
面向边缘计算环境的服务器性能评估及优化模型
2022-09-08 09:40崔建峰
厦门理工学院学报 2022年3期
张 旭,崔建峰,杨 威
(厦门理工学院软件工程学院,福建 厦门 361024)
边缘计算是指在靠近数据源头的一侧,采用网络、计算、存储、应用核心能力为一体的开放平台,就近提供最近端服务。由于传输链路的缩短,边缘计算能够在数据产生侧快捷、高效地响应业务需求,数据的本地处理也可以提升用户隐私保护程度[1]。随着边缘计算能力的不断提高和完善,这种新的计算范式不再受构建集中数据中心的需求所约束[2]。结合虚拟化和云计算技术,边缘计算建立起数量多、规模小、分布广的边缘节点,这些节点可以为多种应用场景提供服务[3-4]。目前,许多云厂商如AWS、微软、阿里、腾云等纷纷布局边缘计算,与其各自云计算、CDN业务复用基础设施,包括边缘节点、服务器、网络等资源[5-7]。
由于边缘计算的分布式特性,边缘节点的规模、网络质量、硬件性能与配置、带宽成本等参差不齐,如何在复杂的网络环境中跨集群管理成千上万台边缘服务器,在提升服务质量的同时又降低业务成本,成为边缘计算面临的一大挑战[8-10]。当前,常见的边缘计算节点规模较小,服务器数量一般在100台以内,服务器故障的容错率较低[11]。同时,边缘计算节点地理位置分布较广,大部分没有IT维护人员,造成了故障恢复周期长、运维成本高等问题[12-13]。边缘计算的业务类型是多样化的,包括物联网、视频、游戏、工业自动化等,不同业务对底层计算资源的要求差异巨大[14-16]。因此,边缘计算往往对服务器的可靠性与配置有较高的要求,特别是当边缘节点没有备份时,以上问题将会成倍放大[17]。在边缘计算起步阶段,针对服务器管理的研究主要以网络监控为主[17-19],多数研究方法针对服务器硬件层及操作系统层进行监控分析,重点关注服务器的利用率及稳定性[20-25]。随着边缘计算的兴起,相关研究将重点放在如何提升边缘计算服务器服务质量及运维效率上,在保障系统稳定运行的同时,进行了服务质量 (quality of service,QoS)优化。这些研究方法主要基于服务器端的数据采集,通过智能控制、机器学习相关算法实现服务器故障检测及预警、性能管理、配置管理、运维决策等[26-27]。黄冬晴等[28]提出一种基于贪心算法的最优计算资源分配和卸载策略,它可以有效降低边缘计算的用户成本。任丽芳等[29]提出用户空间聚类算法及边缘服务器QoS预测算法,它可以对边缘节点服务器的QoS状态进行预测和优化。付韬[30]在分析现有边缘计算系统架构基础上,提出了一种端到端服务质量测试及评估方法。目前,这些研究多以降低故障率为主要目标,且较少涉及边缘计算的上层业务,因此,在提高运维效率、服务器性能及成本优化、细化管理颗粒度等方面效果不明显。
为了从服务器端有效发现瓶颈,提升服务质量,基于边缘计算业务的特点,本文设计出一种服务器性能评估及优化模型,实现对服务器的动态业务规划和软硬件配置的优化调整,在提升业务质量的同时,降低运维工作量和边缘计算业务的总拥有成本。
1 系统模型设计
1.1 基本模型架构
对于边缘计算应用而言,服务器性能指标与服务器硬件配置、业务特征有关,因此,在相同业务特征下的服务器性能指标才具有分析的意义。本模型先从单台服务器中动态采集边缘计算业务特征指标、性能指标和服务质量指标等,通过汇聚算法从采集的海量数据中得到本模型常用的汇聚指标。基于汇聚指标,通过巡检模型评估需要进行优化的目标服务器,并根据动态调整模型中的决策方案对服务器实施优化调整。模型架构设计具体如图1所示,本模型主要包括以下4个模块:
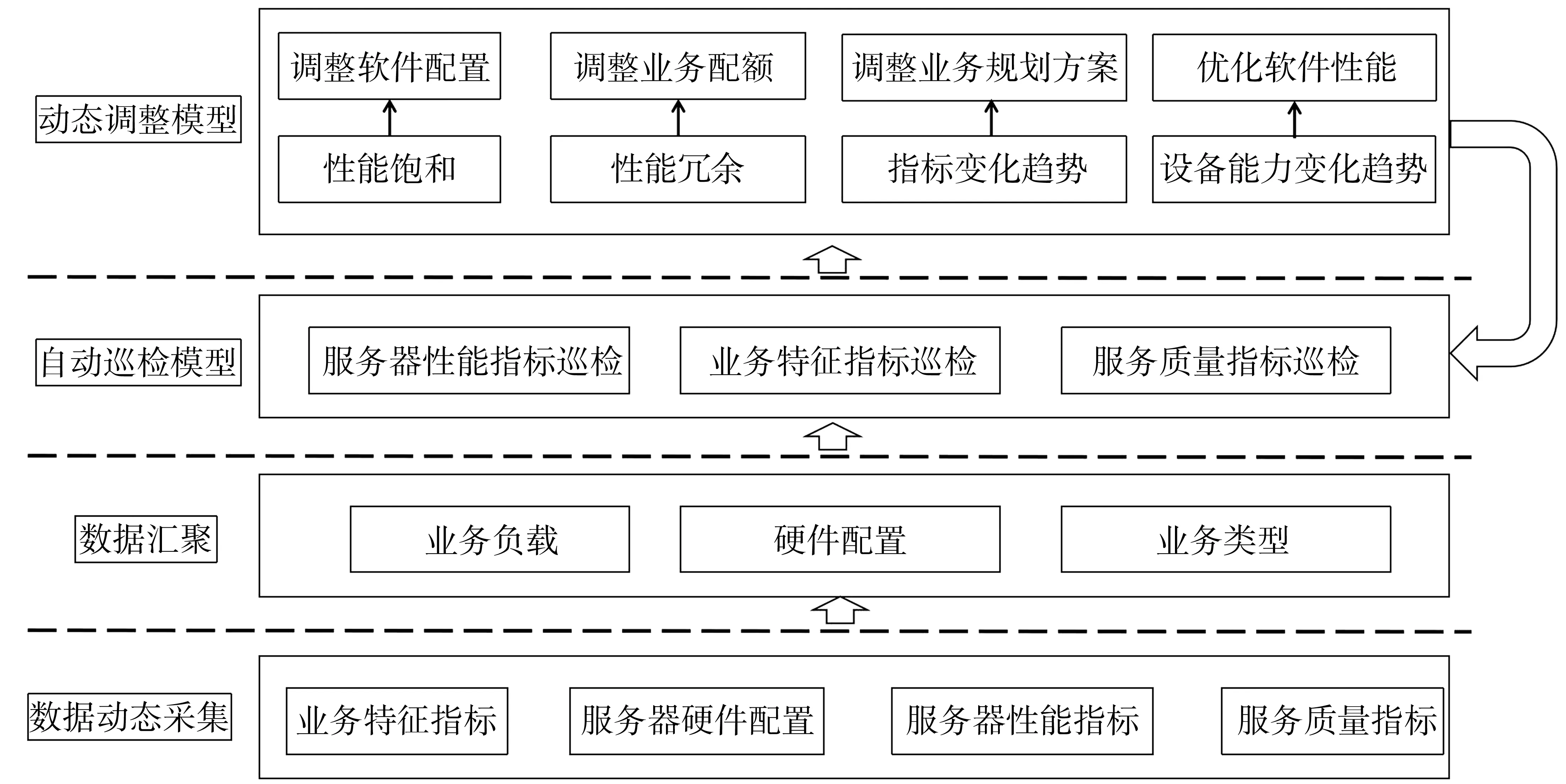
图1 模型总体架构图Fig.1 Model architecture
1)数据动态采集模块。本模块部署在边缘节点的每台服务器上,采集内容主要包括业务指标、系统指标、硬件指标等。比如:代表业务特征的http/https请求数、磁盘IOPS;代表业务负载大小的流量带宽;代表服务器配置的CPU型号、内存容量、磁盘配置;代表服务器性能的CPU使用率、内存使用量、应用内存使用量、磁盘容量使用量和磁盘输入输出性能相关指标;代表服务质量的软件首包响应时间等。基于边缘计算的特点,其业务流量和负载是随时间动态变化的,每天都会有低谷期与高峰期,性能消耗在流量高峰期是最大的。该模块的数据采集粒度为分钟,并动态计算流量高峰期的相关指标数据进行汇聚。
2)数据汇聚模块。服务器的性能指标、服务质量指标与业务特征、业务流量大小、数据时间、业务类型及服务器配置有关,在数据采集模块采集到服务器相关信息后,需要在数据汇聚模块将运行相同业务类型的服务器进行归类,根据不同的服务器配置、业务流量等进行汇聚。该模块采用了自定义的日峰值算法、日均值算法、超阈值占比算法等。
3)自动巡检模块。本模块实现自动巡检功能,通过各项指标的波动率及阈值模型实现自动巡检算法,当此算法的每项指标的波动率或者值超过阈值时,就触发巡检命中条件,命中后将依据巡检结果提供决策依据,处理的紧急程度分为严重、中等、轻度等。
4)动态调整模块。通过对服务器性能、业务特征和服务质量等汇集指标的评估,得到需要优化的目标服务器及决策依据,依据模型给出的不同条件对服务器进行优化。针对边缘计算服务器的特点,采取的主要优化措施包括服务器配置调整、业务能力配额调整、业务规划方案调整、优化软件和配置、持续关注暂不处理等。对任何服务器的优化调整将动态反馈给巡检模型对相关指标进行修正。
1.2 系统实现方式
在数据采集模块,本文把需要采集的服务器信息归为4类,主要包括业务特征指标、硬件配置信息、服务器性能指标和服务质量指标,每一类指标包含一些服务器相关的软硬件参数,具体见表1。
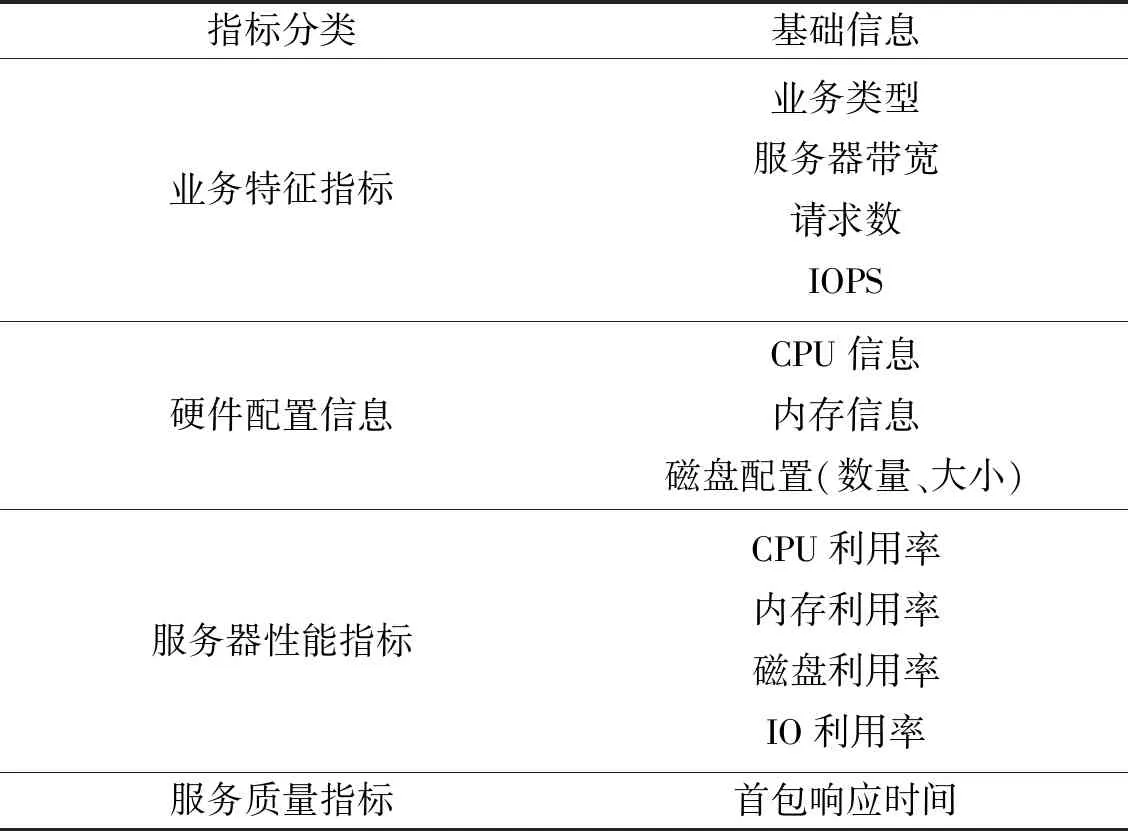
表1 基础数据表Table 1 Basic data
在本研究提出的服务器性能评估及优化模型中,将相同业务类型的机器先汇聚后进行巡检,针对每台服务器需要先选取各指标的当日负载值代表当天负载消耗情况。边缘计算的业务流量是随着客户的使用而动态变化的,因此,对每个指标的采集周期为分钟,并选取每天采集结果中从大到小排在5%数据作为该指标的当日负载值。各个指标的汇聚方式按照如下算法进行计算。
1)日峰值汇聚算法。该算法的计算公式为:
(1)
将xi从大到小进行排序,即
x1≥x2≥x3≥…≥xm≥…≥xn。
(2)
式(1)~式(2)中:PX表示某个具体指标的汇聚日峰值,比如PQPS、PIOPS等;xi代表第i台服务器的某个具体指标的当日负载值,比如QPS、IOPS等;m=|w×n|,w为需要的“峰w值”,本文取“峰二十值”,n为满足巡检范围的服务器总数。
2)日均值汇聚算法。该算法的计算公式为:
(3)
式(3)中:AX表示某个具体指标的汇聚日均值,比如AQPS、AIOPS等;xi为第i台服务器的满足巡检范围的指标当日负载值;n为满足巡检范围的服务器总数。
3)超阈值占比算法。该算法的计算公式为:
(4)
式(4)中:RX表示某个具体指标的超阈占比值,比如RQPS、RIOPS等;m表示指标数据超过阈值的机器数;n为满足巡检范围的服务器总数。
通过以上算法,可以得到本模型中常用的汇聚指标,具体见表2。在自动巡检模块中,需要对各个采集及汇聚的指标设定阈值,本文模型包含的阈值见表3。

表2 汇聚指标名称Table 2 Aggregation indicators
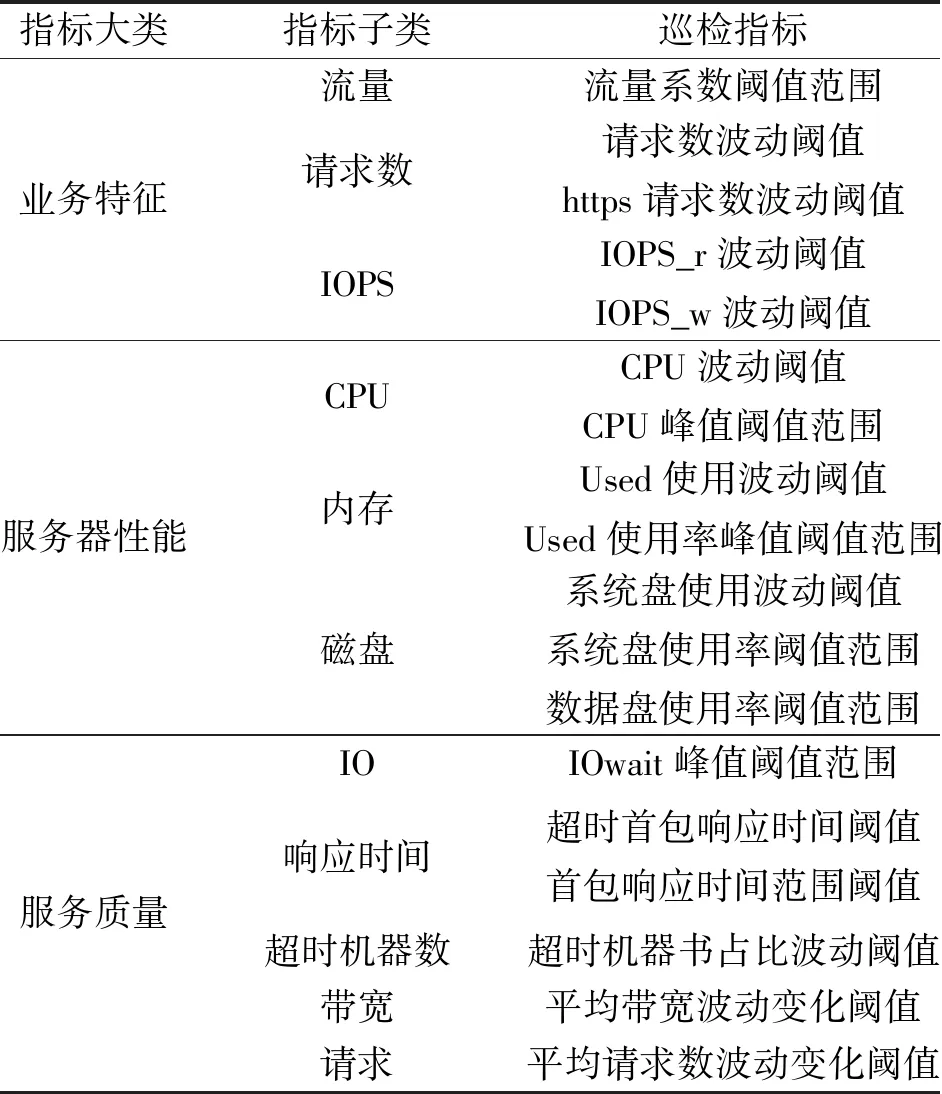
表3 配置巡检阈值表Table 3 Check threshold values
巡检模块会将计算获得的各性能评估值与设定性能评估阈值进行比较,具体的比较逻辑遵循以下原则:1)判断计算峰值是否大于对应峰值阈值;2)若计算峰值不大于对应峰值阈值,则判断计算均值是否大于对应均值阈值;3)若计算均值不大于对应均值阈值,则判断服务器占比是否大于对应占比阈值。
在对比算法中,将计算所得的性能评估值与预设的性能评估阈值进行比较,对计算得到的波动值与对应的阈值进行比较,生成针对同一分类的服务器的性能评估结果。具体逻辑为:1)若峰值不大于对应峰值阈值,均值不大于对应均值阈值,且占比不大于对应占比阈值,则此类服务器生成不存在异常的性能评估结果;2)若峰值大于对应峰值阈值,均值大于对应均值阈值,且占比大于对应占比阈值,将大于预设的性能评估阈值的性能评估值对应的性能评估数据进行异常标注,此类的服务器存在异常的性能评估结果。
比如:在大于预设的性能评估阈值的性能评估值对应的性能评估数据是业务特征指标对应的业务特征数据时,得到此类服务器存在异常的性能评估结果,包括http请求波动率升高、https请求波动率升高、每秒进行读写操作的次数IOPS波动率升高中的任意一项或几项;在大于预设的性能评估阈值的性能评估值对应的性能评估数据是设备性能指标对应的设备性能数据时,得到此类服务器存在异常的性能评估结果,包括波动率升高+过高天数占比高、波动率升高+过高天数占比0、波动率升高+过低天数占比0、波动率降低+过高天数占比0、波动率降低+过低天数占比0、过低天数占比中的任意一项或几项。文中以QPS请求波动值为例,对自动巡检算法进行描述:
(5)
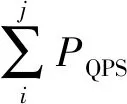
在本研究方法中,其他指标对应的波动值的计算与上述给出的计算请求数波动值方式基本相同。关于各指标对应的使用率波动范围的计算,具体如下:
(6)
式(6)中:Rhigh为使用率过高天数占比;Rlow为使用率过低天数占比;m为巡检时间段中大于对应使用率最大值的天数;i为小于对应使用率最小值的天数;n为巡检时间段总天数。
通过以上的巡检算法即可得到性能评估结果,评估结果由各个指标对应组合而成。本研究根据不同评估结果给出对应的决策方案,具体见表4。
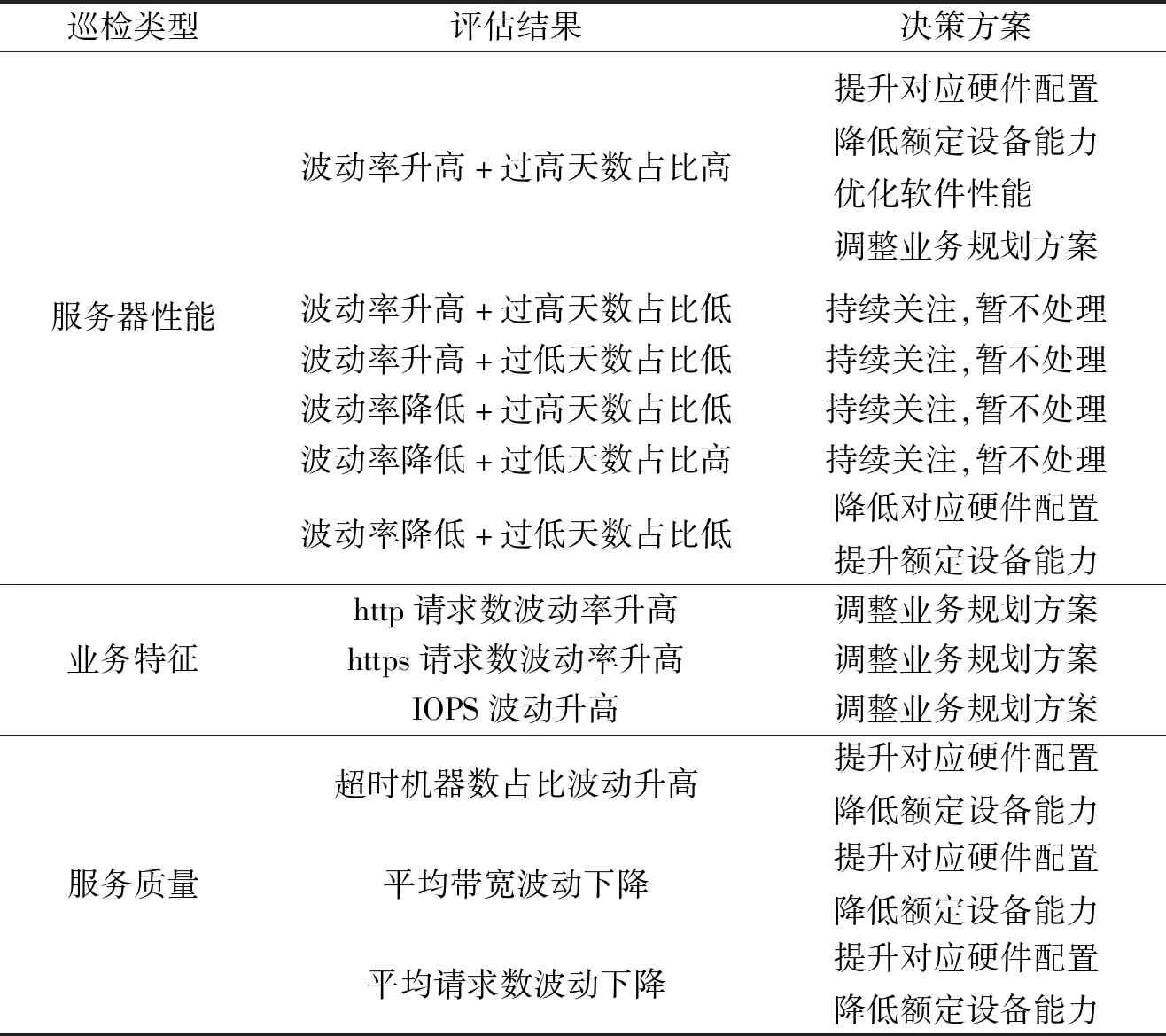
表4 评估决策表Table 4 Evaluation and decision making
在上述决策方案中,设计软件优化、业务规划调整、额定能力调整等方案,均可以与现有的业务系统或者监控系统进行对接,自动化完成,可以减少人工维护的成本及系统优化的效率。由于绝大部分服务器在边缘节点,涉及硬件调整的方案可以先做预警,待维护人员去现场时再进行调整。通过本性能巡检模型提前发现硬件异常,是目前大部分服务器监控系统实现不了的功能,也是在边缘计算节点环境中迫切需要的功能。
2 实验结果与分析
本文的研究成果已应用于某边缘计算服务商的真实环境,目前部署该模型的节点规模超过400个,涉及的场景包括物联网、互动直播、在线教育、视频监控、工业互联网等。根据边缘计算的特点,边缘节点的运行和部署都是动态的,为保证资源合理性,会通过调度算法将节点的服务器平均利用率控制在60%~80%[31-32]。为了进行有效对比,本实验按照如下标准选择边缘计算节点进行结果分析:1) 节点服务器数量大于64台;2) 节点连续运行时间大于12个月;3) 部署本模型时间超过6个月;4) 节点服务器平均利用率在60%~80%。最后筛选出60个边缘计算节点,具体实验环境见表5。

表5 实验环境Table 5 Testing environment
为了说明运行效果,文中统计了模型部署后6个月触发决策方案的类型和数量,并与前6个月进行对比。在未部署该模型前,只有部分措施用于服务质量异常报警或者服务器宕机时的被动处理,此部分数据取自系统的维护日志。具体结果见表6。
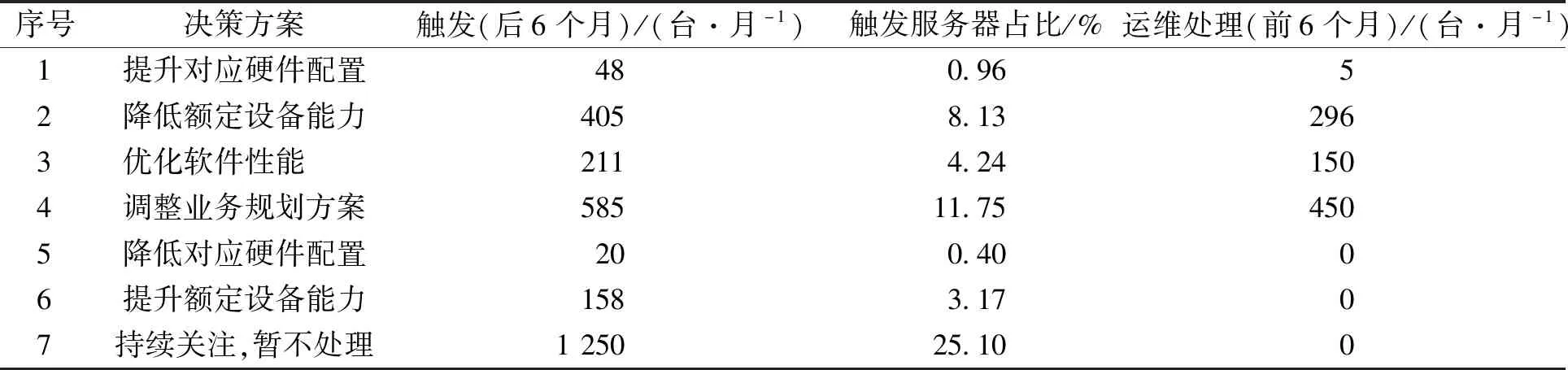
表6 测试结果Table 6 Testing result
由表6可以得到:
1)本模型每月触发的降低额定设备能力、优化软件、调整业务规划方案等措施约占总体服务器的25.08%。与模型部署以前相比,这4项措施的实施次数每月增加了348次,增加38.62%,说明可以通过模型主动发现系统隐患,大大提升了服务质量。通过模型自动完成优化工作,减少了人工运维的时间。根据这几项工作量在运维工作中的占比(约40%),可以估算出运维效率提升了10%左右。
2)本模型触发提升额定设备能力及降低硬件配置的比例约占3.57%,可以通过这部分的工作及时提升服务器利用率,从而降低系统成本。在未部署本模型之前,系统暂无对应的成本优化策略。
3)需要对服务器进行物理操作的如提升硬件配置、降低硬件配置的情况约占1.36%,通过发现类似情况,可以提前计划维护人员进行现场运维的工作,减少人工运维的成本,提高运维效率。
4)本模型记录了约25.10%的系统异常,这部分处理意见为暂不处理,但是通过模型提前识别风险,也可以对系统的可靠性和稳定性提供有力的数据支持。在未部署本模型之前,系统暂无法识别此范围的服务器。
测试结果提取了模型部署前后6个月的系统异常警告数据(见图2),对比结果可见,本模型上线后的6个月,系统异常日均警告次数由20.6下降到15.2,下降比例达到26%,也说明,通过对服务器性能的巡检评估及时调整,明显减少了服务质量的下降甚至是故障的发生。
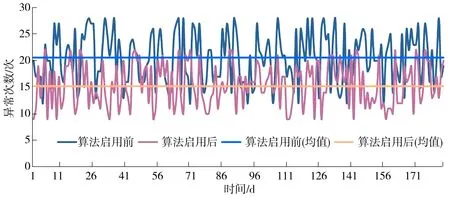
图2 系统异常统计Fig.2 QoS exceptions
3 结论
基于对单台服务器动态采集的多维指标,并通过汇聚算法得到业务汇聚指标,通过自动巡检和动态调整对业务进行监控分析和性能优化,本研究提出了面向边缘计算环境的服务器性能评估及优化模型。该模型实现了以下目标:
1)实现了基于服务器性能评估的动态优化调整。该模型可以动态识别不同业务关联的节点和服务器,并根据业务特点动态制定评估模型,得出优化决策方案应用于此范围的服务器,实现以业务类型为粒度的动态管理,在提高业务性能的同时使运营效率提升了10%。
2)实现了服务器端的多维度分析及决策支持。该模型提炼出描述业务特点指标与衡量服务质量指标,同硬件性能指标相结合,从多维度分析服务器性能消耗原因,为业务提供包括软硬件配置、设备能力规划、业务负载调度等决策方案,将系统服务质量提升26%,同时降低了3.57%的运维成本。
3)实现了面向分布式服务器的自动化性能监控。通过对周期内的指标数据进行数据分析,制定巡检算法及预测模型,自动化输出决策方案与相应的变化趋势,实现智能化运维管理。
基于本模型的思路,后续可以进一步改进算法,对本文提出的指标类型、评估阈值、判断模型等引入机器学习相关算法进行自动学习,从而提高评估模型的准确性与智能化程度。
猜你喜欢
铁道通信信号(2019年9期)2019-11-25
制造技术与机床(2019年9期)2019-09-10
网络安全和信息化(2019年8期)2019-08-28
成都信息工程大学学报(2019年5期)2019-05-21
西南交通大学学报(2018年6期)2018-12-18
通信产业报(2016年44期)2017-03-13
知识产权(2016年8期)2016-12-01
网络空间安全(2016年3期)2016-06-15
探测与控制学报(2015年4期)2015-12-15
雕塑(1999年2期)1999-06-28
