
基于YOLOv5的交通标志识别系统
2022-08-31 23:35:23周钰如厉丹肖辰禹赵子龙
电脑知识与技术 2022年19期
关键词:无人驾驶
周钰如 厉丹 肖辰禹 赵子龙


摘要:为了防止驾驶员因极端天气、照明条件不良、交通标志破损等原因误判或漏判道路交通标志而引发严重交通事故,以及促进智能汽车和无人驾驶技术的发展,提出一种基于YOLOv5算法的交通标志识别系统。YOLOv5在YOLOv4算法的基础上进行了检测性能提升的改进,其在目标检测方面的精度和速度都有极大的提升。实验在原有数据集的基础上还对图像进行了曝光、暗化、雾化、模糊等处理,以尽可能还原真实道路情况。实验采用Make Sense在线标注工具对数据集进行标注,在AutoDL品质GPU租用平台租赁GeForce RTX 3090对数据集进行训练。
关键词:无人驾驶;YOLOv5;交通标志识别
中图分类号:TP183 文献标识码:A
文章编号:1009-3044(2022)19-0097-03
1 引言
近年来,目标检测技术在无人驾驶上的应用得到了长足的发展,交通标志识别系统应运而生。但是,在汽车行驶过程中常会遇到交通标志残缺和极端天气影响的情况,这就对交通标志识别系统的精度提出了较高的要求。
当前目标检测的主流算法框架大致分为One-stage与Two-stage。Two-stage算法代表的有R-CNN系列,例如传统的Faster R-CNN算法;One-stage算法代表的有YOLO系列。传统的Two-stage算法是输入图像后,先经过候选框生成网络,再经过分类网络,而本文的交通标志识别系统是基于YOLOv5算法实现的,其候选框生成与分类是同时执行的,输入图像只经过一个网络,生成的结果中同时包含位置与类别信息。相比之下YOLO算法避免了计算量大,运算速度较慢的问题,同时还具有学到的图片特征更为通用,能基于整张图片信息进行预测的优点。
目前,现有的交通标志识别方法有基于改进的Fast R-CNN模型识别[1]、基于改进的Mark R-CNN模型识别[2]、基于多尺度卷积神经网络识别[3]、基于YOLOv4模型识别等[4]。在此技术基础上,笔者希望实现一个能够识别较多、较全面的交通标志识别系统。该系统基于YOLOv5实现,旨在应用于无人驾驶汽车和辅助驾驶系统,提高无人驾驶汽车的可靠性与安全性,对于普通汽车的驾驶员来说,能够在不良行车环境下给予前方交通标志的提示,以提高行车安全性。此外,该系统亦可应用于智能导航系统,将交通标志识别结果上传至导航系统中,进行数据比较,结合地图信息、车辆定位以及实时交通信息,以纠正导航路线偏差。在交通标志的维护方面本系统亦能起到重要作用,交通标志常出现褪色、变形等问题,应用TSR 技术,可监控相应路段交通标志的可用性,减少人力与时间的投入[5]。
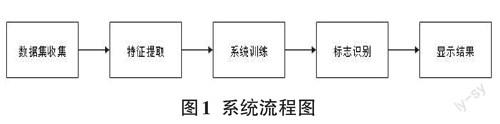
整个交通标志识别系统过程如图1所示。
2 YOLOv5算法简介
YOLO是一种具备实时性和准确性特点的One-stage目标检测算法。简单来说,YOLO算法的核心思想是将物体检测问题处理为回归问题,用一个卷积神经网络结构从输入图像直接预测物体的位置信息和类别。YOLOv5算法和上一代相比主要在检测性能方面进行了提升,优化了数据集的测试效果,在训练速度和精度都得到了极大的性能提升。
YOLOv5目标检测算法的整体框图如图2所示。
YOLOv5通常可以划分为四个通用模块:输入端、基准网络、Neck网络和Head输出端。
输入端模块即输入的图像或视频。该模块包含一个图像预处理阶段,用于将图像缩放到608*608的大小,并进行归一化等操作。而YOLO算法原始的缩放方法存在由于图片长宽比不同,缩放填充后两端黑边大小不相同甚至填充过多的问题,但在YOLOv5算法中提出了一种自适应图片缩放的方法,添加最少的黑边到图片中,大大提升了算法的推理速度。YOLOv5还具有自适应锚点框功能,每次训练时根据数据集的名称自适应地计算出最佳锚点框的位置并标出。
基准网络模块用来从输入的图像中提取一些信息特征,在YOLOv5算法中使用了CSPDarknet53结构和Focus结构作为基准网络。其中Focus结构[6]主要思想是通过slice操作来对输入的图像进行剪裁,将默认的640*640*3大小图片先复制四份,通过slice和concat操作输出320*320*12的特征映射。接着经过卷积核数为64的卷积层,生成一个320*320*64的输出。
Neck网络模块主要用于生成特征金字塔,是一系列混合和组合图像特征的网络层,进一步提升了特征的多样性。YOLOv5中的Neck网络采用了FPN+PAN结构,将原来YOLOv4中的Neck结构采用的普通卷积操作改进为CSP2结构,加强了网络特征融合能力。
Head输出端用于最终检测部分输出目标检测结果,通常包含一个分类分支和一个回归分支。其中IoU_Loss函数用于处理它们之间的重叠面积。但是当预测框和GT框不相交时无法反映两个框之间的距离损失函数不可导,或者当两个预测框大小相等时函数无法区分两者相交。为了解决这两个问题,采用了GIOU_Loss函数[7],增加了相交尺度的衡量方式解决边界框不重合时的问题。DIOU_Loss函数用于处理最小化预测框和GT框之间的归一化距离。CIOU_Loss函数在此基础上又考虑了边界框宽高比的尺度信息。具体计算方法如下。
[CIOU_Loss=1-CIOU=1-(IOU-Distance_22Distance_C2-v21-(IOU)+v)v=4π2(arctanWgthgt-arctanWphp)2](1)
3 實验过程
3.1 实验数据集的收集
本文的数据集是通过网上采集真实街景图像以及道路拍摄采集,数量庞大、内容信息丰富,包括雨雾天气、低曝、过曝、被遮挡、图像模糊的情况。如图所示。数据集中共包含80种交通标志,包括29种禁令标志、21种警告标志、20种指示标志和10种指路标志,一共7000余张测试图像。另外我们还对部分图像进行人工处理,例如曝光、暗化、模糊、雾化等,使其更接近于真实的道路状况。数据集的标注采用Make Sense在线标注工具。
3.2 进行识别
在行驶过程中,交通标志识别系统通过对前方道路出现的交通标志图像进行采集,识别出画面上出现的交通标志图像并标出位置。矩形、圆形和三角形是道路上交通标志的主要形状类别,形状特征相对稳定,不会出现像颜色那样因光照不同而呈现出不同色域的问题,所以我们利用标志形状不易受光照影响的特点,通过搜索形状特点来检测是否为交通标志。识别后的图像上若存在交通标志则该标志会被锚点框框出,锚点框上方会显示该交通标志的名称以及识别的置信度,以此完成识别。
3.3 系统训练
将数据集里的图像导入模型并训练。训练过程中会生成best.pt文件和last.pt文件,分别表示当前最好的模型和当前训练出的最新的模型。我们选用best.pt模型对图像进行测试识别。训练集数据量越多,识别精确度越高。而训练次数过多则会出现过拟合,精确度会下降。
3.4 输出识别结果
在普通条件下,模型能检测出大部分标志,部分标志由于体型较小、距离较远而存在漏检和错检。比较不同条件下的识别结果,原始图像与经曝光后的图像识别准确度最高,经雾化处理后的图像和经暗化处理后的图像较前两种情况而言准确度较低。由此得出,光照差别对交通标志识别的准确率存在影响。
另一个对交通标志识别准确率产生影响的地方是训练的交通标志种类数量。在我们的实验中,我们将80种不同的交通标志作为识别对象,其中不乏极为相似的交通标志图案,比如禁止非机动车驶入和禁止摩托车驶入,禁止大型客车驶入和禁止载货汽车驶入,T型交叉路口和注意合流等,标志的图案都极相似,为识别增添了不小的困难。我们的数据集中还包括一些不太常见的交通标志,比如注意潮汐车道、路面高凸等这些其他实验中不包含的种类,由于难以寻找,所以这几种交通标志种类的实例数量在15个左右,网络无法完全学习该交通标志的特征,后来我们又对其扩充至30余个。同时,部分交通标志种类的实例数量过多,例如限制速度等,以致模型把其他图像识别成这类实例数较多的交通标志。这也导致了部分种类交通标志识别精度不高。而雷蕾[8]等人的实验则采用TT100K数据集,该数据集是由清华大学和腾讯实验室联合发布的,包含30000个交通标志实例约9000张图像,而他们的交通标志类别只有45个,但实例数均大于50个。尹靖涵[9]等人的实验从TT100K中选取了25种常见的交通标志进行识别,故可以得到较高的识别精度。
将识别结果输出,如图4所示。
4 基于YOLOv5算法的交通标志识别系统
交通标志识别系统是在汽车行驶时对前方道路画面中出现的交通标志图像进行定位并准确分类的系统。系统初始界面分为左右两块,如图5(左)所示,左侧为控制面板,右侧为图像显示模块,控制面板中包括打开、更改存储路径、识别、关闭和关于按钮,图像显示模块包括原图像和识别完成的结果图像,如图5(右)所示。
在文件输入模式中本系统提供了单文件和文件夹两种输入方式,为用户对单个样本或批处理提供了通道。选定通道后用户单击打开按钮即可选定单个图片,视频或者整个文件夹,在选择单个图片并且成功打开时,将会同时在识别前区域展示图像。点击识别按钮,系统便会对用户的输入进行识别并且会在识别后区域显示识别结果,识别后的图像会被同步保存到用户指定的存储路径。若选择文件夹通道,系统则会对文件夹内所有目标图像进行批处理。点击关闭按钮系统将关闭相应图像,恢复到初始界面。点击关于按钮,将弹出有关本系统的简略說明。本系统同时还为用户提供了置信度阈值设置界面,用户可根据自身对置信度的要求修改置信度阈值,以应对不同用户对于识别精确度的不同需求。
5 总结
本文提出一种基于YOLOv5算法实现的交通标志图像识别系统,实现不同环境下图像或者视频中交通标志的识别。文中介绍了数据集的采集和处理,模型的训练以及系统的功能和使用。同时指出实验中遇到的问题和存在的不足。在训练数据集的过程中需要注意迭代次数不能过多,在实验过程中就出现了因迭代次数过多而过拟合从而导致训练模型精度下降的现象,后来经过调整迭代次数,识别精度又回归正常。下一步笔者将继续扩大数据集中交通标志种类的数量,主要增添不常见的、数据集中实例较少的交通标志种类实例,以及增加其他极端情况下的图像,从而进一步提高训练精度。另外对已有的基于深度学习的各模型与各优化算法进行优化研究,并探寻两者之间更好的融合方式,以达到更高的识别准确率,使之更为适应现实道路情况。
参考文献:
[1] 马佳良,陈斌,孙晓飞.基于改进的Faster R-CNN的通用目标检测框架[J].计算机应用,2021,41(9):2712-2719.
[2] 伍锡如,邱涛涛,王耀南.改进Mask R-CNN的交通场景多目标快速检测与分割[J].仪器仪表学报,2021,42(7):242-249.
[3] 尉天成,陈小锋,殷元亮.基于多尺度卷积神经网络的道路交通标志识别方法研究[J].西北工业大学学报,2021,39(4):891-900.
[4] 陈梦涛,余粟.基于改进YOLOV4模型的交通标志识别研究[J].微电子学与计算机,2022,39(1):17-25.
[5] 马健,张敏,张丽岩,等.交通标志识别系统研究综述[J].物流科技,2021,44(10):69-74.
[6] 杨晓玲,江伟欣,袁浩然.基于yolov5的交通标志识别检测[J].信息技术与信息化,2021(4):28-30.
[7] 邹承明,薛榕刚.融合GIoU和Focal loss的YOLOv3目标检测算法[J].计算机工程与应用,2020,56(24):214-222.
[8] 雷蕾,方睿,徐铭美,等.基于YOLO的交通标志检测算法[J].现代计算机,2021,27(24):93-99.
[9] 尹靖涵,瞿绍军,姚泽楷,等.基于YOLOv5的雾霾天气下交通标志识别模型[J/OL].计算机应用:1-10[2021-10-31].http://kns.cnki.net/kcms/detail/51.1307.TP.20210917.1616.008.html.
收稿日期:2022-02-25
基金项目:徐州工程学院省一般大学生创新创业训练计划项目(项目编号:xcx2021317)
作者简介:周钰如(2000—),女,江苏泰州人,本科;厉丹(1981—),女,江苏徐州人,副教授,博士,主要研究方向为数据挖掘;肖辰禹(2001—),男,江苏无锡人,本科;赵子龙(2001—),男,江苏淮安人,本科。
猜你喜欢
控制与信息技术(2022年5期)2022-11-19 08:33:52
作文小学中年级(2022年9期)2022-09-08 06:13:30
中国特种设备安全(2021年11期)2021-05-05 06:13:28
科学(2020年3期)2020-11-26 08:18:28
小哥白尼(军事科学)(2020年8期)2020-05-22 06:28:02
专用汽车(2018年10期)2018-11-02 05:32:26
空中之家(2017年11期)2017-11-28 05:28:21
汉语世界(2017年5期)2017-09-21 07:44:38
科学大众(中学)(2017年3期)2017-07-06 18:38:29
百科探秘·航空航天(2016年12期)2017-01-15 13:33:04
