
人工智能技术在供水管网漏水探测中的应用
2022-09-02 03:02:42汤正举陈博姜遍地
城市勘测 2022年4期
汤正举,陈博,姜遍地
(河南力科管线探测技术有限公司 ,河南 郑州 450051)
1 引 言
随着计算机技术的发展,特别是计算机运算速度的不断突破,人工智能逐步进入应用阶段,并且迅速融入社会越来越多的领域。通过识别面部特征的人脸识别技术、实现了一种更为便捷、高效的身份验证模式;基于声纹识别的人机对话,可以解放双手进行语音导航,大大提高了驾驶的安全性。麦肯锡公司分析了全球经济800多个职业中的 2 000多个工作活动。在一篇名为《中国人工智能的未来之路》的报告中指出:从技术层面来看,现在50%的工作活动完全可以通过现有的人工智能技术实现自动化。同时根据目前发展趋势也不难看出,人工智能技术正在被更为广泛的行业所接受。
人工智能最重要的进步在于,通过智能算法训练的机器,可以处理一直以来必须依赖人工完成的各种复杂工作。漏水探测就是这样一项极度依赖人工的复杂工作,从管网流量异常调查,管网压力梯度分析,到阀栓听音检测,路面拾音检测,无不依赖检测人员长期积累的工作经验。
漏水探测工作中经常会遇到干扰噪声的影响,有经验的检测人员可以区分两者,甚至可以分辨出夹杂着干扰噪声的管道噪声,但对于机器来说比较困难。以笔者所在的郑州自来水公司就遇到了这样的问题。和全国很多供水企业一样,郑州自来水公司也在大力发展智慧水务,其中一个项目是管网渗漏预警系统,它由布设在管道上噪声记录仪(振动传感器)和渗漏预警平台组成,噪声记录仪监听管道上的噪声,当噪声超过预设阈值时,噪声记录仪将会报警并将噪声信息上传至预警平台,从而第一时间发现管道漏水异常。为了减少外界噪声干扰,传感器监听时段设置为凌晨两点至三点,但即使这样,报警信息中依然包含大量汽车噪声,风声等干扰噪声引起的误报,特别是遇到降水,几乎所有传感器都会误报。处理报警需要对报警监测点进行人工听测或现场复检,传感器数量多的话势必会带来较大的人工投入。笔者赞同厂商的“宁杀错不放过”的监测报警原则,必须将管网安全运行放在首位,但如果有一种精确的分辨干扰噪声的机制,或将有效减少复检工作的人力投入。
本文通过实验介绍通过机器学习算法训练人工智能模型,使其能够正确分类管道噪声和干扰噪声。有别于传统程序,我们不向机器提供任何分类规则,仅提供音频数据和其分类标签,分类规则由机器通过训练习得。实验之初,我们需要精确定义管道噪声和干扰噪声:
管道噪声:指因压力管道内部介质流动、摩擦、扰动和冲击发生的噪声。包括管件过水噪声和漏水噪声。
干扰噪声:除了管道噪声外的其他噪声。包括交通噪声、天气噪声,电气噪声等
附加说明:①既包含管道噪声又包含干扰噪声的样本归类为管道噪声;②水泵噪声归类为干扰噪声。
2 实验数据与实验工具
实验数据为管网渗漏预警系统日常采集的音频数据。
2.1 数据采集与准备
数据采集设备为压电陶瓷振动传感器,这是一种漏水声学探测中常用的传感器,性能稳定,频响范围宽,测量精度高,广泛应用于听漏仪,相关仪等声学检测设备。传感器采用磁吸式安装,垂直吸附于被测管道管体上方,监听时如果管道振动超过预设阈值,则记录该振动信号。
(1)数据采集设备
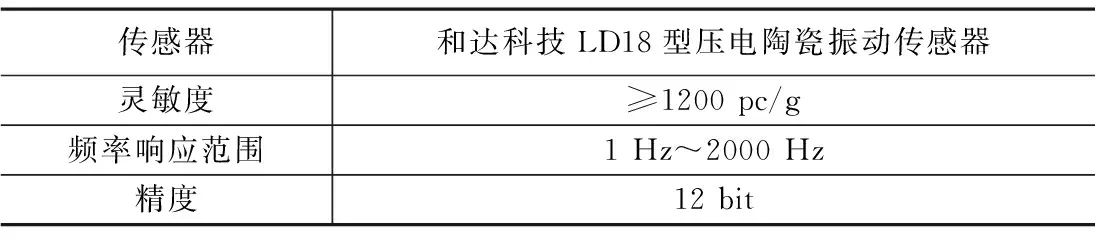
表1 数据采集设备
(2)原始数据格式
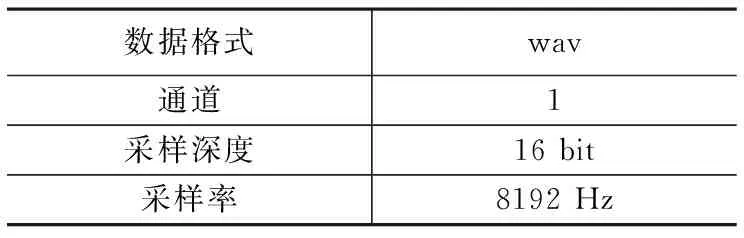
表2 原始数据格式
根据奈奎斯特采样定理,8 192 Hz的采样率可以完整保留 4 096 Hz以下频率的原始信号的采样信息,采集设备与数据格式满足实验要求。
(3)样本(数据)分类
本次实验共采集音频样本354个,采用人工听测分类,将全部样本分为8组,每组约44个,参与分类的漏水检测人员24人。每人随机对一组样本进行听测分类。这样每个样本分别得到三个独立的分类评判,取分类评判中多数票作为该样本最终分类结果。
分类结果:正样本(管道噪声)165个,负样本(干扰噪声)189个,正负样本占比分别为46.6%和53.4%,样本分布均衡。
(4)样本(数据)特征提取
原始音频样本记录了噪声的全部采样信息,可以把它表示为一个长度为 40 960的一维数组。特征提取需要尽量压缩这个数组的长度,并且最大可能的保留原始噪声数据的信息。我们选取了时域和频域上共计17个特征。
由于样本集比较小,实验不需要进行主成分分析和特征降维的处理。
最后将样本特征集整合为一个354行18列的二维数组(如图1所示)作为机器学习的数据集,前17列为样本的特征值,最后一列为样本的分类标签,至此数据准备工作基本完成。
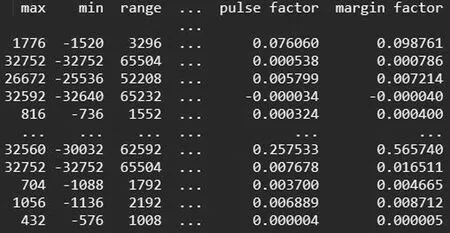
图1 样本特征数据集
2.2 实验软件开发环境

表3 开发环境
2.3 实验设计
实验分为数据集划分,特征预处理,模型优化,模型训练,分类测试五部分组成。
(1)数据集划分:
实验需要保留一部分数据集对人工智能模型的性能进行最终测试,将整个数据集划分为训练集和测试集两部分,本次实验保留数据集中的25%(89个)作为测试集,将剩余75%(265个)作为训练集。
(2)特征预处理
由于我们提取的17项特征在数值上差异很大,比如一个样本时域上的“极差”特征为65360,而“裕度因子”特征仅为0.00214101,两者在数值上相差七个数量级,由此数据直接构建的特征模型就像一张被拉长了的照片,在“裕度因子”维度上的特征也会变得不明显。
为杜绝这种情况,本实验采用标准化对数据进行无量纲化处理,将数据缩放到均值为0,标准差为1的范围内,平衡各个维度上的特征对模型的影响,如图2所示。
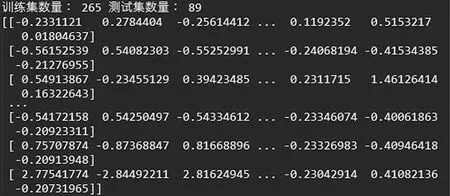
图2 数据集预处理
值得注意的是,标准化必须放在划分数据集之后进行,将训练集与测试集分别标准化处理,否则处理后的训练集中会包含测试集的信息,影响实验效果。
(3)模型优化
决定模型的优劣有两个要素——数据和算法,数据集的质量决定了模型的上限,在同样数据集的基础上,算法决定模型在此上限之内的表现,这里的模型优化指的是后者。每一种模型算法都保留了若干超参数,调整这些超参数可以使训练出的模型更适合实际需求。这里我们使用网格搜索和交叉验证的方式对模型进行调整优化。
①网格搜索
以KNN算法为例,该算法在本实验中需要设置“n_neighbors”“weights”“P”三个超参数,“n_neighbors”表示计算离目标特征点最近的已知特征点的个数,“weights”表示是否考虑距离权重,“P”表示特征点间的距离度量方式。如何调整三个超参数的组合使模型达到最佳性能呢?网格搜索提供了一个“笨”办法,循环遍历所有超参数组合,从而找到最优的模型。
②交叉验证
网格搜索的每一种超参数组合都需要测试其模型性能,但如果使用测试集来进行测试,会泄露测试集信息,影响最终模型性能的测试,实验结果不真实,为了验证设置不同超参数的模型的优劣,我们从训练集中再次分出一部分样本作为评估网格搜索的验证集。为使数据集得到最大利用率,采用交叉验证,如图3所示。

图3 交叉验证
将训练集平均分成n组,每次以其中一组作为验证集,其余部分作为训练集,进行一次训练和验证,得到一个模型的分类准确率,经过n次训练和验证,得到n个模型的准确率,取准确率的平均值作为该超参数下模型的准确率,测试集不参与此过程。这种交叉验证称为n折交叉验证,折数越多需要的运算量越大,本实验采用5折交叉验证。
2.4 模型训练与分类测试
分辨管道噪声与干扰噪声是典型的二分类问题,针对该问题本次实验选取支持向量机、k近邻、随机森林三种可用于分类的机器学习算法。算法原理仅作简要说明。
(1)支持向量机(support vector machines,SVM)
支持向量机是一种适用于二分类问题的模型。它的基本模型是定义在特征空间内的间隔最大的线性分类模型,核函数的引入使它同样可以解决非线性分类问题。
支持向量机的学习策略基于间隔最大化,可以形式化为求解一个目标函数为二次型函数,约束函数为仿射函数的凸优化问题,亦等价于合页损失函数经过正则化后的求解最小化问题,支持向量机的学习算法是求解凸二次规划的最优化算法。实验通过调节“C”和“kernel”两个超参数来达到分类模型的最佳性能。
“C”:浮点型参数,设置对错误分类的惩罚系数,默认值为1.0,详情如表4所示。
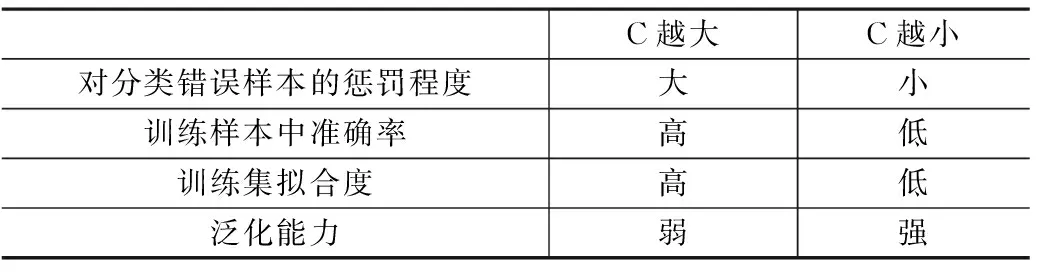
表4 SVM算法超参数“C”
“kernel”:核函数,默认是rbf,详情如表5所示。

表5 SVM算法“kernel”的可选参数
支持向量机模型分类评估数据如图4所示:

图4 支持向量机模型分类评估报告
(2)k近邻(k-nearest neighbor,kNN)
这是一种可用于分类问题和回归问题的基本方法,它的分类原理是:给定测试样本,基于给定的距离度量找到训练集中与其最接近的k个样本点,然后基于这k个最近邻的分类信息来进行预测。可使用普通“投票”,即选择这k个样本中出现最多的类别作为预测结果;还可基于距离远近进行“加权投票”,距离越近的样本权重越大。
k近邻算法属于是懒惰学习(lazy learning),不具有显式的学习过程,此类学习过程在训练阶段仅仅保存了样本信息,无训练时间开销,待收到测试样本后再进行分类计算。实验中通过调节算法中以下三个超参数对模型进行了优化。
"n_neighbors"是指KNN中的“K”,K值增大能够减小噪声的影响,但会使分类边界变得模糊;K值减小起反作用。
“weight”参数有两个可选参数的值,决定了如何分配权重。‘uniform’:不管远近权重都一样,默认为该值;‘distance’:权重和距离成反比,距离预测目标越近具有越高的权重。
“p”参数指定距离度量方法,当模型选用明可夫斯基距离时,p=1为曼哈顿距离,p=2为欧式距离。默认为欧式距离。
在实验操作中通过5折交叉验证和网格搜索,得到最佳的K值为1,加权计算距离以及采用曼哈顿距离度量方式。k近邻模型分类评估数据如图5所示:
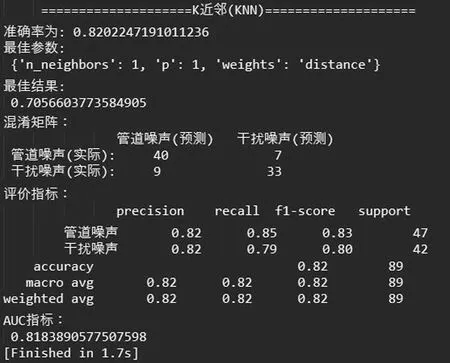
图5 k近邻模型分类评估报告
(3)随机森林(Random Forest)
随机森林属于集成学习中bagging算法的一个扩展变体,随机森林在以决策树作为基础学习算法构建Bagging集成的基础上,进一步在训练决策树模型的过程中随机的选择属性。具体来说,传统决策树模型在选择“分枝”属性时,在当前结点的所有候选属性中选择一个最优属性;而在随机森林中,对基础决策树的每个结点,先从该结点的候选属性集合中随机节选一个属性子集,再从这个子集中选择最优属性用于“分枝”。由此,随机森林的基础学习算法的“多样性”不仅源于样本的扰动,还有来自节选属性子集的扰动,使最终集成算法的泛化能力进一步增强。
随机森林继承了基础学习算法决策树的所有超参数,并加入了配置集成学习模型的超参数。这里我们选取了“n_estimators”“criterion”两个超参数进行调优。“n_estimators”限制森林中树的数目;“criterion”确定树“分枝”的标准,可选的是信息熵或者基尼指数,默认是基尼指数。
随机森林模型分类评估数据如图6所示:
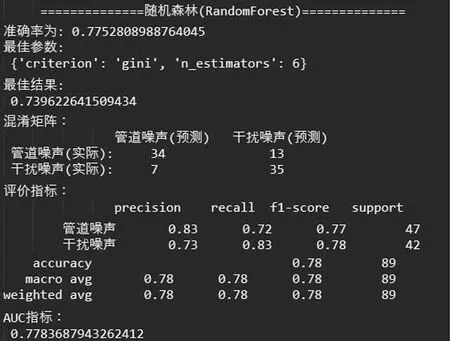
图6 随机森林模型分类评估报告
4 结果分析
从模型分析评估报告中可以看出,三种算法的训练模型在测试集中的表现均优于训练集,说明模型拟合度适当;准确率均在75%以上,对于这样小规模的样本集来说,模型的表现已经可圈可点。其中KNN模型准确率最高,但对于模型性能的优劣不能简简单单地对比准确率,还需要更为细致的评估指标。
在分类任务中,预测结果与真实分类之间存在以下四种不同的情况,这四种预测情况构成了混淆矩阵,如图7所示。
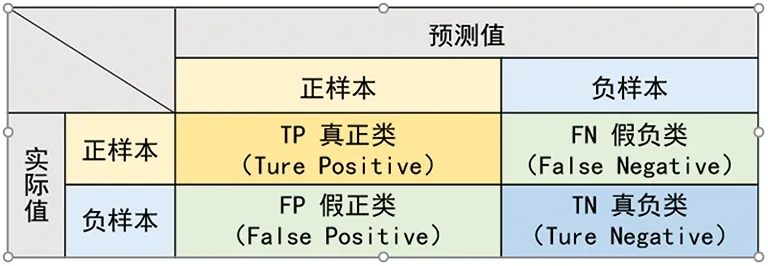
图7 混淆矩阵
其中TP,FN,FP,TN分别表示了预测值域实际值的关系(表6),可以以数量或比例的形式表示。各项评估指标的计算需要借助混淆矩阵中的这四个值。

表6 混淆矩阵
4.1 模型评估指标
以下列出本实验需要用到的模型评估指标:
准确率(Accuracy):所有样本中被正确预测的样本所占比例。
Accuracy=(TP+TN)/(TP+FN+TN+FP)
最佳结果:该结果由网格搜索与交叉验证所得,是训练阶段模型的评估指标。
预测正类精确度(Precision):正确预测为正类占全部预测为正类的比例。
Precision=TP/(TP+FP)
实际正类召回率(Recall)正确预测为正类占全部实际正类的比例.
Recall=TP/(TP+FN)
ROC曲线和AUC指标:这是最常用的模型评估指标。ROC曲线可以检查出机器学习模型的准确率以及阈值对其泛化性能的影响,但很多时候ROC曲线并不容易直观的说明哪个模型的分类效果更好,而AUC指标借助ROC曲线以下与坐标轴所围成的面积来评估模型,它的取值范围介于0.5~1,AUC越接近1,模型分类准确性越高;越接近0.5,则模型分类准确性越低。
4.2 设定先验假设
谈到评估模型算法的优劣,就无法绕开没有免费午餐定理(No Free Lunch Theorem),它的大意是说如果我们没有对特征空间提出先验假设,那么所有算法的平均表现是相似的,不存在哪种算法更好。也就是说我们必须针对需要解决的实际问题提出先验假设,才能找出更加适合该假设的模型算法。
针对渗漏预警系统报警问题,我们最理想的算法当然是百分百准确率(Accuracy)。但如果系统必须存在误差,显然我们首先希望误差不要出现在实际存在管道噪声的监测点(Recall),其次是尽量减小干扰噪声预测误差(Accuracy)。所以针对渗漏预警系统报警问题需要提出的先验假设是:在尽可能避免将管道噪声预测为干扰噪声的前提下能更准确预测干扰噪声的模型性能更优秀。
将这个假设归纳为性能指标即:
约束性指标:正类召回率
优化性指标:准确率
从表7可以看出,虽然KNN模型算法有着最高的准确率,AUC指标表现也最佳,但约束性指标逊于SVM。本次实验最终选取SVM模型对测试样本进行分类,从测试混淆矩阵中可以看出,测试样本共计89个,47个正样本全部分类正确,42个负样本中23个分类正确,19个分类错误,系统误报率21.3%。较原始数据47.2%的误报率有显著改善。
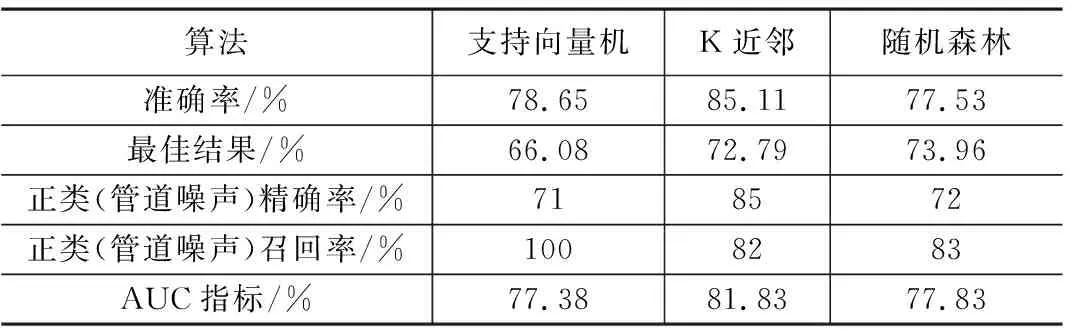
表7 评估指标类比
5 实验思考
通过本次实验,我们可以看出机器学习模型能够有效降低供水管网渗漏预警系统的误报率。其实人工智能技术在漏水探测,乃至整个供水行业的适用程度远不止于此,小到根据噪声计算漏点位置,结合管网的流量和压力分布解决水压异常,大到城镇管网智能调压系统,压力管网仿生漏控体系。相信随着科技创新投入的不断加大,传统供水行业也可以越来越“智慧”。
事实上,该实验的最初设计是一个复杂度更高的三分类问题,即分类漏水噪声、管道噪声、干扰噪声,由于条件所限,样本的数量和分布无法满足实验要求,只能退而求其次将前两类合并为一类,简化成为上述实验,希望勉强能为漏控工作的技术创新起到投石问路的作用。最后援引习主席的讲话与君共勉,“抓创新就是抓发展,谋创新就是谋未来。不创新就要落后,创新慢了也要落后。”。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
今日农业(2020年22期)2020-12-25 02:30:28
数学年刊A辑(中文版)(2020年3期)2020-10-27 02:44:16
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中国特种设备安全(2019年3期)2019-04-22 05:05:40
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
中学生数理化·八年级物理人教版(2017年9期)2017-12-20 08:11:30
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
噪声与振动控制(2015年4期)2015-01-01 07:08:05
燃气轮机技术(2014年4期)2014-04-16 03:54:05
