
大气环境分类的SVM联合决策方法
2022-09-07 07:46王竟成张伦武杨小奎胡学步周俊炎李泽华吴帅
装备环境工程 2022年8期
王竟成,张伦武,杨小奎,胡学步,周俊炎,李泽华,吴帅
(1. 西南技术工程研究所 弹药贮存环境效应重点实验室,重庆 400039; 2. 重庆理工大学 化学化工学院,重庆 400054)
迈入数据时代,时刻都有千亿量级的数据产生,高效的数据分析处理手段一直都是研究热点。气象环境是典型的海量数据生产制造领域,遍布全球的气象监测站不断收集着温度、湿度、降水等数据。这些宝贵的数据资源在经济、军事、社会等各个领域产生着巨大效益。运用各类挖掘分析算法研究环境数据资源的内在规律,提炼隐性知识,能显著提升我们的认知,有效促进数据增值。
气候分类最初源于农业生产,通常对应于植被分布,即每种气候类型由一种植被区域或生态区域支配。气候分类的方法很多,其中科蓬气候分类及其衍生方法应用最多。温度和降水是植被分布的主导性因素,因而是气候分类最基本的变量。材料/产品的使用、服役与植被的分布类似,也具有一定的区域局限性,并且除温度、降水外,应考虑更多的环境因素,如湿度、太阳辐射等。太阳辐射会显著加速高分子材料的老化,湿空气极易引起电子元器件的失效,此外还有温度–湿度–太阳辐射之间的耦合作用引发的性能退化与功能失效。基于农学的传统气候分类方法,不能满足装备产品的多环境因素的分类辨识需求。因此,构建一个综合的环境分类分析决策方法指导装备设计与使用维护具有重要意义。
诸多学者对大气环境的分类辨识开展了研究。如张伦武等使用模糊聚类分析了腐蚀大气环境。吴超等采用有序样本聚类开展了腐蚀大气分类的细化研究。唐其环使用灰色聚类分析了化学成分对大气腐蚀的影响。前期研究中,从产品使用与装备服役的角度,提出了主成分聚类分析法,用于中国城市的环境分类,但并未考虑新增城市的快速分类辨识问题。本文进一步进行了深化拓展,以91个亚非欧城市的环境数据作为输入,在主成分聚类分析的基础上,采用多个支持向量机分类器,组建大气环境分类的联合决策模型,用于城市环境的分类辨识,指导产品设计与使用维护。
1 数据与方法
1.1 技术路线
本研究构建了一种联合决策模型用于城市大气环境的快速分类辨识,技术路线流程如图1所示。首先收集、整理能代表地区环境类型的环境因素,具体包含温度、相对湿度、降水量和太阳辐射累积量等,组装成分析数据矩阵。将各数据列标准化后进行主成分分析,计算得到特征值与特征向量,利用累积贡献率确定主要成分,采用主成分的欧几里得距离表征各城市之间的相似性,以此为依据进行层次聚类。将聚类结果作为训练测试数据,利用联合支持向量机(Support Vector Machine,SVM)分类器进行得分评估,从而构建联合决策模型。采用训练好的联合决策模型,不仅能对新增城市的大气环境类型进行判别,也能对大气环境的主成分数据空间进行区域划分,形成分区云图。

图1 技术路线流程 Fig.1 Technical route flow diagram
1.2 数据
为开展国内外城市大气环境的分类预测研究,从中国气象数据中心网站下载了91个亚非欧城市(包含38个中国城市)近10 a(2010—2019年)的年值数据。数据集包含5个有效环境变量,包括纬度、年平均温度、年均相对湿度、年均降水量、年累积辐射量。求取各环境因素10 a间年值数据的平均值,组合成分析矩阵,以此表征这些城市的大气环境信息,部分城市环境数据见表1。

表1 部分国内外城市环境数据 Tab.1 Environmental data of 8 cities
表1中,各列环境变量之间并非完全独立,存在一定内在联系。例如,平均温度明显受纬度影响,相对湿度和降水显著相关。将表中原始数据(X)以列为对象标准化后(X'),采用式(1)计算相关系数矩阵[R]。
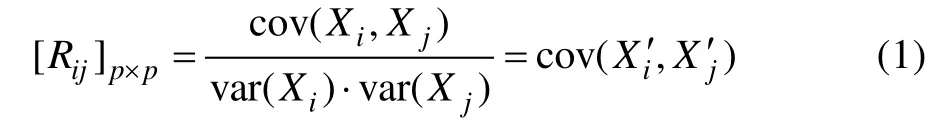
式中:var表示方差,cov表示协方差
由表2的相关系数矩阵可见,平均温度、降水量与纬度呈负相关,相关系数分别为–0.821、–0.793。降水量与湿度相关系数为0.803,显著正相关。辐射累积量与纬度、平均温度的相关性很低。

表2 相关系数矩阵 Tab.2 Correlation coefficient matrix
1.3 分析方法与模型
多变量数组中,一些变量之间存在随动关系,可能是衡量同一系统行为的因素。在气象数据系统中,诸多变量仅有少数的驱动型因素,因此可以采用少数的组合变量来代替原始变量组,即进行数据降维,以此简化数据分析矩阵。主成分分析法(Principal Component Analysis,PCA)作为一种广泛应用的高效算法,能有效地从多变量数据中剔除冗余成分,筛选少数足以解释结果的独立成分。本研究将表征城市环境特征的数据矩阵通过PCA提取主成分,作为层次聚类的输入。
聚类是数据分析中最基本、最普遍的问题。观测对象数据通常自然成团聚类,同一类的对象特征相似,而不同类的对象特征相异。本研究采用层次聚类,通过构建聚类树将不同对象的数据进行聚集。聚类树并非如同K-Means方法中的单个聚集体,而是一个多层级的层次结构,上个层级的聚集体在下个层级会继续合并在一起,各对象之间的相互关联较清晰。在具体应用时,可以根据需求选择最合适的聚类层级或规模。研究中首先计算各城市主成分在数据空间中的距离,评估其相似性。根据相似性,将关系相近的对象归类到二元聚集体中,新的聚集体又进一步归类到更大的聚集体,直至聚类树形成。以聚类树为依据,选择合理的层级,得到城市大气环境的聚类结果。
将上述主成分聚类分析的结果划分成训练集与测试集,采用支持向量机(SVM)算法进行分类学习训练与预测。支持向量机的主要思想是将输入空间的非线性问题,通过核函数映射到高维特征空间,并在此空间搜寻使类间间隔最大的超平面,将数据样本划分开。目前常用的核函数主要有多项式、高斯径向基函数、Sigmoid、傅里叶等4种核函数。基于结构风险最小化准则,SVM网络拓扑结构由支持向量决定,是介于简单算法和神经网络之间最好的算法。它仅有3个自由参数,问题复杂度不取决于特征的维数,只通过几个支撑向量就能确定超平面,忽略细枝末节,可以处理复杂的非线性问题。同时,通过引入松弛变量,SVM能够解决类间的重叠问题,并提高了泛化能力。SVM在处理小样本、非线性时具有明显优势,可规避其他机器学习算法中易于出现的局部极小以及过拟合现象,已被广泛应用于趋势预测与故障诊断等领域,如空气质量预测。
根据城市的分类数确定分类器个数,由各个分类器的得分评判城市的所属分类,并采用测试数据评估训练后模型的有效性。串联起PCA、层次聚类与SVM分类器,组建大气环境分类的SVM联合决策模型,模型部署后可用于城市大气环境分类的快速判别与主成分数据空间的区域划分。
2 结果与讨论
2.1 主成分聚类分析
由相关系数矩阵(见表2),构建特征矩阵|λIR|=0,计算得到特征值及其对应的特征向量(见表3)。特征值表征成分之间的方差,采用降序排列,每个特征向量即为一个主成分的参数矢量。由表3可见,主成分1(PC)方差的贡献率为60.6%,主成分2(PC)的贡献率为27.3%,主成分3(PC)的贡献率为7.5%。仅采用PC与PC时,方差的累积贡献率为87.9%;而采用前3个主成分时,累积贡献率可高达95.4%。

表3 特征值及其对应特征向量 Tab.3 Eigenvalues and corresponding eigenvector
将特征向量(B)与标准化后的变量值(X')点乘计算主成分得分PC。本研究中,选择前3个主成分来表征城市的主要环境特征,包含原始变量95.4%的信息。以主成分得分作为坐标值(PC, PC, PC),在图2的数据空间中把每个城市标注出来,根据距离远近粗略地展示了不同城市之间的相似性。
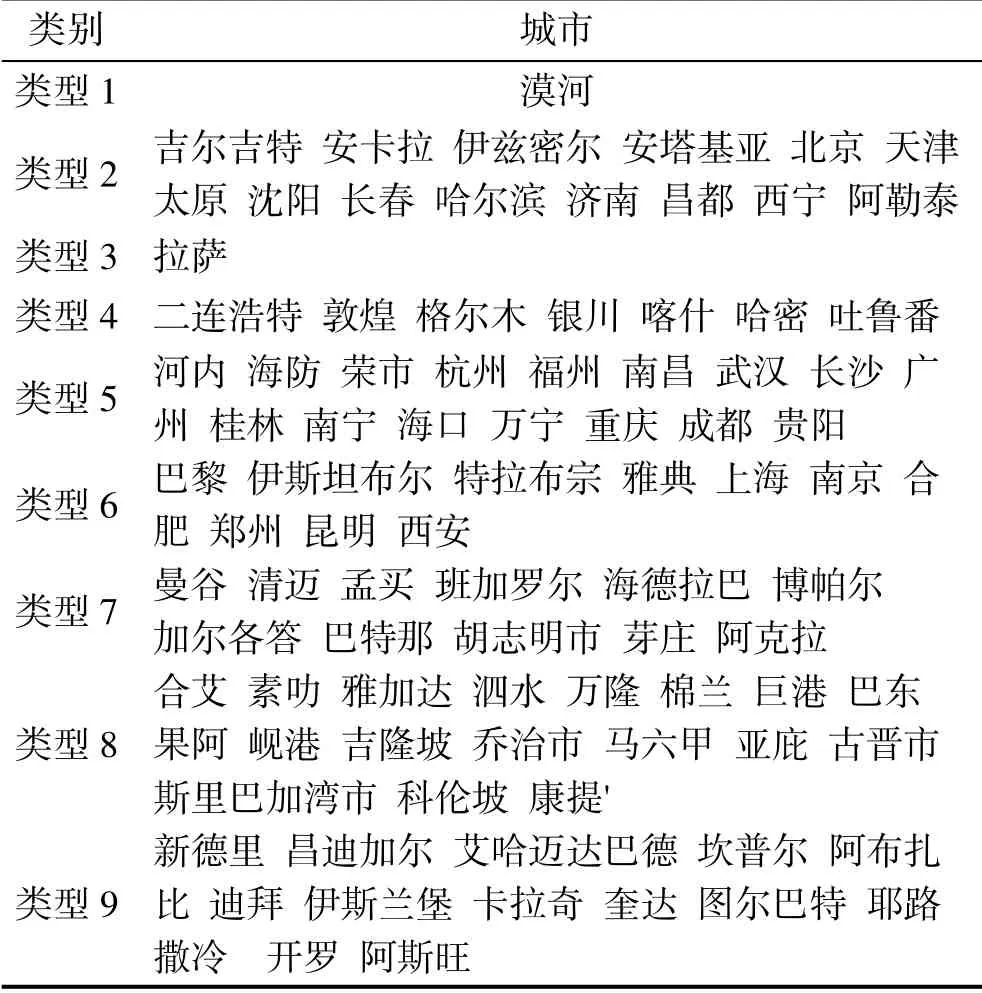
表4 城市大气环境聚类结果 Tab.4 Atmospheric environment classification of 91 cities
利用不同城市的主成分得分进行层次聚类,通过计算欧几里得距离d=sqrt(PC+PC+PC),衡量城市之间的相似性,从而构建层次聚类树,如图3所示。从聚类树可见,当前91个城市大气环境的最优聚类数目为9,由差异值等于2.5的虚线从层次聚类树中划分出来。虚线之下,同一簇团内城市之间的相异性低于2.5,代表一种环境类型,用同种颜色绘制。91个城市中,海防与河内的差异值最低,仅为0.135,从大气环境的角度来说它们犹如孪生城市;格尔木与巴东之间差异值最高,为6.701。城市聚类结果见表4,类型8为赤道附近的热带雨林气候,类型7为高温多雨的热带气候,类型5为亚热带湿润气候,类型9为亚热带半干旱气候,类型6为温带湿润气候,类型4为温带干旱气候,类型2为寒温带半湿润气候。严寒地区漠河(类型1)、高海拔城市拉萨(类型3)与其他城市的环境特征区别较大,自成一类。
2.2 SVM联合决策分类
图2 主成分数据空间中的城市分布 Fig.2 Distribution of 91 cities in principal component data space

图3 91个城市的层次聚类树 Fig.3 Hierarchal clustering tree of 91 cities
基于支持向量机建立9个并行的二分类器,每个 分类器评估对应编号类别的可信度,使用分区聚类结果对所有分类器进行训练。利用训练好的联合分类器分别计算城市大气环境属于每个分区的可信度得分,指定可信度得分最高的分类为当前城市的归属分区,并根据得分判断其可信水平。对于当前应用场景,规定:可信度>1,可信水平极高;1>可信度>0.4,可信水平高;0.4>可信度>0,可信水平中;0>可信度>-0.4,可信水平低;-0.4>可信度,不可信。
91个城市中,抽取10%(9个)的城市作为测试集,其余城市作为训练集训练SVM联合决策模型。由于类型1与类型3仅有1个城市(见表4),为保证训练集对象种类的全覆盖,应避免将拉萨与漠河选入测试集。从测试结果(见表5)来看,本文构建的SVM联合决策模型对当前数据集的预测准确率为100%。从可信度得分来看,9个测试数据中4个城市的可信度>1,可信度极高;3个城市可信度∈[0.4, 1],可信度高;2个城市可信度∈[0, 0.4]。其中,可信水平高以上的占比为77.8%。可见,大气环境分类的SVM联合决策模型具有较高的可靠度。
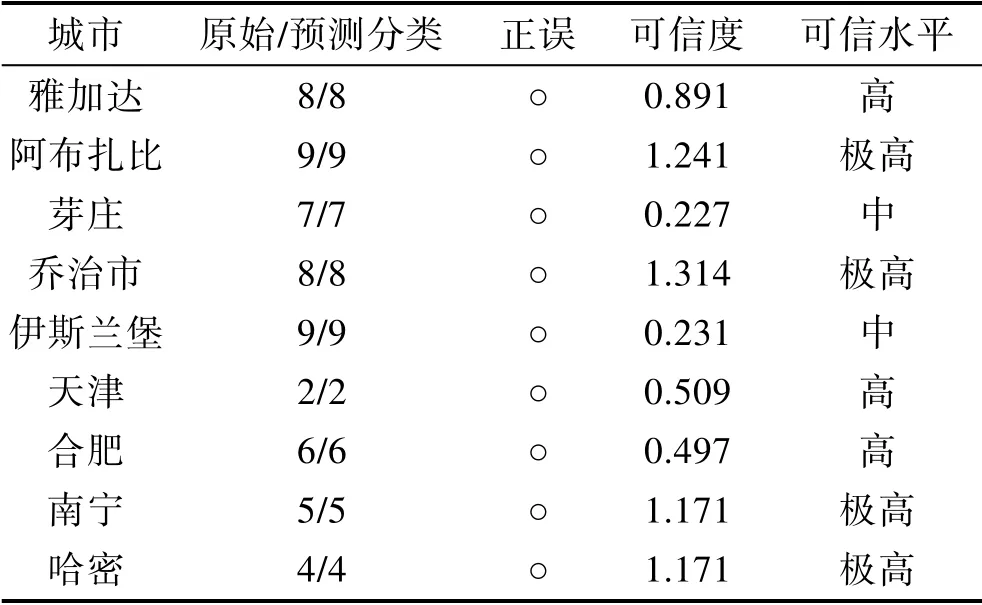
表5 测试集分类预测结果 Tab.5 Prediction results of test data
将91个城市的数据全部用于训练,生成样本点更全的联合决策模型。统计结果(表6)显示,其预测准确度97.8%,预测博帕尔与巴纳特时失效,这2个城市聚类结果为类型7,预测结果为类型9,可信水平为中。在后文的主成分数据空间中,这2个城市正好处于分区7与分区9的交界面,说明博帕尔与巴纳特处于类型7向类型9过渡的区域。在图3的层次聚类树中,若聚类的相异值设定为2,那么博帕尔、巴纳特、海德拉巴与班加罗尔将从蓝色分支(类型7)中独立出来,成为一个新的细分类型。预测结 果中,可信度极高的数目占比为58.2%,高以上的占81.3%。由此可见,本文所构建的模型既具有一定泛化能力,没有出现过学习的现象,也保持了较高的准确率与可靠度。
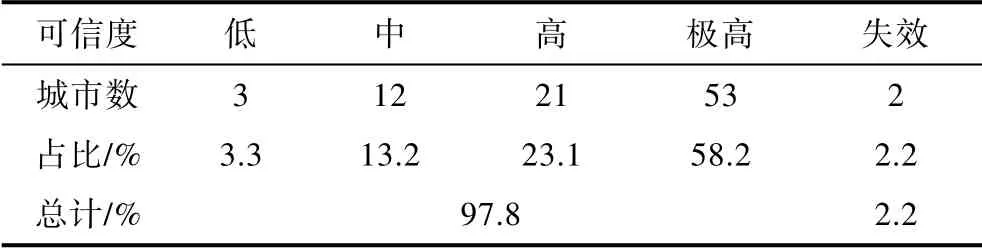
表6 分类决策模型的有效性 Tab.6 Validity of present prediction model
限定边界框范围为:min(PC)≤X≤max(PC),min(PC)≤Y≤max(PC),min(PC)≤Z≤max(PC),遍历主成分数据空间边界框内的所有点,格点间隔取0.1。通过分类决策模型计算每个格点的可信度,将可信度得分最高的类别判定为该格点的分类。对于最高可信度得分低于-0.4的格点,判定为不可信,不划入任何分类,数据空间中表现为空白区域。图4将各分类的区域范围可视化为不同颜色的团簇。取PC=0,绘制分区云图中间截面的剖面图(图4右上部),包含7个分区。在分区云图中直观可见各分区之间的相互关联:热带气候(分区7)处于数据空间的中心位置,与大多数环境类型都相接;热带雨林气候(分区8)与温带干旱气候(分区4)差异很大,处于数据空间的两端;严寒地区(分区1)与高海拔地区(分区3)处于数据空间的边缘位置,环境典型而独立。
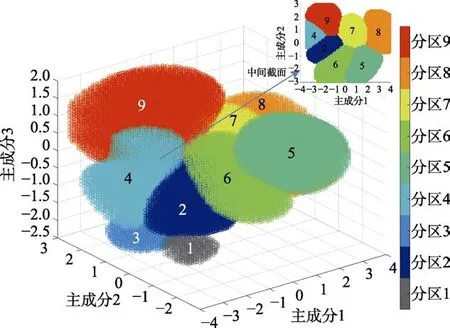
图4 主成分数据空间中的分区云图 Fig.4 Classification clusters in principal component data space
由于数据集中分区1与分区3仅有1个城市,通过联合决策模型判别出的区域较小,处于主成分数据空间左下部(PC<0,PC<0)。数据空间右下部(PC>0,PC<0)表征着中等温度、中等辐射、高湿度、高降水的环境,该区域为空白表明当前数据集中不含这类型的城市。数据空间右上部(PC>0,PC>0)也是空白,这块区域代表着高温、低辐射、中等湿度、中等降水环境,而高温、低太阳辐射这种环境类型比较特殊,满足此条件的有中高纬度的活火山附近地区,不适宜人类居住。
3 结论
1)采用主成分聚类分析将亚非欧91个城市划分为9类大气环境类型,3分量主成分包含了5种环境因素95.4%的信息,数据集城市中河内与海防环境最类似,巴东与格尔木环境差异最大。
2)融合9个支持向量机分类器组建联合决策模型,利用主成分聚类结果对模型进行训练,结果表明,该模型对大气环境类型预测的准确率高达97.8%。
3)应用大气环境分类的联合决策模型将主成分数据空间划分为9大团簇,并可视化为分区云图,使各分区之间的相互关联直观可见。热带气候处于数据空间的中心位置,与大多数环境类型相接;热带雨林气候与温带干旱气候差异很大,处于数据空间两端;严寒地区与高海拔地区处于数据空间的边缘位置,环境典型而独立。
猜你喜欢
计算机时代(2022年9期)2022-11-03
现代电子技术(2022年15期)2022-07-28
大众科学(2022年5期)2022-05-18
电子产品世界(2022年4期)2022-04-21
环球时报(2022-03-29)2022-03-29
汽车实用技术(2022年4期)2022-03-07
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
软件导刊(2017年4期)2017-06-20
电子技术与软件工程(2016年23期)2017-03-06
中国新通信(2016年11期)2016-08-09
