
基于Kinect视频的图像增晰与检测算法研究
2022-08-24 15:43:44查晶晶
太原学院学报(自然科学版) 2022年3期
查晶晶
(铜陵职业技术学院 信息工程系,安徽 铜陵 244000)
0 引言
目标检测是指在系列图像中检测到目标元素,并从大量的背景中提取处理。这项技术在视频监控、3D建模、人工智能等方面都有着大量应用,目标检测的精确性影响到计算机视觉技术、视频分析与处理等诸多领域的发展[1-3]。目标检测技术在人们生产生活和国防安全等方面都有着实际应用,例如利用该技术进行监控、导航,提升人们的工作效率,保障生活安全[4]。此外,还可以在战场上实现侦查、精确制导等功能,具有极高的军事价值[5]。因此,研究使用更高效的增晰算法来准确检测视频中的目标具有十分重要的现实意义。

图1 深度数据流Fig.1 Depth data flow
本文基于Kinect的捕捉功能,从目标检测和图像增晰两方面进行实验。通过对不同数据集测试,得到各个检测算法和增晰方法的优点,为深度视频处理提供重要的理论参考[6]。
1 相关理论与方法概述
1.1 深度图像与深度视频
Kinect(由微软发布的3D体感游戏的交互外设)包括一个红外摄像机、一个红外发射器和一个标准彩色摄像机,可利用红外结构光原理来测量深度,分辨率可达640×480。
深度图像(depth image)也可以被称为距离影像(range image),如图1所示,这类图像的像素值是从图像采集器到空间中每个点的距离,具体而言是每一帧图像在深度感应器的视阈内摄像头平面与物体平面之间的距离,能够清晰地表达出物体的外观。
图像在时间纬度组合成为视频,视频每一帧是一张图像,传统摄像头记录的图像是RGB图像,只有RGB三个纬度,Kinect除了RGB摄像头外,还有景深摄像头(深度摄像头),可以记录RGB-D图像,从而经过组合合成获取深度视频。
1.2 目标检测
选择主要HOG/HOD(histograms of oriented gradients,HOG; histogram of oriented depths,HOD) 框架和SSD(single shot multibox detector)算法进行研究[7]。HOG/HOD框架是一种基于稠密深度信息的人体检测方法,源于Kinect RGB-D传感器的深度特征,效果较为明显。
1.2.1HOG框架
HOG框架采用了在图像尺度空间的搜索来发现目标,可以在短时间内较快得出目标深度图像中不同方位所表示的尺度。从训练数据集中计算出平均人体高度Hm,数据集中地面位置和每个样本的高度都做了精确标注。此信息用来计算一个尺度到深度的映射,如公式(1)所示。
(1)
式中:Fy表示红外摄像机在垂直方向的焦距,mm;Hm表示人体的平均高度且Hm=1.74 m;Hw表示检测窗口在尺度为1 m时的高度,m[8]。
1.2.2SSD算法
SSD算法基于一个前馈卷积网络,并产生一系列固定大小的边界框,以及每一个框中包含物体实例的可能性(称为“分数”)。SSD网络与一般的CNN网络类似,它通过一次性输入n张300×300的图片,输出m个边界框相对偏移量和每个边界框对于每个类的“分数”。在SSD网络中,一共使用6个特征图来生成检测,每个特征图被分支到两个兄弟卷积层中,其中一个生成4m个边界框的相对偏移量,另一个生成c×m个类“分数”。假设一个特征图的大小为m×n,特征图的每个位置产生k个预测,每个预测需要c个类“分数”(c为类的个数+1)和4个相对于原始默认界框的偏移量,那么一个特征图总共会输出(c+ 4)kmn个数据[9]。
1.3 图像增晰
图像增晰就是采取特定的方法在原始图像上面增加额外的信息或者改变原始的数据,可以强调图像中某一部分的特征,更有利于排除那些不必要的特征,使得图像更容易获得与视觉之间的匹配度。对于RGB图像采用滤波技术将图像的相邻像素值用灰度中值或加权的方式替代,达到增晰的目的。而对于深度图则采用形态学图像处理方法,包括腐蚀、膨胀以及开、闭运算,算法如下:
(2)

(3)
式中:g(i,j)为(k,l)坐标处滤波后像素;f(k,l)为(k,l)坐标处原像素;w(i,j,k,l)为加权系数;S(i,j)为滤波后的像素集合;(k,l)为原图像中像素坐标;(i,j)为滤波后图像中像素坐标。
1.4 算法评估
为准确评价各算法的性能,分别采用准确率、召回率和耗时性能进行比较分析。
1.4.1准确率
(4)
式中:P为准确率,%;T为准确检测出目标人体的数量;F为检测出其他目标当作人体的数量。
1.4.2召回率
(5)
式中:R为召回率,%;T为准确检测出目标人体的数量;N为将人体检测为其他目标的数量。
1.4.3耗时性能
分别利用HOG算法和SSD算法对3个不同UR Fall Detection Dataset数据集中100帧图像进行检测,记录每帧所花费时间平滑线散点图。
(6)
式中:t为100帧图像检测消耗的平均时间,ms;ti为第i帧检测消耗的时间,ms。
2 结果与讨论
2.1 数据来源
数据都是源于UR Fall Detection Dataset数据集(编号1)、Crowd Human数据集(编号2)和INRIA数据集(编号3)。分别从目标检测和图像增晰两方面进行检测实验。其中,在目标检测实验中先将视频分割为图片,再分别利用HOG算法和SSD算法检测图片中的目标,最后再将图片拼接回视频。在图像增晰图片中,先将视频分割为图片,并针对RGB图像,采用中值滤波方法进行增晰,对于深度图像,采用膨胀与闭运算进行增晰。
2.2 图像增晰结果
选用Kinect采集到的UR Fall Detection Dataset数据集进行目标检测。对于数据集中的视频,使用FFmpeg工具将深度视频按帧截图,如图2所示。上层为RGB图像,下层为深度图,左侧图像为原始图,右侧图像为增晰后图像。

图2 原始图与增晰图对比Fig.2 Comparison between original image and enhanced image
从对比图中可以清晰地发现原始图画质较差,存在许多瑕疵。如图2所示,原始的RGB图像中噪点多,边缘模糊,如左侧图像中的椅子以及右侧图像中的人体。部分区域的色彩失真,如左侧图像中的桌子上部,以及右侧图像中门的左下部分。原始的深度图像中存在许多晕影,椅子等物体的边缘十分粗糙。对RGB图像分别采用中值滤波与双边滤波方法去除噪点。对于深度通道图像,采用形态学中膨胀以及闭运算两种方法结合进行增晰。最终得到图2所示的增晰图与原始图的对比结果。可以发现,增晰后的RGB图像在物体边缘上显得更加清晰,色彩失真的问题得到了解决,并且图像噪点明显减少[10]。增晰后的深度图像中噪点、晕影减少,整体画质在保持物体形状原样的前提下明显改善。
2.3 目标检测结果
2.3.1准确度分析
分别使用HOG算法和SSD算法对3个不同的UR Fall Detection Dataset数据集进行目标检测。在本实验中,使用MobileNet-V2大大压缩了神经网络的参数量,极大地加快了检测速度。部分检测结果如图3所示。上层为RGB图像,下层为深度图。

图3 部分图片检测结果Fig.3 Partial image detection results
同时,对HOG算法和SSD算法两者的召回率、精确率也做了对比检测,结果如表1所示。根据UR Fall Detection Dataset数据集,利用HOG算法进行目标检测,HOG算法的召回率稳定在75%左右,精确率稳定在80%左右。而SSD算法的整体召回率超过于90%,精确率超过于96%,两者数据都优于HOG算法。
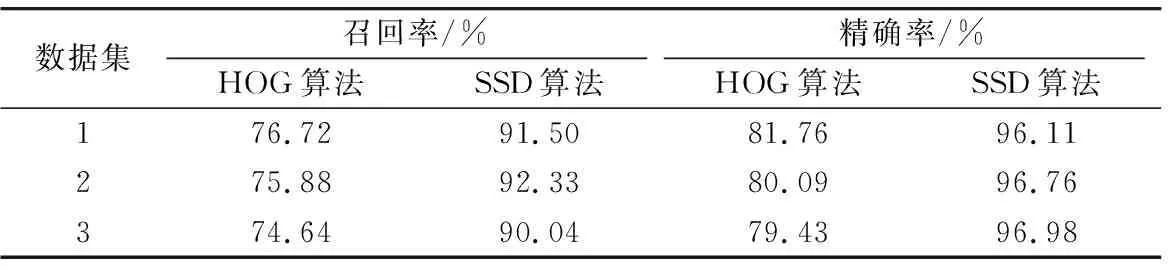
表1 HOG和SSD算法检测结果对比Tab.1 Comparison of detection results of HOG and SSD algorithm
2.3.2耗时性能分析
算法检测的耗时性能也是算法优越性的体现,HOG算法和SSD算法的耗时对比如图4所示。
图4下方3个波动的线条分别代表了HOG算法检测3个不同数据集中100帧图像每帧所花费时间的平滑线散点图;上方3条波动的线条代表的是SSD算法检测相同图像下的耗时。从图中可以看出,总体上HOG算法耗时平均105 ms左右,而SSD算法耗时则需125 ms左右。从图4中可知,虽然SSD算法的耗时要高于HOG算法,但其波动性相较于HOG算法是比较低的。SSD算法每次检测时都是在其基本网络结构下进行相同的运算,所以其耗时波动上不会太大。而HOG算法虽然平均耗时较短,但其是对整张图片直接进行分析运算,所以HOG算法会因图片本身的质量好坏而决定其计算开销,这也就是为什么HOG算法耗时波动性比较大的原因[11]。整体而言,无论是从召回率还是精确率来看,SSD算法都更优于HOG算法。

图4 HOG与SSD算法检测耗时对比Fig.4 Comparison of detection time of HOG and SSD algorithms
3 结论
目标检测和图像增晰是计算机视觉中重要的研究方向,为视频监控、图像分析等领域提供了重要价值。本文基于Kinect深度视频,在目标检测和增晰算法方面进行了深入研究。选取UR Fall Detection Dataset数据集进行了目标检测和图像增晰实验,得到以下结论:
1)HOG算法和SSD算法都能很好地实现目标检测,在检测召回率和精确率上,HOG算法略逊于SSD算法,而在耗时性能上,HOG算法则表现更为优秀。
2)采用中值滤波方法对RGB图像进行增晰,得到的图像在色彩、边缘等方面都有很好的改善。
3)采用形态学中的膨胀与闭运算方法以及像素替换法增晰深度图像,得到的图像在噪点和晕影方面得到了明显的减少。
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
中学生数理化·七年级数学人教版(2020年11期)2020-12-14 06:59:52
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14 01:14:28
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08 02:44:26
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26 06:03:48
CHIP新电脑(2016年3期)2016-03-10 14:22:03
空间控制技术与应用(2015年3期)2015-06-05 14:30:31
遥测遥控(2015年2期)2015-04-23 08:15:18
