
基于数据挖掘的数字图书馆用户行为特征研究*
——以CADAL平台为例
2022-09-05 08:29:58郭科远刘桂锋
图书情报研究 2022年3期
郭科远 刘桂锋 包 翔
(江苏大学科技信息研究所 镇江 212013)
1 引言
图书馆用户研究起源于上世纪30年代,美国芝加哥大学的图书馆学研究生院关于普通民众的阅读需要及阅读行为交流的一系列研究标志着图书馆用户行为研究的开端[1-2]。随着科学方法革命的到来,图灵奖得主James Gray 提出科学研究第四范式,即数据密集型科学发现(Data-Intensive Scientific Discovery),从而成为当前科研的主要方向。在当前大数据环境下,图书馆作为知识数据的集中地,对图书馆用户数据进行分析能够一定程度反映科研方向。大数据时代,技术促使图书馆研究进入新时代[3]。随着我国互联网领域发展步入新的阶段,5G 和产业互联网等新技术带来新机遇,互联网在发展阶段出现更多不确定性,互联网与实体经济进入全面深度融合期[4]。随着移动互联网的高速发展,数字用户规模呈现井喷式增长,记录的用户行为也变得更加丰富,分析复杂度也随之越来越高。
2 国内研究现状
2015年12月31日,教育部发布了《普通高等院校图书馆规程》,其中第三十条规定:“图书馆应积极拓展信息服务领域,提供数字信息服务,嵌入教学和科研过程,开展学科化服务,根据需求积极探索开展新服务。”[5]
近年来,利用数据挖掘技术针对图书馆用户行为的研究越来越多。在国内,相关研究起步较晚,21 世纪以来才出现利用数据挖掘技术对图书馆用户行为数据进行分析,2008年以来,相关文献数量增长速度极快,已经成为了图书馆用户研究的热点前沿之一。王慧[6]等以天津图书馆“数字图书馆知识发现系统研究项目”为例研究数字图书馆浏览行为中的用户兴趣,详细阐述了用户浏览行为数据的采集、知识行为数据的整理与构建,并对个体用户与群体用户兴趣进行分析;张洁[7]等将用户画像概念引入数字图书馆领域,构建数字图书馆各项服务的用户兴趣模型,并依照模型设计、数据准备、数据挖掘以及标签映射的步骤开展对国家农业图书馆知识服务用户的用户画像建模及管理实践;王刚[8]等关注用户在社交网络的各种行为信息,并通过分析社交网络中用户之间的社交密切程度、资源使用情况以及用户对资源访问的时间、访问频率,分析用户对资源使用的兴趣变化,设计用户行为模型,提出好友推荐方法以及资源推荐机制;尹相权[9]等利用北京师范大学图书馆研究间系统日志数据,根据用户画像的研究思路,对用户数据进行多维度行为建模,挖掘高校图书馆研究间的用户行为规律特征,探索影响用户行为的主要因素;高馨[10]等以“数字图书馆推广工程”微信公众号为例,依托微信后台数据统计功能,基于用户行为数据分析,排查微信服务存在的问题及原因,调整微信公众号相应服务运营;许鹏程[11]等通过剖析数字图书馆用户画像的内涵及特征,分析用户画像的数据来源及采集处理过程,提出数据化、标签化、关联化、可视化的数据驱动下的用户画像路线,从自然维度、兴趣维度、社交维度,构建多维度、多层级、立体化来分析用户画像模型;刘速[12]等以天津图书馆为例,从数据来源、数据采集、信息识别、模型搭建等方面探究数字图书馆知识,发现系统用户画像构建的规律,并提出可视化统计描述、多维度交叉分析、用户关系图谱等用户画像分析方法。
综上可知,目前国内学者主要立足于用户视角、关注数字图书馆中用户具体行为的分析、探究影响因素、提供个性化服务等方面。本文则从平台运营的角度开展研究,更关注于用户群体的分类、资源使用、行为习惯以及用户的流失情况。
随着图书馆服务的用户群体规模急速增长,图书馆在对用户行为研究和分析的过程中很难涉及到每个用户的行为特征。对于现代化综合性图书馆而言,无法对用户深入研究就无法分析用户群体的行为特征,也就容易忽视用户的服务需求[13]。针对图书馆数据的传统数据分析方法大多是依据单一的日志文件提供的数据或是单纯的借阅数据来分析单一的用户行为,这一点显然不能满足当前的研究需要。研究中存在问题单一化、不全面,很难反映现实用户的行为特征[14]。数据规模越来越大,传统的用户分析方法已经无法满足处理大量数据这一需要,而利用数据挖掘技术对图书馆用户行为数据进行分析已经有效解决这一问题。面对现在无法提供全面用户分析的问题,可以通过将不同维度、不同来源的数据进行结合,以此更加完整而全面地描述用户的行为特征。
通过之前各领域对图书馆用户行为数据分析的有关研究可以看出,采用数据挖掘手段结合有关模型能够更好地去探索图书馆用户行为规律和特征,因此本文将着眼于不同角度下利用数据挖掘技术探究数字图书馆在线平台用户行为特征以保障平台用户行为分析的全面性、可用性和精确性,这样才能确保图书馆满足用户的个性化服务要求。
3 数字图书馆平台用户行为特征分析方法
平台掌握的是图书资源,平台的使用者是用户,平台与用户之间的交互过程(如图1所示)是使用过程。而在这一过程中,平台能为用户提供的除了资源还有服务,而体现平台服务质量的主要因素之一是用户特征。从静态上看,用户特征是不同用户群体间的不同属性,如果从平台运营的角度去看,主要是从用户对平台具有的价值来对用户进行分类,此外,用户使用资源的类型也能体现用户的习惯和喜好,这些都可以通过分析用户的特征来提高平台的运营管理效率。从动态上看,一方面,用户群体在使用过程的不同阶段的使用行为能够很好的展现该过程所提供的服务是否满足用户需求。本文采取转化率方式加以展现用户不同阶段的平台使用情况,找出平台所需改进的区域。另一方面,用户访问平台的时间既反映了用户使用的习惯,同时也为平台调整改进的时间提供了参考依据。

图1 用户-平台交互图
当然,从不同角度分析用户群体是动态变化的,个人的用户行为也与群体行为有所差异,受限用户的行为数据的不足,因此无法全面反应用户各个群体的行为特征。但无论是从用户的使用过程,还是用户的群体和资源这几个角度,都能反映用户的行为特征,可为平台的运营效率提供决策支持。
本文采用Python 进行数据处理分析,首先对获取的数据进行预处理,然后观察处理数据。在监控平台用户使用流程的过程中,主要是聚焦于两类用户情况:首先是有价值的用户,该类用户主要表现在网站使用上,可以为网站产生一些价值,本文中主要是指常用平台获取资源的用户。二是流失的用户,主要指那些曾经访问过网站或注册过的用户,但由于对网站渐渐失去兴趣后逐渐远离网站,进而彻底脱离网站的那批用户,主要是指近期不再访问或访问次数减少的用户。通过对两者行为的观察并利用Python 进行数据分析,再结合经济学等领域多种分析模型对用户行为进行深入分析,从而为提高平台使用量提供数据基础。
从时间序列上看,从用户访问的时间方面展开分析,对获取用户访问行为数据需要对访问时间进行切片处理并对各时段独立访客数与页面访客数分析,再分天、年分析,并针对产生现象提出建议。
从用户访问阶段方面分析,针对用户访问平台时使用行为进行分阶段分析,根据数字图书馆用户访问流程特点,将用户访问的流程划分为注册、检索、借阅三个阶段,通过建立漏斗模型得到用户访问平台的不同阶段之间用户转化率的差异变化,提出相应建议。
从用户群体与平台资源上看,通过采取聚类方法对用户进行分类,获得不同的用户群体,并针对不同群体提出不同的服务建议。在该阶段一方面要注意用户分类特征的选择,另一方面也要注意聚类方法的选择,本文主要采取K-Means 聚类方法对用户分类。而对资源进行分析相对简便,通过排序,选取热门资源,分析资源类型,来推测用户习惯并提出相应建议。
最后是针对资源进行分析,通过简单的排序,选取热门资源,分析资源类型,推测用户阅读资源喜好并提出相应建议以推动资源优化。整体研究思路如图2所示。

图2 整体研究思路
4 CADAL 平台用户行为特征研究
4.1 CADAL 建设现状
大学数字图书馆国际合作计划(China Academic Digital Associative Library,CADAL)起源于2000年12月中美两国计算机科学家倡导建设百万册数字图书馆项目;2002年9月,被中国教育部列为“十五”期间“211 工程”公共服务体系建设的组成部分,定名为“高等学校中英文图书数字化国际合作计划”;2009年8月,该项目正式改名为“大学数字图书馆国际合作计划”。CADAL 项目建设的总体目标是:构建拥有多学科、多类型、多语种海量数字资源的,由国内外图书馆、学术组织、学科专业人员广泛参与建设与服务,具有高技术水平的学术数字图书馆,成为国家创新体系信息基础设施之一,形成了全世界最大的资源数字化网络,主要来源于国内外研究型大学的馆藏文献,囊括中外文图书、音视频资料以及报刊论文等重要文献,对从国外、境外组织的英文图书进行数字化加工。这是一个以数字化图书期刊为主、覆盖所有重点学科的学术文献资源体系,对高校教学科研起到了巨大的支撑作用[15]。
4.2 数据获取与预处理
本文的数据来源于CADAL 用户行为数据[16],并通过脱敏技术保障了读者隐私。本文主要针对资源借阅数据、用户访问数据,涉及到对数值型与日期型变量的处理,通过慧源数据平台下载相应数据,主要包含自2020年1月以来半年的数据,利用Python 进行数据处理,在数据导入清洗前,要检查是否导入pandas 等库。在导入数据时要注意传输数据的完整性,为保证导入顺利,对数据格式要进行检查,防止部分数据无法导入或被破坏。
首先对缺失值进行清洗,缺失值清理是处理数据问题最为常见的步骤。通过isnull()函数进行异常检测,确定缺失值的范围,统计原始数据包含的各字段的缺失值比例,依照计算所得的缺失值比例、字段重要性等方面,酌情制定清洗策略,主要采用删除法去除缺失情况较为严重的,即影响力较小的字段,使用替换法,利用平均数填补缺失值不太严重且影响分析结果的字段。此外还要对格式内容进行清洗,主要是处理各类数据在显示格式方面的不一致,本文采取的主要方法是在初期导入时将其处理成一致的某种格式(如str 字符型格式),最后对非需求数据进行清洗,删除不要的表格字段,尽量减少机器运算量,使分析过程更为高效。
利用Python 进行分析时间序列的过程中,在可视化分析和分时期统计等方面经常出现时间日期格式处理和转换问题,尤其在分期统计阶段,日期数据的处理好坏直接影响到最终统计结果的准确性。为保证读取表格数据完整性,在读取过程后所得的日期数据通常为字符型数据。为了进一步分析需要,本文对所得数据进行了进一步的处理,首先利用函数将日期数据格式化,保证该数据类型格式一致,方便进一步处理;然后对日期进行切片处理,便于分过程分析数据;对所需数据进行筛选,获取所得数据,进而进行分期统计。
4.3 用户使用过程分析
4.3.1 用户使用时间
通过周页面访问量(图3)可以看出,在周二与周六两日出现过峰值,用户的访问行为主要分布在周二、周五与周六,周三、周四相较而言,访问量较少。考虑到CADAL 服务的对象主要是大学生及研究人员,针对以上现象,应该在周二、周六加强网站管理,或加强检索访问数据的收集,防止影响用户的正常登录或使用。

图3 周页面总访问量(PV)
通过周页面独立访客数(图4)可以看出,在周二出现峰值,周五、周六独立访客数也较多,周四出现了谷值。因此,考虑选择周二加强对登录用户管理、对用户数据进行收集分类,来提供个性化服务。

图4 周独立访客数(UV)
结合图3和图4的分析,基本可以看出页面访问量与独立访客数基本呈正比增长,基本可以判定周四平台的访问量与访客数应为一周最低点,可以将不利于客户使用平台的操作放在周四进行。
由总访问量分时分析可以看出(图5),在9时到24 时多次出现峰值,访问量相对较多,用户访问习惯主要集中于正常工作时间段以及24 时前小段时间,其他时间段相对较少。
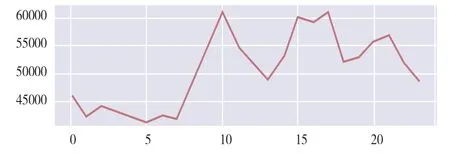
图5 每时段页面总访问量(PV)
根据分时段对页面独立访客数(图6)的分析,独立访客数与总访问量分时分析规律基本一致,在0 时到8 时间访问人数较少,在9 时到24时间出现的两次谷值也基本符合用户午餐和晚餐进餐时间。通过分时分析,可以把握大部分用户一天的访问习惯,因此,可在访客较多时段适时推送相关内容,提高平台利用效益。

图6 每时段页面独立访客数(UV)
从页面访问量与独立访客量两方面分析,在每周四该天页面访问量与该天独立访客量达到最低值,在周六该天页面访问量达到最高,在周二该天独立访客量达到最高。从每天来看(图7),在每天凌晨5 时到6 时该时段页面访问量与该时段独立访客量达到最低值,在10 时到24 时出现三次峰值。在该环节分析中,不难看出在每周四凌晨5 到6 时该时段页面访问量与独立访客量最低,所以在平台维护更新时可以考虑选择这一时段,来减小对用户使用的影响。
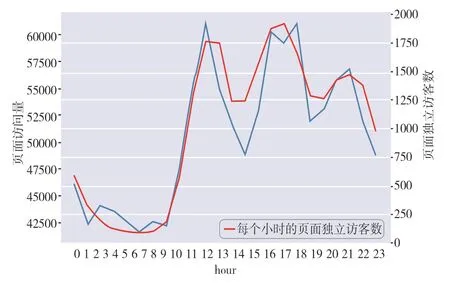
图7 每时段PV 与UV 的变化趋势
4.3.2 用户转化率
通过对新用户增量分析(图8),不难看出自2011 平台建设以来至2017年,新用户注册数量较小。自2018年至2020年该平台用户注册量实现跳跃性增长,除了计算机普及应用等硬件原因,更多的是由于平台资源、服务、宣传等多种因素,尤其是2020年仅上半年记录数据即达到6 860 人的注册量,结合当前疫情常态,越来越多的人选择在线阅读方式,线上阅读平台发展十分迅速。平台应当抓住机遇,扩大用户范围,加大平台推广。

图8 新增用户数
漏斗分析是分析用户流程的数据分析模型,该模型可以较为准确地反映用户的行为状态,同时可以更直观展现从用户使用初期到末期各阶段的用户转化率情况。通过对比漏斗模型各环节间相关数据变化,可以很直观地展示问题出现的阶段,就能够针对问题所在阶段进行相应优化。
通过对平台运营数据观察,可以利用注册用户逐步变为活跃用户的转化过程来构建量化模型。其关键要素包括:环节与相邻环节的转化率。根据用户使用流程,选取关键节点并划分为3 个步骤,分别是:注册、检索、借阅,该模型(图9)展示了用户使用的完整过程,普通用户转变为活跃用户的过程,同时也在一定程度上反映了用户流失情况。当然,网站中用户的新老交替情况是无法避免的,在平台运营中必然会存在流失用户,但平台可以通过流失用户所占比例和变化趋势来说明其对用户的保留能力和未来的发展趋势。

图9 年新增用户数
从表1可以观察到,从整体过程看,用户流失较多,总体转化率仅达39.4%。然而用户注册到检索过程中,用户转化率达到78.55%,所在该平台使用中用户检索行为较为普遍,相比而言,在检索到借阅过程中,用户流失较多,流失率高达49.84%。因此在平台运行过程中除了扩大用户量,更主要的是首先要把重点放在提高检索用户的借阅兴趣上,尽可能鼓励检索用户去借阅书籍,为用户做好推荐等服务,帮助用户选取所需要的书籍,并且扩充书库,采购用户所需书籍,提高服务质量。其次,平台需要做好用户流失预警,不仅要把可能有流失倾向的用户分析出来,而且需要采取相应的召回、引导策略。

表1 用户转化率统计
4.4 用户群体分类分析
利用CADAL 用户行为数据对用户群体进行分类,进而可以针对流失用户进行挽留,也可以根据不同用户群体采取不同策略。
4.4.1 RFM 模型分析
RFM 模型是一种被广泛使用的客户关系管理(CRM)的分析模型。利用RFM 模型可以很好地衡量客户价值,同时也可以评估客户创利能力。相比其他分类模型,RFM 模型能够更好地、动态地凸显各类用户变化,也能够较为客观地判断出用户的长期价值,为进一步提供个性化沟通与服务并制定更多的营销决策提供支持[17]。
在模型中,R(Recency)通常表示用户最近一次购买的时间的远近,F(Frequency)表示客户在最近一段时间内购买的次数,RFM 模型主要利用用户行为的差异来区分客户[17]。由于本文没有获得M 数据,故主要利用R 与F 进行用户分类(图10)。主要原理是近期使用平台的用户相比于近期没有使用的用户更有可能再次使用平台,经常使用平台的用户相对于较少使用平台的用户更有可能再次使用平台。
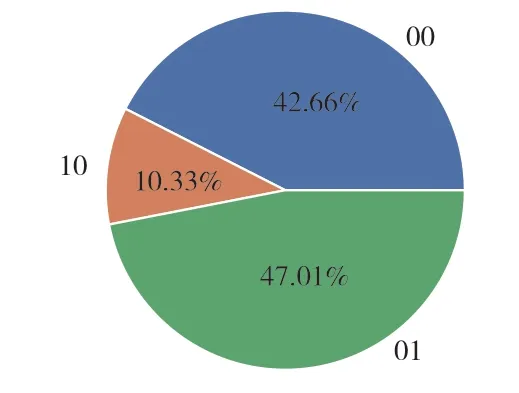
图10 用户价值分类
重要价值客户(11):这类客户主要表现在最近消费时间较近且消费频次较高,由于该类用户数量不多,在使用K-Means 聚类时,该类用户分类不明显。
重要保持客户(01):这类客户主要表现在虽然最近消费时间较远,但消费频次较高,对于此类用户,用户对平台的忠诚度并不高,需要主动联系该类用户,征求建议,改进平台服务。
重要发展客户(10):这类客户主要表现在最近消费时间较近,但频次不高,该类用户多属于初始用户,有对平台的使用要求,该类用户发展潜力较大,应作为重点发展对象。
重要挽留客户(00):这类客户主要表现在最近消费时间较远且消费频次较低,有可能是已经要流失的用户或是准备放弃使用平台的用户,应当采取挽留措施。
4.4.2 基于K-Means 算法的分析
利用聚类算法对某一特征用户群体的划分和归组,不仅方便预测用户之后的态度行为,而且对用户分层管理很有帮助,通过对不同类型客户提供不同服务,提高平台运行效率。利用聚类的方法处理用户信息,能够较快对用户进行分类,帮助平台了解用户,挖掘潜在用户,帮助平台实现差异化营销[18]。
K-Means 算法是一种较为常用的聚类算法,聚类是根据处理数据对象是否相似的原则,把相似度较高的数据对象分配到相同的类簇,将数据对象中相异度较高的对象划分到不同的类簇。相比于分类算法,二者之间最大的区别在于聚类的过程是一个无监督的过程,即在处理待处理数据对象前,是没有任何有关处理的先验知识[19]。而分类过程作为有监督过程,是存在使用先验知识作为处理过程的训练数据集。K-Means 聚类作为一种较为通用的算法,基本可以运用到各种类型的分组分类问题。K-Means 算法是针对已有样本集,通过计算样本间的距离大小划分出K 个簇,实现簇内点尽可能密集(间距小),而簇间距离尽可能大。本文主要是针对已有的用户群体,划分用户类型。用数据表达式表示,假设将当前给定的数据集划分的簇集合为(C1,C2,...Ck),则我们的目标是最小化平方误差E:

其中μi是簇Ci的均值向量,有时也称为质心,表达式为:

K-Means 聚类算法具体操作步骤如下:
(1)首先要选择集群的数量K,主要是通过观察散点分布等方法选取合适的K 值。
(2)利用Python 中已有函数对K 个点进行随机选择,作为初始质心(质心选择不一定非要是已知点)。
(3)通过对点间欧式距离的计算,把每个数据点逐一分配到构成K 簇的最近的质心。
(4)计算并重新放置每个集群的新质心。注意数据点与它们的集群中心之间的平均距离。
(5)重新将计算后的数据点根据距离远近分到最近的质心所在簇。在该过程中,每发生一次重置,就再次循环到步骤4,如果未发生重置则结束该流程并记录下所获取到的K 个簇。
在使用K-Means 聚类过程中,发现分四类特征并不明显(表2),所以采取分三类的方法进行用户分类(表3)。通过观察数据,对高于平均值置1,低于平均值置0,得到重要挽留客户(00)、重要保持客户(01)、重要发展客户(10)三类用户,所占比例分别为42.66%、47.01%、10.33%。利用聚类算法获得了用户分类,方便运营方对不同用户采取不同策略,提高用户体验度。
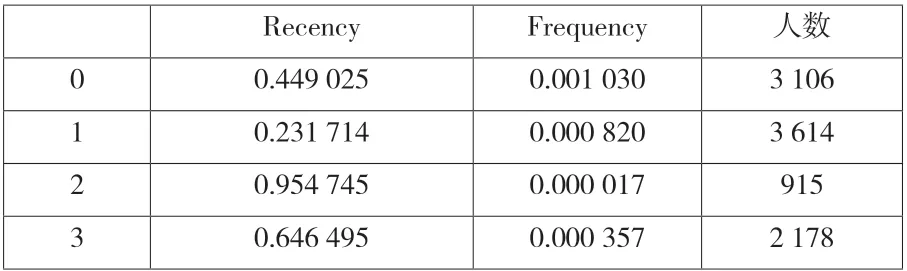
表2 K-Means 分四类结果

表3 K-Means 分三类结果
根据以上方法模型可以实现对用户的分类,不仅可以提取流失客户加以挽留,还可以为有潜力客户提供推送服务,进一步丰富常用用户群体,扩大平台影响。
4.5 用户借阅资源分析
在互联网产业竞争过程中,平台提供的资源仍然是最重要的因素,书籍作为图书馆提供的主要资源,如果这一基础丧失,其他因素的作用都将不存在。对书籍资源进行分析,一方面可以为用户提供推荐服务,另一方面可以通过分析热门资源,为图书馆馆藏提供方向。由于使用Python读取列表的顺序时是自0 开始,由此可以根据推算找出阅读量在前十的书籍(见表4)。
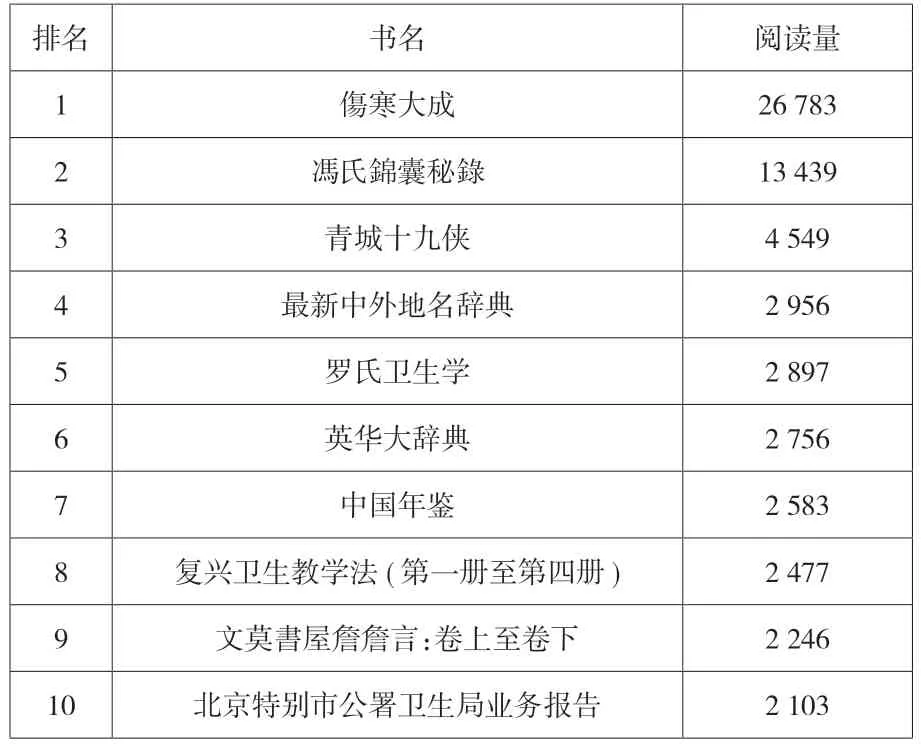
表4 阅读量前十的作品
由于阅读量能够反映用户兴趣,通过收集前十阅读量的书籍可以把握较多用户的兴趣,把握图书资源扩充的方向。通过观察不难发现阅读量较多的书籍涉及范围较广,但有多篇文献涉及医学卫生领域,结合当前疫情的情况来看,也可以看出该模型所得数据一定程度反映了用户关注社会热点问题。平台通过阅读量统计来了解相关信息并结合社会热点把握读者兴趣,进一步加强平台服务,提高用户满意度。
表5是收藏量前十的作品,由表5可以发现,收藏量较多的书籍多涉及人文社科,一方面由于自然科学书籍具有较强的专业性和实效性,另一方面在用户行为习惯方面反映出阅读自然科学书籍的用户可能收藏行为较少。

表5 收藏量前十的作品
对平台资源阅读量与收藏量的分析,平台运营者可以把握用户习惯与兴趣,针对不同用户在不同环节中为了得到某种服务及功能而提出的需求,可以改进平台服务的不足,从而满足用户需求,进一步扩大平台资源覆盖范围,提高服务质量。
5 结论与建议
随着大数据时代的到来,电子书的普及让在线平台已经能够实现图书馆的许多职能,保证了用户的行为数据更容易被收集。利用大数据具有的及时性、精准性、高客观性等特点,本文通过多角度对用户行为及资源进行详细分析,进而为平台提供合理建议,主要分析了网站运营、用户行为、图书借阅等方面。在用户分类阶段采取无监督的聚类方法,基本可以监控用户在各个环节间的转化流失情况,可以让平台运营者聚焦用户使用的全部流程中最为有效转化路径,与此同时运营者可以由此发现可优化的短板,进一步提升用户体验,从而减少用户流失,通过观察不同环节间的转化情况,迅速找到流失环节,并针对有关环节,持续分析,从而找到可优化点,由此提升用户留存率。在分类阶段采取K-Means 聚类分析,通过无监督的聚类方法减小了人为失误的可能性,保证分类的准确性。针对资源的分析可以了解用户习惯,为平台扩充资源提供方向。
针对CADAL 平台用户群体以及用户行为特征,根据平台的运营现状,提出以下建议:
(1)确定平台维护更新时间段,减小对用户使用的影响。针对用户访问的时间分布情况,可以选取周四凌晨5 到6 时页面访问量与独立访客量最低时段作为平台维护更新时间。
(2)利用网络优势扩大用户群体。通过对新用户增加趋势的分析,2020 上半年新用户增加量高达6 860 人,用户阅读方式逐步转移到线上,平台应当抓住机遇,扩大用户范围,加大平台推广。
(3)针对使用阶段的用户流失率,从而调整平台。通过漏斗模型了解每个阶段的转化率,关注用户流失较多的阶段,做好用户流失预警,同时用户流失率也在一定程度上反映用户使用过程中的满意度。比如在检索到借阅过程中用户流失率高达49.84%,用户流失较多,除了要关注流失用户群体外,平台应该对借阅系统进行优化,提高用户满意度。
(4)通过用户价值分类,确立服务等级。可以针对用户流失群体,潜力客户群体及忠诚客户群体分别采取不同服务策略。
(5)根据资源阅读量与收藏量分析,实时优化数字图书馆馆藏资源。根据资源阅读量与收藏量分析,在疫情时期,医学图书较为热门,人文类书籍收藏较多,既反映人文类书籍相对自然科学类书籍阅读群体较多,而且反映人文学者收藏行为较为普遍。应当根据习惯加购人文类书籍,对收藏功能加以优化。
(6)加大数字资源开发力度,开发平台的新功能。不仅限于纸本资源数字化,可以进一步利用虚拟现实等计算机前沿技术,提高用户沉浸式体验。
猜你喜欢
吉林广播电视大学学报(2021年4期)2022-01-14 02:35:48
作文成功之路·小学版(2020年5期)2020-06-11 12:48:26
小天使·一年级语数英综合(2018年11期)2018-11-23 09:47:26
小太阳画报(2018年1期)2018-05-14 17:19:25
资源再生(2017年3期)2017-06-01 12:20:59
商用汽车(2016年11期)2016-12-19 01:20:16
少年博览·小学低年级(2016年10期)2016-11-24 06:48:23
商用汽车(2016年6期)2016-06-29 09:18:54
商用汽车(2016年4期)2016-05-09 01:23:12
创业家(2015年5期)2015-02-27 07:53:25
