
基于YOLOv5的无人机目标图像识别
2022-08-25 08:44张珺仪
电视技术 2022年8期
张珺仪,郭 楠
(合肥工业大学 电气与自动化工程学院,安徽 合肥 230009)
0 引 言
目前,直接使用YOLOv5官方权重进行无人机航拍目标检测时,效果并不理想。无人机遥感场景下进行旋转目标检测数据规模小,大中小目标分布不均,背景复杂,目标尺度变化剧烈,小目标采样易丢失,类间极度不平衡,导致其检测概率小,精确度很低。同时,小目标(32×32)一直是目标检测中的难题,例如检测器在COCO上的小目标检测平均准确率(Average Precision,AP)通常要低20个点[1-6]。本文将针对这类问题利用现有资源进行改进,选取新的DOTA数据集——DOTA-v2.0,并利用改进的YOLOv5算法对DOTA-v2.0数据集进行训练,最终完成航拍目标的检测。
1 DOTA数据集介绍
1.1 选择DOTA数据集的理由
在一般对象数据集上,ImageNet和MSCOCO以图像数量多、类别多、注释详细等特点受到研究人员的青睐。ImageNet在所有对象检测数据集中拥有最多的图像,然而,每张图像的平均实例数远小于MSCOCO和DOTA数据集。DOTA数据集中的图像包含大量的对象实例,其中一些实例超过1 000个。与其他数据集比较,DOTA数据集拥有较大的平均示例数,如表1所示,相较于2018年发布的更庞大的DIOR数据集,更具备本文研究的包含小目标的航拍、遥感图像特征,即在同一区域拥有较多的小目标对象。DOTA数据集与其他数据集的对比如表1所示[7]。
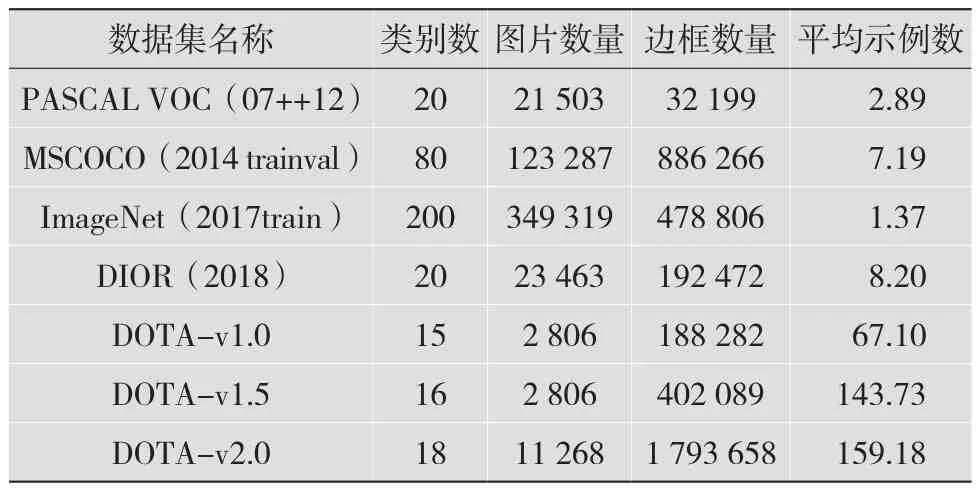
表1 DOTA数据集与其他数据集的对比
DOTA-v2.0作为最新的DOTA数据集,比DOTA-v1.0增加了航拍视角(Aerial)图像。图1是DOTA-v2.0和DOTA-v1.0的对比[8]。
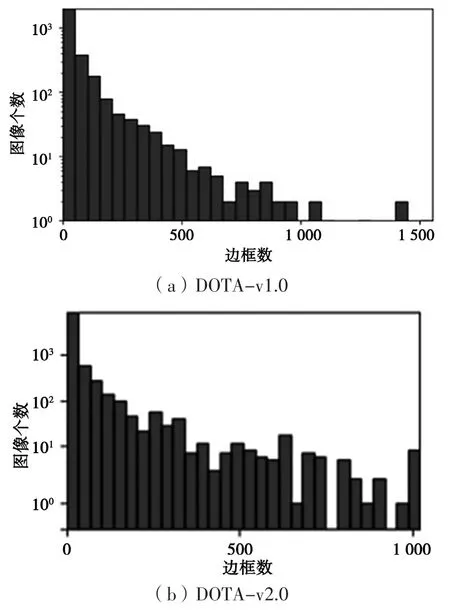
图1 DOTA数据集
由图1可见,在图均检测边框数上,DOTA-v2.0更加平均,且整体数目有所增加。综上所述,本文选择DOTA-v2.0为数据集。
在航拍图像中,所使用的传感器的分辨率和种类是产生数据集偏差的因素。为了消除偏差,数据集中的图像是从多个传感器和平台(如谷歌地球)以多种分辨率收集的。为了增加数据的多样性,本文收集了在多个城市拍摄的图像。这些图像由航空图像解释专家精心挑选。对于这些图像,记录每张图片的位置和拍摄时间的准确地理坐标,以确保没有重复的图片。
DOTA-v2.0数据集共标注了18个类别,包括飞机、船舶、储罐、棒球场、网球场、篮球场、地面田径场、港口、桥梁、大型车辆、小型车辆、直升机、环形交叉路口、足球场、游泳池、集装箱起重机、直升机停机坪以及机场[9]。
1.2 数据集结构
DOTA数据集的标注文件分为有向目标边框(OBB)与水平目标边框(HBB)两个版本,其区别如图2所示。HBB为无方向性的标注框,在小目标检测时很容易造成边框重叠,并且由于框内物体实际拥有朝向方向,容易增加检测难度;而OBB选定了朝向方向,定向框更好地贴合了物体走向、形状,减轻了计算量。根据本文关注的航拍、遥感小目标的密集性特点,本文选取OBB为标注方式。OBB标注的数据格式如表2所示。

表2 OBB标注格式

图2 HBB标注与OBB标注的对比
2 训练数据的改进与处理
处理数据时,本文在传统增强方法的基础上增加了马赛克拼接法,即将多个待检测图像截取一部分合成为一张图片进行整体检测。这种方式能够同时有效提升微小扰动和大量扰动条件下模型的检测准确性。
2.1 网络改进
遥感图像由于分辨率过高,在训练或预测过程中单张图片运算时要求的显存较高,成本要求高。对此,通常有以下两种解决办法。
(1)直接降低图像的分辨率。将大于YOLOv5网络标准图片大小的图像,直接调整图像大小,例如将20 000×20 000大小的图像直接调整至1 000×1 000,则大部分GPU都能满足运算要求,但是很容易损失图像信息,尤其对于DOTA-v1.5版本中新增加的许多小于10像素的示例极不友好,其尺寸会进一步缩小,进而可能致使其特征在深层网络逐层提取中消失。
(2)切割单张图像为多张图像。即将大于YOLOv5网络标准图片大小的图像,在送入程序前先进行分割处理,使其满足要求。如将20 000×20 000的图像裁剪成20×20=400张1 000×1 000大小的图片,对切割的图片进行多次预测,再将预测的结果进行拼接,同样可以获得原图的预测结果。代价就是原本只需进行一次前向传播,切割后需要进行100次前向传播才能获得预测结果,时间成本大幅增加。由于切割时常会导致处于切割后图像边缘部分的目标信息缺失,因此需要设置一定的重叠区域(gap)。由于DOTA-v2.0中的最大图像大小超过20 000×20 000,为保证图像中小目标的识别精度,取gap为切割图像的50%。
本文选用第二种方法,并预先编写分割图像的函数,对图像进行预处理。
2.2 label文本文件数据格式转换
将分割后的label文本文件DOTA数据格式poly转为YOLO数据格式xywh。
2.3 数据集的数据增强
为了提升模型的检测效果,使其更好地适用于应用场景,同时增加训练的数据量,提高模型的泛化能力,本文采用了图像增强处理,即对数据集的数据增强。本节对数据集进行镜像处理、随机角度旋转以及图像平移等处理[10]。
经过垂直镜像、水平镜像、随机角度旋转处理后的结果示例如图3所示。

图3 数据增强处理结果
由图3可见,经过垂直镜像、水平镜像、随机角度旋转处理后,图像的方位、角度更具有随机性,模型多样性也得以提升。
2.4 检测结果合并
利用被分割图像检测出的目标位置信息和图像名称中的裁剪位置信息,还原目标在原始未分割图像中的位置。程序中考虑到由于裁剪图像之间重叠区域的存在,图像组合后会有一个目标被多个bbox标记,因此还在合并(merge)之后添加了一个poly_NMS。表3为分割前后的数据格式。

表3 分割前后的数据格式
通过训练,模型在DOTA-V2.0数据集上的检测结果如图4所示,在DIOR数据集上的检测结果如图5所示。
由图4和图5可见,本文通过训练得到的模型在DOTA-v2.0数据集和DIOR数据集上的检测结果都很理想,说明了本模型具有普适性。

图4 在DOTA-v2.0数据集上的检测结果

图5 在DIOR数据集上检测结果
3 数据集训练
由于数据集较大,因此本文中数据集采用线上GPU,型号为NVIDIA GeForce RTX 3090,epoch选为150,batchsize为4。数据集训练过程截图如图6所示。
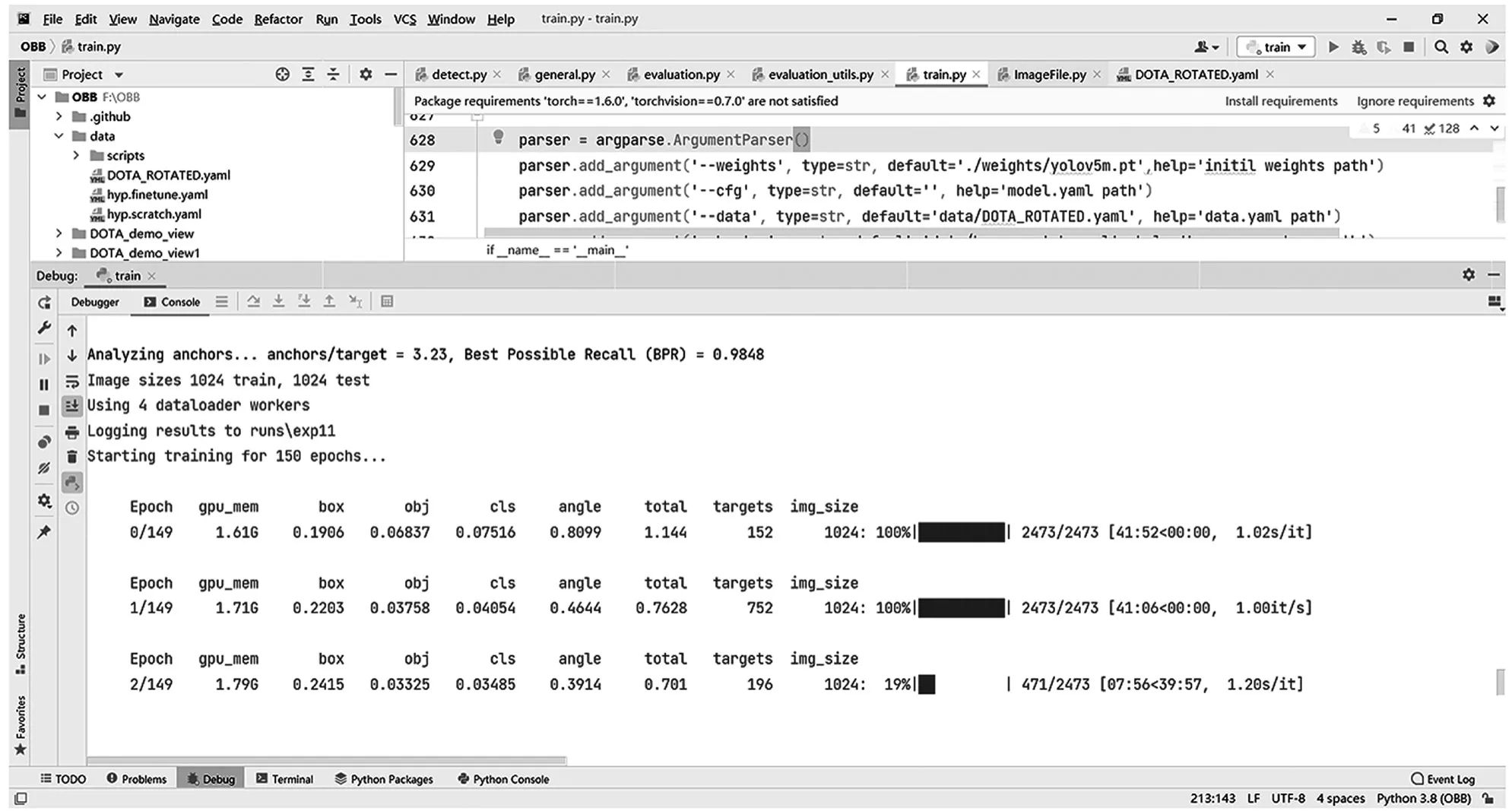
图6 训练过程截图
4 数据集测试
数据集测试中,weights代表训练的权重,source代表测试数据,可以是图片/视频路径,也可以是‘0’(电脑自带摄像头),也可以是rtsp等视频流;output代表网络预测之后的图片/视频的保存路径,img-size代表网络输入图片大小,conf-thres代表置信度阈值,iou-thres代表做nms的iou阈值,device代表设置设备,view-img代表是否展示预测之后的图片/视频,默认False;save-txt代表是否将预测的框坐标以txt文件形式保存,默认False;classes代表设置只保留某一部分类别,例如设为class0或者class023;agnostic-nms代表进行nms是否将所有类别框一视同仁,默认为False;augment代表推理的时候进行多尺度、翻转等操作(TTA)推理;update代表如果为True,则对所有模型进行strip_optimizer操作,去除pt文件中的优化器等信息,默认为False。
测试过程的部分程序如下所示。


经过程序运行,最终得到的测试结果有3 933张图,截取其中1张,如图7所示。

图7 测试结果
5 模块性能评估
对比原图gt_poly和原图detection_poly,求得各个类别的AP以及mAP,得出图片包含类型、图片名等,以评估模型性能。用detoutput表示detect.py函数的结果存放输出路径,imageset表示DOTA原图数据集图像路径,annopath表示原始测试集的DOTAlabels路径,classnames表示测试集中的目标种类部。评估结果如表2所示。
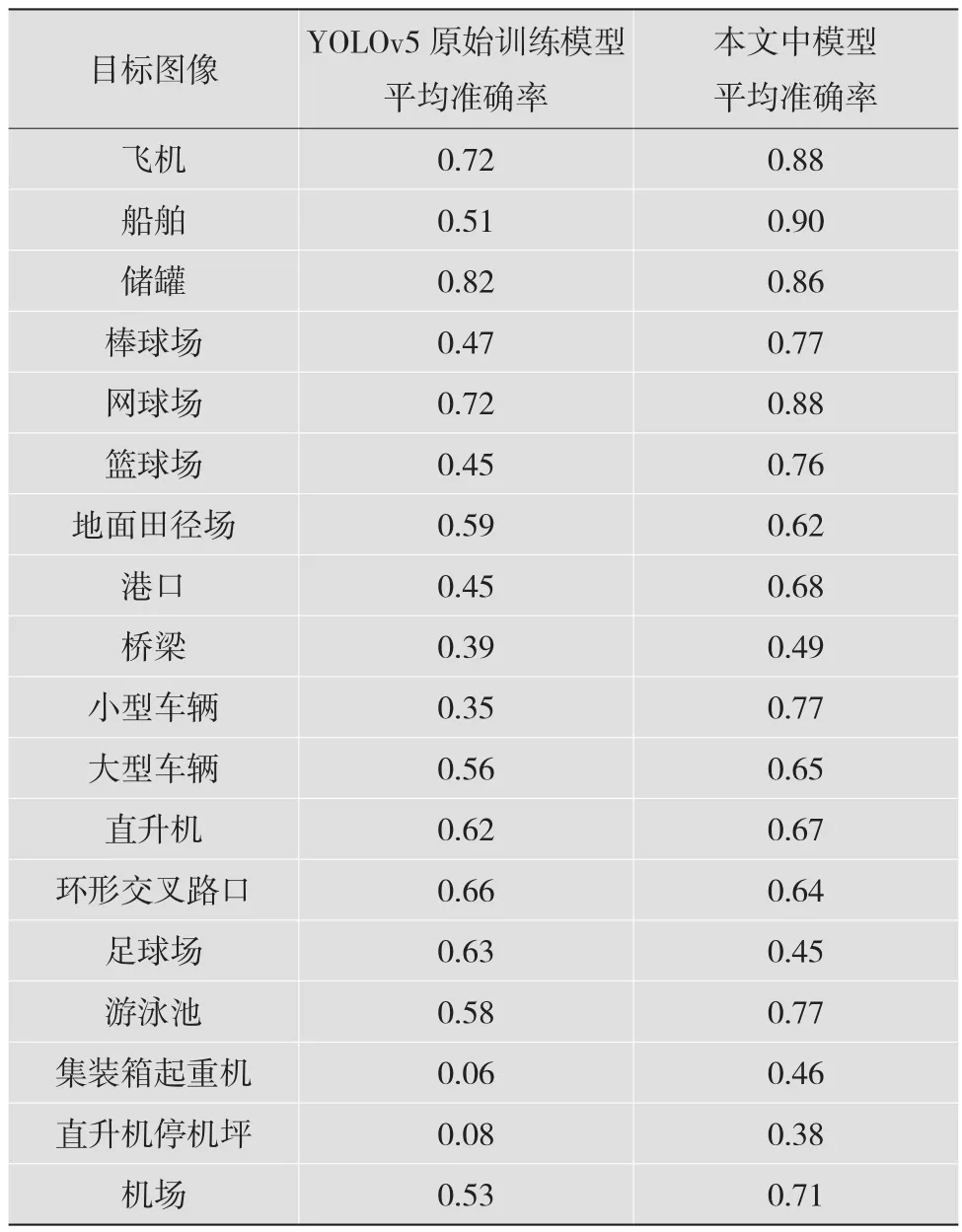
表2 检测各类目标的平均准确率
由表2可见,用本文模型检测目标的平均准确率能够达到68%,部分类别的平均准确率可以达到90%。可见,该改进模型能满足航拍目标的检测精度要求,比原始训练模型的精度有一定提高。
6 结 语
本文应用改进的YOLOv5算法对无人机航拍目标进行检测,建立了基于YOLOv5算法的目标检测模型,通过应用网络改进、数据增强等技术,提高了模型检测效能,完成了对航拍小目标的检测,获得了较高的检测精度。
猜你喜欢
四川大学学报(自然科学版)(2021年6期)2021-12-27
计算机应用(2020年12期)2020-12-31
时代邮刊·下半月(2020年9期)2020-09-23
金桥(2018年6期)2018-09-22
小学生优秀作文(低年级)(2018年6期)2018-05-19
科学与财富(2017年33期)2017-12-19
电脑知识与技术(2017年6期)2017-04-26
陕西画报(2017年1期)2017-02-11
科技与创新(2016年17期)2016-11-04
文苑(2015年9期)2015-09-10
