
红外光谱数据融合对栽培滇重楼产地鉴别*
2022-09-02 03:56丁于刚张庆芝
云南中医学院学报 2022年1期
丁于刚,张庆芝
(云南中医药大学中药学院,云南 昆明 650500)
作为百合科多年生草本植物,滇重楼(Paris polyphylla var.yunnanensis)的根茎被广泛应用于中国、印度、不丹、尼泊尔等国家[1]。重楼在中国有超过两千年的药用历史,最早被名为“蚤休”记录于《神农本草经》中[2]并记其“味苦微寒,主惊痫摇头弄舌,热气在腹中,癫疾,痈疮阴蚀,下三虫,去蛇毒”,现代药理研究表明重楼具有抗肿瘤、凝血、抗氧化、抗炎镇痛、抗微生物活性等[1]药理活性。中国是重楼最大的生产国和消费国,在过去的40年间,重楼药材的市场价从2.7元/kg增涨到了600~750元/kg[3]。随着市场需求的增大,野生重楼药材已经不能满足市场的需要。多样的环境因素使得不同产地的栽培滇重楼化学成分也各有不同,且影响滇重楼的分布的主导因子与其地理环境息息相关[4]。因此,药材的产地溯源对其质量控制及合理开发利用具有重要意义。滇重楼化学成分的差异主要体现在次生代谢产物甾体皂苷类化合物上,有研究表明不同产地、不同年份的滇重楼其化学成分具有较大的差异[5-6]。裴艺菲等采用多光谱技术对云南不同产地滇重楼进行了分析,结果表明单一光谱建立的模型正确率较高[7]。目前为止,不同类型的检测分析技术被成功应用于鉴别滇重楼的来源,例如高效液相色谱法(HPLC,High performance liquid chromatography)[8-9]、超高效液相质谱联用(UHPLCMS/MS,Ultra-performance liquid chromatographytandem mass spectrometry)等[6]。然而,这些技术需要对样品进行复杂的预处理、有害试剂的使用、对实验员的高要求等,基于湿法的液相色谱法的方法不适于大量样本的快简分析。振动光谱结合化学计量学已然成为一种绿色、快捷的方法,这使得利用红外光谱结合化学计量学对不同产地的栽培滇重楼的快速鉴别成为了可能。中级数据融合能减少大量的冗余和无关变量,在模式识别分析中更具有可靠性。通过采集云南和四川共8个产地的滇重楼根茎的近红外和中红外光谱数据,光谱数据表征不同产地植物样品的化学信息差异。结合多元变量提取方法,建立一个稳定可靠的产地模式识别方法,以促进云南不同产地栽培滇重楼的合理开发利用。
1 材料与方法
1.1 实验材料 本研究实验样品为栽培滇重楼的干燥根茎样品,原植物采自我国西南的云南和四川省,包括保山、楚雄、大理、红河、丽江、文山、玉溪和成都。所有采集原植物均经云南中医药大学张庆芝教授鉴定为滇重楼(P.polyphylla var.yunnanensis)。所有样品信息如表1所示,样品采集后经清洗干净后切片,在50℃下烘干。后经打粉机粉碎后过100目筛,所有样品均置于干燥皿中待下一步分析。
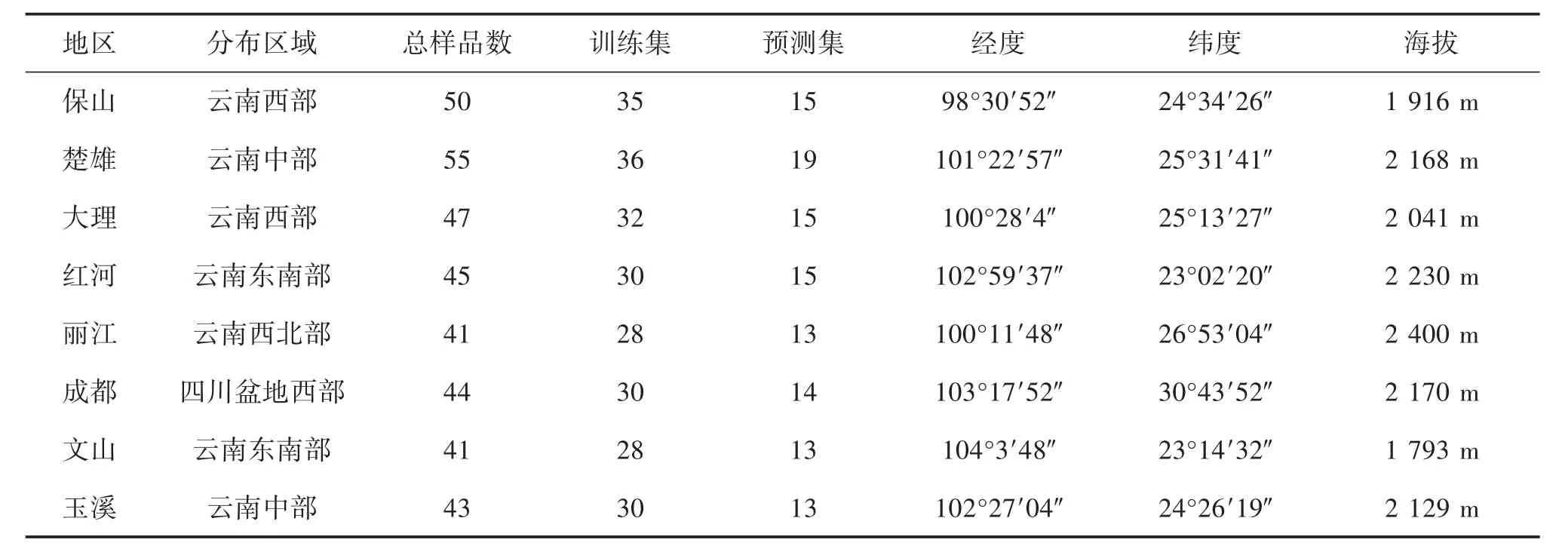
表1 重楼样品信息表
1.2 红外光谱采集
1.2.1 衰减全反射傅里叶变换中红外光谱 衰减全反射傅里叶变换中红外光谱采集自配备氘化三甘氨酸硫酸盐(DTGS)检测器和ZnSe衰减全反射元件的中红外光谱仪。光谱采集范围为4 000~650 cm-1,分辨率为4 cm-1,每个样品累积扫描16次。经过3次重复扫描后,得到了所有样品的光谱数据。光谱采集室恒定的温度和湿度由温湿度控制仪进行调控,所有采集得到的光谱数据由SIMCA-P+14.1进行分析。
1.2.2 傅里叶变换近红外光谱 重楼样品的近红外光谱由AntarisⅡ型光谱仪检测,仪器结合漫反射附件。光谱采集波数范围为10 000~4000 cm-1,分辨率为4 cm-1。样品采集室的温度和湿度维持恒定的值,温度(25℃,30%RH)。每次采集样品光谱之前,空气背景(CO2和H2O)会被校正以减小误差。每个样品平行检测3次,3次后的平均光谱将用于进行下一步分析。
1.2.3 红外光谱数据预处理 从光谱检测仪获得的原始数据往往会包含一些干扰信息,它们来自环境因素、检测器和其它因素等[10-11]。在本研究中,采用标准正态变量变换(SNV,standard normal variate transformation)[12]以减少由样品物理状态带来的散射干扰,同时可以将变量平衡在0~1之间。
1.3 模式识别技术 在最初,偏最小二乘算法(PLS,partial least squares algorithm)被应用于回归问题的处理。在偏最小二乘回归中,变量矩阵Y(Y block)与训练集X(X block)按照常规方法配对[13]。一般来说,偏最小二乘判别分析(PLS-DA)应用于特定情况如Y是类别数据。偏最小二乘判别模型的建立主要分为4步:数据预处理、降维、模型验证和决策。本研究运用了7折交叉外部验证,R2(Coefficient of determination of model fitting)、Q2(Prediction)、RMSEE(Root mean squared error of estimation)、RMSEP (Root mean squared error of prediction)、RMSECV (Root mean squared error of calibration validation)等参数被用来评价模型的优劣。一般来说,Q2大于0.5表明模型具有较好的预测能力,而模型的稳定性则与R2有关。所有数据处理和建模均在SIMCA-P+14.1软件完成。
1.4 特征变量提取 变量投影重要性(VIP,Variable importance for the projection)是衡量PLS-DA模型中单个变量对整个模型的影响的参数。VIP值为数值的均方根,一般来说,它代表了相关性[14]。选取VIP值大于1的变量建立模型能减少其他不重要变量带来的干扰,从而提高分类效果。SPA的优势是能够消除大量的冗余信息,适合于光谱特征波长的筛选,并已被证实结合分类算法(如SPA-PLS-DA)具有较好的效果[15-16]。竞争性自适应再加权算法(CARS,Competitive adaptive reweighted sampling),有别于其他的特征变量筛选方法,主要通过自适应再加权采样技术选择出偏最小二乘回归系数绝对值较大的波长点,根据交叉验证选出RMSECV值最小的子集[17]。序列正交协方差特征变量选择(SO-CovSel,sequential and orthogonalized covariance selection),通过对每个预测变量与所有变量之间的协方差进行评估,筛选出协方差最高的变量作为特征变量[18]。基于以上原理,所有的预测因子和相应的响应值将会被统计,并将重复以上过程,直至选择出适当的变量数。
光谱数据具有复杂、多维的特点,本研究采用多种不同的特征变量提取方法旨在从不同的角度简化和提高模型的可解释性。
1.5 多源数据融合策略 当处理来自多传感器的数据时,多源数据融合策略(MSDF,Multi-sensor data fusion)是比较适用的方法。数据融合策略通过结合不同模块的数据,进而分析可以得到相比单一来源数据更准确和有效的决策[19]。总的来说,根据融合策略的不同,数据融合方法可分为数据级融合(Low level)、特征级融合(Mid-level)和决策级融合(Decision-level)。在本文中采用了2种数据融合策略进行对比,以提高实验结果的准确性。
2 结果与分析
2.1 光谱的特征解释 根茎样品的傅里叶变换中红外光谱图能够反映化学信息,体现不同产地滇重楼的差异。在本研究中,来自8个产地的滇重楼中红外和近红外光谱数据均做了平均处理。如图1所示,经过二阶导数的光谱相比于原始光谱更能反映出样品的化学信息[20]。在二阶导数的光谱中,共有20个显著的吸收峰(2 927,2 852,1 745,1 459,1 415,1 372,1 336,1 240,1 204,1 154,1 106,1 079,1 049,1 020,995,925,896,863,767,711 cm-1)[21]。其中,3 334 cm-1的峰为羟基的伸缩振动吸收,2 927、2 852、1 459、1 415 和 1 312 cm-1的吸收主要为来自亚甲基碳氢键的弯曲和伸缩振动。在1 745 cm-1的较大吸收峰为碳氧双键的伸缩振动,推测与甾体皂苷、黄酮、挥发油及多糖类物质相关[22]。1 300~400 cm-1范围的峰较为密集且复杂,为样品的指纹图谱区。
图1 保山、楚雄、大理、红河、丽江、成都、玉溪、文山的ATR-FTMIR和FT-NIR
相较于中红外光谱,来自8个地区的平均近红外光谱吸收峰较少。5 500 cm~4 200-1光谱区域为其主要吸收波段,该波段的吸收可能与碳氢键的变形和氧氢、氮氢、碳氢组合模式的第二泛音有关[23]。位于7 200~5 500 cm-1的低频区的2个吸收峰归属于碳氢、氧氢和氮氢键伸缩振动的泛音,而碳氢、氧氢和氮氢键伸缩振动的第二泛音则位于9 000~7 500 cm-1的弱吸收峰处[24]。整体上看,不同产地的中红外和近红外光谱吸收峰位置相同,但是强度略有差异,仅凭平均光谱图的差异难以实现不同产地滇重楼的鉴别。
2.2 多源数据融合策略结合PLS-DA判别滇重楼产地
2.2.1 基于低级数据融合的PLS-DA 在本次实验中,通过SIMCA-P+14.1对采集自样品的中红外和近红外光谱数据进行转换,共得到3 346个变量(FTNIR:1 557个变量,ATR-FTMIR:1 789个变量)。在进行建模之前,先对所有来自8个大类的样品进行KS训练,将样品分为2/3的训练集和1/3的预测集。在对原始数据进行SNV预处理之后,中红外和近红外的数据被串联建立PLS-DA模型。PLS-DA模型的最佳潜在变量数则是根据模型的交叉验证均方根误差和Q2决定的,如图2所示所有模型的最佳潜在变量数均已确定。模型参数如表2所示,训练集和预测集的正确率均达到了100%。
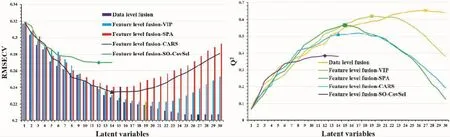
图2 PLS-DA模型的最佳潜在变量数
表2 基于数据融合的多种PLS-DA模型的参数值
2.2.2 中级数据融合结合PLS-DA 区别于低级数据融合较为庞大的计算量,特征级融合摒除了大量的冗余变量从而使模型较为简单[25]。基于VIP的特征变量选择方法分别从中红外和近红外数据中筛选出VIP值大于1的变量,这505和500个变量将被视为重要变量进行下一步分析[26-27]。根据VIP-PLS-DA模型可知,最佳潜在变量数为19,训练集正确率达到100%,训练集正确率达到99.60%,只有预测集中有2个样品被错误分类。
基于SPA选择的特征变量来自光谱的各个波段。来自不同传感器的特征变量组成一个新的366×132的数据集,根据模型可知,其最佳LVs为15,模型预测集正确率为94.02%。根据竞争性自适应再加权算法的原理可知,在交叉验证均方根误差最低时筛选的变量为最佳变量数。随着模型运行次数的增加,交叉验证均方根误差呈高-低-高的变化趋势,无关冗余变量被剔除,均方根误差减小,在最佳变量数时达到最低值。但随着采样的继续进行,RMSECV增加是因为消除了必要的变量。最终共有32和76个变量参与模型的建立。采用SO-CovSel特征变量筛选方法筛选的变量数较少,分别为(10×366)和(4×366)变量并进行下一步建模分析。结果表明,基于低级数据融合的效果最佳,训练集和预测集正率均达到了100%。而基于SO-CovSel方法的模型效果最差,预测集正确率仅有84.62%。
3 讨论
从8个产地的滇重楼平均中红外光谱图可以得出,来自四川成都的样品在3 000~2 800 cm-1与其它产地具有较为明显的差异,这可能是四川盆地相对独特的气候条件所致。Yang等通过超高效液相色谱-紫外串联质谱法(UHPLC-UV-MS,Ultra-performance liquid chromatography-ultraviolet spectroscopy-tan-dem mass spectrometry)检测了不同产地滇重楼的皂苷类成分含量,结果显示云南省南部地区总皂苷的平均值显著高于中部地区[6]。表明不同产地的滇重楼,其有效成分的差异较为明显。
根据模型正确率和参数表明(表2),基于低级数据融合建立的偏最小二乘判别分析模型效果最优,低级数据融合通过串联不同传感器的信息能最大限度的保留样品的化学信息。在中级数据融合中,最终变量数较多的模型其参数较优,正确率较高。这可能是因为在去除大量冗余信息的同时,许多对建立模型有效的变量也被去除。令人意外的是,基于SPA变量选择方法的模型效果达到了94.02%,因其只在较少的变量上进行分析,表明该方法具有较好的泛化能力。
4 结论
本研究通过红外光谱技术结合数据融合方法,采用PLS-DA模型对来自四川和云南8个产区的栽培滇重楼进行了鉴别分析。在特征级数据融合中采用了多种特征变量提取方法,结果表明基于VIP特征变量提取方法模型结果较优,其正确率达到99.60%,预测集中只有2个样品被错误分类。综合两种数据融合类型,初级数据融合的模型效果最优,分类正确率达到了100%。综合模型可知不同传感器来源的数据具有协同性,该方法能够成功应用于不同产地滇重楼的鉴别。
猜你喜欢
医学食疗与健康(2022年3期)2022-04-23
今日农业(2021年4期)2021-06-09
中华养生保健(2020年7期)2020-11-16
海峡姐妹(2020年2期)2020-03-03
红楼梦学刊(2020年2期)2020-02-06
诗潮(2019年10期)2019-11-19
中国外汇(2019年22期)2019-05-21
当代陕西(2019年6期)2019-04-17
意林·全彩Color(2018年9期)2018-10-12
当代县域经济(2017年3期)2017-03-06
