
改进的Faster R-CNN算法在数码印花织物缺陷检测中的应用
2022-08-27 02:27苏泽斌武静威李鹏飞
西安工程大学学报 2022年4期
苏泽斌,武静威,李鹏飞
(西安工程大学 电子信息学院/陕西省人工智能联合实验室,陕西 西安 710048)
0 引 言
数码印花机目前在纺织行业已经得到越来越广泛的应用,使印花行业更加环保、科技,进一步提升了纺织品的附加值[1]。但是,针对印花织物的成品检测主要还是由人工完成。依靠人工检测不仅效率低,还存在极大的漏检、误检率,而且数码印花产品色泽丰富,种类繁多,人工检测已经不能完全适应印花产品的质量检测。数码印花过程中因喷孔堵塞、导带黏度下降、电机步进偏差、蒸箱漏水等问题,使产品出现PASS track、PASS tracks、漏墨、留白、重影、绒毛、漏水以及浆瘢等缺陷,生产成本大幅提升。在数码印花过程中,织物缺陷检测有利于监测印花机异常工况,减少缺陷产品的产生,提高生产效率。
随着机器视觉技术的快速发展,许多研究人员将其应用于纺织品缺陷检测中[2-4],主要包括基于统计[5-8]、基于频谱[9-11]和基于模型的方法[12-13]。传统的图像处理方法在白坯布以及背景单一的纯色织物上具有较好的检测结果,但是对于数码印花图像来说,其本身图案背景丰富多样,缺陷类型难以判别,上述方法已经难以完全满足实际检测需求。
近年来,深度学习已经广泛应用于工业检测领域[14-16],在织物缺陷检测领域也已经开展了大量的研究。陈雪阳等提出了一种融合主结构提取和多尺度线性滤波的疵点检测方法,可检测多种织物疵点,且检测精度较高[17];陈梦琦等提出一种融合注意力机制的Faster R-CNN织物疵点检测算法,提高了检测模型的鲁棒性和准确率[18]。JING等提出了基于Mobile-Unet的织物缺陷检测模型,利用轻量级网络MobileNetv2作为Unet网络的编码器,降低了模型的参数量和计算量,在保证织物缺陷检测精度的前提下,提高了织物缺陷检测的效率[19];LIU等结合分割网络和生成对抗网络(GAN),使模型拥有适应未知缺陷类型的能力[20];PENG等提出了先验锚卷积神经网络(PRAN-Net),提高了织物缺陷的定位精度[21];ZHU等提出了一种改进的 DenseNet 模型,以更好地适应资源受限的边缘计算场景[22];张宏伟等提出了一种基于生成对抗网络的色织物缺陷检测方法,通过重构图像与原图之间的残差分析实现色织物的缺陷区域检测与定位[23]。上述方法在常规织物缺陷数据集上取得了高准确率的检测精度,而在实际数码印花中由于设备的影响使得获取的数据存在严重的类别不均衡,导致现有检测模型精度难以进一步提高。
本文采用了在缺陷检测领域具有高质量表现的Faster R-CNN[24]作为检测网络框架,并通过引入ACSL[25]模块,自适应地调整每个样本在不同类别位置分类损失的权重系数,避免头类别(出现频率较高的类别)对尾类别(出现频率较低的类别)的支配作用,进而提高算法的检测精度。
1 Faster R-CNN
Faster R-CNN作为两阶段检测器,其模型的通用性和鲁棒性得到了研究人员的广泛好评。本文选择Faster R-CNN作为检测的基础框架,具体的网络结构如图1所示。
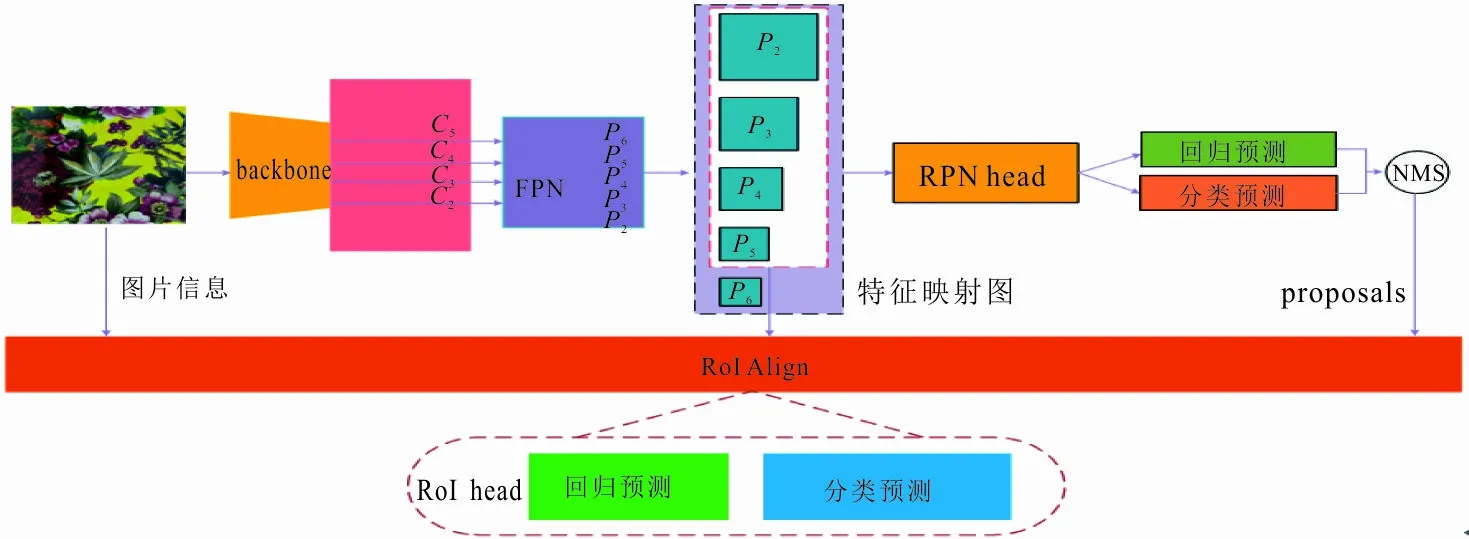
图 1 Faster R-CNN的网络结构Fig.1 Network structure of Faster R-CNN
从图1可以看出,输入的缺陷图像经过骨干网络(backbone)进行特征提取,得到下采样比例依次为4、8、16和32特征映射图,编号为C2、C3、C4和C5;将它们输入到特征金字塔网络(feature pyramid network, FPN)进行多尺度特征融合,使得底层特征映射图拥有顶层特征映射图的强语义信息,并得到下采样比例依次为4、8、16、32和64的特征映射图,编号为P2、P3、P4、P5和P6;接着,将它们输入到区域生成网络(region proposal network, RPN),为生成高质量的proposals提供注意力(其中,RPN基于先验的尺寸和比率,在每一个滑动窗口中平铺k个anchors);然后,利用Intersection over Union(IoU)阈值和随机采样的方式筛选出高质量的anchors参与训练,并将RPN生成的proposals映射到P2、P3、P4和P5特征映射层;最后,利用RoI Align,将proposals映射到特征映射图并固定区域7×7,输入到全连接网络,进行分类和回归任务。proposal的特征提取层计算方法可表示为
(1)
式中:s表示proposal的面积;smin表示proposal划分超参数。
2 改进的检测模型
2.1 基于自适应类别抑制损失的结构
本文提出的改进模型在训练过程中不断平衡对头类别(出现频率较高的类别)、中间类别(出现频率中等的类别)和尾类别(出现频率较低的类别)的关注,提高了算法的检测精度。在Faster R-CNN网络引入的自适应抑制损失结构,如图2所示。
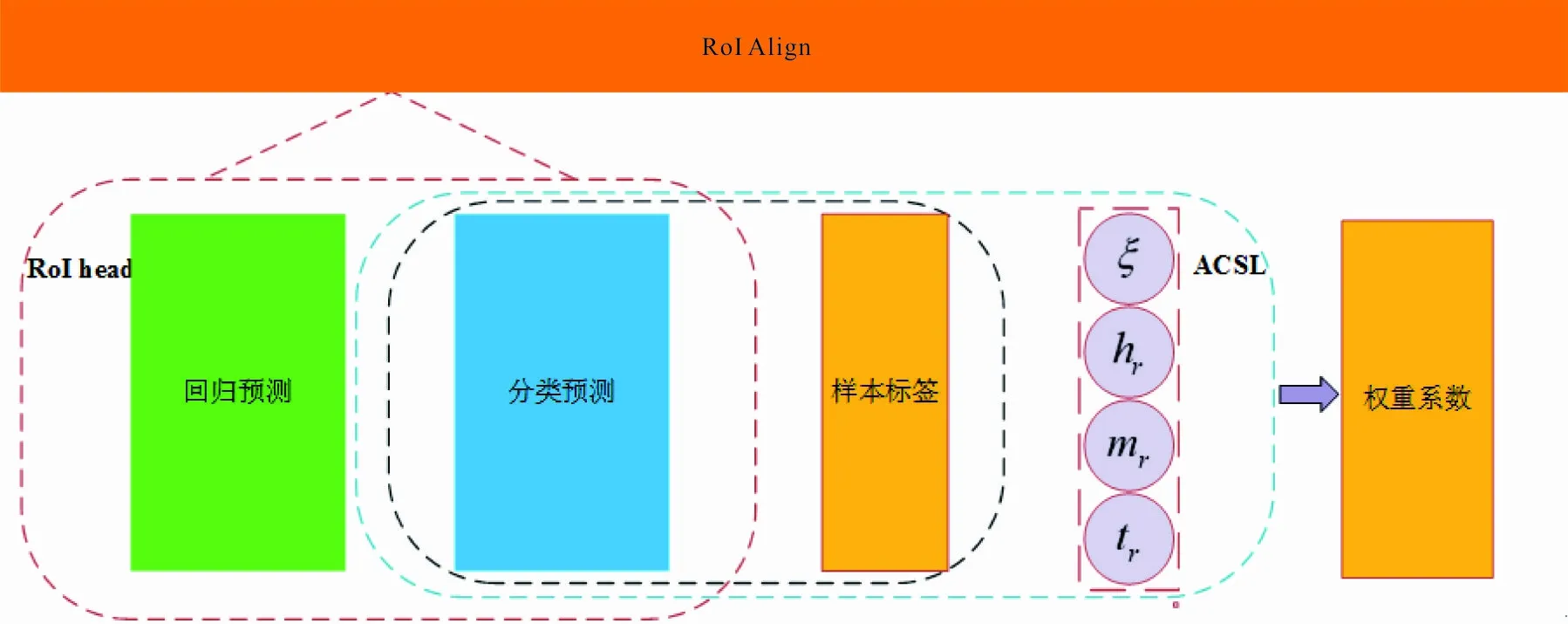
图 2 改进后的损失结构Fig.2 Improved loss structure
图2中,Faster R-CNN为每个proposal分配好标签信息的基础之上,通过引入置信度阈值ξ、头类别位置的采样抑制比率hr、中间类别位置的采样抑制比率mr和尾类别位置的采样抑制比率tr,自适应地调整每个proposal在不同类别位置二元交叉熵损失函数的权重系数,缓解模型对尾类别位置二元交叉熵损失函数长期负激活的现状并且提高模型对头类别位置二元交叉熵损失函数负激活的比例,最终使得不同类别位置二元交叉熵损失函数正激活和负激活的数量差异得到缓和,提高模型对类别样本分布不均衡数据集的泛化能力。
2.2 二元交叉熵损失函数
设二元交叉熵损失函数在目标检测任务中,头类别x的proposalY,one-hot编码是Z,则zx=1并且zi=0(i≠x),通过sigmoid 函数可获得其类别位置i的预测置信度pi,sigmoid函数可表示为
(2)
式中:si表示网络对于类别位置i的输出逻辑。二元交叉熵损失函数可表示为
(3)
(4)
式中:C为类别总数;i=0对应背景类别。
头类别x的proposalY在其他类别位置(i≠x)二元交叉熵损失函数的负激活将迫使算法降低其预测置信度pi,在一定程度上有助于算法的训练;然而,由于头类别、中间类别和尾类别样本数量的严重失衡,往往导致尾类别位置的二元交叉熵损失函数长期处于负激活状态,正激活数量和负激活数量严重失衡,最终造成算法对尾类别的检测效果不佳。
2.3 自适应类别抑制损失(ACSL)
ACSL模块的提出源于以下思考:1)由于头类别和尾类别样本数量的显著差异,导致尾类别的proposals在头类别位置的预测置信度偏高,所以应该对proposals容易误检类别位置的二元交叉熵损失函数进行负激活,使得算法保持判别不同缺陷类别能力,同时降低了尾类别位置二元交叉熵损失函数负激活的频率,以此维系尾类别位置二元交叉熵损失函数正激活和负激活的数量平衡,进而缓解尾类别位置二元交叉熵损失函数长期负激活的现状;2)由于头类别和尾类别样本数量的显著差异,应当在proposals为背景类别时,根据不同缺陷类别样本数量的分布情况,对头类别、中间类别和尾类别位置二元交叉熵损失函数负激活的数量进行差异调整,即增加模型对于头类别二元交叉熵损失函数负激活的频率,适当减少模型对于尾类别二元交叉熵损失函数负激活的频率,使得不同缺陷类别位置二元交叉熵损失函数正激活和负激活的数量差异得到缓和,进而提高模型对长尾分布数据集的泛化能力。

(5)
其中,
(6)
合适的置信度阈值ξ可使模型保持缺陷判别能力,同时降低尾类别位置二元交叉熵损失函数负激活的频率,维系了尾类别位置二元交叉熵损失函数正激活和负激活的数量平衡,提高了模型的检测精度。当proposals为背景类别时,ACSL模块利用不同缺陷类别样本的分布情况,设定头类别、中间类别、尾类别位置二元交叉熵损失函数的采样抑制比率分别为hr、mr、tr,并分别对背景类别proposals进行采样,即增加模型对于头类别二元交叉熵损失函数负激活的频率,适当减少并缓解模型对尾类别二元交叉熵损失函数负激活的频率,以及长期负激活现象,提高头类别位置的二元交叉熵损失函数负激活的比例,使得不同缺陷类别位置二元交叉熵损失函数正激活和负激活的数量差异得到缓和,提高模型的检测精度。
3 结果与分析
3.1 数据集的制作与分析
数码印花的过程中会存在喷孔堵塞、导带黏度下降、电机步进偏差、后处理蒸箱漏水等工况,同时还存在坯布本身质量问题。以上情况会导致印花产品出现PASS track、PASS tracks、漏墨、留白、重影、绒毛、漏水以及浆瘢等缺陷,如图3所示。

(a) PASS track (b) PASS tracks (c) 漏墨 (d) 留白

(e) 重影 (f) 绒毛 (g) 漏水 (h) 浆瘢图 3 数码印花织物缺陷样例Fig.3 Examples of digital printing fabric defects
实验数据集来自于自建的数码印花织物缺陷检测数据集。数据集包括10 320幅印花图像,在实验过程中,将每类缺陷图像分为3部分,即80%作为训练集,10% 作为验证集,10%作为测试集。
根据不同缺陷类别样本参与模型训练的数量,可以发现此数据集存在类别样本分布不均衡的特点,具体类别样本分布如图4所示。

图 4 类别样本分布Fig.4 Distribution of class samples
类别样本分布不均衡会导致以往先进的目标检测算法在训练过程中不断增强对头类别(PASS track、漏墨和绒毛)的学习,而不是中间类别(PASS tracks、留白、重影和漏水)和尾类别(浆瘢),最终造成算法检测精度不理想。
3.2 实验条件和评价指标
实验采用的硬件配置为Intel E5-2680v3 处理器(2.5 GHz)、128 GiB内存和 1 个 NVIDIA GeForce 2080 Ti。除此之外,骨干网络的初始化权重从COCO2017数据集上的训练模型迁移而来,所有其他权重通过“Xavier”范例进行初始化。在微调过程中,将max-epoch固定为30,并使用SGD作为优化器,将其基本学习率设置为0.001,权重衰减设置为 0.000 1,动量常数设置为0.9,批量大小设置为 4。对于所有实验, 采用COCO指标中的平均精度(AP、AP50、AP75、APS、 APM、APL) 来评估模型检测性能。
3.3 与其他先进模型的性能比较
为了客观评价模型的检测性能,采用2种不同的骨干网络(ResNet50和ResNet101)和相同的实验条件,性能比较结果如表1所示。
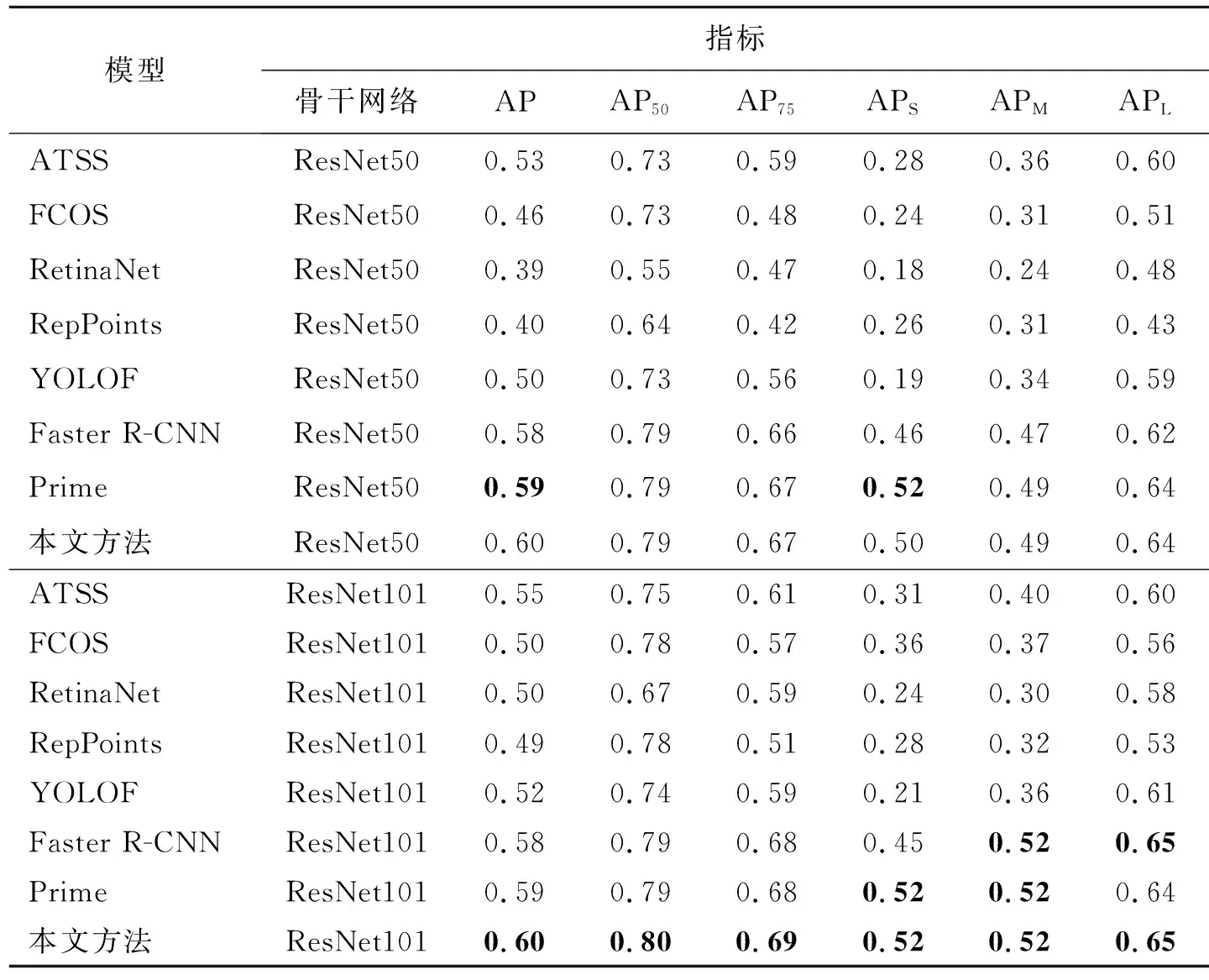
表1 与其他模型的性能比较Tab.1 Performance comparison with other models
表1中,指标最优值以黑体显示。可以看出,与其他先进模型相比,选用骨干网络为ResNet50时,本文提出的模型在最综合反应模型整体检测精度的AP指标上比最优模型提升了0.01,在AP50、AP75、APS、APM、APL指标上具有最高的检测精度;选用骨干网络为ResNet101时,与其他先进模型相比,本文提出的模型在AP、AP50、AP75指标上均提高了0.01,并且在APS、APM、APL指标上持平,说明本文提出的模型有助于缓解由数码印花织物缺陷检测数据集类别样本分布不均衡引起模型检测精度不理想的状况。
3.4 消融实验
在验证ACSL模块作用时,引入了2组超参数ξ和(hr、mr、tr),其中ξ为置信度阈值,hr、mr、tr分别为头类别、中间类别和尾类别位置二元交叉熵损失函数的采样抑制比率。消融实验中,先固定超参数(hr、mr、tr)再来寻找最优的超参数ξ;然后,固定最优的超参数ξ,验证超参数(hr、mr、tr)对于模型检测精度增益的作用。
为了探究非背景类别的proposals在各个类别位置二元交叉熵损失函数负激活对于模型精度增益的作用,需要确定一个最优的超参数ξ。为了验证超参数ξ对模型检测精度的影响,通过前期的分析,本文固定超参数(hr=1,mr=1,tr=1),此时可看作ACSL模块只作用于非背景类别的proposals,超参数ξ采用6个备选数值(0、0.1、0.3、0.5、0.7、0.9)。超参数ξ的性能分析结果如表2所示。
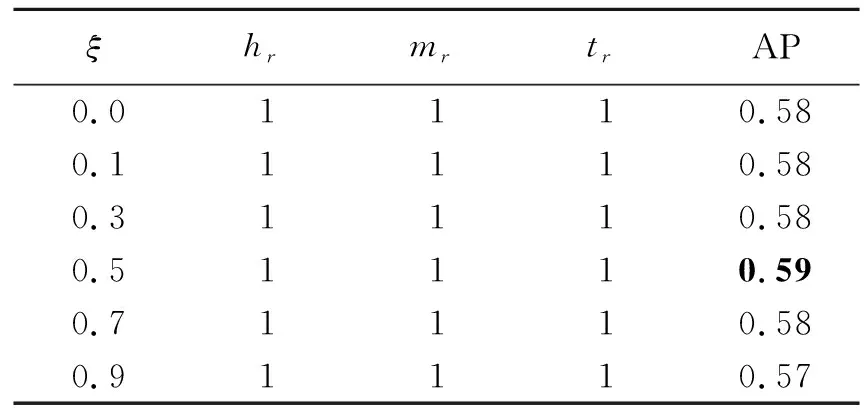
表2 超参数ξ的性能分析Tab.2 Performance analysis of hyperparameterξ
表2中,当ξ为0时是基本的Faster R-CNN检测模型;当ξ由0变化为0.5,模型的检测精度增加,且在ξ=0.5时,模型达到了最佳的检测精度;当ξ由0.5变化为0.9时,模型的检测精度不断下降。可以看出合适的超参数ξ能够缓解模型在训练时期对尾类别位置二元交叉熵损失函数过度负激活的问题,并相对提高了模型对于容易误检类别位置二元交叉熵损失函数负激活的频率,进而提高了模型的检测精度。
为了验证超参数(hr、mr、tr)对模型检测精度的影响,固定ξ=0.5,根据前期的实验结果分析,采用3组备选数值:(hr=1,mr=1,tr=1),(hr=1,mr=2/3,tr=1/3),(hr=1,mr=0.1,tr=0.01),其性能分析结果如表3所示。

表3 超参数(hr,mr,tr)的性能分析Tab.3 Performance analysis of hyperparameter (hr,mr,tr)
从表3可以看出,超参数(hr、mr、tr)在调整背景类别proposals在其他类别位置二元交叉熵损失函数负激活数量时是有效的,可促进不同类别proposals在其类别位置二元交叉熵损失函数正激活和负激活的数量平衡,从而提高了模型的检测精度。
根据消融实验结果,本文模型中选取超参数分别为ξ=0.5,hr=1,mr=2/3,tr=1/3。
3.5 缺陷检测结果
改进的Faster R-CNN方法在数码印花织物缺陷检测的结果如图5所示。

图 5 所有缺陷类别的检测结果样例Fig.5 Detection samples of all defect classes
从图5可以看出,此方法能够对测试集中的所有缺陷类别完成高精度的检测,并适应于不同尺寸的待检测目标。经分析,该方法性能的提升源于基于类别感知策略的ACSL模块通过在模型训练阶段不断平衡proposals在不同类别位置二元交叉熵损失函数正激活和负激活的数量,有效缓解了头类别样本对其他类别样本的支配作用。
此外,为了验证ACSL模块增强了算法对语义相似度的尾类别(浆瘢)和中间类别(PASS tracks)的区分能力,本文将浆瘢和PASS tracks的检测结果进行了可视化对比,如图6所示。明显看出,本文方法对于存在语义相似度的类别检测具有较高的精度,证明了ACSL模块的引入增加了算法对于容易误检类别位置的二元交叉熵损失函数负激活的频率,从而间接增强了算法对语义相似度的尾类别(浆瘢)和中间类别(PASS tracks)的区分能力。

图 6 语义相似度类别的检测结果Fig.6 Detection results of semantic similarity classes
4 结 语
本文提出了一种自适应类别抑制损失的数码印花织物缺陷检测算法。方法基于Faster R-CNN网络结构,通过引入ACSL模块,自适应调整每个样本在不同类别位置分类损失的权重系数,有效缓解了数码印花织物缺陷检测算法所面临的困境,从而提高了模型对于长尾分布数码印花织物缺陷检测数据集的检测能力。实验结果表明,提出的模型在多项指标上都达到了理想的结果,能够实现数码印花织物缺陷的检测任务。
猜你喜欢
纺织标准与质量(2022年3期)2022-08-10
纺织标准与质量(2022年1期)2022-07-12
少儿画王(3-6岁)(2020年4期)2020-09-13
初中生世界·八年级(2019年6期)2019-08-13
东方教育(2018年20期)2018-08-22
小学生导刊(低年级)(2016年9期)2016-10-13
小学生导刊(低年级)(2016年6期)2016-07-02
小学生导刊(低年级)(2016年4期)2016-04-12
中国纤检(2015年15期)2015-11-13
微型计算机(2009年4期)2009-12-23
