
融合知识图谱与协同过滤的图书推荐算法
2022-08-25 09:56李灵慧黄树成王云沼
软件导刊 2022年8期
周 倩,王 逊,李灵慧,黄树成,王云沼
(1.江苏科技大学计算机学院,江苏镇江 212003;2.中国人民解放军陆军通信训练基地,北京 100029)
0 引言
随着互联网的发展,面对海量数据不断涌现,人们很难选择个性化的信息。由此,推荐算法应运而生,它能够缓解信息过载问题,并且为用户推荐感兴趣的信息[1]。在推荐算法中包括3 种较为流行的推荐:基于内容的推荐(Content-based Recommendation)、基于协同过滤的推荐(Collaborative Filtering-based Recommendation)以及基于关联规则的推荐。学者们也进行了大量研究,比如Hernando等[2]提出一种基于贝叶斯概率模型的用户评级协同过滤推荐预测方法;Zhang 等[3]将学生的学习轨迹、借书时间信息以及图书流通时间融入算法,提出一种基于时间序列的协同过滤个性化书籍推荐算法;赵杰[4]提出一种改进的LDA 用户兴趣模型用于个性化图书推荐,将借书者特征信息的相似度计算和借书者属性融入相似度计算方法;邹海涛等[5]利用局部网络拓扑结构组合模型,将用户自身购买历史与社交网络特征相结合,提升推荐结果准确度。
然而,上述算法没有考虑到图书本身的语义信息。知识图谱(Knowledge Graph,KG)作为最近新兴的辅助数据源,引起越来越多人的关注。例如,Zhang 等[6]利用网络嵌入和自编码器获取结构化知识的向量化表示、文本知识特征、图片知识特征,在将这3 类特征融合到协同集成学习框架实现个性化推荐;Wang 等[7]提出RippleNet 算法,通过在推荐算法中利用知识图谱并结合注意力机制得到用户的偏好特征表示,有效提高了推荐算法的准确性;Wang等[8]提出RKGE-CF 算法,将知识图谱实体嵌入与神经网络相结合,提高了推荐性能;李浩等[9]将物品的外部附加数据和用户的偏好数据加入知识图谱,提取实体与关系的语义,将结果与协同过滤推荐结果相融合,准确率有显著提升;Wang 等[10]提出KGCN 模型,利用用户和项目属性提出一种将知识图谱作为辅助信息的图神经网络推荐模型,有效缓解稀疏性和冷启动问题,提升推荐效果。
综上所述,为了更好地进行图书推荐,本文提出融合知识图谱与协同过滤的图书推荐算法。首先,利用TransE算法计算得到图书之间的语义表示,然后利用余弦相似性计算方法计算图书的语义近邻;然后,在协同过滤算法基础上利用同现相似度公式计算相似度,并改进相似度公式,加入活跃用户惩罚因子,减少热门书籍和活跃用户对结果的影响;最后,将两种结果通过创新性的高位替换低位方式融合形成最终推荐结果。本文算法融入了图书的语义信息,寻找图书之间的语义相似度,根据语义相似程度进行推荐,对改进推荐算法的物品冷启动问题有一定效果。
1 相关工作
1.1 基于图书的协同过滤推荐
协同过滤推荐算法是应用最为广泛的推荐算法之一,通过挖掘用户历史行为数据发现用户偏好,基于不同的偏好对用户进行群组划分并推荐品味相似的商品[11-12]。协同过滤推荐算法包括基于用户(User-based)和基于物品(Item-based)的协同过滤算法[13]。基于用户的协同过滤算法根据用户历史评分数据计算用户偏好物品,利用用户偏好物品寻找与用户偏好一致的用户,然后将寻找到用户的其他偏好商品推荐给该用户。而基于物品的协同过滤算法思想与基于用户的协同过滤算法类似,只是将用户变为物品,例如喜欢物品A 的用户都喜欢物品B,用户T 喜欢物品A,则给用户C 推荐物品B。
目前,各网上商城用户数量明显多于图书数量,因此本文采用基于物品的协同过滤推荐算法,且利用余弦相似度公式计算物品相似度。
1.2 基于知识图谱的推荐
与其他种类的辅助信息相比,知识图谱的引入可以让推荐结果具有可解释性且更加精确[14]。将知识图谱引入推荐算法,有以LibFM 为代表的基于Embedding 的推荐算法[15]和以PER、MetaGraph 为代表的基于Path 的推荐算法[16]。基于Embedding 的方法通常直接使用来自知识图谱的信息以丰富Item 或User 表示。该类算法可分为两类:基于翻译的模型,如TransE[17]、TransH[18]、TransR、TransD等;语义匹配模型,如DistMult等。基于Path 的方法通过构建User-item Graph,利用知识图谱中实体的连通性模式进行推荐。由于该算法利用的数据库为Book-Crossing,该图书数据库数据量大且较为稀疏,因此本文将采用翻译方法[19]中效果较好的TransE 方法。
2 本文提出的推荐算法
传统的图书推荐算法未考虑到图书语义信息的缺陷,因此本文提出融合知识图谱和协同过滤的图书推荐算法,首先通过知识图谱自学习算法,将图书语义信息转化为图书向量矩阵,然后利用相似性计算方法计算图书之间的相似性,形成图书语义相似性矩阵。利用协同过滤表示学习,根据用户—图书评分矩阵,获取图书—图书相似性矩阵,根据相似性计算结果获取协同过滤推荐集合,最后将两个结果通过一定比例的低位换高位算法进行融合。
本文算法流程如图1 所示。算法需要输入用户—图书评分矩阵Rm*n、图书知识图谱和评分矩阵—知识图谱对照表这3 部分,输出为融合知识图谱和协同过滤的图书推荐算法的推荐列表。具体流程步骤描述如下:
(1)根据评分矩阵—知识图谱对照表,将用户—图书评分矩阵Rm*n进行筛选,获取与知识图谱相关的评分矩阵R′m*n。
(2)利用评分矩阵获取图书集合,再计算图书与图书之间的相似性并得到图书相似性矩阵。
(3)利用TransE 算法进行训练,最后得到实体向量集E 和关系向量集R。
(4)获取知识图谱中的图书集合,利用上一步得到的实体向量集E,通过余弦相似度计算图书与图书之间的语义相似性并得到图书语义相似性矩阵。
(5)根据当前用户的历史评分数据,获取历史交互的图书列表,根据列表中的图书分别获取协同过滤推荐集合以及语义推荐集合,最后将两个推荐集合排序。
四是顺利启动实施世行贷款节水灌溉二期项目。配合河北、山西和宁夏三省(自治区)完成了世行贷款节水灌溉二期项目转贷协定的签订和项目启动实施工作,制定了项目和资金管理办法;组织开展了项目设计、实施方案技术性审核以及管理人员培训。
(6)选择融合比例,分别计算出协同过滤推荐集占比x及语义近邻推荐集占比y,然后取协同过滤推荐集中前x个成员及语义推荐集中的前y个数据。如果在取得过程中某个数据已经存在,则顺延取下一位。
2.1 协同过滤推荐算法
基于物品的协同过滤推荐算法是在用户—图书评分矩阵上为每本书找到K 个与之最相似的最近邻,根据相邻图书的相似度权重以及用户对图书的偏好计算相似度矩阵。在相似度方法选择中,本文使用同现相似度公式计算图书之间的相似度。

其中,分母|N(x)|是喜欢物品x的用户数,而分子|N(x) ∩N(y)|是同时喜欢物品x和物品y的用户数据。
由于图书会有畅销和冷门的区别,同现相似度公式容易形成任何图书都会与畅销书有较大相似度的现象,于是本文惩罚了畅销书的权重减少畅销书与很多图书相似的可能性。同时,图书推荐不仅有畅销书的影响,还会有活跃用户的影响。因此,本文还加入了对活跃用户的惩罚使推荐结果更加准确。

其中,|N(y)|表示喜欢图书y的用户数,喜欢图书y的用户越多,说明图书y越畅销,同时结果也会越小,两本书的相似度就会越低。u代表同时给图书x和图书y评分的用户,|N(u)|是用户u一共评分过的图书数量。用户u评价过的图书数量越少,结果就会越高,两本书的相似度也就越低,这样避免了畅销书及活跃用户对相似度的影响。
2.2 知识图谱
知识图谱的本质是一种揭示实体之间关系的语义网络,能够利用已存在的关系数据集判断未标注实体间的关系,使相似度计算结果更加准确[20]。图书知识图谱如图2所示。

Fig.2 Book knowledge graph图2 图书知识图谱
本文采用TransE 算法进行知识图谱训练。以往训练三元组的方法大多存在参数过多问题,以至于模型过于复杂难以理解,而TransE 算法能够有效学习三元组的向量表达。通过将每个三元组实例(head,relation,tail)中的关系relation 看作从实体head 到实体tail 的翻译,不断调整h、r和t(head、relation 和tail 的向量),从而使(h+r)尽可能与t相等,即h+r=t。TransE 算法训练得到图书语义向量矩阵及关系向量矩阵,再利用相似性公式将图书语义向量矩阵转化为图书语义相似性矩阵,最后可以得出每本图书的语义近邻。本文在选取相似性计算方法时,选用的是余弦相似度公式,如式(3)所示。
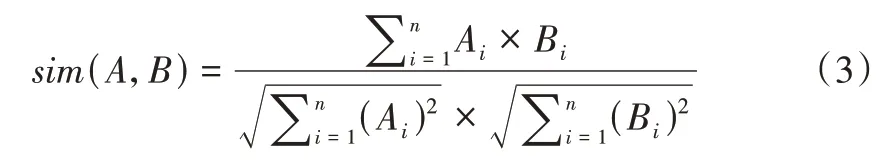
其中,当A、B 两个图书向量相似度越大,sim(A,B)数值就越接近1,知识图谱中两者的语义相似性越高,反之,相似性越低。最终计算出图书—图书语义相似性矩阵。根据相似度公式可以得知,矩阵是一个对称阵,即a(i,j)=a(j,i)。通过矩阵,可以获得每本图书的语义推荐集合。
为更好地实现新图书推荐(此处新图书指评分数据少于2 条的图书),在计算新图书的语义相似性时,加入阈值判断,即在计算图书A,B 的语义相似性时,判断图书B 是否为新图书,若B 是新图书,则会获取与图书A 相似性最大图书X 的相似度maxsim(A,X)以及与图书A 相似性最小图书N 的相似度minsim(A,N)),若sim(A,B) >(maxsim+minsim),sim(A,B)的相似度计算如式(4)所示。

这样既可以增加新图书语义推荐概率,也不会造成新图书与任何图书都有较大相似性的现象,对解决物品冷启动有一定意义。
2.3 算法融合
本文创新性地使用高位替换低位的方式进行融合,即首先将知识图谱推荐结果集及协同过滤推荐结果集按相似度大小倒序排序,然后将知识图谱推荐集合与协同过滤推荐集合按适当的比例选取相似度高的图书集成最优结果集。这样既考虑了外部评分数据,也考虑了图书语义信息,同时可以缓解新物品因为评分信息不足而无法得到推荐的现象。融合过程如下:

假定要为用户推荐N 本图书,ListCF为协同过滤算法推荐的集合(已排序),ListKG为语义相似度矩阵推荐的集合(已排序)。ListBook为最终给用户推荐的结果集,融合比例为x,其取值范围为x∈[0,1]。在最终推荐结果集中,若ListCF集合不为空,则ListCF集合的数量为其中为向下取整,ListKG的数量为kglen=N-cflen。融合算法根据输入的融合比例分别计算两个近邻集中数量占比。算法在取推荐数据时会判断结果集中是否包含本数据,最终得到结果集ListBook。
3 实验及结果分析
3.1 实验数据集
本文使用Book-Crossing 数据集进行测试。将该数据集信息转换为隐式反馈数据,其中每个条目都标有1,表示用户对该图书给予正面评价,并为每个用户采样一个标记为0 的未监视图书。此外,Book-Crossing 数据集数据较为稀疏,因此未设置肯定评分阈值。
知识图谱则利用Microsoft Satori 构建。首先从整个KG 中选择关系包含“书”的三元组子集,然后通过将Book-Crossing 中ID与三元组头部或尾部匹配以获取有效数据,同时排除没有匹配或者多匹配实体的项目。此时,Book-Crossing 中每一个ID都可以在三元组中找到对应数据,但三元组中头部或尾部在Book-crossing 中不一定有数据,即模拟现实中某些图书只有语义信息而没有评分信息。
本文将评分数据随机分为4 份,选取其中1 份作为测试集合,其他3 份作为训练集,每次实验结果运行5 次取平均值。数据集详细信息如表1所示。

Table 1 Book-Crossing data set information表1 Book-Crossing数据集信息
3.2 实验环境
实验硬件处理器型号为Inter(R)Core(TM)i5-1021U,内存为12G,软件环境为Python 3.7。
3.3 评价指标
对于推荐算法结果,本文使用3 个评价指标进行分析:精确率(Precision)、召回率(Recall)、F1 分数。3 个评价指标都可以根据混淆矩阵计算得出。精确率表示预测为正样本的样本中,正确预测为正样本的概率;召回率表示正确预测出正样本占实际正样本的概率;F1 分数折中了召回率和精确率,如式(5)—式(7)所示。

其中,TP代表样本的真实类别为正,最后预测得到的结果也为正,FP代表样本的真实类别为负,最后预测得到的结果为负;FN代表样本的真实类别为正,最后预测得到的结果却为负。
3.4 实验结果分析
实验将融合比例作为变量,显示不同融合比例下的推荐效果。本次实验选取Top-K 的K 值为10,定义相似图书数量为20。协同过滤推荐:对语义相似性推荐的融合比例从0∶10 到10∶0 分别做实验,每个融合比例均运行10 遍求平均值。精确率、召回率、F1 指标曲线如如图3 所示。横坐标为融合比例,纵坐标分别为精确度、召回率、F1值。从图3 可以看出,精确率、召回率、F1 在融合比例为5∶5 时效果最好,即进行Top-10 推荐时,协同过滤推荐与语义相似性推荐各占一半时,效果最好。

Fig.3 Curve of precision rate,recall rate and F1 score图3 精确率、召回率、F1 score指标曲线
本文选取经典和新的推荐算法进行比较,如KGCN 算法、RippleNet 算法和RKGE-CF 算法与CKCF 算法进行比较,验证本文算法的可行性和优越性。由于F1 分数折中召回率和精确率,则展示召回率和精确度指标上的对比结果。本文算法与KGCN,RippleNet 和RKGE-CF 算法在召回率和精确度指标上的对比结果如图4、图5 所示。从图4可以看出,不管K 值为多少,4 种算法的召回率不相上下,说明本文算法虽有优势,但优势不明显。
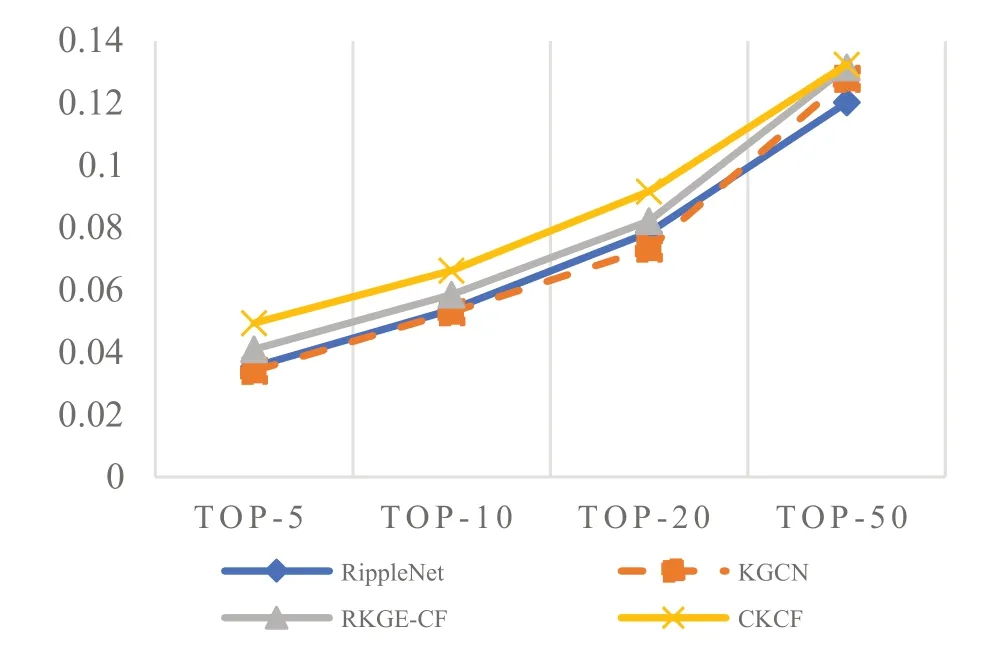
Fig.4 Comparison of recall rates of various algorithm图4 各算法召回率比较
从图5 可以看出,本文算法在Top-5、Top-10 优势明显,在Top-20 及Top-50 上也有一定提高。CKCF 算法在精确率指标上随TOP-K 的K 值呈递减趋势变化。精确率最高在TOP-5 时达0.043 7,与其他算法相比有明显提高。在TOP-50时达0.013 1,但相比其他算法仍有一定提高。
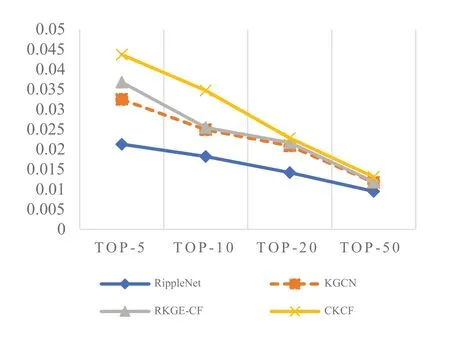
Fig.5 Comparison of precision of various algorithm图5 各算法精确率比较
综合考虑,本算法在计算物品相似度时不仅惩罚了热门图书还惩罚了活跃用户的比重,使得协同过滤推荐结果更加准确,同时基于知识图谱训练计算图书的语义相似度,然后将评分近邻与语义近邻相结合,从而提升推荐质量。
4 结语
本文提出一种融合知识图谱和协同过滤的图书推荐算法CKCF,通过协同过滤发现用户现有兴趣,同时利用知识图谱挖掘用户潜在兴趣,最后将两者融合以提升推荐效果。CKCF 算法能够利用TransE 将三元组数据转换为低维空间向量矩阵,获取图书实体向量矩阵。通过余弦相似度公式计算出每本图书之间的语义相似性,同时提升新图书的语义相似性,生成语义相似性矩阵并获取图书语义近邻。在获取协同过滤推荐集合时改进相似度计算方法,加入惩罚因子减少畅销书及活跃用户对推荐结果的影响。最后将语义相似性矩阵推荐结果与协同过滤推荐结果集融合,得到个性化推荐结果。本文算法在语义的层面上增强了协同过滤算法推荐效果,但算法还有待优化之处,如未考虑知识图谱关系向量矩阵,这为今后工作提出了新的思路。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
少先队活动(2020年12期)2021-01-14
河北画报(2020年8期)2020-10-27
开放教育研究(2020年2期)2020-03-31
中成药(2017年3期)2017-05-17
浙江大学学报(工学版)(2016年2期)2016-06-05
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
俄罗斯问题研究(2013年1期)2013-03-11
杂草学报(2012年1期)2012-11-06
