
一种融合对抗层的图像通用对抗扰动生成算法
2022-08-24 10:24:32徐登辉巩敦卫孙晓燕
小型微型计算机系统 2022年8期
徐登辉,张 勇,巩敦卫,孙晓燕
(中国矿业大学 信息与控制工程学院,江苏 徐州 221008)
E-mail:yongzh401@126.com
1 引 言
深度学习自提出以来,已在计算机视觉[1]、语音识别、自然语言[2]等诸多领域得到了广泛应用,深度神经网络作为深度学习的重要组成,在图像分类和语音识别等任务中表现尤其突出.随着深度神经网络的快速发展及其迫切的商用需求,其安全隐患逐渐暴露出来,如人脸识别算法的非法认证、自动驾驶的恶意控制等.目前,深度神经网络的安全问题已经成为众多学者的研究热点.
对抗攻击作为神经网络安全的一个重要研究方向,学者们已经提出了多种对抗攻击算法.在处理图像分类问题时,Szegedy等[3]首次向图像添加微小扰动,以较高的置信度欺骗深度神经网络进行误分类.这些加入扰动后被误分类的样本称为对抗样本,产生对抗样本的方法称为对抗攻击.根据产生对抗样本时所需要获取的模型和样本信息的不同,可以将对抗攻击分为白盒和黑盒攻击.对于黑盒攻击,被攻击系统的详细信息隐藏且不可知,攻击者仅可以根据输入获得系统的输出.部分代表工作包括One-Pixel[4]、Zeroth Order Optimization (ZOO)[5]、Houdini[6]和Universal Perturbations for Steering to Exact Targets (UPSET)[7]等算法.对于白盒攻击,攻击者需要了解待攻击系统或神经网络的模型参数和结构等信息.典型算法有L-BGFS[3]、Fast Gradient Sign Method (FGSM)[8]、Hot/Cold[9]、Basic Iteration Method (BIM)[10]、Carlini and Wagner attacks(C&W)[11]、Jacobian-Based Saliency Map Attack (JSMA)[12]和DeepFool[13]等.由于可以有效利用系统信息,白盒攻击通常可以获得比黑盒攻击更好的攻击效果.本文所研究方法属于白盒攻击.
根据攻击适用的范围和维度,Yuan等[14]又将对抗攻击分类为个体对抗攻击和通用对抗攻击.在个体对抗攻击中,每个样本的对抗扰动互不相同.典型算法有DeepFool、C&W、Project Gradient Descent (PGD)[15]等.虽然这些算法在攻击过程中可以为每个样本单独产生最优的对抗扰动,但是当待攻击样本显著增加时,其攻击效率会大大降低.与个体对抗攻击不同,通用对抗攻击作用于整个数据集,新的输入样本只需添加已有的通用扰动即可生成对抗样本.这一特点在待攻击样本数较多和攻击时间有严格要求的领域尤为重要.Wang等[16]提出了一种将差分进化和粒子群算法相结合的通用扰动算法,并将其运用于图像分类问题.该算法首先利用差分进化计算出通用扰动,然后用计算结果初始化粒子群并继续优化.但是,该算法计算代价大,且难以有效解决图像分类中的维度灾难问题.Moosavi-Dezfooli等[17]将DeepFool应用于通用扰动问题,提出了通用对抗扰动生成算法Universal Adversarial Perturbations (UAP).该算法首次在深度神经网络图像分类问题中引入通用扰动的概念,利用DeepFool针对每个输入样本获得最小扰动,并逐一将分类边界内的大部分图像推到边界外.然而,如何准确设定算法终止运行参数,作者并未给出合适方法.
鉴于现有个体对抗攻击算法执行代价相对较长的不足,本文重点研究通用对抗扰动的生成.通过观察发现,基于梯度的对抗攻击方法大都依据像素变化梯度来寻求最优对抗扰动,这与神经网络权值的训练过程相类似.受此启发,本文研究一种融合对抗层的通用扰动生成算法.考虑神经网络训练过程中模型参数对所有样本“通用”这一特点,将求解通用扰动问题转化为训练神经网络参数问题,在神经网络输入层后加入对抗层,使用梯度上升法更新对抗层参数用以求得通用扰动.本文主要贡献如下:1)首次提出对抗层的概念,并将部分基于梯度的对抗攻击算法统一到对抗层框架中.该框架是对基于梯度的白盒对抗攻击算法的理论归纳和推广;2)提出一种基于对抗层的通用对抗扰动生成算法,具有所需样本数据少、攻击成功率高、通用扰动转移性好等优点;3)与多种典型的通用扰动算法进行对比,结果表明,所提算法仅需要使用少量样本数据,就可以获得较高的攻击成功率.
2 相关工作
本节主要介绍相关背景知识,包括深度神经网络的基本概念、几种典型的白盒对抗攻击算法和通用扰动算法.
2.1 深度神经网络
自从第一个神经元模型MP[18]被提出以来,神经网络至今已发展80年.深度神经网络出现之前的工作都可归为浅层神经网络模型.一个简单浅层神经网络包含输入层、隐藏层和输出层,其中隐藏层可以包含若干层.图1展示了浅层神经网络的结构.
神经网络的训练过程可描述为:沿损失函数的负梯度方向不断调整网络权重,使损失函数值最小.具体地,其网络权值更新公式如下:
Δw=-η∂J∂w
(1)
其中,w表示神经网络的权值,J表示损失函数,η为给定学习率.在训练过程中,根据J的梯度信息调整w以最小化损失函数.
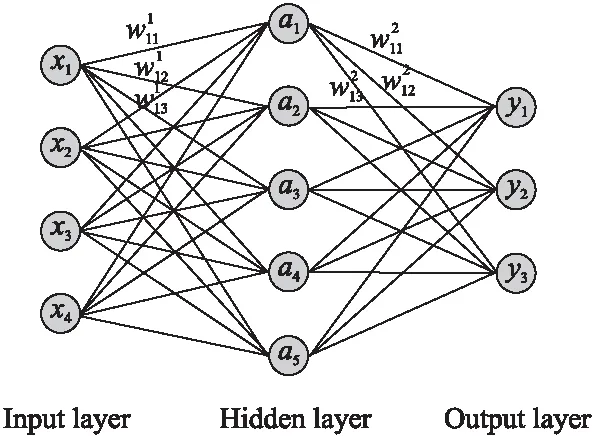
图1 神经网络结构图Fig.1 Neural network structure diagram
与浅层神经网络相比,深度神经网络(Deep Neural Networks,DNN)能够从数据中自动提取特征.随着网络深度的增加,模型的学习能力呈现指数增长[19].2012年,Krizhevsky等[20]首次在卷积神经网络中应用ReLU、Dropout 和LRN等技术,提出了AlexNet模型,展示了深度学习的强大能力.随后,诸多优秀的深度神经网络模型被提出.Simonyan等[21]通过在网络结构中反复堆叠3×3 卷积核,提出了具有19层的VGG模型,进一步证明了网络深度对提高模型精度的重要性.He等[22]使用残差块搭建了152层的ResNet模型.该模型通过跨层连接降低误差,解决了网络的退化问题.Huang等[23]从特征角度出发,通过特征复用和设置旁路,在大幅减少网络参数的同时也减轻了梯度消失问题.上述工作极大促进了深度神经网络发展.近些年,DNN获得飞速发展,诸多典型方法被提出,限于论文篇幅不再详述.
2.2 对抗攻击算法
本节首先给出对抗攻击的一般描述;随后,详细介绍4种典型的基于梯度的对抗攻击算法,包括FGSM、BIM、Iterative Least-likely Class Method (ILCM)[10]和Momentum Iterative Fast Gradient Sign Method (MI-FGSM)[24].基于这些算法,第3.3节将分析所提框架的一般性.
给定一个深度神经网络分类器f(·),输入样本为x,其标签为y,标签集合为l={1,2,…,m},有:
f(x)=y,x∈Rn,y∈l
(2)
无目标对抗攻击是获取一个满足约束条件的微小扰动δ,将其添加到x后生成导致分类器误分类的对抗样本:
x*=x+δ
f(x*)≠y,x*∈Rn,y∈l
(3)
无目标攻击要求x*分类错误,并不指定误分类标签.而目标攻击要求对抗样本被误分类到指定类别y*:
f(x*)=y*,y*≠y,y*∈l
(4)
1)FGSM算法[8]. Goodfellow等将对抗样本的出现归因于DNN在高维空间中的线性特性,提出了FGSM算法.该算法通过在损失函数J(x,y,w)的正梯度方向上添加扰动来增大损失函数值,产生对抗样本:
x*=x+δ
δ=ε*sign(▽xJ(x,y,w))
(5)
其中,ε表示对扰动幅度的限制,‖δ‖∞≤ε, ▽xJ(x,y,w)表示损失函数对x的梯度,符号函数sign于计算梯度方向而忽略其大小.
2)BIM算法[10].该算法是FGSM的迭代版本,基本思想是使用小步长α,经过多次迭代逐渐增大J(x*,y,w)值:
x*i+1=Clipx,ε(x*t+α·sign(▽xt.J(x*t,y,w)))
(6)
其中,t表示迭代次数,裁剪函数Clip用来裁剪x*,使其满足x*∈Rn.
3)ILCM算法[10].该算法选择预测分类置信度最低的类作为目标攻击类,在模型训练过程中将样本的正确标签改为指定类标签后进行训练.与传统训练过程不同,该算法基于梯度下降策略调整输入样本,而不是调整模型参数.具体样本生成方法如下:
x*t+1=Clipx,ε(x*t-αsign(▽xt.J(x*t,yll,w)))
yll=argmin(f(x))
(7)
4)MI-FGSM算法[23].该算法同时考虑当前和先前的多个梯度方向,使用它们的指数加权结果更新对抗扰动,达到避免算法陷入局部最优的目的,具体扰动产生公式如下:
x*t+1=x*t+αsign(gt+1)
gt+1=μ·gt+▽xJ(x*t,y,w)‖▽xJ(xt,y,w)‖1
(8)
2.3 通用对抗扰动
不同于先前针对单个样本寻找对抗扰动的方法,Moosavi-Dezfooli等[17]通过引入通用扰动的概念,首次给出了用来生成通用扰动的UAP算法.研究发现,针对某一个模型生成的通用扰动在其它模型上也具有良好攻击效果.随后,通用扰动算法得到学者们的广泛关注.Mopuri等[25]提出了一种无数据的通用扰动算法FFF (Fast Feature Fool),以各卷积层的输出乘积作为目标函数,直接优化更新通用扰动.该算法无需直接利用样本数据,适用于样本数据难以获取的攻击场景.然而,因为缺少样本数据,其攻击效果不佳.通过改进FFF算法,Mopuri等[26]提出了一种新的通用扰动算法GD-UAP.该算法将添加扰动的样本数据作为输入,将目标函数由各卷积层输出乘积改进为卷积层输出的2范数乘积.上述改进提高了算法的攻击效果,但是该算法只能用于无目标攻击,限制了其应用场景.Khrulkov等[27]计算神经网络每个隐藏层的雅克比矩阵的(p,q)奇异向量,仅需较少样本就能使通用扰动算法获得较好的攻击成功率.然而,不同隐藏层计算出的通用扰动的攻击效果差异很大,如何准确找到最佳隐藏层,论文中并没有给出合适方法.
3 所提算法
本节首先给出通用扰动问题的优化模型;接着,在详细介绍所提通用对抗样本产生框架的基础上,给出一种基于RMSprop的通用对抗样本产生方法;最后,将4种典型对抗攻击算法统一到所提框架下,定量分析所提框架的可扩展性.
3.1 问题描述
求解通用扰动问题就是寻找一个精心设计的扰动δ,在保证δ比较小以至于人眼难以感知的情况下,使得大多数样本在添加δ后被错误分类.利用神经网络的损失函数来定义优化目标,可以将该问题转化为一类带约束的优化问题:
arg maxδ1k∑ki=0J(x*i,yi,w)
s.t.x*i=xi+δ
‖δ‖p≤ε
(9)
其中,k为待攻击样本的数目,xi=[xi,1,xi,2,…,xi,n]是第i个待攻击的n维样本,yi是样本xi的真实类标签;δ=[δ1,δ2,…,δn]表示n维通用扰动.同时,为了满足人眼难以感知到样本变化,约束条件里通常使用Lp-范数限制δ.依据需求不同,p可以取0、1、2和∞等.
公式(9) 描述了以最大化分类错误率为目标的无目标攻击问题.当指定待攻击样本的错误类标签y*时,即f(xi+δ)=y*,y*≠yi时,通用扰动问题可以描述为如下目标攻击问题:
arg minδ1k∑ki=0J(x*i,y*,w)
s.t.x*i=xi+δ
‖δ‖p≤ε
(10)
3.2 所提通用对抗样本产生算法
通用对抗样本的产生过程实际上就是在所有待攻击样本上添加相同的扰动量δ.具体到深度神经网络,可以抽象为对输入层数据增加扰动的过程.因此,通用扰动在一定程度上可以看作是深度神经网络内部的一组待训练参数.鉴于此,本文首次引入网络对抗层概念,提出基于对抗层的通用扰动产生框架.在该框架中,对抗层作为一种新的网络层结构被加入到当前网络,进而将求通用扰动的过程转化为训练对抗层参数的过程.
3.2.1 算法框架
假设神经网络模型的输入层神经元为A=(ai,j)m×n,在输入层后添加一层对抗层R=(ri,j)m×n.该层神经元的排列与输入层相同,两层中相对应神经元之间相连.对抗层的产生过程描述如下:
R=f(A·W+b)
(11)
其中,W表示输入层与扰动层连接的权值向量,b表示偏移向量.f(x)是非线性激励函数,表示如下:
f(x)=cx
dx>d
(12)
其中,c和d表示输入样本取值范围的下限和上限.
公式(11)中,输入层和权值向量计算内积后与偏移量相加,最终通过激励函数得到对抗层.对抗层和后面网络层的连接方式、权重、偏置均与融入对抗层前相同.进一步,图2给出了融入对抗层后的深度神经网络的结构.图中对抗层添加在输入层与隐藏层之间,其偏移量b表示扰动,输出表示添加扰动后的对抗样本.输入图像正确类别为“Bird”,但加入扰动后错分类为“Cat”.
基于上述思路,通用对抗样本的生成过程即为深度神经网络对抗层参数的训练过程.算法1给出了所提通用对抗样本的产生框架.设X={x1,x2,…,xk}是从训练集中随机抽取的k个样本组成的训练样本集,训练样本迭代轮数设置为epoch;在每个epoch内将k个样本随机平均划分为P批次,每个批次包含l个样本.在算法初始化阶段,设置输入层和对抗层连接的权重w为1,偏置b为0.在算法每个批次内,先计算l个样本损失函数对b的平均梯度:
▽=1l∑lk=0▽bJk(x,y,w)
(13)
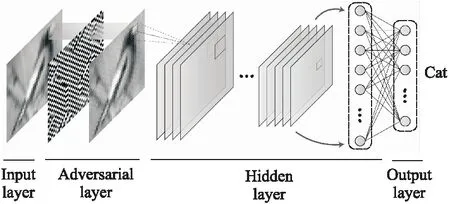
图2 融入对抗层后的神经网络Fig.2 Neural network integrates with adversarial layer
随后,使用优化器处理梯度并更新b.达到设定epoch后,算法停止运行.
本文所提框架的攻击方式取决于攻击目标或者样本分类标签的设置.当样本的分类标签设置为正确标签且使用梯度上升法增加损失函数时,所提算法属于无目标攻击;当样本的误分类标签设置为某一指定错误类且使用梯度下降法减少损失函数时,所提算法属于目标攻击.此外,所提框架中另一个重要参数是扰动限制条件.目前通常采用单个Lp范数限制扰动的大小.若将两个甚至多个范数综合考虑,可进一步保证扰动难以被人眼感知.
算法1.所提通用对抗样本的产生框架
输入:样本集X,损失函数J(x,y,w),分类器f(x),迭代次数epoch,范数限制ε;
输出:对抗扰动δ
1.初始化:轮回次数r, 批次p;扰动层的初始权值w=1, 偏置b=0;
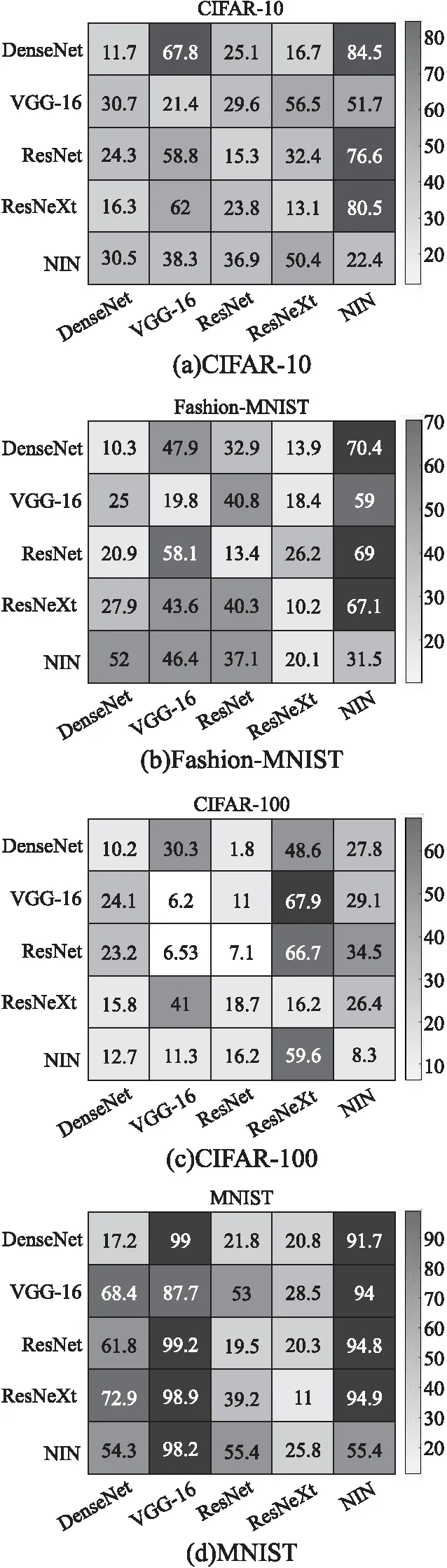
2.Forr 3. 将样本集X随机均分为P份,X=X′1∪X′2∪…∪X′p; 4.Forp 5. 利用公式(13)计算X′p中样本偏置b的平均梯度▽; 6. 使用优化器更新b和w; 7. End for 8. End for 9. 输出δ=b. 由所提框架可知,通过调整优化器和相关参数可以描述出不同的对抗攻击算法.所提对抗层框架可以协助研究者在模型训练完成后查找各种对抗攻击的梯度漏洞. 3.2.2 基于RMSprop的对抗样本产生算法 进一步,在上述框架中使用经典的RMSprop (Root Mean Square Prop)[28]优化器来更新b,本节给出基于RMSprop的对抗样本产生算法.算法2给出了RMSprop的具体步骤.相对SGD (Stochastic Gradient Descent)等传统优化器,RMSprop使用微分平方加权法计算给定窗口内的梯度,有效解决了损失函数在更新中摆动幅度过大的问题,加快了函数的收敛速度.需要说明的是,由于通用扰动的求取与网络训练过程相反,因此,我们使用b=b+Δb代替b=b-Δb.使用无穷范数作为扰动的限制条件,对超出限制的扰动使用Clip裁剪函数进行修剪.超参数衰减速率β默认设置为0.9,全局学习率α设置为0.001;eps设置为10-8,用于确保数值的稳定性.在算法2运行过程中,w不参与更新,恒等于1. 算法2.RMSprop优化器 输入:梯度▽,范数限制ε,衰减速率β,全局学习率α 输出:b 1.初始化:eps= 10-8 2.计算梯度加权平均值,s=βs+(1-β)▽2 3.更新b值,b=b+Δb,Δb=α▽s+eps 4.If‖b‖∞>εthen 5.Clip(b) 6.Endif 除上述微分平方加权法外,优化器还可以使用一些基于自适应学习率的梯度下降法,如AdaGrad[29]、AdaDelta[30]、Adaptive Moment Estimation (Adam)[31]等.这些优化器可以应用到对抗层框架,在加快训练的同时避免陷入局部最优. 本节将第2.3节给出的4种典型对抗攻击算法统一到所提对抗层框架下.尽管这些算法隶属于个体对抗攻击方法,但是它们都采用梯度策略来产生样本的对抗扰动.从扰动产生机理而言,所提对抗层框架是对这些方法的推广,即从单样本对抗扰动生成推广到通用对抗扰动生成. 1)FGSM的统一描述.设置本文算法的参数k=1,epoch=1,P=1,即只选择一个样本进行单步攻击,优化器使用公式(14)更新b,并用无穷范数‖b‖∞<ε限制b,那么,基于本文框架可产生FGSM. b=ε*sign(▽bJk(x,y,w)) (14) 2)BIM的统一描述.设置本文算法的参数k=1,P=1,即选择一个样本进行迭代攻击,优化器使用梯度上升法(即公式(15))更新b,那么,基于本文框架可产生BIM. bi+1=bi+α*▽bJk(x,y,w) (15) 3)ILCM算法的统一描述.如果攻击方式设置为目标攻击,指攻击类标签为yH,设置本文算法参数k=1,P=1,优化器使用标准梯度下降(即公式(16))更新b,那么,基于本文框架可产生ILCM. bi+1=bi-α*▽bJk(x,yH,w) (16) 4)MI-FGSM算法的统一描述.如果设置本文算法参数k=1,P=1不变,优化器使用动量梯度下降法(Momentum)更新b,即公式(17),那么,基于本文框架可产生MI-FGSM. vi=μ·vi-1+α·▽bJk(x,y,w) (17) 式中,μ是动量系数. 在常用的4个典型数据集上验证所提对抗样本生成算法.首先,第4.1小节介绍数据集、分类模型、评价指标;随后,第4.2-4.5小节针对不同的数据集和模型开展实验,与4种典型的通用扰动算法相比,分析所提对抗样本生成算法的有效性. 数据集:选择常用的MNIST、Fashion-MNIST、CIFAR-10和CIFAR-100数据集.其中,数据集MNIST和Fashion-MNIST包含70000张大小为28×28的灰度图像,共有10类,每类7000张.CIFAR-10和CIFAR-100数据集各有60000张大小均为32×32×3的彩色自然图像;CIFAR-10分为10类,包含交通工具和动物等,每类6000张图像;CIFAR-100包含100类,每类600张图像. 评价指标:为了有效评估算法的对抗攻击效果,采用分类准确率作为评价指标.它表示加入扰动后模型分类正确的样本占总样本的比例,准确率越低说明攻击效果越好.在目标攻击时,采用错误率评价攻击效果,它表示分类到指定攻击类的样本占总样本的比例.为了和其它算法进行对比,使用愚弄率(Fooling rate,FR)作为评价指标.愚弄率指添加扰动后预测标签改变的样本占总样本的比例. 对比算法:为了衡量本文所提算法的先进性,选择UAP[17]、FFF[25]、GD-UAP[26]和SingularFool[27]等4种通用对抗样本生成方法作为对比算法.尽管第3.3节将FGSM等方法统一到本文所提框架下,但是这些方法都隶属于个体对抗样本生成方法.因此,本文并未选择这些方法作为对比算法.为了便于对比,算法设置样本数量为1000.在4个数据集的分类模型上对比各个算法的愚弄率. 分别对每个数据集训练5种分类模型,包括DenseNet[23]、VGG-16[21],ResNet[22]、ResNeXt[33]和Network In Network(NIN)[34],测试集的准确率结果如表1所示.后续实验采用本文算法和4种对比算法生成对抗样本,攻击这5种分类模型,以判断本文所提算法的有效性. 表1 4个数据集上各个分类模型的准确率(%)Table 1 Accuracy of each classification model on 4 data sets (%) 本实验分析不同扰动限制下所提通用扰动产生算法的有效性.针对数据集CIFAR-10和CIFAR-100,依次设置扰动的无穷范数限制ε=0.02、0.03、0.04,折算到像素取值范围[0,255]中分别是5、8、10.针对数据集MNIST和Fashion-MNIST,依次设置扰动的无穷范数限制ε=0.04、0.1,其中,最大限制0.1折算后的值为26.在这两个数据集上适度增加扰动限制的原因是,由于这两个数据集是非自然图像,图像背景纯净且与前景反差大,适度增加扰动限制人眼也不易感知.训练通用扰动的样本数量K=1000,占数据集MNIST和Fashion-MNIST中总样本的1.7%,占数据集CIFAR-10和CIFAR-100中总样本的2%.使用测试集计算对抗攻击后模型的准确率. 在不同扰动限制下执行本文所提算法产生通用扰动,表2展示了添加扰动后5种分类模型在训练样本集和测试样本集上的准确率.可以看出:1)当扰动限制ε为0.04时,在数据集CIFAR-10和CIFAR-100上5种分类模型的准确率平均下降了74%和56%,其平均准确率只有17.46%和10.24%,模型分类结果完全不可信.与上述两个数据集的攻击效果不同,在ε为0.04时数据集MNIST的平均分类准确率仅降低了2.6%,攻击效果并不理想.对于数据集Fashion-MNIST,5种分类模型的准确率平均降低了42.6%,其攻击效果也十分有限.概括而言,在相同扰动限制下,所提算法针对不同数据集的攻击效果相差较大.这与数据集本身特点有较强关联.比如,对于数字边界清晰的数据集MNIST,较小的扰动对边界影响不大,因此,在同样扰动限制下,分类模型的准确率下降幅度较小.2)当ε为0.1时,对于数据集MNIST,通用扰动显著降低了DenseNet、ResNet和ResNeXt等3种分类模型的准确率;对于数据集Fashion-MNIST,通用扰动显著降低了所有5种分类模型的准确率. 训练样本数量K是本文所提算法中的一个重要参数.如果所选训练样本过少,由于神经网络参数训练不充分,算法可能无法产生最优的对抗扰动值;相反,如果所选训练样本过多,不仅会增加网络的训练代价,而且会带来过拟合现象.本节分析训练样本数量对本文算法所得通用扰动攻击效果的影响.选择数据集CIFAR-10和Fashion-MNIST作为测试对象,最大扰动限制ε依次设置为0.04和0.1,训练样本数量K从{10,50,100,500,1000,2000}中取值.在不同训练样本情况下执行本文所提算法产生通用扰动,表3展示了添加扰动后5种分类模型在训练样本集和测试样本集上的准确率.进一步,图3给出了表3实验结果的柱状图. 可以看出:1)对于数据集CIFAR-10,当K=10时,5种分类模型在训练样本集上的平均准确率为24%,在测试集上的平均准确率仍有59.7%,两者相差35.7%.这意味着,规模为10的训练样本集不足以代表总体,无法找到理想的通用扰动.当K=100时,5种分类模型在训练样本集和测试集上的平均准确率分别为26.8%和41.1%,两者相差14.3%;随着训练样本数目的增加,训练样本集和测试集上的平均准确率的差值显著缩小.当训练样本数量上升至500时,DenseNet、ResNet和ResNeXt等3个分类模型在训练样本集和测试集上的准确率的差值缩小至1%.这说明,当训练样本数量只占总数据集规模的1%时,所提算法就能得到相对较好的通用扰动.2)类似地,对于数据集Fashion-MNIST,随着训练样本数目的增加,训练样本集和测试集上的平均准确率的差值也显著缩小.当训练样本数量为500时,5种分类模型的准确率基本不再下降.本文所用数据增强和Dropout方法使对抗层算法所求通用扰动具有很好的泛化性能,可以有效防止通用扰动过拟合到训练样本,因此只需要不到1%的样本就能找到有效的通用扰动.换句话说,在只能获取小部分训练样本进行对抗攻击的场合,所提对抗层算法仍然可以获得较为理想的攻击效果.3)从图3中可以直观看出,随着训练样本数量的增加,测试集的准确率呈现明显的下降趋势. 表3 不同训练样本数量下融入通用扰动后5种分类模型的准确率(%)Table 3 Accuracy of 5 classification models after adding universal perturbation under different rain samples (%) 图3 不同训练样本数量下5种分类模型的准确率变化趋势Fig.3 Change trend of the accuracy of the 5 classification models under different number of training samples 4.4.1 愚弄率比较 为了探究本文所提算法与对比算法的优劣,本节针对每个数据集的5个模型计算其添加通用对抗扰动后的愚弄率.在数据集MNIST和Fashion-MNIST上设置无穷范数限制ε=0.1,另两个数据集设置ε=0.04.实验结果如表4所示.可以看出,在同等限制条件下,除CIFAR-100数据集的ResNeXt模型外,本文所提对抗层算法在其余数据集和模型上均取得最好的攻击效果.表中也列出了每个算法在5个模型中的平均愚弄率.本文所提对抗层算法均取得最高的平均愚弄率,比如在CIFAR-10数据集上其平均愚弄率达到83.6%,明显好于其他对比算法.为了便于直接观察产生的通用扰动,以CIFAR-10数据集为例,图4给出了在DenseNet模型上所产生通用扰动的可视化结果和扰动前后样本对比. 图4 CIFAR-10通用扰动可视化及添加扰动前后对比Fig.4 Visualization results of universal adversarial on CIFAR-10and comparison before and after adding adversarial perturbation 4.4.2 迁移效果比较 本小节分析通用扰动在模型间的迁移攻击效果.将针对某一分类模型生成的通用扰动添加到其它模型,观察通用扰动跨模型的迁移攻击效果.首先设计实验观察本文所提算法在4个数据上的迁移攻击效果.针对纵轴模型生成的通用扰动添加到横轴模型上,以热力图的形式展示结果.图5展示了在4个数据集上经过迁移攻击后分类模型的准确率.然后,以CIFAR-10数据集为代表,计算对比算法迁移攻击后的愚弄率,实验结果如表5所示. 表4 本文算法与4种对比算法针对5种模型所得愚弄率(%)Table 4 Fooling rates obtained by the proposed algorithm and 4 comparison algorithms on 5 classifier models (%) 由图5可知,对角线上的模型分类准确率为所在列的最低值.这说明,将针对一个模型产生的通用扰动迁移到其它模型后,其攻击效果会不同程度的减弱.但是,同时也能看到,迁移后通用扰动在一些模型上也取得了相对较好的迁移攻击效果.例如,关于数据集CIFAR-10 (见图5(a)),DenseNet 模型在添加其它模型的通用扰动后,其准确率下降均超过60%;关于数据集Fashion-MNIST (见图5(b)),ResNeXt 模型在添加另外4个模型的通用扰动后,其准确率平均下降了75.3%.这说明,针对部分数据集,所提对抗层算法得到的通用扰动可以很好的应用于其它分类模型.同时,我们发现,由于数据集本身和分类模型结构的差异,一些模型在特定数据集上表现出了较强的鲁棒性或抗攻击能力.例如,NIN网络在CIFAR-10、Fashion-MNIST和MNIST上防御跨模型通用扰动能力较强,准确率分别平均降低13.4%、26.7% 和5.1%. 为了比较本文算法和4种对比算法(UAP、FFF、SingularFool和GD-UAP) 的通用扰动迁移攻击效果.以数据集CIFAR-10为测试对象,表5给出了在模型之间迁移通用扰动的愚弄率.通过统计各个算法在迁移攻击中取得最大愚弄率的个数来评价算法的优劣.本文所提对抗层算法共取得7个最大愚弄率,其次是SingularFool,取得了6个最大愚弄率.这表明,与4种对比算法相比,所提对抗层算法具有更好的迁移攻击效果. 综上所述,本文所提对抗层算法得到的通用扰动除了在样本之间通用外,在模型间也有一定通用性.这意味着,对抗层算法具有一定的黑盒攻击能力.在分类模型内部结构不可知的情况下进行攻击时,可以先利用替代模型计算出一个通用扰动,再将该通用扰动迁移到目标模型,最终实现黑盒攻击. 4.5.1 目标攻击效果分析 在一些要求更高的攻击场景中,需要将样本攻击到指定的错误类别,这就需要攻击算法具有较好的目标攻击能力.为了验证本文所提对抗层算法的目标攻击效果,针对数据集CIFAR-10和Fashion-MNIST,选择DenseNet模型为代表进行目标攻击,扰动的无穷范数限制分别为0.04和0.10.图6展示了DenseNet模型的目标攻击错误率,其中纵轴为原始类,横轴表示指定类,表内数据表示错误率.可以看出,针对两个数据集,本文所提算法对DenseNet模型进行目标攻击的平均错误率分别达到83.5%和82.6%.这说明,超过8成的样本被误分到指定错误类,所提对抗层算法在目标攻击中仍然能够保持较好的攻击效果.进一步,统计每个类别的平均错误率,发现目标攻击存在类别不均衡现象.例如,从目标类方面来看,图6 (a)中指定目标类为2时本文算法所得平均错误率为90.5%,而目标类为7时,所得平均错误率降到69.4%.从源类方面来看,第6类攻击到目标类的平均错误率为74.5%,显著低于其它类.在攻击模型时,可以选择平均错误率更高的类作为目标攻击类. 图5 针对4个数据集本文所提算法的跨模型迁移攻击准确率(%)Fig.5 Accuracy of the cross-model transfer attack of the proposed algorithm for 4 data sets (%) 图6 DenseNet模型的目标攻击错误率(%)Fig.6 Target attack error rate of DenseNet model (%) 4.5.2 对抗样本类别非均衡分析 为了进一步探究对抗样本分布非均衡对所产生通用扰动的影响,统计添加通用扰动后模型预测结果的分布情况.针对数据集CIFAR-10和Fashion-MNIST,图7展示了添加通用扰动后模型所得类标签的分布百分比.可以看出,添加通用扰动后的对抗样本的预测结果大都集中在某一个特定类.针对数据集CIFAR-10,预测结果主要集中在“Cat”和“Frog”类;对于数据集Fashion-MNIST,则主要集中在“Bag”和“Shirt”类.这意味着,针对不同数据集,分类模型的鲁棒性存在较大差异.对抗层算法就是将鲁棒性较差的类样本扰动至分类边界外,进而使大部分对抗样本的预测标签属于某一特定错误类. 图7 添加通用扰动后各模型的分类结果(%)Fig.7 Classification results of each model after adding universal perturbation(%) 本文通过在深度神经网络中引入对抗层的概念,提出了一种基于对抗层的通用对抗样本产生框架,通过改变样本数量、优化器和迭代次数等参数,可以将多种典型的基于梯度的对抗攻击算法统一到该框架内.随后,给出了一种基于RMSprop的通用对抗样本产生算法.针对4个典型的实际数据集,与UAP、FFF、SingularFool 和GD-UAP等典型通用扰动算法相比,实验结果表明,所提算法仅需要使用1%的样本数据,就可以获得较高的攻击成功率,并且该通用对抗扰动在模型间具有较好迁移效果.3.3 所提框架下典型方法的统一描述
bi=bi-1+vi4 实 验
4.1 实验设置

4.2 最大扰动限制的影响分析
4.3 训练样本数量的影响分析


4.4 与4种通用扰动算法的对比


4.5 进一步分析


5 结 论
猜你喜欢
数学物理学报(2022年4期)2022-08-22 04:06:36数学物理学报(2021年6期)2021-12-21 06:24:38应用数学(2020年2期)2020-06-24 06:02:50科技创新与应用(2020年6期)2020-02-29 10:39:27数学物理学报(2019年4期)2019-10-10 02:38:56数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:52贵州师范学院学报(2016年3期)2016-12-01 03:53:52北京理工大学学报(2016年6期)2016-11-22 11:17:22电视技术(2016年9期)2016-10-17 09:13:41系统工程与电子技术(2016年7期)2016-08-21 13:59:00
