
城市街区和签到数据结合的个性化城市兴趣区域推荐方法
2022-09-01 09:20:26刘纪平张志然杨超伟徐胜华仇阿根张福浩
测绘学报 2022年8期
刘纪平,张志然,2,杨超伟,徐胜华,陈 才,仇阿根,张福浩
1. 中国测绘科学研究院,北京 100830; 2. 西安石油大学地球科学与工程学院,陕西 西安 710065; 3. 乔治梅森大学时空创新中心,弗吉尼亚 费尔法克斯 22030; 4. 江苏海洋大学海洋技术与测绘学院,江苏 连云港 222005
基于位置的社交网络(location-based social networks,LBSNs)已经成为人们生活中不可或缺的一部分。LBSNs平台上的签到功能吸引了越来越多的用户记录和分享他们的位置和体验[1],由此产生了稀疏且海量的签到信息,这些信息为用户签到偏好分析和区域推荐提供了数据基础。用户在LBSNs中的签到具有多种特征:用户的大多数签到发生在特定的地理区域[2],具有区域性和聚集性[3-6];用户签到活动局限于常去区域的少数类别[7-8],区域内的兴趣点类别是吸引用户的重要因素。如何利用多种签到特征分析用户签到区域特征,构建更加贴合用户需求的推荐模型,是非常值得研究的问题,对城市规划管理、商业选址和旅游资源开发都具有重要意义[9-10]。
相比于兴趣点(point of interest,POI)推荐[2,11-12],兴趣区域推荐的研究起步较晚。由于区域中分布了若干POI,不同的POI对不同用户的吸引力不同,POI推荐算法难以直接应用到ROI推荐中[13]。已有研究学者基于社交媒体数据实现城市兴趣区域分析并应用到位置推荐系统中。文献[14]从带有标题的地理标签的照片中提取主题标签,给每个照片赋予多个主题,使用基于密度的空间聚类算法发现用户感兴趣的主题区域,向用户推荐主题区域。文献[15]利用POI之间的交互来提高推荐性能,并将区域推荐问题简化为几何相交问题,向用户推荐可能感兴趣的居住地以外的区域。文献[16]利用用户在区域内签到过的兴趣点类别的熵值与区域内类别的最大熵值之间的差值来衡量用户在区域内的偏好偏差,寻找用户的城市功能区域。然而,现有研究还存在以下问题:①利用以聚类[14,17-18]、地理格网[15,19]、Voronoi[20]等方式获得的ROI,虽然可用于实现细粒度的ROI分析,但忽略了地物的连续性,所获得的城市兴趣区域难以与城市地理特征相结合,可解释性不强;②由于位置维度的连续性,Voronoi和聚类等方式难以对用户的签到活动偏好进行连续建模。
道路网是人类发展和城市发展的产物[21],道路网包围形成的街区是城市结构的基本组成单位,通常具有一种或多种相似的功能特征,且与兴趣点的分布具有密切的关系[22]。例如,一个包含很多商店和餐馆的街区可能是一个商业中心,一个包含纪念碑和公园的街区可能是一个旅游景点。用户的签到活动与街区的功能特征相关联,用户通常在固定街区访问其中几种类别的POI。因此,城市街区在ROI分析上具有天然的优势,以城市街区为基本单元既能对用户的签到偏好进行连续性建模,也能提高ROI可解释性。
综合以上分析,本文结合城市街区和LBSNs中的签到数据,提出一种个性化城市兴趣区域推荐(city block and check-in data,CBCD)方法。该方法基于空间邻近性原则推断用户的空间活动偏好,同时利用区域内包含的POI类别判断区域功能的相似性,协同建立用户在其他区域的类别偏好,最后将基于地理偏好和类别偏好的特征进行融合。CBCD方法受传统兴趣点推荐方法启发,基于传统理论方法改善了用户签到数据的稀疏性,对用户兴趣区域进行了定量分析,提高了兴趣区域推荐的精准度。
1 基本定义
定义1:兴趣区域。具有特定功能、能够吸引用户关注和活动的综合区域,一个兴趣区域内往往包含一个或若干个兴趣点[13]。
定义2:城市街区。被街道包围的最小的一组建筑物,包含住宅、商店、学校等,它通过道路与其他街区相连[23]。在《语言大典》中的定义为:通常由街道围绕,有时由其他边缘(如河流、铁路)围绕的长方形空地,被使用或计划修建建筑物之用。将街区集合表示为R={r1,r2,…,rn},ri∈R表示一个城市街区,城市被划分为n个街区。本文将城市街区作为兴趣区域的基本组成单位。
定义3:活跃区域。若用户u在街区ri中的签到数量占总签到数量的比例frequ,ri大于或等于阈值σfreq,则街区ri为用户频繁访问的区域,加入活跃区域集合Ru,a。
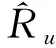
定义5:最短路径。从某顶点出发,沿道路到达另一顶点所经过的路径中,各边的权值之和最小的一条路径为最短路径。两个区域ri和rj的中心点经纬度分别为li={loni,lati}和lj={lonj,latj}。则这两个区域之间的距离最短路径定义为li和lj之间沿道路网的最短路径值。

2 兴趣区域推荐方法
在日常生活中,用户经常访问自己熟悉的位置,对曾经访问过的位置感兴趣,距离用户兴趣区域越远的街区对用户的吸引力越弱[24]。另一方面,用户的签到偏好体现了用户在区域内对POI类别的偏好程度[16],当两个街区拥有越多的共同类别的POI时,这两个区域在类别上越相近。因此,距离和区域类别相似性是发掘用户潜在兴趣区域的两个重要因素。
2.1 研究框架
基于用户的签到信息发现用户活跃区域,基于活跃区域定义用户在未访问区域的潜在偏好程度。受基于记忆的协同过滤思想的启发,通过计算未访问区域与活跃区域的相似性,判断用户在未访问区域的偏好得分,实现用户兴趣区域的连续性建模。图1为本文的研究路线,主要包括以下4个步骤:
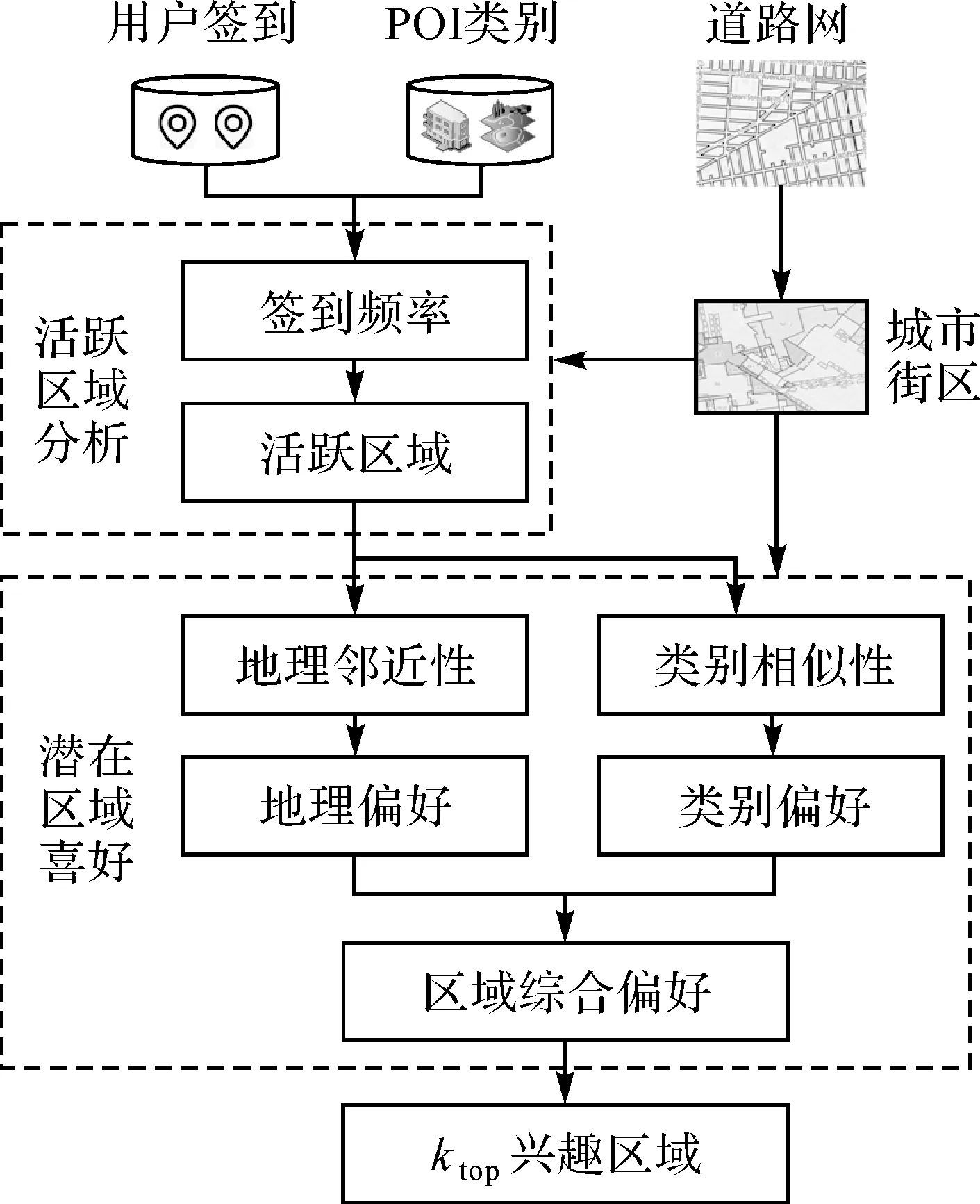
图1 研究路线Fig.1 Analysis process
(1) 城市街区构建。将城市整体按照道路网划分为若干个街区,将用户的签到信息映射到这些区域中,将兴趣点签到转化为区域签到。
(2) 用户活跃区域分析。依据用户的签到信息计算每个用户在区域的访问频率,用户访问频率越高说明该区域越受用户欢迎。
(3) 潜在区域偏好得分。针对用户未签到过的潜在区域,提出基于空间邻近性和类别相似性的兴趣区域推荐方法,得到用户在未签到街区的潜在地理偏好和类别偏好。在空间邻近性上,采用基于欧氏空间中的最短路网距离来度量。在类别相似性上,采用两个街区共同拥有的POI类别数量来度量。最后,基于统一的融合方法融合用户在未知区域的地理偏好和类别偏好得分,得到用户的综合偏好得分,实现用户在城市区域空间的连续性建模。
(4) 兴趣区域推荐。根据用户对所有街区的综合偏好得分,向用户推荐ktop个得分最高的街区。
2.2 路网距离约束的地理偏好建模
在位置推荐问题中,研究者在进行地理建模时通常采用欧氏距离或大圆距离计算两个对象之间的距离[2,25-26]。然而,城市中的兴趣点常沿道路分布,用户在城市空间中的物理运动通常受道路网约束[22]。对用户在城市内部的活动进行建模时,应该考虑实际路网距离的影响,使用最短路径距离能真实地考虑到用户的实际旅行距离和城市网络空间的服务功能,更为直观和可靠(图2)。同时,本文采用了城市街区作为研究的基本单元,最短路径能更真实反映区域之间的地理距离。
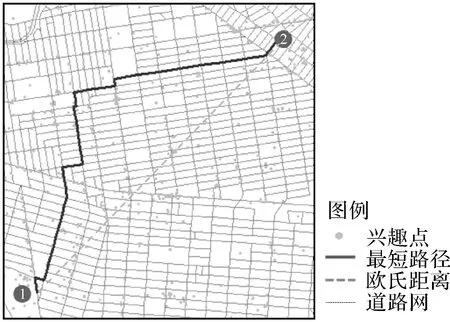
图2 两点之间的距离Fig.2 Distance between two points
已有学者研究了用户访问位置的可能性,发现是与距离成反比[27-28]。本文在已有研究的基础上,结合区域中心点之间的最短路径距离来度量空间中两个区域之间的邻近性。给出区域r1和r2的空间邻近性
(1)
式中,d(r1,r2)表示r1和r2的最短路径距离,距离越远,Simspatial(r1,r2)值越小,表明区域r1和r2邻近性越小。在实现方式上,将道路网处理为无向图,采用Dijkstra方法计算得到任意两个区域中心点之间的最短路径值。
假设用户u的活跃区域Ru,a={r1,r2,…,rm},则用户对未访问区域rj的地理偏好度为
(2)
式中,frequ,ri表示用户u在ri签到次数。由式(2)可知,用户对rj的地理偏好为用户的活跃区域对该街区的地理影响力的和。
2.3 基于区域类别相似性的偏好建模
在判断两个区域之间的相似性时,区域内POI的类别组成也起着至关重要的作用。若两个区域拥有越多相同的类目,则它们的城市功能越相似。给出区域r1和r2,基于Jaccard相似度计算方法,对类别相似性定义如下
(3)
式中,Cr1、Cr2分别表示区域r1和r2中包含的POI类别。Simcategory(r1,r2)值越大,表明区域r1和r2相似性越大。
假设用户u的活跃区域Ru,a={r1,r2,…,rm},则用户对未访问区域rj的类别偏好度为
(4)
式中,frequ,ri表示用户u在ri签到次数。由式(4)可知,用户对rj的类别偏好为用户的活跃区域与该街区的类别相似性的和。
2.4 综合偏好
由空间邻近性和类别相似性可知,当两个区域具有相似的区域功能且距离较近时,更有可能吸引用户,成为用户的潜在兴趣区域。线性加权和乘积是融合多种偏好最直接的两种方式,得到了广泛的应用[3,16]。当综合考虑用户的地理和类别偏好时,简单的加权平均很难动态地分配这两个权重。因此,采用乘积方式计算用户对未访问区域rj的综合偏好。对于用户已访问区域,采用签到次数表示用户对该区域偏好。用户对区域rj的综合偏好度为
(5)
式中,frequ,ri表示用户u在ri签到次数。pu,ri值越大,表明rj对用户的潜在吸引力越大。
至此,本文针对所有用户在城市内所有区域的偏好进行了连续性建模,获得用户对城市街区偏好的综合分布。最后,依据用户在城市区域的综合偏好得分pu,ri,向用户推荐ktop个得分最高的街区,帮助用户在位置社交网络的海量数据中找到自己感兴趣的位置,从而探索新的兴趣点或兴趣区域。
3 试 验
3.1 数据集
本文研究的试验数据主要包括Foursquare的公开数据集和纽约市道路网[29]。Foursquare数据集[16]时间范围为2012年4月3日—2013年2月16日。本文在原数据集的基础上移除了用户在纽约市以外的签到记录。为了缓解数据稀疏性的影响,采用与文献[16]类似的数据预处理方式,对Foursquare数据集移除访问少于10个兴趣点的稀疏用户。经过数据预处理,有1008个用户,30 497个兴趣点,总签到次数为181 876,每个兴趣点至少被访问一次。数据集中POI类别包括9大类,251个子类[30]。表1给出了部分数据示例,包含了用户编号、POI编号、兴趣点子类别、纬度、经度、时间等信息。图3给出了Foursquare数据集的签到点空间分布,同时截取了用户在中央公园附近的签到情况,可以看出,用户的总体签到具有明显的沿街道分布的特征。图4给出了纽约市城市街区空间分布。

图3 Foursquare签到点(2012年4月3日—2013年2月16日)Fig.3 Check-in point of foursquare (from Apr. 3, 2012 to Feb. 16, 2013)
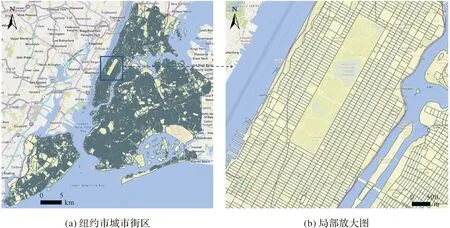
图4 纽约市城市街区Fig.4 City block of New York city
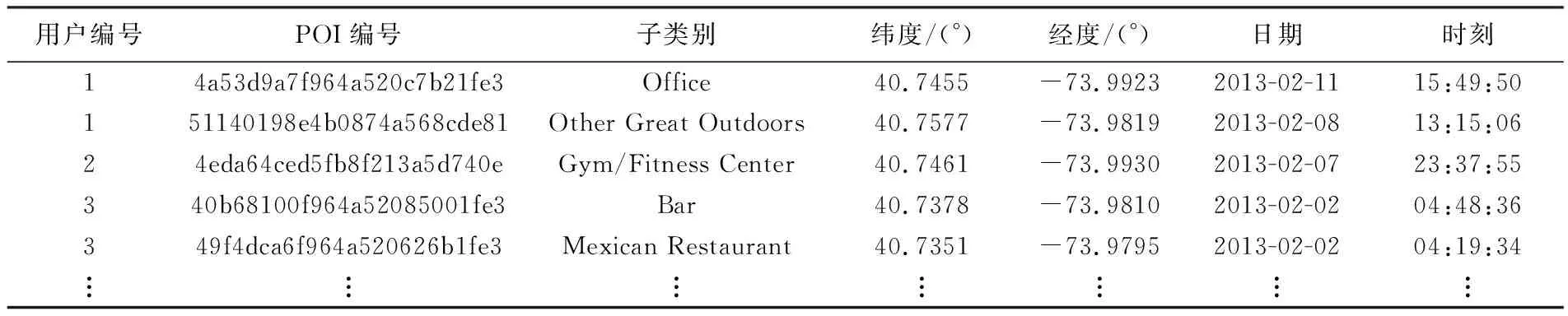
表1 数据示例Tab.1 Example of foursquare
为了验证兴趣区域推荐算法的有效性,将每个用户的签到按时间排序,签到序列的前80%签到作为训练集,最后20%的签到作为测试集。
3.2 评价指标
主要评估目标是查看用户在测试集的签到区域是否出现在推荐区域列表中。具体来说,对测试数据集中的每一个签到,获得其所在区域编号,然后判断该签到是否在推荐列表中。本文使用准确率(P)、召回率(R)和F1score (F1)作为评价指标。为了全面评测ktop推荐的性能,选取不同的推荐列表长度ktop(k值分别设置为1、5、10、20)。
准确率表示在ktop的推荐区域中,用户在测试集中真实访问过的百分比。给定用户u∈U,Tu表示用户在测试集中访问的区域集合,Ru(ktop)表示通过算法计算得到的推荐列表,准确率的计算公式为
(6)
召回率表示测试数据集中的签到出现在ktop的推荐区域中的百分比。给定用户u∈U,Ru(ktop)表示通过算法计算得到的推荐列表,Fu表示用户在测试集中的签到集合,(u,t,c)表示Fu中用户的一次签到记录,召回率的计算公式为
(7)
F1score是准确率和召回率的调和平均数,取值范围为[0,1]。当两个方法在准确率和召回率上表现不一致时,可以采用F1作为最终测评的方法。召回率的计算公式如下
(8)
3.3 对比方法
本文首次采用城市街区为基本单位进行用户的兴趣区域推荐,与已有基线方法进行比较。试验均使用Python及其开放源代码包实现。
(1) UCF:基于用户的协同过滤(user-based collaborative filtering,UCF)推荐算法,找到具有相同区域偏好的用户,向用户推荐相似用户经常访问的区域。本文采用余弦相似度计算用户相似性,用户在区域的访问频率作为用户对该区域的偏好度,记为UCF。
(2) MFR:用户访问最频繁签到的区域(most frequent region,MFR),向用户推荐签到次数最多的街区,由于假设所有用户的空间偏好是相同的,该方法为非个性化的推荐。
(3) CBCD+:使用线性加权的方式将地理偏好和类别偏好进行融合,在线性加权之前对pspatial(rj)pcategory(rj)进行标准化。
(4) CBCD:本文提出的个性化兴趣区域推荐方法(2.4节),其中SpatilRR为基于地理偏好的推荐方法(2.2节),CategoryRR为基于类别偏好的推荐方法(2.3节)。
3.4 结果分析
3.4.1 活跃区域分析
本节对用户的平均签到区域数量和每个区域平均签到次数进行了分析。首先,用户平均签到区域数量结果显示,平均每个用户的签到区域数量为52.77,94.54%的用户在签到区域数量低于100个,这说明用户的平均签到活动比较活跃。图5为用户签到区域数量统计,可以看出,用户签到区域数量在50左右时用户数量最多。其次,对用户在区域的平均签到次数进行分析,所有用户的平均签到次数为3.08,这说明每个用户在自己访问过的区域平均签到3.08次。图6为区域平均签到次数,可以看出,分别有35.32%和34.14%的用户在区域的平均签到次数位于[1,2)和[2,3)之间。这说明大多数用户会倾向于访问自己曾经访问过的区域。

图5 签到区域数量Fig.5 The number of check-in blocks
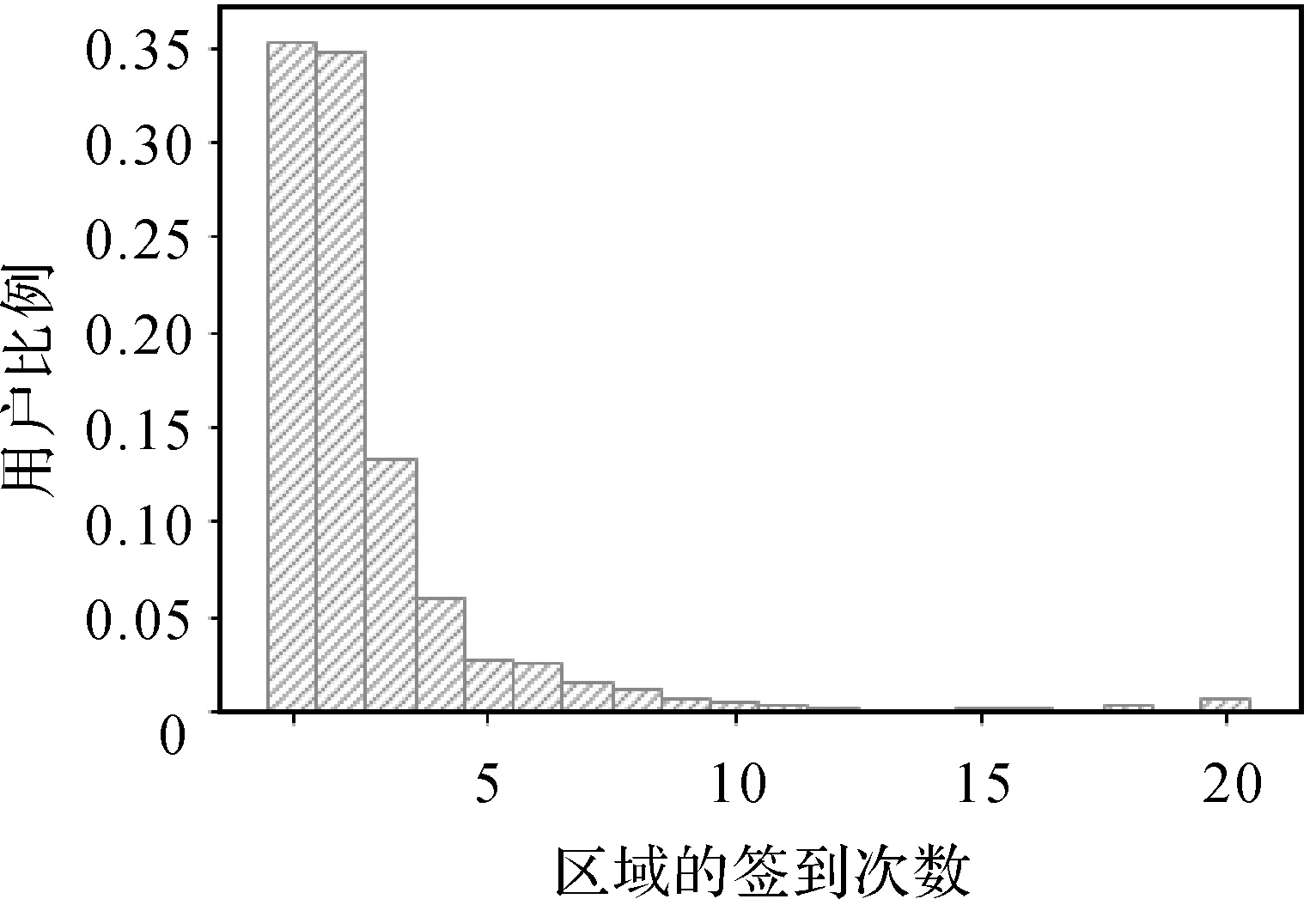
图6 区域平均签到次数Fig.6 The average check-in count for blocks
为了清晰地表示用户的签到区域,图7给出了所有用户在不同街区签到频率的分级统计图,可以看出,用户的签到足迹遍布城市,在单个街区内的签到次数范围为[1,1654]。其中,最受用户欢迎的街区主要分布在交通枢纽、著名景点附近等,空白区域表示该区域没有签到。对于单个用户来说,通过设置频率阈值σfreq可以选出最受用户欢迎的区域。

图7 城市街区签到Fig.7 Check-in map of city block
3.4.2 整体推荐性能
本节根据用户活跃区域,基于CBCD方法对推荐用户的感兴趣区域。其中,签到频率阈值σfreq取0.001,SpatialRR中距离阈值θdis设置为无穷大,参数分析见3.4.3节。
图8为不同推荐方法的推荐准确率、 召回率和F1score的柱状图。随着ktop值增大,推荐结果中用户在测试集中真正签到的区域增加,因此召回率增大;而与此同时,用户未签到的区域也增加,因此准确率减小。总体上来说,考虑了区域地理影响和类别影响的方法在推荐精度上明显高于仅考虑了地理影响和类别影响的方法。在ktop值为1的情况下,SpatialRR和CBCD具有几乎相同的推荐准确率、召回率和F1score,且准确率达到75.40%,这说明两种方法能够较准确地找到用户最感兴趣的区域之一。同时,CategoryRR在推荐性能上明显低于SpatialRR,这说明LBSNs中用户签到活动的空间规律性更显著。CategoryRR能够捕获区域类别相似性,但没有考虑距离影响,在类别上相近但距离较远的区域对用户吸引力较低。
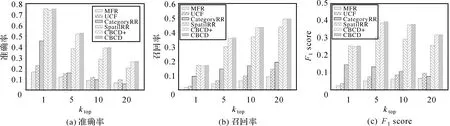
图8 不同方法的推荐结果对比Fig.8 Comparison of the recommendation results under different methods
CBCD推荐性能明显高于UCF和MFR两种基线方法。UCF方法仅考虑了相似用户的偏好,没有考虑到用户签到的地理和类别影响,MFR方法采用了非个性化的建模方式,且没有对所有区域进行连续性建模。这说明CBCD能够很好地捕获用户的地理偏好和类别偏好,提高推荐精度。CBCD+也表现出较好的性能,但在推荐性能上略低于CBCD方法。
3.4.3 参数分析
CBCD融合了地理偏好和类别偏好,参数的确定决定了推荐精度,以下分别对参数设置进行说明。主要参数包括签到频率阈值σfreq和距离阈值θdis,分别针对两个阈值进行了两组试验。由于不同的ktop值4种方法的相对表现基本相同,因此ktop取10。
(1) 在距离阈值θdis为无穷大的情况下,将σfreq依次取值为[0.001,0.005,0.01,0.05,0.1]。图9为3种方法在不同频率阈值下的准确率、召回率和F1score。当σfreq为0时,表示将用户所有访问过的区域作为兴趣区域。可以看出,随着阈值增大,3种方法的准确率、召回率和F1score均呈下降趋势,当σfreq小于0.001时精度最高。当逐渐σfreq时,大于该阈值的兴趣区域被保留,用户兴趣区域数量减少,推荐精度逐渐降低,这说明用户对曾访问过的区域均具有一定的偏好,对提高推荐精度都起到了一定的作用。虽然σfreq可以选取用户最感兴趣的若干个区域,但在当前应用场景下,σfreq取值小于0.001更为合适。

图9 不同频率阈值下推荐结果Fig.9 Results of various frequency thresholds
(2) 为了探究θdis参数的影响,在保持σfreq为0.001的情况下将θdis依次取值为[INF,0.2,0.5,1.0,1.5,2.0,2.5,3.0,3.5,4.0,4.5,5.0](单位:km)。INF表示无穷大,即不考虑路网距离的影响。依次加入距离阈值进行分析,比较SpatialRR、CBCD在不同参数下的推荐性能。图10为两种方法在不同距离阈值下的准确率、召回率和F1score。可以看出,随着阈值减小,两种方法的准确率、召回率和F1score均呈上升趋势,SpatialRR上升趋势明显,而CBCD整体趋于平稳。这说明当逐渐缩小用户兴趣区域影响范围时,推荐精度逐渐升高,用户倾向于访问自己经常访问区域的周边区域。随着阈值的减小,计算复杂度增加,且阈值小于500 m时,推荐精度基本不变,因此,可以认为500 m是一个合适的距离阈值。

图10 不同距离阈值下推荐结果Fig.10 Results of various distance thresholds
同时,当阈值小于500 m时,两种方法的准确率、召回率和F1score差距很小,这说明距离阈值能够显著提高SpatialRR方法的推荐精度。通过限制兴趣区域的地理影响,仅将用户经常访问区域的周边区域赋予权重,是提高推荐精度的有效方法。
3.4.4 案例分析
为了清晰地表示用户的兴趣区域以及距离阈值的影响,本文随机选取一个用户的签到点和区域得分进行可视化。图11为CategoryRR、SpatialRR和CBCD 3种方法下区域得分的空间分布,其中,图11(a)表示不设置距离阈值的SpatialRR,图11(b)表示距离阈值为500 m的SpatialRR,图11(c)表示CategoryRR,图11(d)表示距离阈值为500 m的CBCD。σfreq均为0.001。
由图11可以看出,CategoryRR方法计算得到的类别偏好得分在城市街区中的空间分布比较分散,而类别相近的但距离较远的区域对用户的吸引力较小,难以有效地区分出用户的区域偏好;SpatialRR方法计算得到的地理偏好得分中分值较高的区域集中分布于两个区域,同时,距离阈值能够明显识别出用户的签到热点区域,相比CategoryRR取得较好的效果;CBCD方法计算得到的综合偏好得分较高的街区主要分布在用户频繁签到的区域及其周围,CBCD方法能够较为准确地找出用户的感兴趣区域,且表现更为稳定。
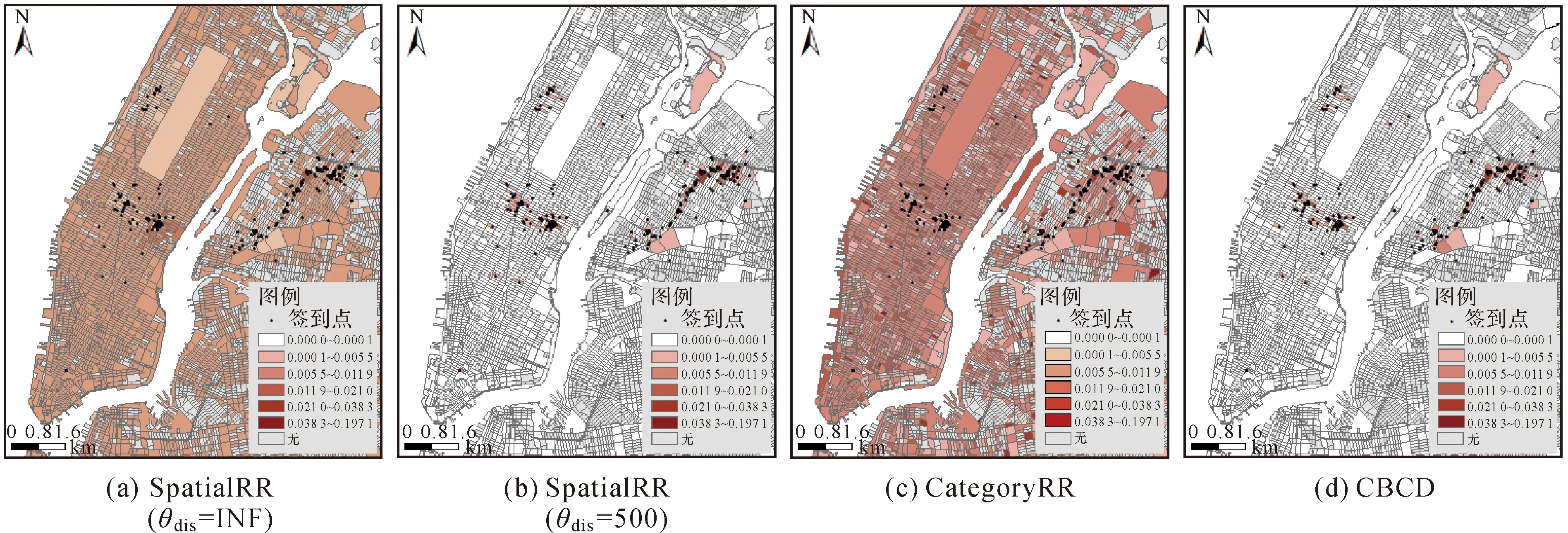
图11 用户签到偏好的空间分布Fig.11 Spatial distribution of user 's check-in preference
4 结 论
分析用户的城市兴趣区域,对用户在城市区域级别的活动进行连续性建模,对了解用户行为模式、辅助城市商业规划起着重要作用。受传统兴趣点推荐算法启发,本文首次结合道路网形成的城市街区和位置签到数据,提出了基于空间和类别相似性的个性化兴趣区域推荐方法(CBCD),该方法有效融合了地理邻近性和类别相关性,研究了地理影响和类别影响在改善推荐性能方面所起到的重要性,对用户城市活动进行连续性建模,最终实现了用户的兴趣区域分析和推荐。试验结果表明,用户更喜欢其经常访问区域的周边,本文方法提高了兴趣区域推荐精度,对于用户兴趣区域推荐研究具有一定的意义。
基于个体活动的地理分布,用户活跃区域可能有更复杂的地理表示;用户在经常访问区域内访问特定的几个类别,而不是所有类别,说明用户在不同区域的访问行为具有偏好偏差。将在未来的工作中研究不同地理表示方法、不同类别偏好的表现。同时,本文仅对用户的兴趣区域进行建模并没有结合当前用户位置和时间信息,不能预测用户接下来可能访问的区域,将在今后研究中解决该问题。
猜你喜欢
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14 07:36:02
制造技术与机床(2019年9期)2019-09-10 07:36:54
西南交通大学学报(2018年6期)2018-12-18 02:22:28
电子制作(2018年17期)2018-09-28 01:56:44
通信电源技术(2018年5期)2018-08-23 01:15:36
河北遥感(2017年2期)2017-08-07 14:49:00
衡阳师范学院学报(2016年3期)2016-07-10 07:16:27
新校长(2016年8期)2016-01-10 06:43:59
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
