
基于改进SSD的视频烟火检测算法
2022-08-29 12:13王艺钢靳永强
物联网技术 2022年8期
赵 洋,王艺钢,靳永强,华 丹
(1.沈阳化工大学 计算机科学与技术学院,辽宁 沈阳 110142;(2.辽宁省化工过程工业智能化技术重点实验室,辽宁 沈阳 110142)
0 引 言
为解决目前火灾频发,消防设施和消防人员不足的问题,减少人民生命和财产安全损失,需要对火灾做出更加快速而准确的检测。目前传统的烟火检测通常借助传感器检测烟雾气体特征和火焰红外信息,这种检测方法检测精度低,响应速度慢,在智能化、抗干扰和成本等方面有待加强。基于视频的烟火检测可以很好地弥补上述不足。视频烟火检测借助摄像头传输的视频画面,检测烟火位置并提供丰富的现场状况,便于采取相应的措施,及时解决火情。
近年来,不少学者从不同的角度研究了视频烟火的检测问题。文献[4]根据人眼视觉注意机制,提出基于显著性检测和高斯混合模型的视频烟雾分割方法,提高了检测精度和速度。该算法过于依赖手工提取特征,算法鲁棒性较差,难以应用于复杂的烟火检测场景。文献[5]针对视频火灾检测算法泛化能力弱等问题,提出了一种基于ViBe和机器学习的算法,该算法依靠ViBe算法以及随机森林和支持向量机组成的两级分类器,对前景信息进行选择性提取,再结合Hu矩阵训练出决策分类器,提升检测稳定性。由于随机森林和支持向量机等算法对特征提取的能力较弱,该算法存在分类效果较差,误报率较高的问题。文献[6]利用YCrCb颜色空间对捕获的图像进行分割,使用基于分群体融合的改进FOA算法搜索SVM最优参数和惩罚因子,提升了对火灾图像的分类效果。该算法以参数量较大的元启发式算法(Meta-Heuristic Algorigthm)为基础,在检测速度上不能满足对视频实时检测的需求。上述方法主要依靠人工提取特征,算法的泛化能力不强,检测精度和速度都难以满足实时稳定检测的需求。
随着深度学习的发展,使用卷积神经网络(CNN)取代人工提取特征成为趋势,众多学者展开了将CNN应用到烟火检测中的研究。文献[7]通过CNN对火灾图像进行自动特征提取和分类,大幅提升了对烟火图像分类的精度和速度,但该算法没有深入应用到检测任务中。文献[8]提出了一种改进YOLOv3的火灾检测方法,通过改进特征提取网络和多尺度检测网络,提高了检测效果,但该算法模型尺寸较大,计算成本较高。文献[9]将SSD算法与轻量化模型MobileNet结合,对实时火灾图像进行检测,提升了算法的检测速度,降低了模型复杂度,但在检测精度上存在一定不足。上述深度学习方法在一定程度上提升了算法的检测性能,但是并没有完全平衡高检测精度、实时检测和小模型尺寸对算法的要求。
针对上述模型复杂度较高,检测速度与检测精度难以兼顾的问题,本文提出了一种基于改进SSD的视频烟火检测算法(GSSD)。首先,使用GhostNet轻量化网络模型替换SSD算法中的VGG16网络模型。相较于VGG16网络模型,GhostNet网络模型大幅度减少了模型的参数量,并在PASCAL VOC 2012数据集上具有较高的准确率。使用GhostNet网络模型可以提高算法的检测速度,减少模型的参数量。其次,在SSD算法的特征映射网络中使用多尺度特征融合技术。通过下采样和Concat拼接操作,对多尺度的特征图进行融合,以提升模型对小目标物体的检测能力。通过以上改进得到了GSSD算法,该算法有效改善了原始SSD算法检测精度不高、检测速度慢和模型参数量大的问题。在PASCAL VOC 2012数据集和自制的烟火数据集上对GSSD算法进行实验。结果表明,该算法具有更高的检测精度和速度,以及更小的模型复杂度。
1 SSD算法
SSD算法主要由骨干网络、特征映射网络和检测网络组成,其算法流程如图1所示。
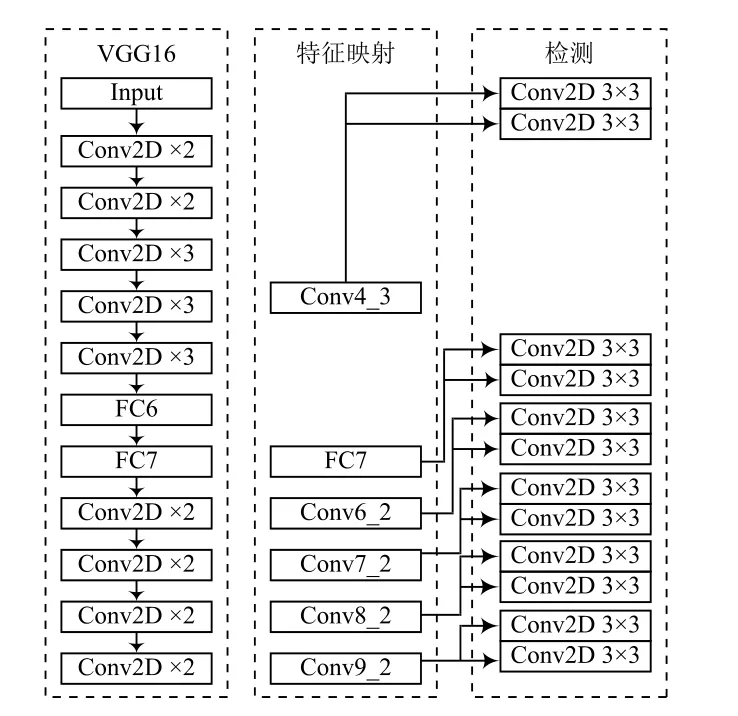
图1 SSD算法流程
SSD算法使用改进的VGG16网络模型作为骨干网络。考虑到全连接层会干扰模型对特征位置信息的提取,将VGG16网络中的两个全连接层FC6和FC7替换为3×3卷积和1×1卷积。为进一步提取特征,在FC7层后添加4组卷积层:Conv6、Conv7、Conv8和Conv9,每组卷积层首先使用1×1卷积核进行下采样,然后使用3×3卷积核进行特征提取。
特征映射网络选取若干尺寸不一的特征图,为检测提供更多的特征信息。SSD算法选用6个卷积得到的特征图为:Conv4_3、FC7、Conv6_2、Conv7_2、Conv8_2、Conv9_2。
在检测网络中,使用2个大小为3×3的卷积核对特征提取网络的6张特征图进行卷积运算,其中一个卷积核输出类别置信度,另一个为回归提供对象位置信息。所有运算结果被合并后,转移给损失计算函数,然后迭代训练直到模型收敛。
由于SSD算法采用改进的VGG16网络模型作为骨干网络,其仅仅依靠多层卷积进行特征提取,网络结构较为单一,网络模型中含有较多冗余计算。针对SSD算法的不足,本文通过相对应的改进提出了对视频烟火检测效果更优的GSSD算法。
2 GSSD
2.1 骨干网络改进
GhostNet是一种通过少量计算表征更多特征的轻量化卷积神经网络。相较于MobileNet系列和ShuffleNet系列等轻量级网络模型,GhostNet具有更高的准确率。各轻量化模型在PASCAL VOC 2012数据集上的比较结果见表1所列。由表1可知,GhostNet虽然具有较大的模型参数量,但准确率得到了大幅度提升,可以认为GhostNet相比其他轻量化模型具有一定优势。
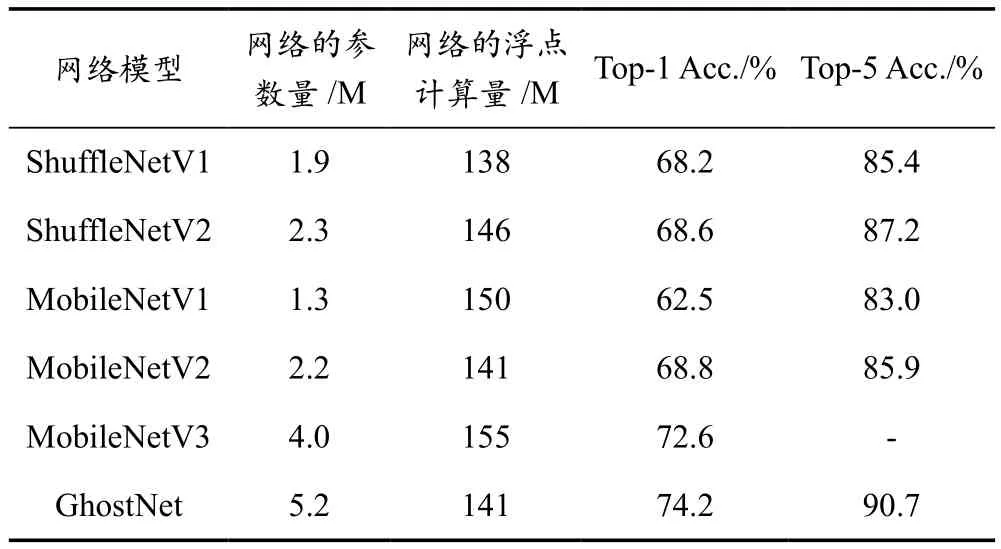
表1 在PASCAL VOC 2012数据集上各轻量化网络比较
GhostNet的核心思想是使用一系列线性运算代替部分卷积,减少推理计算量。这种结合卷积运算和线性运算的模块叫做GhostNet module,其结构如图2所示。
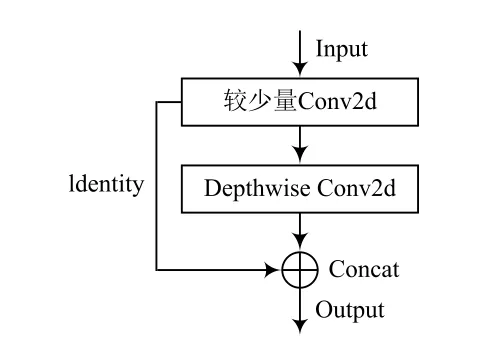
图2 Ghost module网络结构
GhostNet module将传统的卷积分为三步。首先使用较少的卷积核生成第一部分特征图;其次对该部分特征图采用深度卷积(Depthwise Convolution)运算得到第二部分特征图;最后将两组特征图通过Concat方式拼接,得到GhostNet module的运算结果。
为对比GhostNet module和VGG16中普通卷积的运算成本,分别计算所需的浮点计算量和运算时的参数量。当输入特征图的尺寸为××,输出特征图的尺寸为××,普通卷积核大小为×,通道卷积核大小为*×*,Ghost module中标准卷积数为/时,使用VGG16普通卷积的浮点计算量为:
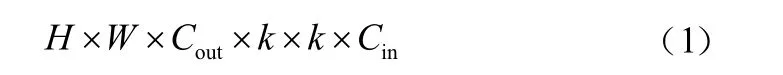
Ghost module的浮点计算量为:
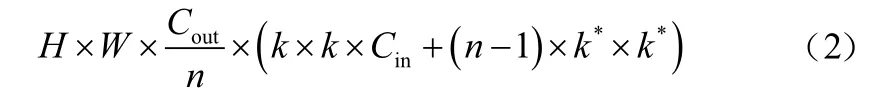
VGG16普通卷积的参数量为:

Ghost module的参数量为:
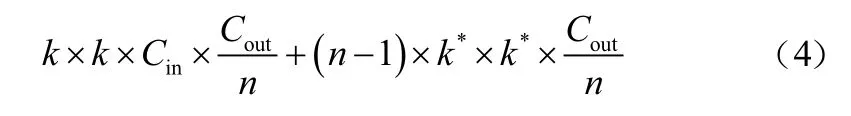
由公式(1)~公式(4)可以看出,相较于标准卷积运算,Ghost module压缩了大约倍的浮点计算量和参数量。
通过对Ghost module的堆叠,可以得到GhostNet的两种残差结构(Ghost BottleNeck),如图3所示。stride=1的Ghost BottleNeck(G1-bneck)串联 2个 Ghost module用于特征提取;stride=2的Ghost BottleNeck(G2-bneck)在2个Ghost module之间添加了步长为2的深度卷积,使G2-bneck可以用于下采样。
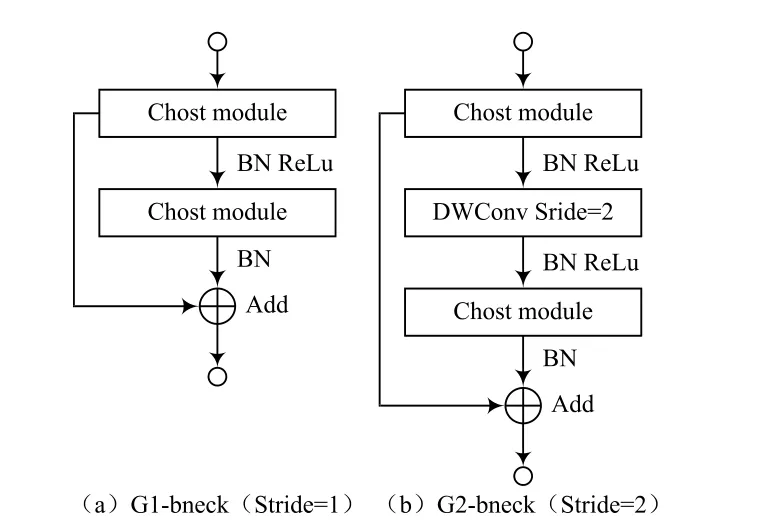
图3 Ghost BottleNeck网络结构
2.2 多尺度特征融合
深层卷积层中的小目标经过多次卷积和池化操作后,容易丢失大量的特征信息;在浅层卷积层中存在目标特征提取不足,冗余信息过多以至于干扰检测效果等问题。本文通过将浅层特征与深层特征进行多尺度融合的方式来改善。综合考虑检测精度与模型计算量,对算法进行改进,如图4所示。
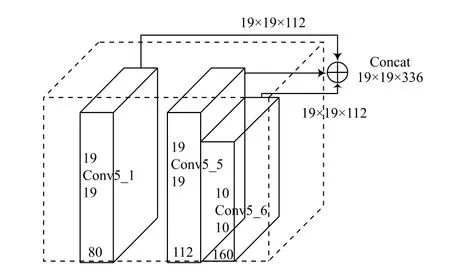
图4 特征融合示意图
多尺度特征融合分为三步。首先对Conv5_1层的特征图做卷积运算,将通道数扩张到112个;其次将Conv5_6层特征图上采样到19×19,并将特征通道数由160个降为112个;最后将Conv5_1层、Conv5_5层和Conv5_6层的特征图做Concat拼接,拼接后特征图的通道数为336个。
Conv5_1层位于网络较浅层,特征图通道数较少,拥有较多的特征信息,在与Conv5_5融合前需要对其做进一步的特征提取。为加强对Conv5_1层特征图的信息提取,采用步长为1,膨胀率为2,卷积核为3的空洞卷积进行运算。空洞卷积是一种在不做pooling损失信息的前提下,可以扩大卷积时的感受野,提高特征提取能力的卷积运算,其示意如图5所示。
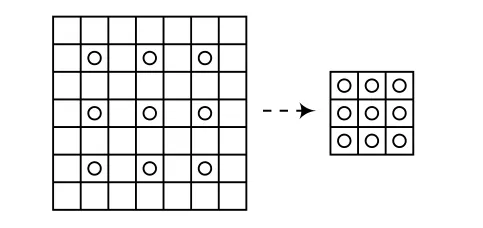
图5 空洞卷积示意图
空洞卷积的输入与输出特征图的大小关系为:
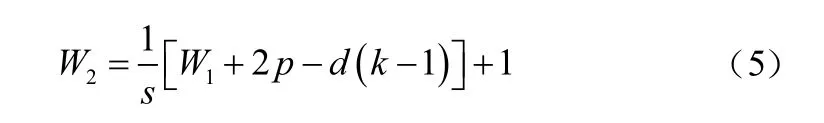
式中:为填充像素的大小;为膨胀率;为步长;为卷积核大小;为输出特征图的尺寸;为输入特征图的尺寸。
Conv5_6层位于网络较深层,特征图尺寸较小,在与Conv5_5融合前需要通过上采样增大特征图的尺寸。对Conv5_6层特征图的上采样操作选用双线性插值法。相较于转置卷积,双线性插值法不需要训练新参数,运行速度更快且操作简单,更适用于对检测速度和模型计算量有较高要求的视频烟火检测。
2.3 GSSD网络
通过对SSD算法的骨干网络以及特征融合模块的改进得到GSSD算法,该算法网络结构见表2所列。

表2 GSSD网络结构
在模型训练过程中,将Conv5_1层、Conv5_5层、Conv5_6层的输出进行特征融合,作为第一张特征图,再选取Conv6、Conv7_2、Conv8_2、Conv9_2、Conv10_2特征图。使用2个大小为3×3的卷积核对检测网络中的每个特征图进行卷积运算,分别得到类别置信度和回归信息。最后将计算结果合并传递给损失计算函数。
3 实验及结果分析
3.1 数据集
本文使用的数据集为PASCAL VOC 2012公共数据集和自制的烟火数据集。PASCAL VOC 2012数据集包含20个类别,5 717张用以训练的图片,5 823张用以验证的图片。自制的烟火数据集包含fire和smoke两个类别,8 199张图片,按照7∶2∶1的比例分配为训练集、验证集和测试集。由于自制的烟火数据集图片数量有限,为了让模型更好地学习目标特征和提高鲁棒性,需要对数据做数据增强。本文对图像进行90°、180°、270°旋转和水平翻转,如图6所示。

图6 数据增强
3.2 评价指标
本文将通过训练后模型检测的平均精度(mean Average Precision,mAP)、模型参数量(Params)和模型推理速度(FPS)做对比,其中mAP由式(6)~式(9)计算:

式中:TP为真正例;FP为假正例;FN为负正例;为种类数。
3.3 对比试验
为验证GSSD算法的检测性能,将GSSD算法与目标检测效果良好的SSD、YOLOv2、YOLOv3模型分别在PASCAL VOC 2012数据集与烟火数据集上进行实验对比,4种算法的性能测试结果见表3所列。
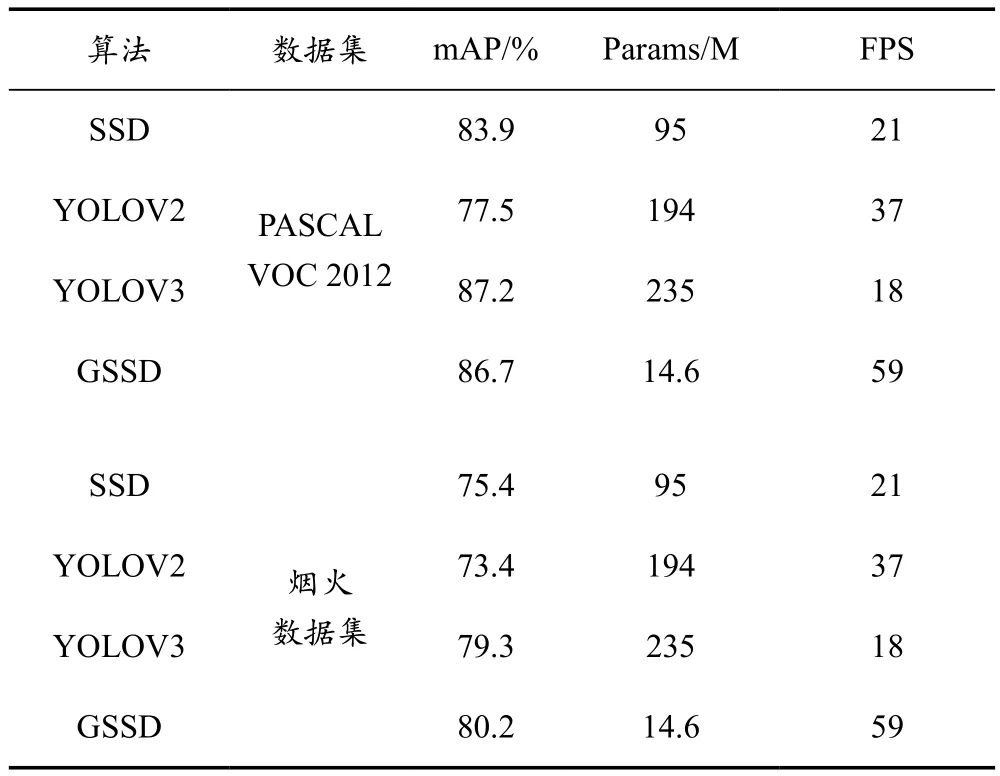
表3 GSSD算法与其他目标检测算法的比较
在PASCAL VOC 2012数据集上,相比SSD算法,GSSD算法的检测效果有较大幅度提升,mAP提高了2.8%,Params减少了84.64%,FPS提升了1.9倍。GSSD算法在SSD的基础上进行相应改进和拓展,提高目标检测的效果,显著降低了模型参数量,提升了检测速度。
与YOLO系列算法相比,GSSD比YOLOv2的mAP提高了19.2%,Params减少了92.5%,FPS提升了59%。YOLOv2算法的网络结构较为简单,仅依靠卷积层和池化层对特征进行提取,检测精度较低。GSSD算法比YOLOv3的mAP降低了0.5%,Params减少了93.8%,FPS提升了70%。YOLOv3算法使用融入残差结构的Darknet-53作为骨干网络,虽然具有比GSSD高的检测精度,但模型参数量较大,检测速度不能满足视频检测的需求。
在烟火数据集上,GSSD算法的mAP比SSD、YOLOv2和YOLOv3分别提高了4.8%、6.8%和0.9%。在4种算法中,GSSD对烟火的检测精度最高,在检测速度和模型的参数量方面具有较大优势,实验证明了GSSD算法在烟火检测中的可行性。GSSD与SSD算法对烟火数据集可视化检测对比如图7所示。

图7 对烟火检测数据集可视化结果对比
4 结 语
本文针对视频烟火难以高精度实时检测和模型参数量较大的问题,提出了GSSD算法。GSSD算法主要对SSD进行了骨干网络改进和多尺度特征融合改进。通过以上改进,GSSD算法对视频烟火检测的性能得到了提高。
在PASCAL VOC 2012数据集上GSSD算法达到了86.7%的mAP,参数量为14.6 M,FPS为59。与主流目标检测算法相比,GSSD算法具有更好的检测效果,在缩小模型尺寸的同时,检测精度与速度也有良好的表现。在自行设计的烟火数据集上,GSSD算法比SSD算法的mAP提高了4.8%,达到80.2%,参数量减少了84.64%,降为14.6 M,检测速度提升了1.9倍,FPS达到了59。下一步将在网络模型改进的基础上,针对类火类烟目标的检测进行研究,以提高算法的鲁棒性。
猜你喜欢
中学生数理化(高中版.高考数学)(2022年1期)2022-04-26
阅读(快乐英语中年级)(2021年2期)2021-04-01
数学小灵通(1-2年级)(2020年6期)2020-06-24
学生天地(2020年35期)2020-06-09
读友·少年文学(清雅版)(2019年10期)2019-05-21
电子制作(2018年19期)2018-11-14
自动化学报(2017年11期)2017-04-04
火花(2016年7期)2016-02-27
噪声与振动控制(2015年4期)2015-01-01
轴承(2010年2期)2010-07-28
