
基于50 Hz倍频小波时频熵和RUSBoost的变压器绕组松动声纹识别*
2022-08-31 06:55:58马宏忠崔佳嘉
电机与控制应用 2022年5期
李 楠,马宏忠,朱 昊,王 健,崔佳嘉,何 萍
(1.河海大学 能源与电气学院,江苏 南京 211100;2.国网南京供电公司,江苏 南京 210019)
0 引 言
变压器是电力系统的核心设备之一,其安全稳定运行对电力系统的安全性和可靠性起着重要作用[1]。国家电网统计表明,绕组损坏引起的变压器事故占总事故的55.6%。绕组松动导致变压器抗短路能力大大降低[2],给变压器安全稳定运行造成重大隐患,因此迫切需要切实有效的绕组松动故障诊断方法。
针对绕组松动的故障诊断,现有方法主要包括频率响应法、低压脉冲法、短路电抗法以及振动检测法[3]。频率响应法和低压脉冲法要求设备必须离线检测。短路电抗法允许设备在线检测,但无法准确反映故障程度。振动检测法因其与电力设备之间无电气联系以及可以实现在线监测等优点而受到广泛关注,但是其对测点选择要求较为苛刻。
变压器运行过程中发出的声纹信号中包含大量能够反映设备状态的有效信息。基于声音信号的变压器状态监测与故障诊断,具有与被测对象没有任何接触、易于实现带电监测与诊断等优势,且能很好地解决振动测点空间敏感度过高的问题,展现出广阔的应用前景[4]。目前,针对变压器噪声产生机理进行了广泛研究[5-9]。多数学者认为变压器声纹信号由绕组以及铁心振动产生,可以从振动角度去阐述声纹机理[10],绕组以及铁心振动基频为100 Hz,因此变压器声纹信号的基频也是100 Hz[11]。然而从现场数据测量分析的结果看,变压器声纹信号除100 Hz以外,还含有其他50 Hz的倍频分量,并且不同类型的变压器以及在变压器不同的运行状态下,其声纹信号也都存在差异[12]。变压器本身结构的非线性以及声纹信号为多振动源叠加是产生上述现象的主要原因,并且在变压器运行工况波动时,提取的特征量在正常和故障之间存在交叠。因此,传统的特征提取方法难以针对性地提取各类变压器关键故障特征量,无法形成有效的特征提取和识别方法。
近年来人工智能技术在预测、分类等方面的高效率和高准确度发展,给变压器故障诊断和状态监测提供了一种新的思路。包海龙等[13]针对常规波束形成算法定位精确度差的问题,开展了基于反卷积波束形成算法的干式变压器异响故障研究。张重远等[14]提出一种基于Mel时频谱-卷积神经网络的变压器铁心松动声纹识别方法。马文嘉等[15]针对变压器遭受短路冲击时的声信号,提出基于稀疏自适应S变换的变压器绕组状态检测方法。大型电力变压器可靠性高,且工况稳定,故障或异常数据往往较难获取,传统的研究方法对变压器声纹信号能够进行有效的特征提取和模式识别,但存在对不平衡数据适用性差和对数据样本数量要求较高等问题。
为解决上述问题,本文提出一种基于50 Hz倍频小波时频熵和RUSBoost的变压器声纹绕组松动诊断方法。首先,针对变压器声纹特点,提出50 Hz倍频小波时频熵,有效提取声纹特征。然后,利用RUSBoost模型对不同松动故障进行识别。最后,在现场实测数据的基础上验证了方法的有效性。研究结果表明,本文所提方法对变压器绕组不同松动程度故障能够进行准确识别。
1 变压器声纹产生机理分析
变压器声纹一般可以分为铁心声纹和绕组声纹。变压器声纹由铁心振动和绕组振动产生,声波通过液体或者固体路径传播,最终传播至变压器外的声波为多声源共同耦合叠加而成。声波信号在变压器油以及空气传播中衰减极少,并且声波信号在穿过油箱壁时也不会发生频率偏移现象。因此,声纹特性与振动特性基本保持一致。本文通过分析振动原理对变压器声纹进行分析。
绕组是变压器的基本结构,而线圈是绕组的基本组成单元,存在多种绕制方式。以往的质量-弹簧-阻尼模型大多针对饼式结构,不具备普适性,将垫块间的导线作为基本物理单元,称为简化线圈基本单元。将这种具备机械特性和电磁场特性的物理模型称为绕组两体模型[16]。绕组两体模型的运动方程为

(1)

对两体模型进行逐步简化分析,将原非线性系统转换为线性系统。假设流经绕组的电流为
i(t)=Icosωt
(2)
式中:I为电流幅值;ω为电源的角频率。
两体模型可以转换为

(3)
求解非齐次常系数线性微分方程的通解,分为齐次方程的通解和非齐次方程的特解,其中通解为自由分量,特解为强制分量。由于实际系统中的阻尼存在,无源的自由分量最终衰减为零,因此只需要考虑方程的强制分量解:
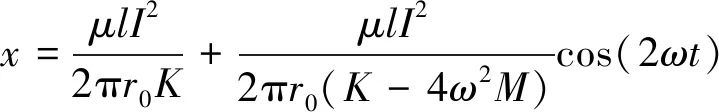
(4)
式(4)右边第一项为恒定力产生的恒定分量,第二项中绕组振动的频率为2ω。对于50 Hz的电力系统而言,其振动频率为100 Hz,即50 Hz的偶数倍频分量。在绕组线圈振动情况下,线圈之间发生周期性变化,使得导线周围磁场与自身振动存在机电耦合。当变压器绕组固有频率与激励频率满足一定条件时,会产生参数共振;当固有频率与电源频率相近时,产生激励电流的奇数倍频率;当固有频率为电源频率2倍时,产生偶数倍频率[17]。
2 50 Hz倍频小波时频熵
本文针对变压器声纹信号特点,提出一种针对变压器声纹信号的特征提取方法,实现对大量音频信号的降维压缩与特征提取,称之为50 Hz倍频占比时频熵(50 FMWTE),主要针对变压器声纹信号中50 Hz倍频分量,其计算过程如图1所示。

图1 50 FMWTE计算过程图
(1) 信号预处理。对采集到的声纹信号进行分帧加窗处理,通过分帧将长声音信号切成短时帧,选取帧长为400 ms,帧重叠率为0.2,并利用汉明窗平滑处理,减轻吉布斯效应影响。
(2) 小波时频分析。对声音信号进行分帧以及加窗处理后,对声音信号进行连续小波变换,先确定小波基与尺度,后求出小波系数,其计算公式如下:

(5)
式中:x(t)为输入声音信号序列;ψ为母小波,采用复数小波Complex Morlet,其在时频两域具有很好的分辨率,适合处理非平稳的声音信号。
(3) 熵值计算。从小波系数序列中提取50 Hz倍频分量小波系数c50×i(i=1,2,3,…,20),并对其进行相空间重构:
Y=

(6)
式中:m为嵌入维数;t为延迟时间;K=N-(m-1)t。
将Y中每行重构分量按照升序重新排列,将重新排列后的矩阵记为S(l)={j(1),j(2),…,j(m)},其中每列数据记为一种符号序列,并计算每一种符号序列出现的概率,记为{P1,P2,…,PK}。利用以下公式计算其熵值,再对计算结果进行归一化处理,得各50 Hz倍频分量的时频熵:

(7)
(4) 占比权重计算。为削弱无用分量的波动信息,增强幅值大的分量,权值采用每种频率分量在时间序列中的最大值之最大值占所有分量在时间序列中的最大值之和的比重,计算公式如下:

(8)
(5) 50 Hz倍频小波时频熵计算。将50 Hz倍频分量小波时频熵按照频率大小排列构成特征向量Hpe,i×50={Hpe,50,Hpe,100,…,Hpe,1 000}。将权重按照频率大小排列构成权重向量δ={δ1,δ2,…,δ20}。50 Hz倍频小波时频熵计算公式如下所示:
Hi=Hpe,i×50·δ
(9)
3 基于RUSBoost的绕组松动故障诊断方法
3.1 RUSBoost模型
人工智能算法往往要求训练集中各样本数据相对均衡,以保证算法具有良好的泛化性。然而作为运行可靠性相对较高的变压器而言,各类样本分布往往不均衡,正常运行状态数据较多,而非正常运行状态数据较少,这使得模型预测结果往往偏向正常状态,对更具意义的非正常样本识别效果不佳。
针对样本数据存在的严重不平衡问题,本文提出基于RUSBoost模型建立变压器声纹识别模型,通过欠采样提高数据样本的均衡性,并结合提升法,将多个简单的基学习器提升为强学习器。对比当前基学习器的训练误差调整训练样本的分布权重,并增加惩罚因子,提高后续训练过程中的关注度,再利用调整后的样本训练下一个基学习器,并由此反复迭代[18]。
RUSBoost模型通过最小化指数损失函数以达到贝叶斯最优错误率,其中最优权重计算公式为

(10)
式中:εt为t组样本预测错误率。
模型最终输出的学习器为T个基学习器的线性权重叠加组合。

(11)
式中:ht(x)为基学习器ht在对应样本x下的预测值。
设训练数据集为S={S1,S2,…,Sm}。模型流程图如图2所示。

图2 RUSBoost模型流程图
3.2 在线故障诊断流程
基于50 Hz倍频小波时频熵和RUSBoost的变压器绕组松动声纹识别方法如图3所示。具体步骤如下。

图3 故障识别流程
(1) 50 Hz倍频小波时频熵计算及特征提取。首先将预处理后的声纹信号进行小波变换,并提取小波系数,然后提取50 Hz各倍频小波系数计算熵值,并利用幅值最大值计算各分量占比权重,最后计算50 Hz倍频小波时频熵并叠加,构成21维的特征向量。
(2) 构建RUSBoost识别模型。采集构建训练集数据样本,通过欠采样处理不平衡数据,结合提升法建立模式识别模型,并通过网格搜索调参,完成对模型的训练。
(3) 基于声纹的变压器运行状态监测。提取测试集数据,通过上述方法计算其50 Hz倍频小波时频熵,并将计算结果代入训练好的RUSBoost识别模型,获得绕组不同松动程度的识别结果。
4 案例分析
4.1 变压器声纹采集平台搭建
本文搭建的变压器声纹数据采集平台如图4所示,数据采集平台主要包括变压器、电脑、DHDAS动态信号采集仪、信号传输线、前置放大器HS14618以及电容式声传感器HS14401等。

图4 数据采集平台
在信号测量方面,电容式声传感器有频率范围宽、稳定性好、能最大程度减少自身误差等优势。根据国际测量标准IEC60651,声信号测量应该覆盖20 Hz~20 kHz的可听声范围,因此设备采用50 kHz的采样频率。采用抗强磁场干扰的信号传输线,有效减少外界电磁场干扰。电容式声传感器测点布置如图5所示,距离变压器油箱外壁30 cm,距离地面35 cm。变压器短路试验下,绕组振动产生的声音远大于铁心振动引起的声音。因此,本文开展短路试验,并利用龙门吊和扭力扳手模拟绕组不同松动程度故障。试验设置低压侧短路,高压侧从零开始施加电压,当低压侧电流达到额定值时停止,并测量声纹信号。测量完毕后,重复通过变压器吊芯,并利用扭力扳手调整变压器绕组垂直方向上的紧固螺丝松紧程度,分别调整预紧力为0、0.25FN、0.5FN、0.75FN和FN,此处FN为额定预紧力,静置后重新测量变压器声纹数据。

图5 声传感器测点布置
4.2 声纹信号时频域与测点位置分析
频谱与时频谱是声信号处理的重要特征频率谱,频谱能够反映信号在不同频率的幅值大小,时频谱能够反映声音信号在不同时间下频率能量的分布状况。频谱与时频谱可以有效建立时域与频域之间的联系,展现声音信号的特征信息,反映变压器的运行状态。如图6所示,变压器正常运行时的声纹信号频率分量表现为50、100、150 Hz等50 Hz倍频分量,其中100、200、300 Hz频率分量相对较多。

图6 声纹信号频域与时频分布
对比不同测点数据,如图7所示,测点位置不同,声音信号各频率分量幅值大小有所差异,但都表现出相近的趋势。声音信号一般都位于900 Hz范围内,并且声音信号频率以50 Hz偶数倍分量为主,50 Hz及其奇数倍分量所占比重较少。变压器声纹为多声源耦合叠加,造成声纹复杂程度增加,测点选取应遵循简单的原则,但变压器状态改变时,测点相对其他测点变化应更为剧烈。2号测点多次测量结果稳定,声纹特征突出,基频占比高,因此选择此测点作为代表测点进行后续研究分析。

图7 不同测点数据对比
4.3 变压器绕组松动模式识别
针对变压器声纹信号特点,提出基于50 Hz倍频小波时频熵的声纹特征提取方法,既保证了关键信息的提取,又防止数据量过大。对随机森林算法进行改进,优化调整其参数,提高识别率。
数据是模型训练识别的基础,本文对设定的5种工况进行数据收集,对麦克风接收到的声纹信号进行数据预处理,并计算其50 Hz倍频小波时频熵得到[H1H2H3…H20],再对各50 Hz倍频熵进行叠加求和得到Hsum,将其组合构成21维特征向量[H1H2H3…H20Hsum]。
为保证模型识别的有效性,在进行模型训练时,需要样本集分成训练集和测试集,样本划分如表1所示。在共计797组样本中,正常样本257组,25%松动程度样本240组,50%松动程度样本218组,75%松动样本43组,100%松动样本39组,各类别样本间最大不平衡率为6.94。表中对不同的工况设置标签,最后将所有带有标签的样本随机输入到模型中进行训练。

表1 样本个数
模型训练采用10折交叉验证的方式,即将数据集划分为10个子集,随机挑选其中1个子集作为验证组,其他9个子集作为训练集,对模型进行10次训练和测试,并通过网格搜索的方法对超参数进行寻优。平均准确率对不平衡样本的性能评价不够全面,因此网格搜索的优化目标为寻找最优AUC值。最终设置调整最大分裂数为37、基学习器个数45以及学习率为0.12。评价结果如图8所示。

图8 混淆矩阵
在如图8所示的混淆矩阵中,横坐标为模型的预测结果,纵坐标为模型的真实结果,最右边1列为模型识别准确率。由图8可知,针对铁心不同松动程度的识别准确率均高于94%,表明模型对绕组不同松动程度故障均能实现有效识别,总体准确度达到98.9%。AUC值为0.98,表明模型对存在不平衡问题的变压器声纹样本同样具有良好的识别精度和适用性。
4.4 优越性验证
为验证本文所提特征提取方法的有效性,绘制各类别特征降维图,对故障特征提取前后进行可视化。由图9可知,原始信号特征在不同故障类别间高度重合,难以被区分,而本文所提50 Hz倍频小波时频熵具有良好的区分度。

图9 特征可视化
为验证本文所提优化的RUSBoost模型的优越性,将常见的决策树(DT)、随机森林(RF)、K近邻(KNN)以及支持向量机(SVM)等模型与本文所提模型进行对比,模型均采用网格搜索寻找最佳超参数,使得其AUC值最佳。各模型分类结果如表2所示。

表2 常见模型分类结果对比
由表2可知,5种模型总体识别准确率都较高,但对于样本量较少的75%松动和100%松动分类性能较差。针对75%松动故障和100%松动故障,本文所提模型相较于RF、DT、KNN、SVM等传统模型,至少提高了2.8%和2.5%。由此可知RUSBoost模型对于不平衡的变压器样本数据具有较好的分类准确率,这对在实际运用中解决变压器故障或异常样本数据缺失具有重要作用。
5 结 语
本文以变压器声纹信号为研究对象,通过变压器声纹数据采集平台采集数据,对变压器运行过程中的不同工况进行研究,并搭建50 FMWTE-RUSBoost声纹信号运行状态监测,为基于声纹的变压器状态监测和故障诊断提供依据。主要结论如下。
通过理论研究和试验数据分析可知,变压器声纹信号主要为50 Hz倍频分量。针对此特点,提出50 Hz倍频小波时频熵,提高了信息的利用率和丰富程度,对变压器绕组不同程度的声纹信号具有较好的区分度,并对测点选择进行研究,选择信息程度最为丰富、稳定的2号测点用作后期算例验证。
针对变压器声纹样本多存在不平衡以及异常样本较少的问题,提出基于RUSBoost的变压器声纹运行工况模式识别,总体准确度达到98.9%,样本量较少的75%松动样本和100%松动样本的识别准确率高达97.2%和94.6%,较其他模型至少提高2.8%和2.5%。结果表明RUSBoost模型较传统模型对不平衡样本数据具有更好的准确度。
猜你喜欢
科技风(2021年19期)2021-09-07 14:04:29
电子制作(2019年13期)2020-01-14 03:15:32
通信产业报(2018年32期)2018-11-24 10:37:58
制造技术与机床(2017年10期)2017-11-28 05:20:43
大庆师范学院学报(2015年3期)2015-12-24 07:35:36
中国光学(2015年5期)2015-12-09 09:00:42
浙江大学学报(工学版)(2015年1期)2015-03-01 01:17:11
电测与仪表(2014年8期)2014-04-04 09:19:38
现代医药卫生(2014年18期)2014-03-11 19:33:26
物理学报(2011年2期)2011-10-23 12:13:54
