
基于YOLOv3的自注意力烟火检测算法*
2022-08-26 07:58冯庭有蔡承伟江志宏周俊煌
机电工程技术 2022年7期
冯庭有,蔡承伟,田 际,江志宏,周俊煌,陈 乐
(1.华能东莞燃机热电有限责任公司,广东东莞 523000;2.广州市奔流电力科技有限公司,广东广州 510700)
0 引言
火灾发生具有可预见性小、蔓延速度快、危害性大的特点,是危害生命安全和企业生产安全的重大事故的因素之一。如何快速并准确的检测识别是安全防控的重要方面。
早期的烟火防控主要依靠人工巡逻查看为主,发现则及时进行扑灭,该方法依赖于大量人工巡逻。随着厂房、器件和设备的增加,导致巡查难度不断增加,大大降低了巡检的效率。
随着传感器和数字化监管技术的发展,针对烟雾和火焰具有的高温特性,逐渐研发了基于红外方式的烟火检测装置[1]。此类装置根据物体随温度所散发的红外线多少来绘制热力图成像,从而达到检测的目的。然而,此类方法无法对高温类别进行甄别和判断,受检测区域易受到高温设备的干扰和影响而导致误报,虚警率高。红外辐射与监控距离增加成反比,距离越远,成像越差。因此,此类装置覆盖传感监测范围有限,极易出现漏报。
随着计算机图像处理技术不断发展,基于图像处理和识别的方法在逐步发展,通过成像的先验特征,如颜色[2]、纹理[3-4]、梯度[5]等因素进行特征设计,结合霍夫变换、卡尔曼滤波、梯度计算等方式实现对目标区域的特征提取和判断,但受限于人工设计算子的感官偏向性,此类算法易受到外部环境的干扰,鲁棒性不强。近年来,随着计算机性能的不断提升,基于深度学习的图像算法通过自适应的特征信息抽取来实现对物体的识别与检测,具备较好的鲁棒性和广泛的应用性。
现有的深度学习目标图像检测算法主要是通过多层堆叠的卷积层用以实现对图像特征的抽取,本文使用YOLOv3[6](You Only Look Once version 3)检测烟火图像进行实验,由于烟火图像的多变性和无规则性,该算法存在漏检现象,检测效果稳定性不高。
针对此问题,本文提出一种基于自注意力特征的改进YOLOv3烟火检测算法,融合上下文信息的基础上引入自注意力机制,引导模型关注关键性特征,以增强目标检测的性能和稳定性。
1 相关工作
1.1 深度学习的发展
随着计算机的不断发展和应用,人工智能在无人驾驶、机器翻译、语音识别等领域都有着广泛的应用。与传统的机器学习算法相比,基于深度学习的人工智能算法有着更好的表现效果。2012年,Hinton团队在ILSVRC[7](ImageNet Large-Scale Visual Recognition Challenge)上采用神经网络并一举夺得冠军。2013年,Pierre Sermanet等人提出了OverFeat[8]算法,此算法兼顾了图像分类,检测,定位等多项任务。此后R-CNN[9]与YOLO[10]等系列算法提出,受到目标检测任务研究人员和众多工程应用人员的青睐。目标检测算法可分为基于区域候选的双阶段算法和基于目标回归的单阶段算法,区域候选算法具有精度高,检测速度慢的特点,而目标回归算法检测速度较快,但检测精度较低。2016年,SSD[11]算法在二者之间找了较好的平衡点,此后Mask-RCNN[12]和Retina-Net[13]等算法被相继提出。
1.2 注意力机制的发展和应用
注意力机制一直都是计算机视觉中的一个研究热点,其想法来源于人的视觉行为特点,20世纪90年代,研究者们发现人类在图像观察中,并非关注图像的全部信息,而是重点关注感兴趣的区域进行特征提取和判断。
2014年,Mnih等[14]在循环神经网络中引入注意力机制实现图像分类。随后,D Bahdanau等[15]提出了将注意力机制引入自然语言机器翻译任务中用于实现翻译对齐。此后注意力机制在自然语言处理领域大放异彩,并不断进行改进。2017年,Google团队Vaswani等[16]提出了,一种纯注意力特征模块的用于自然语言处理,并刷新多项记录。随后Vi T[17]等算法相继被提出,基于自注意力的神经网络算法在图像领域应用广泛。
注意力机制按照编码方式可分为两种:硬注意力机制和软注意力机制。硬注意力方式采用one-hot编码的方式进行设定,在每一组待判定的特征编码中采用概率最高的概率信息,有利于去除噪声。硬编码转换不可微,模型整体优化较难;软注意力方式采用加权的方式将数据映射为0-1之间的概率。此种方式有利于模型的优化,也可兼顾调节不同权重的信息预测[18-19]。
本文为了进一步提升烟火检测的精度,提出了一种基于YOLOv3的自注意力特征烟火检测算法。该自注意力特征模块,融合上下文信息,引导模型关注特征关键信息,提升检测精度。本文提出一种基于YOLOv3的多尺度的自注意力烟火检测算法,多尺度注意力特征检测较好地实现对场景下的烟火监控。
2 实验
2.1 数据集和预处理
本数据集基于现实场景应用的基础上,收集了4 800张内容包含有烟雾和火焰的数据图像。如图1所示,其中数据集的标注格式采用Pascal VOC[20]进行存储。随机选取4 500张图像作为训练集,剩余图像作为测试集进行模型测试。

图1 部分数据集展示
图像预处理部分主要包含有数据增广策略,通过图像处理的方式增加图像数据的多样,此种策略有利于增强模型的鲁棒性。常见的增广手段包含有旋转、水平翻转、明暗变换、增加噪声等方式。本文采用旋转、水平翻转和对比度变换3种方式预处理图像,如图2所示。
面对国内外食品安全面临的紧迫形势及国家食品安全战略政策导向,培养高水平食品质量与安全专业人才是国家和社会对高校人才培养的基本要求。在这样的大背景下,课程团队对“食品安全控制技术”课程的内容体系及教学模式进行了积极的探索与实践,构建了以食品全产业链安全危害与控制措施为主线的课程内容体系,提出了以案例教学、分组讨论、理论教学及实验教学和实践教学相结合、综合考评为标志的教学模式,且成效显著。最后,结合近3年的教学实践,提出了适应性教材的迫切需要,以期提高“食品安全控制技术”课程教学的质量与效果,培养出高水平的专业人才,为切实保障食品质量与安全作出贡献。

图2 数据增强效果
2.2 YOLOv3算法
原有的YOLOv3算法是通过卷积神经网络实现端到端的目标回归预测任务。其网络结构见2.3.2节所述。YOLOv3目标检测模型包含3个部分:主干网络、融合层及预测层。YOLOv3算法采用darknet-53网络模型作为模型的主干网络提取原始图像的目标特征。通过通道合并的方式融合主干网络中多尺度特征的信息,将特征输入预测层进行目标边界、类别和置信度的预测。
通道合并的方式实现多尺度特征的上下文信息融合,但无法捕捉特征图内部信息的差异性,其具体操作如图3所示。图中Fi表示高分辨率特征,Fi+1表示低分辨率特征。Fi+1通过Fup(·)实现分辨率大小与Fi保持一致,采用维度叠加以实现特征信息实现融合。

图3 通道融合示意图
其中Fup(·)表示特征尺寸对齐,其表达式如式(1)所示。尺寸对齐的方式一般包含有转置卷积、线性插值等方式,本文采用双线性插值的方式。
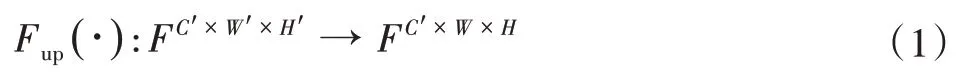
式中:F为特征,C′,W′,H′分别为特征原有的通道、宽度、高度维度,W、H为特征的对齐后的尺寸。
2.3 基于YOLOv3自注意力烟火检测算法
2.3.1 自注意力机制
尽管YOLOv3算法利用基于通道合并的方式实现了多尺度信息的融合,但为了进一步排除非关键信息的干扰,引导网络聚焦于特征中的关键特征,本文引入注意力机制。其结构如图4所示。
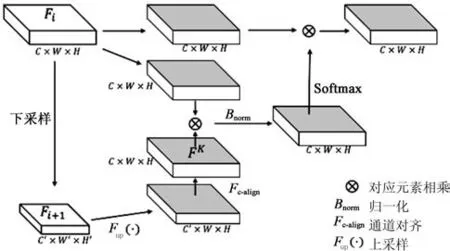
图4 自注意力机制结构示意图
在自注意力模块中,其输入为来自主干网络的特征图Fi和Fi+1,结构分别为C×W×H和C′×W′×H′。其中,C、C′为特征通道数,W、W′为特征图宽度,H、H′为特征图高度。一般来说,Fi大于Fi+1特征分辨率,在模型的最后一层中,Fi等于Fi+1特征分辨率,因此不需要Fi与Fi+1特征结构对操作。自注意力模块运算的流程如下所示。
(1)将输入特征Fi+1先后经过Fup(·),Fc-align的方式实现特征结构的对齐,其中Fc-align采用1×1的卷积实现特征通道对齐,得到结构为C×W×H特征图FK。
(2)输入特征Fi分别通过两次3×3的卷积转换为特征FV和F Q,特征的尺度大小保持不变。
(3)将步骤(1)中的FK特征与步骤(2)中的FQ逐元素相乘实现上下文信息的融合,经过Bnorm实现对W×H维度标准化得到特征FT,Bnorm降低特征方差防止特征权重两极化严重。其中Bnorm计算如式(2)所示:

式中:F为输入特征矩阵;d为标准化的维度,值为W×H。
(4)将步骤(3)中得到的特征FT在W×H的维度上进行softmax归一化,与步骤(2)得到的F V进行对应元素相乘得到注意力特征FA,完成自注意力模块的计算。
总体的自注意力模块的计算如式(3)所示:
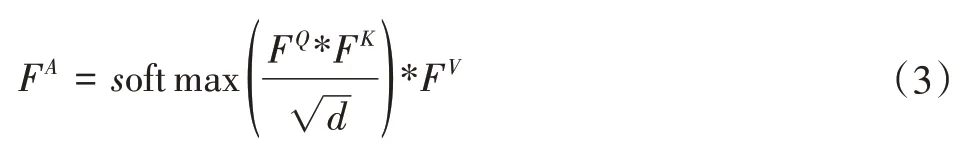
式中:*表式对应元素相乘。
2.3.2 网络结构
改进后模型仍然包含3个部分:主干网络,自注意力层及预测层,如5所示。主干网络总体结构借鉴了残差神经网络的“short-cut”的思路,有利于梯度在深层网络中的传递和模型的优化,在运算速度和表现精度上不逊色于Resnet101网络,后文也有对比,具备较好的实用性。其基本的结构如表1所示。
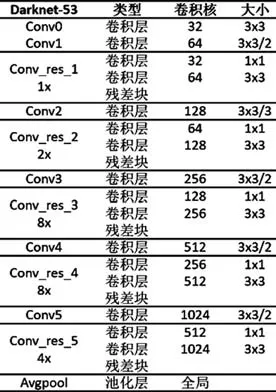
表1 主干网络结构表
在主干网络中,Conv_res_3、Conv_res_4、Conv_res_5位置输出特征后嵌入自注意力模块。融合上下文信息,通过自注意力模块计算,输出特征图内信息的差异性,使网络优化倾向于目标关键特征的提取,提高模型的整体表现性能。
YOLOv3预测层在多尺度的注意力特征上进行预测,通过包含了类别预测,目标置信度预测和位置预测。其优化目标包含有3个方面,如式(4)所示:

式中:l为总损失;lbbox为位置损失;lclass为分类损失;lconf为置信度损失。
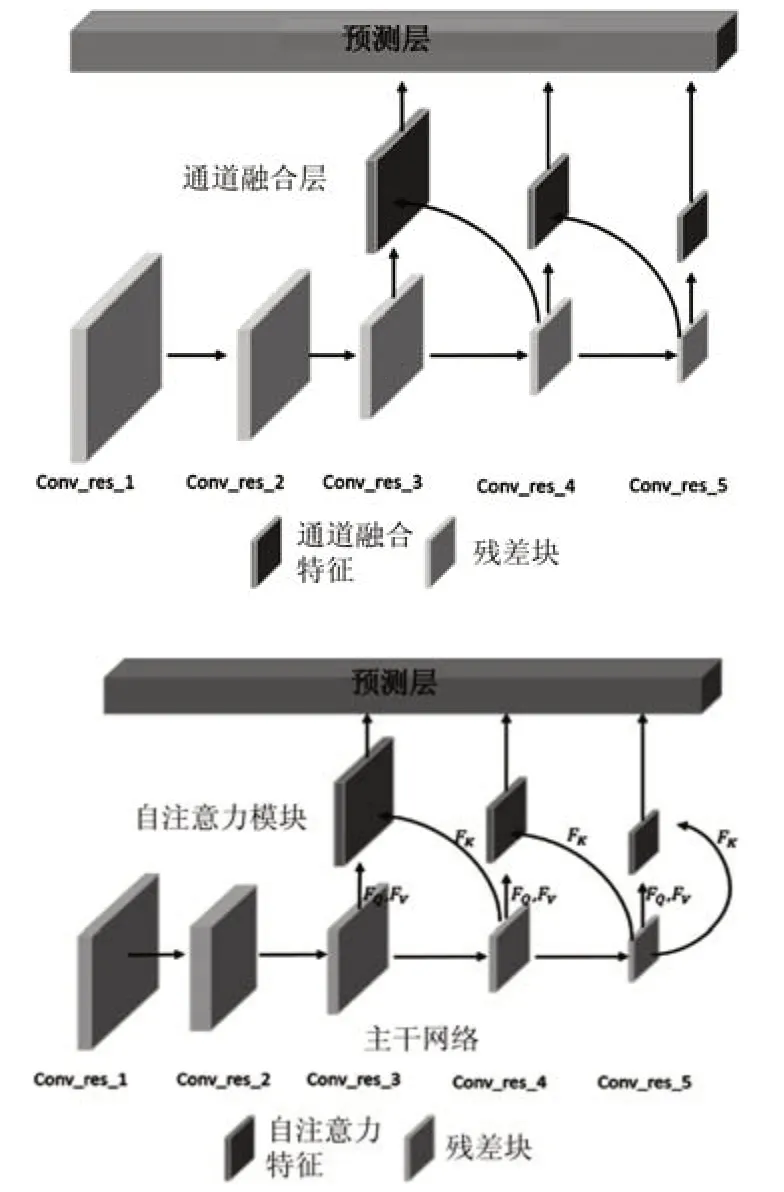
图5 模型对比
其中类别预测采用Sigmoid结合交叉熵损失函数实现多类别的预测,其分类损失计算如式(5)所示:
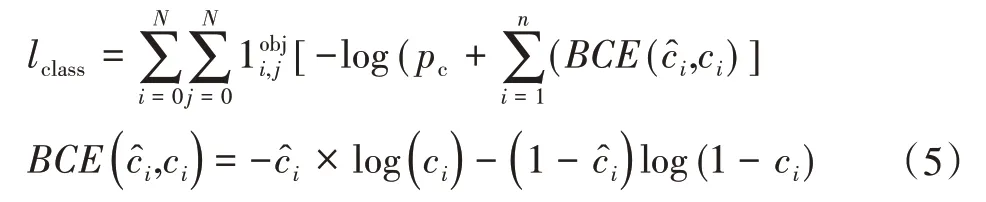
式中:lclass为分类损失;为预测类别;ci为真实类别;如果在i,j表示位置坐标处有物体则为1,反之则为0;pc为置信度概率;BC E为二分类用的交叉熵损失,N为划分网格的数量。
位置损失通过计算预测框和真实框之间的偏移量得出。本次采用平方差的形式予以计算,如式(6)所示:

式中:lbbox为位置损失,i,j为位置坐标,xi为真实框中心行坐标;yi为真实框中心纵坐标;wi为真实框的宽度;h i为真实框的高度;为预测框中心行坐标;为预测框中心纵坐标;为预测框的长度;为预测框的宽度。λcoord为位置损失系数,一般设置为1。
目标置信度为错误预测目标的概率之差,其总体的损失计算如式(7)所示:

式中:λnoobj为置信度损失系数;表示在i,j坐标处没有物体为1,反之为0;pc为预测的置信度概率;N为划分网格的数量。
3 实验结果
3.1 YOLOv3与YOLOv3自注意力对比
YOLOv3与基于YOLOv3的自注意力网络算法的对比如图6所示。经过80 000次的迭代训练。模型基本处于稳定且收敛的状态。

图6 训练损失与迭代次数
本文在测试集上验证算法,基于YOLOv3的目标检测算法在准确率和召回率上都取得一定提升。其对比如表2,基于YOLOv3的模型在测试集上的准确率达到了92.1%,召回率达到了90.5%。
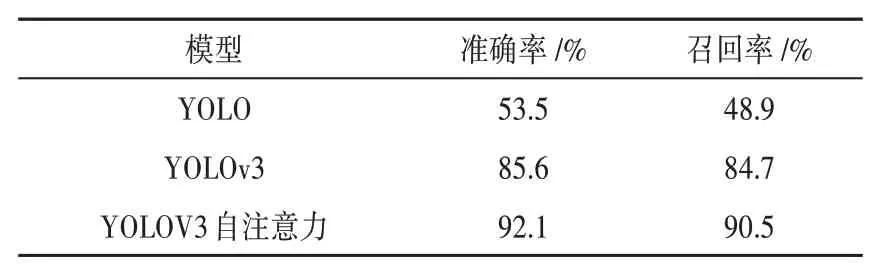
表2 准确率和召回率对比
3.2 主干网络对比
为了进一步提升精度,本文尝试将主干网络替换为Resnet101网络。为方便对比,本文在Resnet101中也采用后3个残差块输出特征作为注意力模型的输入,如表3所示。基于Resnet101的YOLOv3方法在准确率上与YOLOv3算法相当。基于YOLOv3自注意力网络在不同的主干网络中仍然具有较好的表现。

表3 主干网络方法的精度对比
3.3 效果图展示
本文在基于YOLOV3的目标检测算法上引入自注意力机制,用于烟火图像检测,其效果如图7所示,检测效果较好。

图7 烟火检测效果展示
4 结束语
本文提出了一种基于YOLOv3的自注意力烟火检测算法,通过融合模型上下文信息,引入自注意力模块,引导模型自适应学习,提取关键的特征信息,从而有效地提升了模型的特征表达和检测精度。本文还通过不同模型方法的结果对比发现此结构同样有效。然而,尽管如此,研究中也发现,采用矩形框的目标检测标注框在非刚性物体的检测中具备较大的难度和缺点,矩形框无法较好地框住形态多变的目标。因此,在今后的研究中,一方面将继续研究自注意力机制在神经网络算法中的深层次扩展和应用,另一方面,也将探索目标标记检测框的设计和改进方式,以方便更好地实现对目标的检测,提升模型的表现性能。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
小雪花·成长指南(2022年1期)2022-04-09
阅读(快乐英语中年级)(2021年2期)2021-04-01
学生天地(2020年35期)2020-06-09
甘肃教育(2020年22期)2020-04-13
读友·少年文学(清雅版)(2019年10期)2019-05-21
第二课堂(课外活动版)(2016年2期)2016-10-21
