
在微服务下基于GraphQL构建通用一层
2022-08-31 22:37:28李小红
电脑知识与技术 2022年18期
李小红

摘要:芒果TV是以视听互动为核心,融网络特色与电视特色于一体,实现“多屏合一”独播、跨屏、自制的新媒体视听综合传播服务平台,同时也是湖南广电旗下唯一互联网视频平台,提供湖南卫视电视栏目高清视频点播服务,并同步推送热门电视剧、电影、综艺和音乐视频等内容,以及部分电视台网络同步直播。面对直播一层后端服务等最核心业务,如何进行技术创新升级值得思考。本文介绍如何在微服务下基于GraphQL构建通用一层服务。
关键词:微服务;GraphQL[1];通用一层
中图分类号:TP181 文献标识码:A
文章编号:1009-3044(2022)18-0091-04
开放科学(资源服务)标识码(OSID):
1 播放一层业务和技术架构的发展介绍
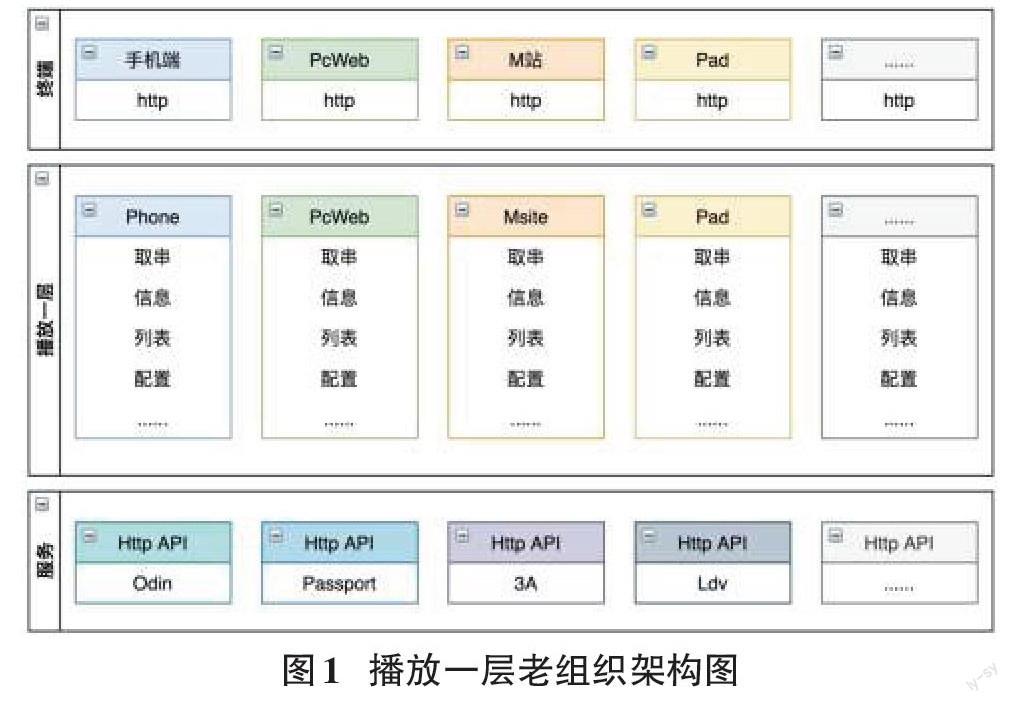
播放一层负责客户端点、直播功能的后端业务逻辑,是直接面向终端的,所以叫“一层”。
芒果TV从最开始的PcWeb端,逐步发展为拥有M站、手机、Pad等客户端,由于早期是按照终端做产品的,也间接决定了播放一层之前的架构。
各个终端发起HTTP请求到自己对应的播放一层,各端播放一层再请求下游HTTP服务接口获取数据,进行业务逻辑处理。
各端播放一层都包含播放的全部业务,且各端播放业务大体相似,抽象来说,有取串、播放页信息、诸多列表和很多配置接口。
此架构的优点有:
1)开发简洁,功能都在各个终端的播放一层内部,便于软件设计和开发规划。
2)容易测试,核心业务没有复杂的服务调用关系,都是内部调用,方便测试。
3)容易运维,各个终端独立部署,互相隔离。不存在分布式集群的复杂部署环境,降低了部署难度。
随着业务的发展,工作模式发生了变化。由按终端来做产品变为统一做产品和业务,只是终端的承载方式不同。播放一层老的技术架构渐渐暴露出一些问题。
主要有三个方面问题:
1)由于播放一层包含有复杂的业务逻辑,在终端、播放一层和服务层职责划分不清楚的情况下,小需求的修改,需要牵动终端、播放一层和服务层三方;
2)全端的相同需求,相同业务逻辑需要在各个终端的播放一层实现一遍,产生大量的重复代码;
3)原生客户端的版本差异化,是通过增长接口的版本号来实现。随着版本的快速增长,带版本号的接口越来越多,难以维护。
2 BFF架构介绍
面对这些问题,我们急需改变。服务化、BFF架构、GraphQL等技术开始实施。接下来介绍播放一层是如何向BFF架构演进的,感受播放一层BFF架构的演进。
要解决播放一层的问题,我们希望:
1)明确定位,明确终端、播放一层和服务层的职责,最主要是搞清楚中间层:播放一层的定位;
2)终端适配,需要一种方便、标准的方式实现多端差异化需求适配;
3)服务化,播放一层合并的过程中抽象出通用业务可以下沉为服务。
据此,新的架构如图2所示。
播放一层定位为介于终端和服务层之间的实现终端差异化的系统。
将播放一层的通用业务独立为微服务,下沉到服务层。微服务按功能划分为:起播、取串、播放页信息、列表等。
将各端播放一层合并为通用一層,合并后如何优雅实现多端和多版本的差异化适配成为重中之重,这也是本文的重点。
上述新的架构,其实就是BFF架构(Backend for Frontends),为前端而存在的后端中间层。
传统的前后端分离应用中,前端直接调用后端服务,后端服务进行业务逻辑处理。那么引入了 BFF 之后,前端将直接和 BFF 通信,BFF 再和服务层进行 API 通信,所以本质上来说,BFF 更像是一种“中间层”服务。
BFF需要做到实现多端和多版本差异化适配,有下面几种适配需求。
1)聚合,对于客户端(特别是移动端)来说,HTTP 请求是很昂贵的,为了减少请求的次数,前端一般会倾向于把有关联的数据API合并为一个;
2)裁剪,不同屏幕的大小等差异,导致相同接口客户端需要的响应结果内容大小不同;
3)适配,不同客户端对后端响应结果名称要求不同。
3 播放一层使用的GraphQL技术
聚合、裁剪和适配如何实现呢?经调研后,选中了GraphQL,一种为API而生的高性能查询语言。
GraphQL 作为一种 API 查询语言,专门用于处理已有服务接口的响应结果,已被Facebook、Netflix、GitHub[2]使用。
例如,一个获取视频信息的接口,GraphQL分为服务端描述数据部分,我们在播放一层定义了Video类型数据,有vid,videoName和serialno字段。同时GraphQL会把描述的数据与后端微服务接口做关联,指定哪个服务的哪个接口返回Video类型数据。
客户端按需求请求播放一层定义的Video类型数据,例如获取vid为10000的视频,且只需要videoName字段。
此时播放一层给客户端的响应内容就只有视频名称信息。
GraphQL并不是一门程序语言或者框架,是一种用于API的查询语言,它的结构为三层结构。
最上层QuerySchema是客户端按需请求的接口数据内容,可对服务端描述数据的DataSchema做裁剪和适配等。中间DataSchema是用于服务端描述数据的。最底层的DataFetcher是静态数据、DB、第三方接口等的包装。GraphQL会把DataSchema和DataFetcher做数据上的关联。
对GraphQL的实现有了初步了解后,接下来介绍GraphQL如何做到:聚合、裁剪和适配,以及GraphQL的高性能和产生的N+1问题解决方案。
3.1 聚合
聚合,多个服务接口数据聚合。
对于客户端(特别是移动端)来说,HTTP 请求是很昂贵的,所以为了减少请求的次数,前端一般会倾向于把有关联的数据API合并为一个。
比如Video类型的数据中,客户端期望返回该视频的基础信息同时,还返回播放次数信息。
服务端描述数据Video中增加playCount字段,标识视频的播放次数。同时给playCount绑定到播放次数服务的接口。
客户端请求Video数据时,也增加playCount字段,那么服务端响应的Video数据就同时聚合了视频基础信息和播放次数信息。
3.2裁剪
裁剪,裁剪掉冗余信息。
客户端获取视频信息时,不需要serialno集数字段,客户端请求时,去掉serialno集数字段即可,服务端响应的Video类型数据则没有serialno字段。
3.3适配
适配,自定义响应内容。
客户端需要接口响应的视频名称不是videoName,而是vname,客戶端请求给videoName取别名为vname,服务端响应的Video类型数据中视频名称字段则为vname。
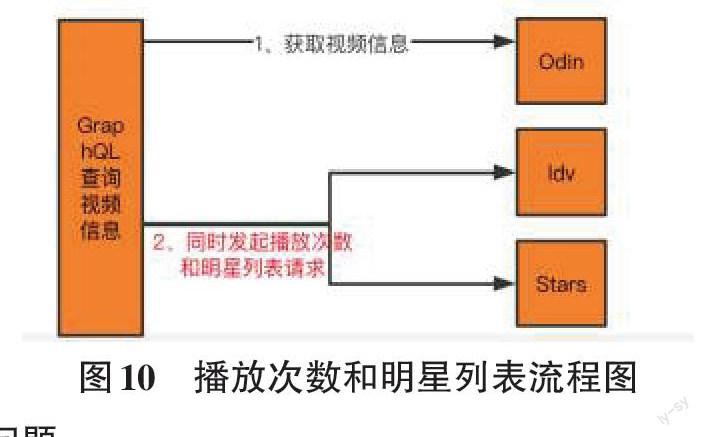
3.4高性能
GraphQL引擎不仅灵活,还可以通过指定查询策略为AsyncExecutionStrategy,实现多个DataFetcher并发执行,提高性能。
比如当QuerySchema获取视频信息的同时,还要获取播放次数和明星列表。
GraphQL引擎在获取到视频信息后,会同时发起播放次数和明星列表的请求。
3.5 N+1问题
虽然GraphQL灵活,但也有天生的缺陷:N+1问题。比如获取视频列表的接口,每个视频都需要返回其的明星列表。
视频列表下的明星列表:
GraphQL执行步骤为:先查询1次视频列表,得到多个视频信息,再遍历视频列表,根据videoId查询明星列表。一共需要发起N+1次请求,这就是N+1问题。
可以通过FaceBook的DataLoade来解决N+1问题。DataLoader支持通过Cache[3]去除重复请求,同时支持去重、合并后,批量请求。
DataLoader支持通过Cache去除重复请求,同时支持去重、合并后,批量请求。
GraphQL提供了丰富的特性,让播放一层非常容易就实现了业务的差异化。例如合集下视频列表接口,同时有计数信息、是否收藏和明星列表信息。
从业务上看,在视频播放页展示列表时,关心的是计数信息和是否收藏,如图14左侧。
在别的页面展示列表时,关心的是明星列表数据,如图14右侧。
因为存在不同的使用场景,所以对于同样的数据却有着不同的关注点。基于GraphQL的播放一层就是为此而生,轻松即可实现。
GraphQL让播放一层的版本化不再复杂。假设播放一层视频列表接口已经上线,提供了isLiked和isCollected的查询,如图15左图所示。
现在需要把接口结构改为中图所示,需要不影响老版本的API访问,如果是之前,我们可能会升级API版本。
但在新架构的播放一层中,为了向前兼容,可以使用图15右图的结构。
4 播放一层接口配置化
在微服务下基于GraphQL 构建的通用一层是什么样子的呢?我们实现了配置即可提供新接口给客户端使用的目标。
播放一层基于Graphql-java开发,整体分为三个部分。
1)QuerySchema部分是接入层,管理QuerySchema配置。支持客户端传入QuerySchema,也可以根据客户端传入的code或请求path和params通过规则映射到QuerySchema;
2)DataSchema部分是各个服务返回数据的图形化组织,用于服务端描述数据;
3)DataFetcher部分是下游服务的抽象层,可配置各个服务的域名、接口地址、请求参数(包括参数验证)、响应结果等,配套有熔断、容错和降级等功能。
播放一层这三个部分,由于主体都是配置文件。故可以做到只需要修改配置,即可在已有微服务的基础上,开发出新的接口。
5 结束语
当通用一层算法固定,只有配置变化时,极大地解放了生产力,提高了生产效率。同时与前沿的Serverless[4]、边缘加速[5]等技术有着友好结合的可能性。
参考文献:
[1] Matt Asay. How GraphQL turned web development on its head[J]. InfoWorld.com,2020:
[2] 齐晴,曹健,刘妍岑.GitHub中软件生态系统的演化[J].计算机研究与发展,2020,57(3):513-524.
[3] 张苏豫,江凌云.基于主动缓存的云边端协同卸载策略[J].计算机工程与设计,2021,42(8):2124-2129.
[4] Hassan H B,Barakat S A,Sarhan Q I.Survey on serverless computing[J].Journal of Cloud Computing,2021,10:39.
[5] 程小兰.面向边缘计算的视频处理加速方法研究[D].杭州:杭州电子科技大学,2020.
【通联编辑:唐一东】
猜你喜欢
小学生学习指导(高年级)(2024年4期)2024-05-07 03:28:46
小学生学习指导(中年级)(2021年4期)2021-04-27 10:14:56
课堂内外(初中版)(2020年5期)2020-06-19 08:11:11
东华大学学报(自然科学版)(2018年1期)2018-06-29 03:35:18
传媒评论(2018年4期)2018-06-27 08:20:24
传媒评论(2018年4期)2018-06-27 08:20:16
电子测试(2018年10期)2018-06-26 05:53:34
消费导刊(2018年8期)2018-05-25 13:19:48
网络安全和信息化(2017年9期)2017-11-07 06:30:48
华东师范大学学报(自然科学版)(2014年3期)2014-03-11 16:18:15
