
针对轻量化网络的安全帽检测方法
2022-08-25 02:12刘泽西
测控技术 2022年8期
刘泽西, 张 楠, 连 婷, 马 骏, 赵 勇, 倪 威
(1.国网新疆电力有限公司巴州供电公司,新疆 库尔勒 841000;2.华北电力大学 电气与电子工程学院,北京 102206)
传统的安全帽佩戴检测方式主要有视频监控图像和人工巡检查看等。查看视频监控图像的方法需要工作人员长期盯着屏幕,容易出现错判漏判等情况;人工巡查的方式则在时间和精力上的消耗更大,效率低下。随着对计算机视觉研究的深入,无人监督智能安全帽佩戴检测方法开始走入人们的视野,因其具有检测成本低、检测速度快和检测精度高的优点,故引起了人们关注。传统检测方法根据安全帽和人体的特征来进行人工选取,再设计训练分类器,过程较为烦琐,实际应用中存在较大局限性。到目前为止,国内外学者对安全帽检测进行了较多的研究,Shrestha等[1]使用类似Haar的特征检测人脸,再使用边缘检测算法查找安全帽轮廓特征实现对安全帽佩戴的检测。Rubaiyat和Silva等[2-3]将图像中的频域信息和梯度直方图(Histogram of Oriented Gradient,HOG)算法结合来对行人进行检测,再利用圆环霍夫变换(Circle Hough Transform,CHT)来检测人员安全帽佩戴情况。刘晓慧等[4]结合Hu矩阵和支持向量机(Support Vector Machine,SVM)来对人员安全帽佩戴进行检测。冯国臣等[5]通过选取SIFT角点特征和颜色统计特征的方法进行安全帽佩戴检测。
目前,基于深度学习的目标检测算法主要分为两类:一类是以R-CNN(Region-Based Convolutional Neural Network)[6-8]为代表的双阶段算法,这类算法首先生成大量候选框,之后对各个候选框使用卷积神经网络提取特征,最后使用回归器修正候选框位置;另外一类是以YOLO(You Only Look Once)[9-11]系列和SSD(Single Shot Multi-Box Detection)[12]等为代表的单阶段算法,这类算法采用端到端的设计思想,在单个卷积神经网络中完成候选框获取、类别分类和位置预测。很多学者针对安全帽佩戴检查提出的方案是基于YOLOv3改进的,文献[13]通过对YOLOv3的损失函数进行改进,在检测精度上得以提升。文献[14]改进了YOLOv3网络结构,使用深度可分离卷积替代原有主干网中的卷积,并采用多尺度检测,相较于原网络其在推理速度和检测精度上都有明显提升。文献[15]通过增加一个输出特征层的方法增强对小目标检测效果,使用K-means算法重新聚类生成4个尺度的候选框,在损失函数中用GIoU(Generalized Intersection over Union)损失作为边框回归损失,Focal Loss作为置信度损失,提高了检测精度。文献[16]针对安全帽尺寸不一的问题,采用K-means++算法重新聚类,再引入多光谱通道注意力机制增强信息传播,从而加强了对前景和背景的区分能力。
2020年Glenn等提出了YOLOv5系列模型,该模型主干特征提取网络中增加了Focus结构,在检测速度和精度上取得了较好的平衡。本文以YOLOv5s为基础,对YOLOv5s进行改进,实验结果表明改进后的算法在检测速度上有所提升,满足施工人员安全帽佩戴检测要求。
1 YOLOv5s网络简介
YOLOv5共包含YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x共4种版本,4种版本分别适合部署在算力不同的设备上,各版本模型大小依次递增,并以Bottleneck结构的数量来区分。YOLOv5s由backbone和head两部分组成,backbone主要包含Focus结构、C3结构和SPP结构,head部分主要包含路径聚合网络(Path Aggregation Network,PANet)和检测头结构。
在backbone部分,通过一个Focus结构和4个普通卷积块实现32倍下采样,Focus结构将输入图片切割为4份,在通道维度进行拼接操作之后再进行卷积操作,实现了下采样并增大了通道维度。C3结构将输入特征图分为2个部分,进行拆分和合并后跨阶段结合,较好地减少了语义信息的损失。由于重复梯度信息的减少,使YOLOv5s网络具有更好的学习能力,在YOLOv5s中通过设置CSP-true和CSP-false参数来决定Bottleneck结构中是否有残差边,同时加入SPP结构后,通过3个多尺度最大池化层来增大网络感受野范围。
在head部分,将高层的特征信息通过上采样的方式与底层信息进行融合,实现自顶向下的信息流动,再通过步长为2的卷积,将底层特征与高层特征进行Concat操作,使底层分辨率高的特征信息易于传到上层,从而构造路径聚合网络结构,更好地将底层与高层特征优势互补,有效解决网络模型多尺度问题。
2 改进的YOLOv5s模型
2.1 主干网络的改进
在对YOLOv5s主干网络进行改进时,主要参考了RepVGG的主干网络。RepVGG[17]核心思想是通过结构重参数化,在训练时采取多支路结构来获得更多的特征,在推理时转换为单路结构来提高模型推理速度。原VGG网络[18]是直筒型单路结构,由于不需要保存中间计算结果,故该结构占用内存更少,而且并行度高、速度更快。在VGG中共有5段卷积,每段内有2~3个卷积层,在每段卷积层尾部会连接一个池化层来缩小特征图尺寸,每段内部卷积核数目一致,随着网络加深,越靠后卷积核数目越多。RepVGG主体结构由3×3卷积核、1×1卷积核和identity支路结合而成,RepVGG训练时结构如图1所示。在训练过程中,为每一个3×3卷积核添加平行的1×1卷积核和恒等分支映射,其借鉴了ResNet构造残差块的思想,以此提高模型的特征分辨能力,获取更多特征信息;采用identity的分支结构使模型更易收敛,从而避免出现梯度消失的问题。
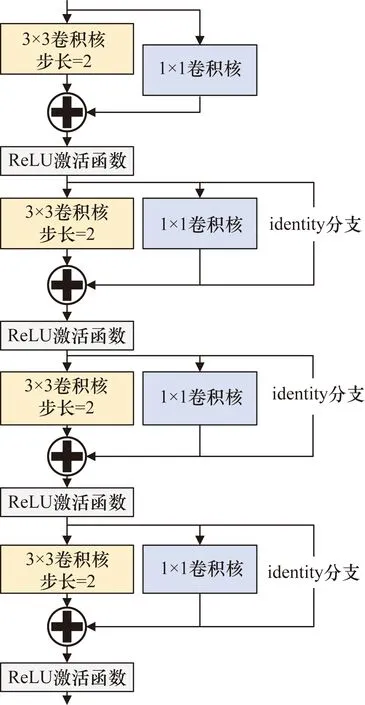
图1 RepVGG训练时结构图
在推理阶段,通过参数重构化的方式,将1×1的卷积核及identity分支转换为3×3卷积核与ReLU激活层堆叠的方式,单线型的结构有助于提高模型推理速度,减少内存的占用。RepVGG推理时网络结构如图2所示。
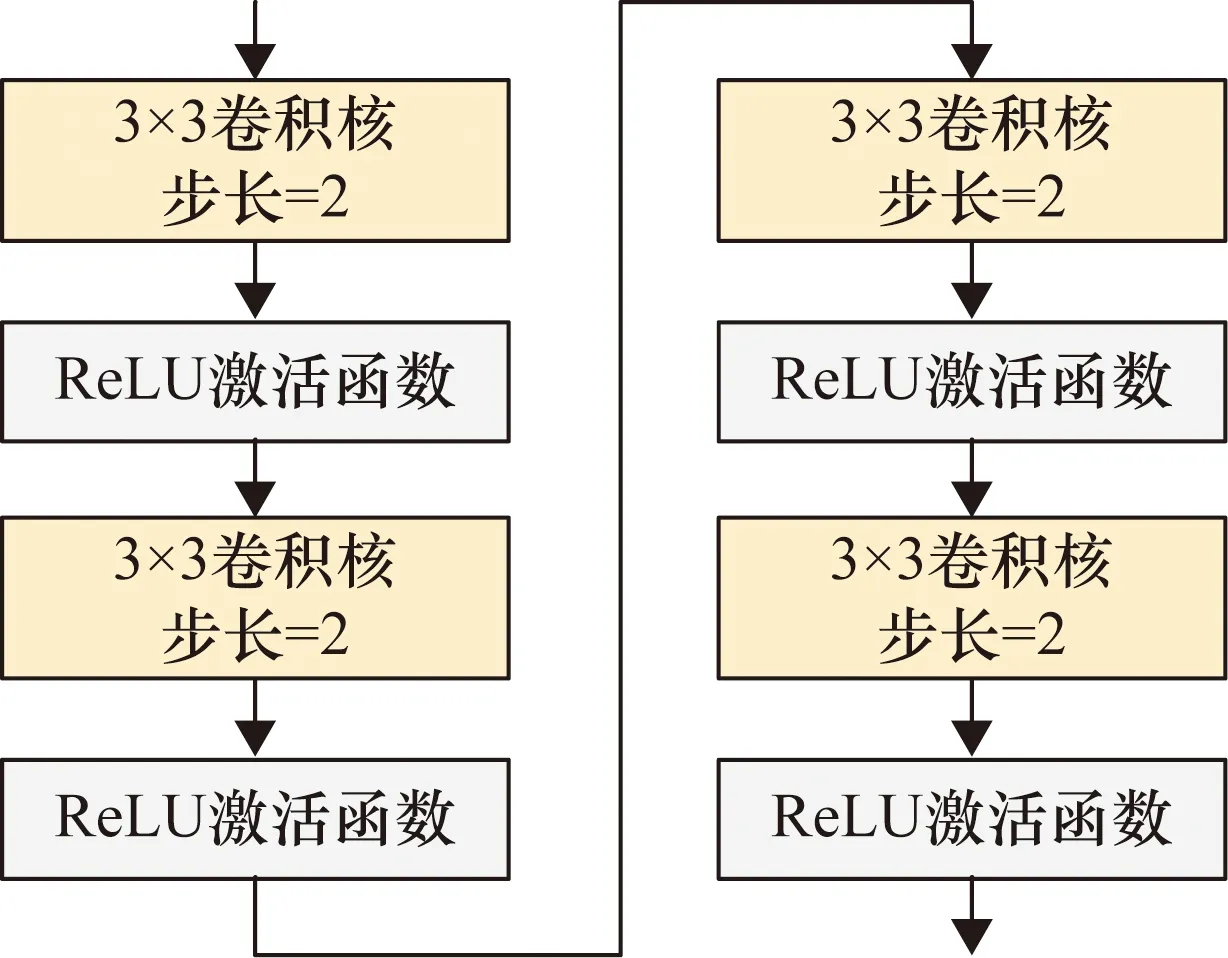
图2 RepVGG推理时网络结构图
结构重参数化主要体现在批量归一化(Batch Normalization,BN)层与卷积层的融合,在神经网络中,BN层常被用于加速神经网络的收敛,有效缓解了梯度消失和梯度爆炸问题,这里将BN层与卷积层合并,能够达到减少网路层数和提升网络性能的效果。卷积层计算公式为
Conv(x)=W(x)+b
(1)
式中:W(x)为权重函数;b为偏置;x为输入。
BN层计算公式为
(2)
式中:σ为对卷积层输出求得的标准差;ε为防止标准差为0而加入的正则化参数;μ为对卷积层输出求得的均值;β为平移因子;γ为尺度缩放因子。其中,β与γ都是可学习参数。
将卷积层计算公式代入BN层计算公式可得:
(3)
BN(x)=Wfused+Bfused
(4)
在RepVGG结构中有1×1卷积核和identity两种分支结构。对于1×1卷积核而言,可以通过填充的方式将其等效为3×3卷积核,等效的3×3卷积核除了卷积核中心位置,其他位置都为0,即将1×1卷积核移动至3×3卷积核中心。而对于identity分支而言,可利用权重为1的卷积核,将identity结构构造为一个1×1卷积,同时该卷积的权重值为1。再通过设置一个3×3卷积核,对输入特征映射相乘后,使identity分支前后值不变。此时1×1卷积核和identity均可转变为3×3卷积核,而根据卷积的特点,卷积核在大小形状相同时满足可加性。此时3个卷积分支可以融合,过程如图3所示。选择将3×3的卷积块重构为RepVGG模块,改进后的网络结构如图4所示。
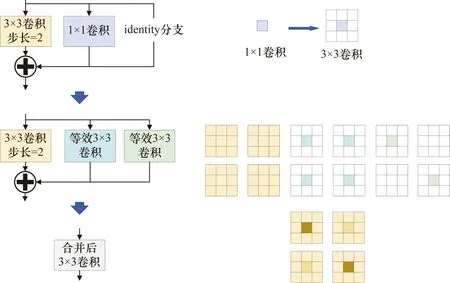
图3 分支合并过程
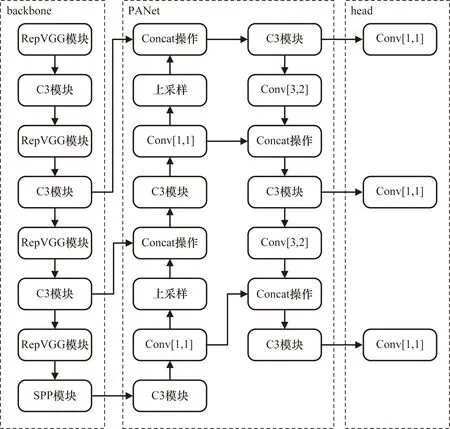
图4 改进后网络结构图
2.2 后处理阶段的改进
在检测的后置处理阶段,非极大值抑制(Non Maximum Suppression,NMS)算法常被用于移除多余的检测框,但是NMS在每轮迭代中会抑制所有与预测框交并比大于给定阈值的检测框,从而造成目标漏检和误检。同时,交并比给定阈值的选取对最后预测结果也有较大影响。NMS的计算公式为
(5)
式中:Si为检测框的得分;M为当前得分最高的检测框;bi为剩余待处理检测框;Nt为人工设定的阈值;IoU(M,bi)为2个检测框的重叠度。当IoU大于或等于给定阈值时,该检测框得分清零,导致与目标框相邻的检测框被强制清零,造成漏检和误检。在此基础上Soft-NMS[19]对重叠度高的检测框进行识别,当待处理检测框与得分最高的检测框交并比大于给定阈值时,通过添加非线性惩罚项的方法来降低其得分,而不是直接清零,从而在检测时降低对遮挡目标的漏检可能性,Soft-NMS计算公式为
Si=Sie-IoU(M,bi)2/σ
(6)
式中:σ为超参数,越接近高斯分布的中心,惩罚影响越大。同时该函数是平滑且连续的函数,避免了检测框集合中得分出现巨大翻转。
2.3 数据增强
数据增强常被用于深度学习中,对于提高样本鲁棒性、改善模型性能有着重要作用。Mixup[20]数据增强与传统数据增强方法不一样,Mixup通过逐像素级别线性相加将图像混合,对2个样本-标签按比例相加后生成新的样本-标签,通过服从贝塔分布的参数λ来调整不同样本-标签对应的权重,即通过对特征向量进行插值实现对应标签的线性插值。用该方法能够拓展训练分布,提升模型训练的鲁棒性。插值过程如下:
(7)
(8)
λ~β(α,α),α∈(0,∞)
(9)
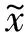

图5 不同混合系数下数据增强效果图
3 实验对比及分析
3.1 实验环境
本文的实验环境为:处理器AMD Ryzen 5 4600H@3.00 GHz,机带RAM 16.0 GB,GPU为NVIDIA GeForce GTX 1650,Windows 10操作系统,PyTorch深度学习框架,编程语言为Python,GPU加速库为CUDA 11.4和CUDNN 8.04。
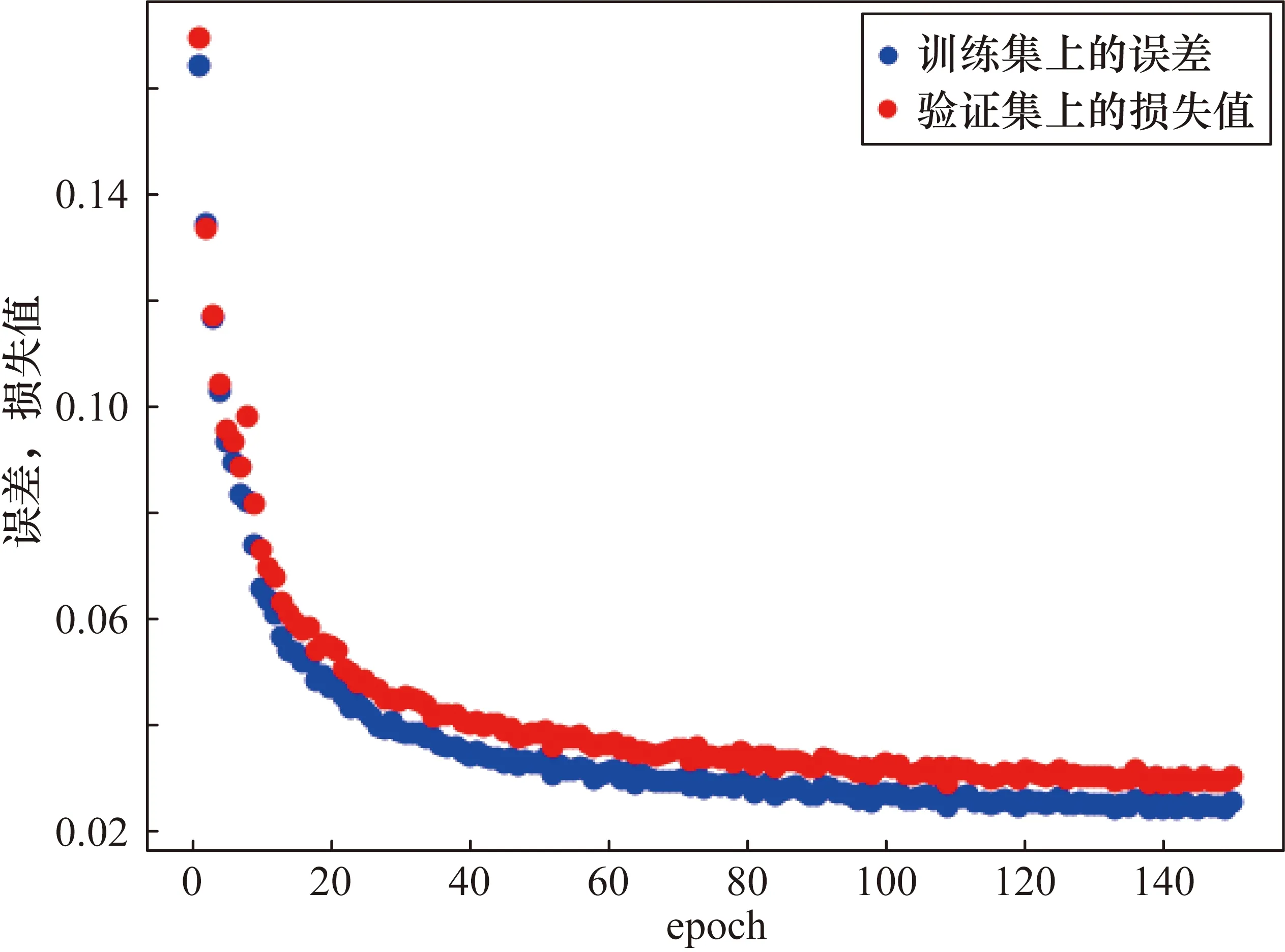
图6 训练过程损失曲线
3.2 数据集及训练
本实验所用数据集为已经开源的安全帽佩戴检测数据集(Safety Helmet Wearing Dataset,SHWD),这里选取了该数据集中partB的1500张图片,按照7∶3的比例划分为训练集和验证集,在训练时采用Mixup数据增强方法对数据进行扩充,最终训练集共包含佩戴安全帽类6745个、未佩戴安全帽类6591个,验证集共包含佩戴安全帽类3212个、未佩戴安全帽类3457个。
在进行训练时批训练数据量(Batchsize)设置为16,输入图像大小为640像素×640像素,权重衰减(Decay)为0.005,训练动量(Momentum)配置为0.937,初始学习率为0.001,每个模型分别训练150个epoch,训练损失变化如图8所示。从图8中可以看到随着训练的进行,损失曲线在慢慢收敛,进行到第150个epoch时,模型的损失基本收敛,说明训练有效。
3.3 评价指标及结果分析
本文主要采用平均精度(Mean Average Precision,mAP)和每秒检测帧数这2个指标对模型进行评估。AP值由准确率(Precision)和召回率(Recall)生成的Precision-召回率曲线和坐标轴组成的面积计算得到,mAP表示对所有AP求得的均值。召回率和准确率的计算公式为
(10)
式中:TP为检测为正样本并且确实为正样本数量;FP为检测为正样本但实际不是正样本数量;FN为检测为负样本但实际不是负样本数量;Precision为检测为正样本且确实为正样本占所有检测为正样本的比例;Recall为检测为正样本且确实为正样本占所有确实为正样本的比例。训练完成后将模型的AP值、参数量、模型大小与原YOLOv5模型进行对比,结果如表1所示。由表1结果可知,本文方法在检测佩戴安全帽时AP值变化不大,在检测未佩戴安全帽时AP值变化较大。由于主干网络的优化,本文方法的参数量为5.4×106,比原YOLOv5s模型减少了22.86%,模型大小压缩了22.62%。

表1 模型性能对比
同时为了验证本文所做改进的有效性,在测试数据集下进行相应的消融实验,消融实验结果如表2所示。在YOLOv5s模型中分别引入Soft-NMS和Mixup数据增强后,模型计算量会有所增加,推理速度略低。采用本文所提出的方法,即引入RepVGG模块改进主干网,并同时引入Soft-NMS和Mixup数据增强后,推理速度得到加快,但因模型的特征提取能力有所下降,导致检测精度略下降。
表2 消融实验结果
在变电站场景下,用本文所提改进后的模型对施工人员佩戴安全帽进行检测,效果图如图7所示。在密集人群场景下安全帽佩戴检测效果较好,没有误检漏检的发生。在安全帽大小不一场景下检测精度较高,能够满足实际工作中安全帽检测需要。

图7 改进模型检测效果图
4 结束语
针对变电站工人安全帽佩戴检测情况,提出了基于深度学习的解决方法,克服了传统方法人工设计特征提取器泛化性差的弊端。该方法以YOLOv5s为基础,通过引入RepVGG模块的方法对网络进行改进,同时利用Soft-NMS和Mixup算法来优化,在保持较高精度的前提下对模型大小进行压缩,大幅减少了网络的参数量,加快了网络推理速度,但是在目标尺度大小不一的情况下还会出现漏检问题。针对多尺度目标检测问题,考虑从改进网络neck部分入手,目前BiFPN在多种网络neck部分改进效果较好,可以有效解决多尺度问题,降低漏检率。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
课外生活·趣知识(2019年4期)2019-09-10
领导决策信息(2018年16期)2018-09-27
人大建设(2017年10期)2018-01-23
今古传奇·故事版(2017年5期)2017-04-08
数学学习与研究(2017年3期)2017-03-09
西南学林(2011年0期)2011-11-12
