
基于遥感影像的张掖灌区作物种植结构提取研究
2022-08-28 00:36金双彦吴志勇
中国农村水利水电 2022年8期
田 鑫,何 海,金双彦,吴志勇
(1.河海大学水文水资源学院,南京 210098;2.黄河水文水资源科学研究院,郑州 450004)
0 引 言
作物种植结构信息是农业灌溉用水预测、农业产量估算、农业补贴定损和区域水资源分配的重要参考指标[1-3]。基于传统调查方式获取作物种植结构的方法由于时效性和范围性问题在实际应用中受到限制[4]。基于遥感影像的作物种植结构提取方法,因其范围广、时效性强的特点在实践应用中越来越重要[5-8]。在基于遥感影像的作物种植结构提取中,合适的分类特征和样本数量在提高作物种植结构提取精度方面起着关键的作用。
现阶段在遥感影像识别的分类特征研究中,已有研究包括基于光谱特征采用分层决策树方法提取作物种植结构[9],或基于时序NDVI 特征利用阈值法进行作物提取[10],或基于特征指数采用随机森林方法进行作物提取[11]等方面,上述分类特征与监督分类方法结合进行作物提取的研究较少,而已有关于遥感影像提取分类方法研究表明,监督分类方法通常具有更好的精度[7,12]。在样本数量的研究中,Wei H 等[13]通过生成对抗网络的方法采集数量合适的训练样本,但该方法仅适用于卷积神经网络分类;樊东东等[14]通过改善训练样本质量提高了分类精度,但缺少对样本数量的讨论;Lin Chuang 等[15]和Jingxiong等[16]仅关注训练样本空间和时间准确性对分类精度的影响。但已有研究较少关注样本数量对作物提取精度的影响。
监督分类是以概率统计理论为基础,利用采集到的各类地物训练样本,对判决函数进行训练,然后用训练好的判决函数去对其他像元进行分类[17,18]。在监督分类方法中,按分类器的不同又可细分为最小距离、最大似然、支持向量机和神经网络。监督分类中的分类器各有侧重,但支持向量机方法因提取精度较高和应用范围较广更受关注,例如张亚新等[7]和徐存东等[12]的研究中表明监督分类方法中的支持向量机提取精度更优;L Su 等[19]利用支持向量机方法进行草原干旱与半干旱研究。因此,本文主要采用监督分类中的支持向量机,作为本研究作物种植结构提取的分类方法。
甘肃张掖灌区为中度缺水地区,农业灌溉以引黑河水为主,随着当地经济的不断发展,水资源供需矛盾已成为制约当地经济发展的主要因素[20]。及时、准确的作物种植结构信息为当地农业灌溉用水预测提供数据基础,同时也为当地水资源精细化管理提供数据支撑。
基于上述分析,为探讨不同分类特征和样本数量对作物种植结构提取精度的影响,以黑河流域张掖灌区为研究区,采用监督分类中的支持向量机方法,比较分析了光谱特征和时序NDVI 特征在十组不同样本数量条件下作物种植结构提取精度的差异,得到了研究区最优的分类特征和参考样本数量。
1 研究区概况及数据来源
1.1 研究区概况
张掖灌区位于甘肃省西北部,包括板桥灌区、上三灌区和盈科灌区,总面积为1 174 km2。张掖灌区地处99°51′E~100°30′E、38°57′N~39°42′N 之间,海拔1 370~2 200 m,具有日照时间长、积温高、昼夜温差大、降雨稀少、蒸发强烈等特点,年降水量110~130 mm,年蒸发量高达1 400 mm,属中度缺水地区。研究区是重要的灌溉农业经济区,种植作物主要有玉米和蔬菜瓜果,其中玉米种植面积占作物总种植面积的80%,研究区位置见图1。
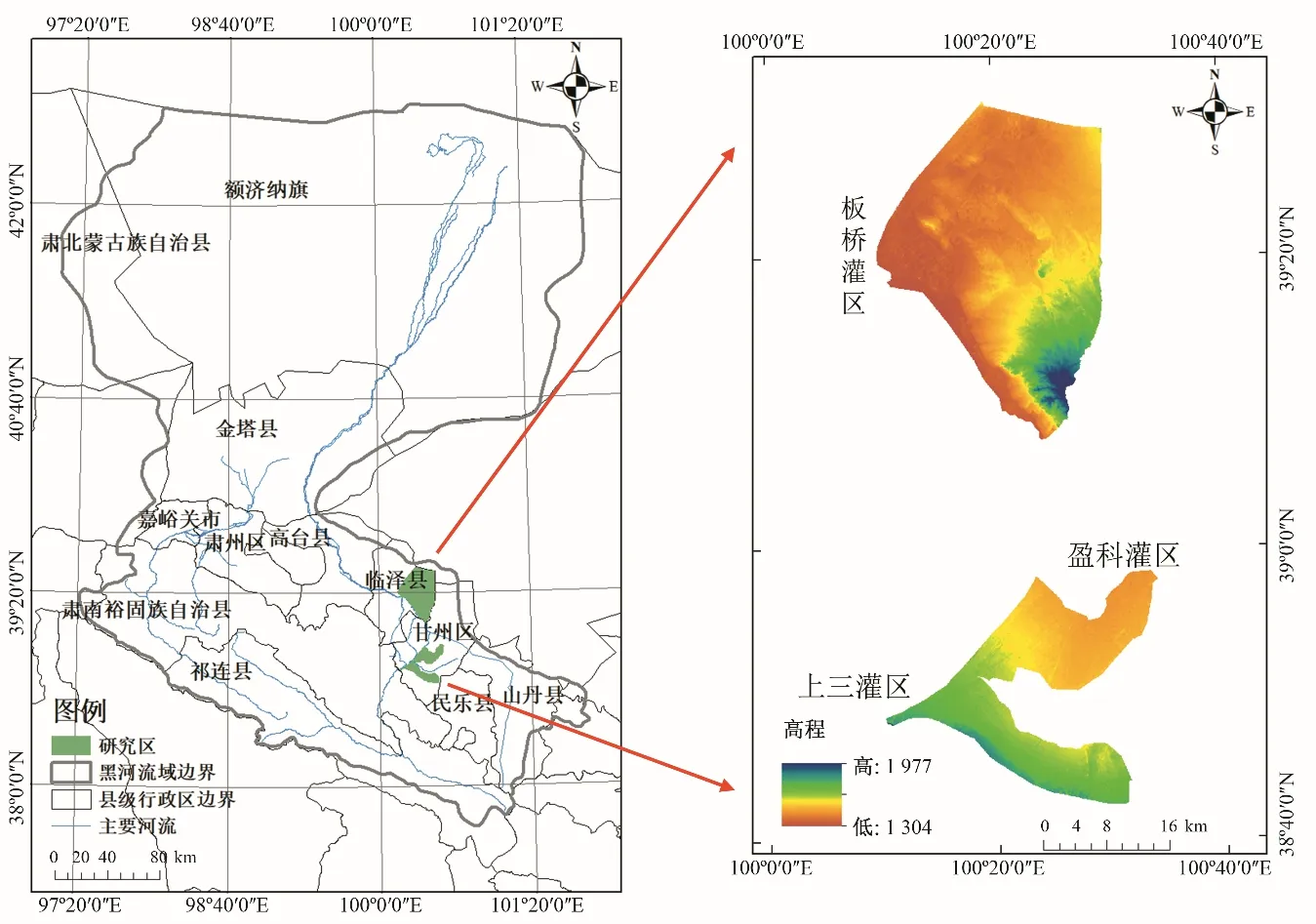
图1 研究区位置Fig.1 Location of study area
1.2 数据来源及预处理
遥感影像主要为2020年全年11 景分辨率为30 m 的Landsat8遥感影像(http://www.gscloud.cn/home)和2020年6月3景分辨率为2 m 的高分一号遥感影像(http://www.cresda.com/CN/)。研究区作物种植面积信息,主要来自实地勘察、板桥灌区、盈科灌区和上三灌区水利管理所的统计资料。
Landsat8 遥感影像预处理包括辐射定标、大气校正和影像裁剪;高分一号主要用于采集训练样本和验证样本,因此只需进行正射校正。本研究重点关注分类特征和样本数量对作物种植结构提取精度的影响问题,为保证样本精度,在样本采集中使用了厘米级国产地图作为辅助。
2 研究方法
2.1 基于光谱特征和时序NDVI 特征的监督分类方法
基于光谱特征的遥感分类,是利用亮度值或像元值的高低差异(反映地物的光谱信息)进行地物分类提取[17]。本文对遥感影像所进行的预处理中,辐射定标可以将卫星传感器记录的数字量化值转化为辐射亮度;大气校正可以消除大气分子、气溶胶散射的影响,得到真实的地表反射率数据。
研究区主要作物为蔬菜瓜果和玉米,根据当地作物物候期,两种作物分别在7月和9月成熟,其中蔬菜瓜果在7月开始收获,利于识别作物收获前后的差异。本文选择8月9日的影像进行提取,如图2(a)中光谱特征曲线所示,各地物在不同波段下具有一定差异;尤其在波段b4 至b7 之间,玉米和蔬菜瓜果之间差异显著。
遥感分类的本质是寻找不同地物间的差异[21],根据地物间差异选择不同分类方法进行地物提取,而通过特征指数可以凸显地物间差异。本文选取常用的特征指数:归一化差异植被指数NDVI(Normalized Difference Vegetation Index),该指数通过近红外(植被强烈反射)波段与红光(植被吸收)波段间的运算来区别植被,公式如下:
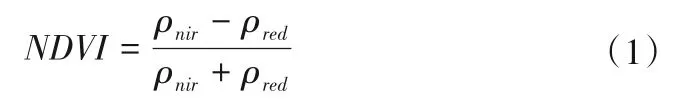
式中:ρnir为近红外波段反射率;ρred为红光波段反射率。
NDVI 取值范围为(-1,1),由于遥感影像中可能存在一些异常区域,使计算的NDVI 值产生异常,需要对计算后的NDVI值进一步修正,小于-1 异常值赋予0,大于1 异常值赋予0.8,修改后的NDVI 特征曲线能够更加准确地反映地物真实情况,公式如下。
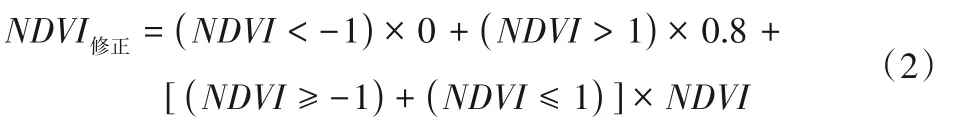
有研究指出时序NDVI 有助于提高作物种植结构的提取精度[22],本文通过2020年全年11 景Landsat8 影像构建时序NDVI特征指数,玉米和蔬菜瓜果在8月至10月区分度很高,同时作物的NDVI 变化符合研究区作物8月至10月收获的情况,且其他地物在8月至10月也易于区分[见图2中(b)]。
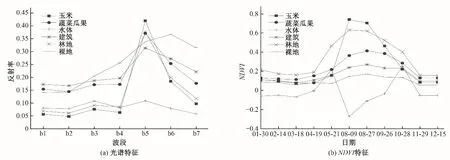
图2 研究区不同地物的反射率和NDVI特征曲线Fig.2 Reflectance and NDVI characteristic curves of different ground features in the study area
2.2 基于不同样本数量的监督分类
样本是遥感地物分类的基础[13],在监督分类中,只有在对样本类别属性有先验知识的前提下,才可以进一步分析不同地物特征并进行分类。
因此本研究基于2 m 分辨率的高分一号采集样本,选择支持向量机分类方法,比较光谱特征和时序NDVI 特征在十组不同样本数量条件下的提取精度,分析两种分类特征条件下样本数量对作物种植结构提取精度的影响程度。
根据收集的研究区下垫面资料,将地物分为六类:玉米、蔬菜瓜果、水体、建筑、林地和裸地。在样本采集中,主要侧重于作物信息。本文共采集10 组训练样本,其中每组样本均包含3个灌区的数据,总个数从72~720 个不等。此外,本文以第五组条件下采集的检验样本为各组的验证样本,保证每组验证时的样本相同。样本详情见表1,其总体空间分布见图3。
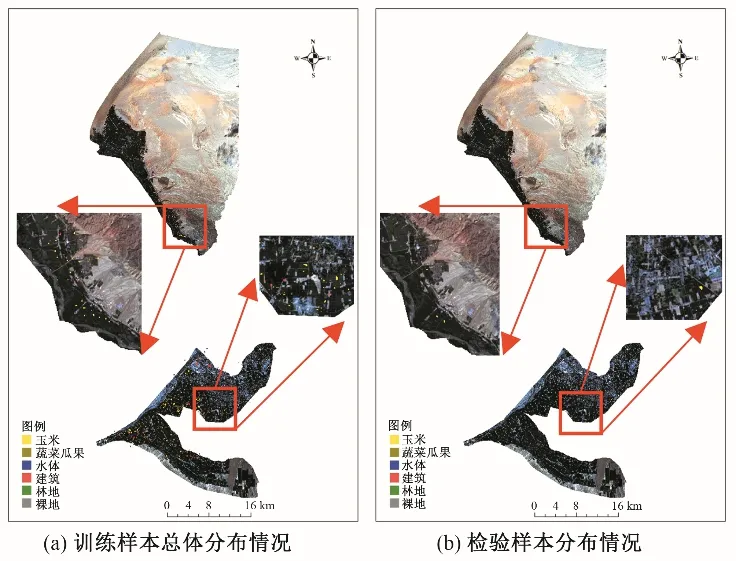
图3 样本空间分布Fig.3 Spatial distribution of samples
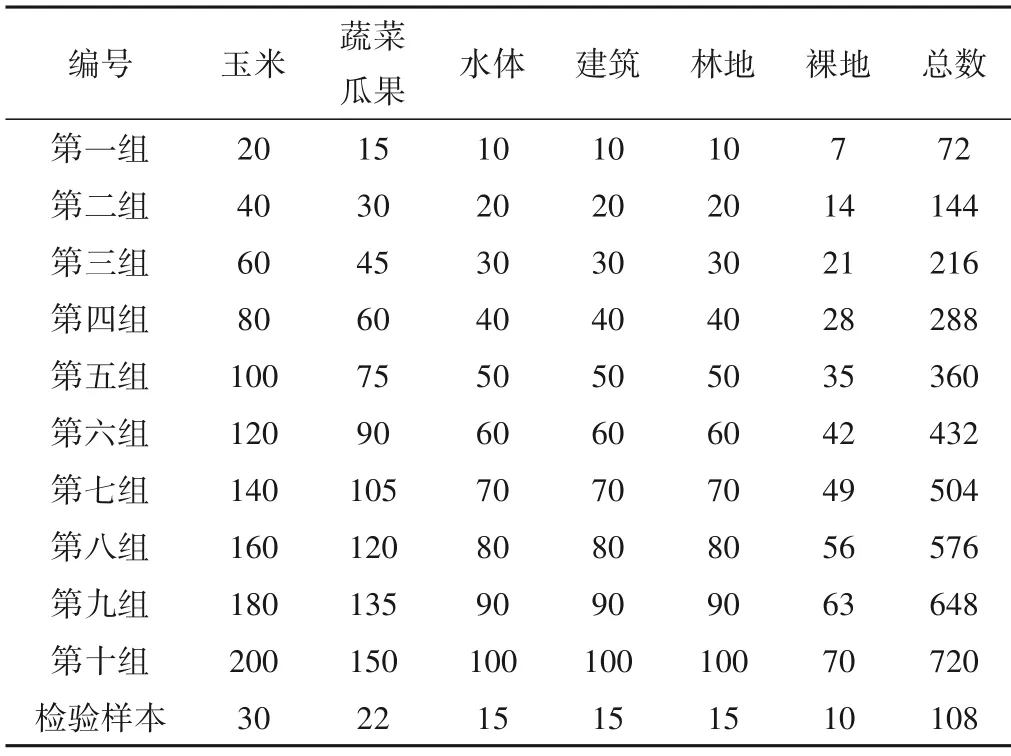
表1 10组训练样本数量及检验样本数量 个Tab.1 Number of training samples in ten groups and verification samples
2.3 精度评价指标
本研究采用面积验证和混淆矩阵验证两种方法对分类结果进行精度评价。
面积验证是比较研究区实际地物面积与提取地物面积,在本研究中主要关注玉米和蔬菜瓜果两种地物。
混淆矩阵是通过验证样本像元位置与分类图像中相应位置的比较计算得到的。主要评价指标为总体分类精度(Overall Accuracy)和Kappa系数,计算公式如下:

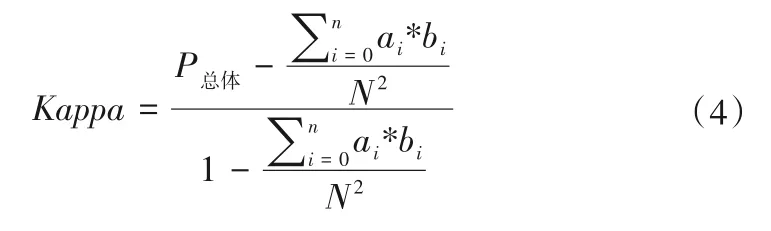
式中:POA为总体分类精度;xi为n类地物中被正确分类的像元总和;ai为n类地物的真实样本像元数;bi为样本中被归为n类地物的像元数;n为分类结果总类别数;N为样本像元总数。
总体分类精度表征样本的地物类型与分类结果中地物类型的相似情况。Kappa 系数用于衡量分类结果和样本的一致性,取值范围为(0,1),大于0.75表示高度的一致性[18]。
3 结果与分析
3.1 识别结果分析
根据现场收集的研究区下垫面信息,板桥灌区北部主要为裸土,南部主要为作物种植区且有河流经过;上三灌区与板桥灌区相似;盈科灌区北部为城市群,但蔬菜瓜果主要集中于该灌区。
基于光谱特征支持向量机提取的作物种植结构空间分布如图4所示,其中图4(a)到图4(j)为板桥灌区在10组不同样本数量条件下的提取结果。通过与收集的下垫面信息比较发现,随着训练样本数量的增加,图4(a)到图4(j)识别的空间分布逐渐稳定。相比其他地物,玉米整体空间分布更加准确;图4(a)和图4(b)中识别建筑空间分布有误。图4(k)到图4(t)为上三灌区和盈科灌区的结果,总体上玉米识别的空间分布更加准确,但蔬菜瓜果的识别变化较大。具体来看,图4(m)到图4(q)蔬菜瓜果识别的空间分布更为准确,图4(k)、图4(l)和图4(r)到图4(t)中有将蔬菜瓜果错误识别为其他地物现象。
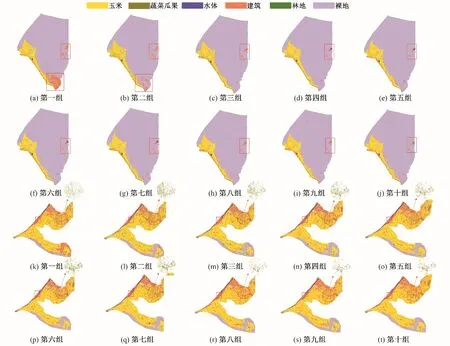
图4 基于光谱特征支持向量机在10组不同样本数量下的分类结果Fig.4 Classification results of support vector machine based on spectral features under ten groups of different samples
基于时序NDVI 特征支持向量机提取的作物种植结构空间分布如图5所示,其中图5(a)到图5(j)为板桥灌区的提取结果,通过与收集的下垫面信息比较发现,图5(f)和图5(g)中玉米识别的空间分布相比其他组更为准确,图5(b)到图5(e)中林地识别的空间分布更稳定,其中图5(e)识别的建筑空间分布比基于光谱特征识别结果更为准确。图5(k)到图5(t)为盈科灌区和上三灌区,玉米整体识别的空间分布较为准确;但蔬菜瓜果识别的空间分布有所变化,从图5(k)到图5(q)可以明显看到蔬菜瓜果识别从开始的零星区域逐渐扩大,在图5(p)和图5(q)达到稳定状态,同时,水体周边的裸地识别准确性要优于基于光谱特征的识别结果。
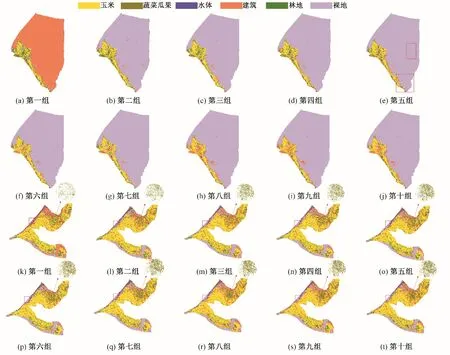
图5 基于时序NDVI特征支持向量机在10组不同样本数量下的分类结果Fig.5 Classification results of support vector machine based on temporal NDVI features under ten groups of different samples
分析上述两种分类特征的识别结果,发现不同样本数量条件下的识别结果整体上有一个清晰的变化趋势,即随着样本数量的增加,识别的作物种植结构空间分布准确性也在逐渐增加直至稳定状态。但是也能清晰看到不同分类特征提取结果的差异,在基于时序NDVI 特征的提取中,玉米、蔬菜瓜果和林地识别的空间准确性优于基于光谱特征的识别结果。
3.2 面积验证分析
根据收集的研究区下垫面作物种植面积资料,与两种分类特征提取下的作物种植面积进行比较。表2为基于光谱特征下的作物面积提取结果,可以看到玉米的识别面积整体大于实测面积,识别的误差有先降低后增大的趋势,其平均误差为23.63%,第三组误差最小,为19.99%;相比玉米,蔬菜瓜果识别面积误差较大,误差并没有随着训练样本数量的增加而减小,其平均误差为74.18%;各组当中,第二组至第四组误差相对较小,第二组最小,为53.73%。
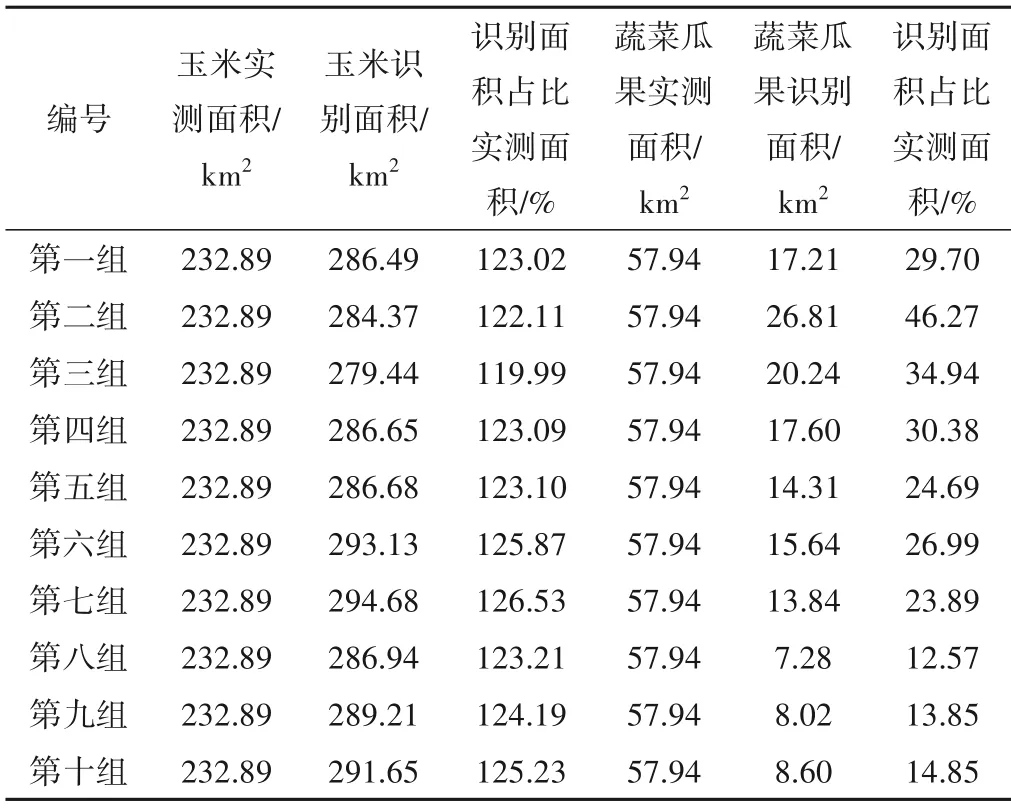
表2 基于光谱特征支持向量机作物面积识别结果Tab.2 Crop area recognition results based on spectral feature support vector machine
基于时序NDVI特征下的作物面积提取结果见表3所示,总体来看,玉米和蔬菜瓜果的各组相对误差并无显著区别;但与基于光谱特征的识别结果相似,玉米的识别精度明显更高。平均误差仅为3%,第二组、第三组和第六组表现最佳,其中第三组识别误差仅为0.17%。而蔬菜瓜果面积识别的平均误差为32.19%,较上一方法更为准确,其第五组至第七组误差最小,第六组误差仅为12.95%。

表3 基于时序NDVI特征支持向量机作物面积识别结果Tab.3 Crop area recognition results based on temporal NDVI feature support vector machine
为了更直观的比较两种分类特征下作物提取的面积结果,图6 展示了不同组间的折线图。玉米和蔬菜瓜果提取的面积中,基于时序NDVI 特征的提取结果均表现较优,因此可以认为,在作物种植结构提取的面积验证中,基于时序NDVI 所提取作物结果优于光谱特征提取作物结果。
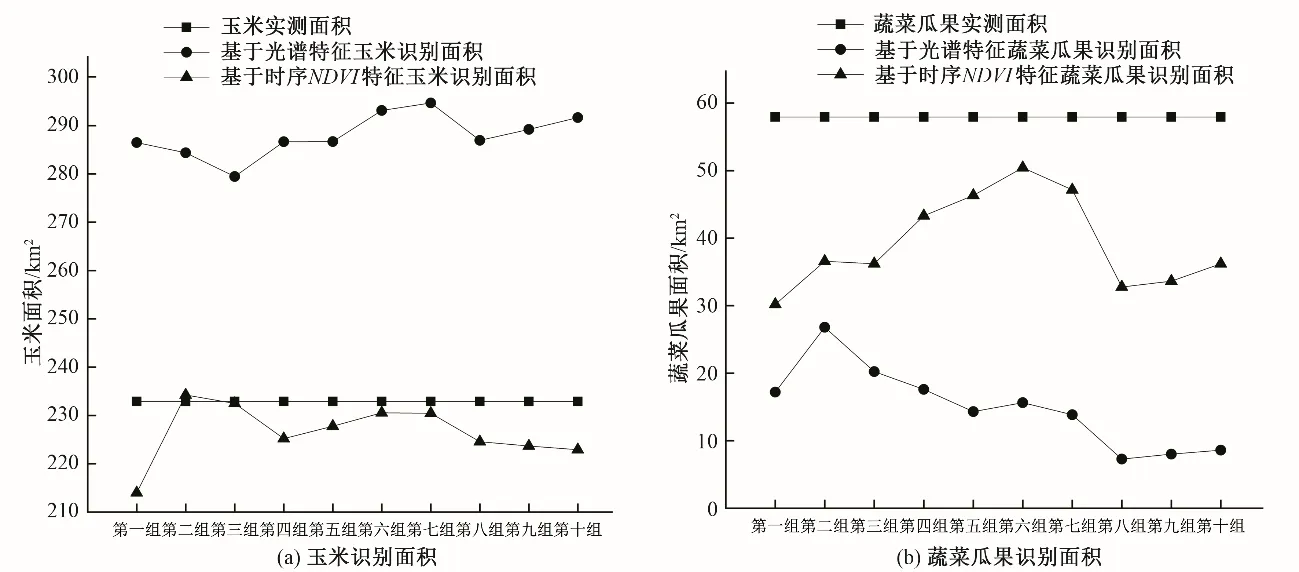
图6 两种分类特征下作物面积识别结果Fig.6 Area of the crops extracted through different features
3.3 混淆矩阵验证分析
基于光谱特征条件下不同样本数量的混淆矩阵验证结果见表4,总体分类精度与Kappa 系数变化趋势相同,都是先增高后降低,平均总体分类精度为78.9%,平均Kappa 系数为0.73,其中第七组分别达到最大值80.4%和0.75。
基于时序NDVI特征下混淆矩阵的结果见表4,该特征分类结果变化较大,平均总体分类精度为84.8%,平均Kappa 系数为0.81,其中总体分类精度从第一组先增加,至第三组达到最大值87.6%,然后开始降低至第七组,第八组和第九组再增大,至第十组又开始降低;Kappa系数则是从第一组开始增至第三组,达到最大值0.84,第四组降低后又再次达到最大值,然后降低至第七组,第八组和第九组再增大,至第十组降低。
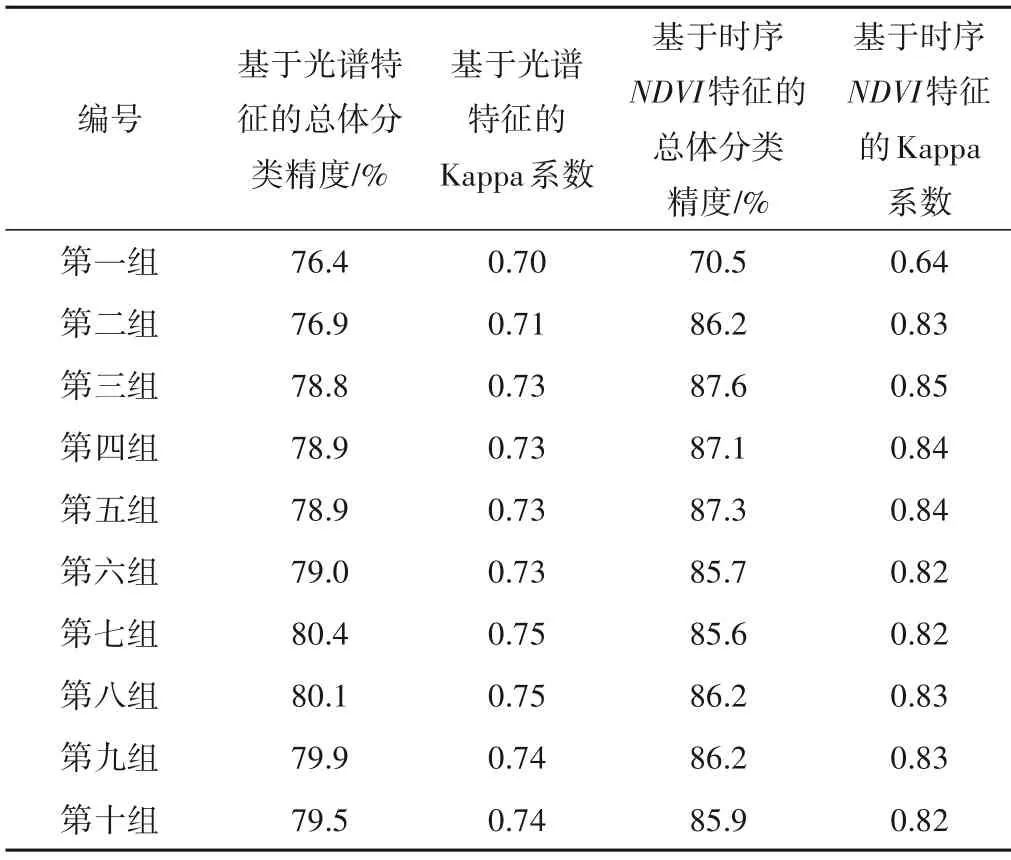
表4 基于光谱特征和时序NDVI特征的支持向量机混淆矩阵验证Tab.4 Confusion matrix verification of support vector machine based on spectral features and temporal NDVI features
图7 展示了两种分类特征下混淆矩阵验证结果,除第一组外,基于时序NDVI特征的混淆矩阵评价指标均高于光谱特征的评价指标,同时,基于时序NDVI特征的总体精度最高达87.6%,表示样本地物类型与识别结果中地物类型相似性高,Kappa 系数从第二组开始均大于0.75,表示识别结果与样本的具有高度的一致性。

图7 两种分类特征下混淆矩阵比较Fig.7 Comparison of confusion matrices through different features
3.4 两种特征和样本数量对提取结果的影响
在对基于光谱特征和时序NDVI特征提取结果的精度评价分析中,基于时序NDVI特征提取结果整体精度优于光谱特征提取结果。但基于光谱特征的提取方法相对更加简洁、迅速,只需针对作物光谱特征差异显著的一景遥感影像即可完成。若对提取精度要求不高,则该方法也能满足一些作物提取工作。基于时序NDVI特征的提取则要求作物关键物候期影像或全年的遥感影像,但该方法提取的精度要明显优于光谱特征提取精度。基于时序NDVI特征相较于光谱特征的总体分类精度平均提高5.9%,Kappa系数平均提高0.08。
在作物种植结构的提取中,对分类规则的要求更高,不仅要识别地物是否是耕地,还需要识别耕地中具体是哪种作物,因此需要更加凸显作物差异的特征进行提取,时序NDVI特征正是加强了作物间的差异,提取结果才更优。
在对不同样本数量提取结果的精度评价分析中,样本数量对提取精度具有一定影响。基于光谱特征中样本数量在第七组(样本总数504个)表现最佳,基于时序NDVI特征中样本数量在第三组(样本总数216 个)及第五组(样本总数360 个)表现最佳,综合两种特征,样本数量在第五组(样本总数360个)至第七组(样本总数504个)表现较佳。
不同样本数量的提取结果,在精度验证中表现出先升高后降低的变化趋势。样本数量超过阈值后不仅不会提高分类器的训练效果,还会产生一定的干扰。本文是在30 m 分辨率的Landsat8 影像上进行识别的,而Landsat8 的获取则受到卫星传感器、天气、辐射等因素影响,虽然本文进行一些处理尽量消除这些因素的影响,但是局部依然存在一定干扰[23],这些干扰会影响到采集样本的训练,无法使分类器得到更加精准的分类规则。
4 结 论
本研究通过分类特征与样本数量对作物种植结构提取精度的影响分析,基于监督分类的支持向量机方法,比较了张掖灌区光谱特征和时序NDVI 特征下不同样本数量的提取结果,得到如下结论:
(1)在十组不同样本数量下提取的作物分布图中,随着样本数量的增加,识别作物的空间分布准确性也在逐渐增加直至稳定状态。
(2)基于时序NDVI 特征提取的作物种植结构精度优于光谱特征提取的精度,时序NDVI 提取的玉米面积平均误差为2.82%,平均总体分类精度为84.8%,平均Kappa 系数为0.81,其中面积误差最小仅为0.17%,总体分类精度最高达到87.6%,此时Kappa系数也达到最高0.84。
(3)结合两种精度验证结果及研究区面积信息,可以得出研究区每10 km2的样本数量为3~4 个时,样本能够保持最佳的训练效果,即S = 0.3A~0.4A,其中S 为样本总数,A 为研究区面积,单位为km2。
监督分类因其更加高效而受学者青睐,而监督分类中的支持向量机方法因提取精度较高和应用范围较广更受关注,本文对影响支持向量机提取精度的因素分析,可为监督分类提取精度的进一步优化提供参考。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
导航定位学报(2022年5期)2022-10-13
农业工程学报(2022年8期)2022-08-08
小猕猴智力画刊(2022年3期)2022-03-28
农业工程学报(2022年1期)2022-03-25
意林·作文素材(2021年23期)2021-01-22
科学24小时(2019年6期)2019-09-05
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
光学仪器(2016年6期)2017-04-24
电子技术与软件工程(2016年24期)2017-02-23
