计算等基本处理任务。Backbone部分作为主干网络,主要使用 CSP 结构提取出输入样本中的主要信息,以供后续阶段使用。Neck部分使用FPN及PAN结构,利用Backbone部分提取到的信息,加强特征融合。Prediction 部分做出预测,并计算GIOU_Loss等损失值。

表1:模型描述与YOLOv5模型图
3 本文模型介绍与改进工作
3.1 YOLOv5网络修改损失参数
YOLO 系列算法通常使用的损失函数类型为GIoU、DIoU和CIoU,从GIoU到CIoU的演变使得回归损失不断精确、目标框回归更加稳定.但在实际实验过程中发现,对具有高纵横比的目标和密集目标,以上3类损失函数均会产生定位框不准确的问题,这极大地限制了目标识别的回归效率.为了解决这一问题,引入Pixels-IoU(PIoU) 函数。
该损失函数通过引入一个旋转参数,使得原有的处理标注框能够更加紧凑地框选目标.考虑到在手势识别情况中,识别目标受到主观印象因素比较大,比如“比耶”这个手势,包含有竖方向,左斜方向和右斜方向。为了精确计算目标交并比(IoU),该损失函数是采用像素计数的方式来计算目标IoU,这使得损失值对处理标注框的大小、位置和旋转都是敏感的.PIoU 损失的计算公式为:

式中,M为所有正样本的集合,|M|为正样本数,真实目标b和目标框b`的b∩b`和b∪b`分别表示两者之间的交集区域和并集区域,PIoU函数的计算公式为:

式中,S和S分别表示经损失函数内核函数处理后,目标b和目标框b`交集的像素量数和并集的像素量数。
3.2 注意力机制的引入
客观现实中需要识别的案例往往具有明显的实际色彩:图像模糊、识别目标所占比例太小,背景色千奇百怪、手势姿势偏斜角度各自不一等等特殊情况占了多数情况。引入注意力机制为了捕获手势上下文的信息与时空领域的信息,可以提取更多的基于骨骼的关节向量信息等特征。


此时,在时间t这个节点,关节之间的距离大小表示为一个矩阵,矩阵尺寸为3×N×N,其中N对应的是手势骨骼关节点的总数,而参数d∈D的计算公式如下:
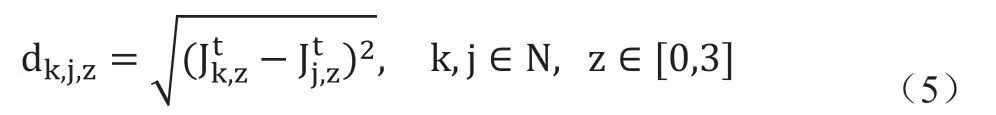
由于Transformer的特性,输入特征向量的最终尺寸取决于所用特征的类型。本文中,手部特征、速度和加速度组成的特征向量大小为240。增加了基于骨骼节点的手势之后,特征向量的大小为640。
4 模型验证及结果
4.1 实验数据集介绍及实验环境
4.1.1 实验环境配置
本文模型是在一台装有NVIDIA GeForce RTX 3090的计算机上实现的,使用PyTorch语言。在前面介绍的工作中,骨架序列被均匀地采样到8帧作为输入。同时,本文采取了数据扩充的方式优化数据集,包括缩放、移位、时间插值和添加噪声。选择Adam作为优化策略,选择交叉熵作为损失函数。培训的批量大小设置为32,辍学率固定为0.1。学习率从0.001开始,一旦学习停滞,学习率将衰减10倍。当学习速率第四次衰减时,就停止整个训练过程。
4.1.2 实验数据集
本文对数据集进行了优化和改良,收集项目中实拍和网络上自然裸手手势数据库,共5万张图片,涵盖各种场景、18种动作手势、5个拍摄角度、多个年龄组、多个个体和各种照明条件。在标签方面,标准中有21个关键点和手势类别。
本文使用 Anaconda 工具创建一个 Python3.8 预处理工作环境,在该环境中,安装 LabelImg工具及其依赖包。LabelImg 工具为目标检测标记工作提供可视化支持,可使用矩形框快速确定目标位置及名称。标注后的文件为 Pascal VOC 支持的 XML 格式,编写 Python 脚本可以快速将 XML格式输出文件转化为 YOLO 支持的 TXT 标签格式。
4.2 实验与结果分析
4.2.1 模型描述
模型描述大致如下:输入为X,输出为U,V是卷积核,*代表卷积操作,vs代表通道数为S的2-D的卷积核。在通道上输入空间特征并学习特征的空间关系。由于每个信道的卷积结果的总和、信道特征关系和卷积核学习的空间关系混合在一起。引入自我注意力模块就是为了摆脱这种混合,使模型直接学习信道特征关系。如表1所示。
4.2.2 实验结果
(1)实验结果表明,各个参数均在60轮次内逐渐收敛(损失参数收敛至 0.010,结果参数收敛至0.999),准确率0.997,
mAP@0.5也达0.996(见图2)

图2:训练结果图
(2)优化后模型网络识别效果图如图3所示。

图3:改进网络的识别效果图
由图3可知,改良后网络基于全局语义信息采集获取到的特征更加精准,识别精准度更高,并且能适应于不同的场景。
由表2结果可以看出:本文改进后的模型的总体 mAP达到0.887,与原始的YOLOv5相比,准确率提升了6.2%,说明改进模型在召回率、准确率等指标上均表现良好。

表2:两个网络对测试集识别准确率和总体mAP对比
在实际应用中,因为主体具有主观性,比如在AR设备中,人们会下意识的调整手势,减少遮挡等情况,反而是外界光照因素称为了主要印象因子,因此,在这部分,本文将强光照与弱光照单独做了模型检验。
实验结果表明(见表3、表4),在较强光照条件下,手势识别效果比较弱光照条件下好,最好的识别准确率能达到98.2%。在较弱光照条件下,准确率仍然能达到92%及以上,如图4所示。由此可知在外部环境变换的情况下,该方法依然能保持一个较好的识别准确率,也证明了整个动态手势识别方法的鲁棒性较好。

表3:较强光照识别结果

表4:较弱光照识别结果

图4:强光照和较弱光照下的识别图像对比图
5 结论和未来工作
综上所述,为了实现精准的手势识别,本文提出了一种基于YOLOv5的优化模型:引入了PIoU损失函数来提高识别效果。引入了具有较强非线性能力的轻量级注意机制模块,有效地避免了传统浅层学习算法中人工干预和识别率低的问题。本文扩展了数据集,包括但不限于明暗处理、手势遮挡、复杂背景贴图、复杂人体手势等。它更符合现实生活中的手势识别应用。模型中使用的测试集也在不同情况下进行了测试,取得了良好的识别效果。通过实验证明,优化后的算法比YOLOv5准确率提高了6.2%,目标识别网络的mAP@0.5达到了0.99。对复杂背景、强光照图片、弱光照图片识别效果较好,在标准Finger Spelling(ASL)、OUHANDS两个数据集也证明了优化后的模型检测准确率高,鲁棒性好,计算速度快。
未来将会将该算法应用于实时动态手势识别,也有更加详细的进一步进行手势关键点识别。
猜你喜欢
电子乐园·上旬刊(2022年5期)2022-04-09
医学食疗与健康(2021年27期)2021-05-13
红领巾·萌芽(2019年9期)2019-10-09
小学科学(学生版)(2018年12期)2018-12-19
中国交通信息化(2018年5期)2018-08-21
中国煤层气(2014年3期)2014-08-07
温州职业技术学院学报(2013年4期)2013-03-11
