
注意力残差模型的语音抑郁倾向识别方法
2022-08-24 10:24:30鲁小勇石代敏原静仪董强利马秀云
小型微型计算机系统 2022年8期
鲁小勇,石代敏,刘 阳,原静仪,董强利,马秀云
1(西北师范大学 物理与电子工程学院,兰州 730070)
2(互联网教育数据学习分析技术国家地方联合工程实验室,兰州 730070)
3(甘肃省行为与心理健康重点实验室,兰州 730070)
4(兰州大学 第二医院心理卫生科,兰州 730030)
E-mail:luxy@nwnu.edu.cn
1 引 言
据世界卫生组织的统计数据显示,全球约有3.5亿名患者被抑郁症困扰,其中国内抑郁患者高达5400多万[1].抑郁障碍的终身患病率高达6.8%[2],给自己、家庭及朋友带来巨大的心理压力.然而,以往大多数研究聚焦于抑郁症患者,忽略了对抑郁倾向群体的研究.但当下心理健康异常抑郁倾向人群占比更大,对该群体进行准确识别,继而进行及时干预可有效阻断向抑郁症的转化.
通常,抑郁症的诊断以主观量表评测为主.诊断结果往往与患者的配合程度及临床医生的经验、专业水平紧密相关[3].近年来,抑郁患者的数量急剧增加,为此,如何准确、快速地进行抑郁倾向诊断是相关人员面临的巨大挑战.采用计算机实现抑郁倾向诊断可以为临床医生提供一个新的切入点.语音的非侵入式、相对易获取等特征和有效性已被证明是评估抑郁的可靠客观指标[4].例如,研究发现与健康对照被试相比,其发声特点表现为声音低沉、缓慢、犹豫、单调等[5,6],临床水平与韵律特征之间存在显著相关性[7,8].此外,深度学习技术的兴起促使研究人员探索用于评估抑郁的不同深度架构和方法[9,10].
传统的抑郁症识别任务的关注点主要聚焦在如何选择更优的特征和分类器[11].随着深度学习的快速发展,研究者们将重心转移到如何去构建深度神经网络去实现特征的自动提取与分类.文献[12]提出一种基于DCNN的抑郁症识别方法,通过将手动提取的特征和神经网络提取的高层次特征相结合来达到识别抑郁症的目的.文献[13]提出一种基于CNN的集成学习方法,在AVEC2016(Audio/Visual Emotion Challenge and Workshop,AVEC2016)数据集上进行了评估,取得了很好的效果.文献[14]提出一种结合CNN和LSTM的深度模型,在训练阶段引入随机抽样策略来平衡样本,能够让分类结果不出现偏差.文献[15]将语音的频谱图和梅尔频率倒谱系数(Mel frequency cepstrum coefficient,MFCC)分别输入到CNN网络,采用DCNN在公开数据集AVEC2017上识别抑郁症.
针对传统抑郁识别方法存在特征维度过高、需手动提取特征,以及经典的深度学习模型在深度过深时存在梯度消失、提取深层次特征时表现差、模型复杂和多参数导致训练费时的问题.本文借助残差神经网络(Residual Networks,ResNet)思想在特征提取和预防梯度下降方面的优势以及在获得精细化特征时注意力机制的高效性,提出注意力残差抑郁倾向分类算法.本文的主要贡献如下:
1)基于心理学SRE经典实验范式流程采集抑郁语料.
2)在残差模块中引入注意力机制的思想,并将两者相结合得到注意力残差单元,最后将注意力残差单元堆叠得到高性能的注意力残差模型.
3)语音的MFCC特征能表征抑郁倾向识别的关键特征,从语音片段中提取MFCC特征,输入到构建的注意力残差模型中进行抑郁倾向的识别.
2 抑郁倾向识别模型
本文提出的语音抑郁倾向识别整体流程如图1所示.首先,设计语料采集方法;然后,对采集的语音语料进行处理;最后,构建基于MFCC特征的注意力残差抑郁倾向识别模型并获得分类结果.

图1 语音抑郁倾向识别整体流程图Fig.1 Flow chart of speech depression tendency recognition
2.1 网络架构
近几年,鉴于残差网络对特征的高学习能力,被应用在各领域,本文发现残差网络在抑郁倾向识别方面有高表现力.除此之外,语音的MFCC特征更能表征抑郁特性,加之声音的信息通过图像的形式输入到卷积,特征图的纹理和轮廓特征的很多区域像素值很低,具有稀疏性,减少了训练的时间,而且还能让网络学习的难度降低,容易收敛.鉴于此思想,本文将语音的MFCC特征以图像的形式输入,利用网络卷积层学习深层次特征,然后特征输入到堆叠的残差注意力模块在不同维度(通道、空间)变换与提取.由于采用残差卷积的深度不同,所以堆叠的残差注意力模块的数量也有所不同,网络的性能也随之改变.
2.2 残差模块
ResNet不是输入、输出的直接映射,而是拟合残差函数的理念.将F(x)作为由前馈神经网络层堆栈拟合的直接映射函数,其中x表示该层的输入,假设前馈神经网络层的堆栈可以近似为复变函数,那么前馈神经网络层可以近似为残差函数,即F(x)-x.因此,残差函数可近似表达为H(x)=F(x)-x,通过对方程进行重新构架,原始函数H(x)=F(x)+x[16].残差网络通过短连接将低层的特征直接映射到高层网络中,该思想不仅让输入的语音信息绕道输出,而且保证了信息的完整性.
2.3 注意力模块
根据文献[17]中CBAM(Convolutional Block Attention Module),注意力模块包括空间注意力模块和通道注意力模块.通道注意力如图2所示,在对通道进行压缩时,不仅考虑平均池化层而且考虑最大池化层对通道信息进行特征映射,并送入共享网络来压缩输入特征的通道维数,最后,逐元素求和以生成空间注意力模块需要的输入特征.

图2 通道注意力Fig.2 Channel attention
空间注意力如图3所示,是将特征在空间维度上压缩为一个一维矢量后再进行操作.在空间维度上进行压缩时,将通道注意力学习的特征,依次经过最大池化层和平均池化层,进行特征在空间维度上的学习,最后将学习的特征输入到下一层的卷积层进行下一轮的特征提取.

图3 空间注意力Fig.3 Spatial attention
2.4 注意力残差模块
近年来,由于注意力机制技术可以使网络更好的集中在特征提取上,逐渐成为研究热点.在残差基础上加入注意力机制模块可以使网络关注到更全面的信息,提升残差网络的表示能力,弥补残差网络在关注于局部信息方面的缺陷型.
在本文,考虑到注意力模块与残差模块在特征学习方面的优势,为提高模型的性能,将注意力模块与残差模块相结合,构建注意力残差模块.提取的特征经过前面的卷积层后,依次通过通道注意力模块和空间注意力模块,最后特征和残差模块相加输出到后面的卷积层.
残差网络的卷积层有一定的通道数,通道注意力的加入可以更好的让卷积层的每个通道学习与抑郁倾向识别相关的特征,抑制与抑郁倾向不相关的特征,从而达到让网络集中在所需特征上的目的.空间注意力模块可以更好的定位相关特征的条纹和轮廓位置,让网络集中于表征抑郁倾向的特征上.
2.5 基于MFCC的注意力残差模型
MFCC特征的许多优点之一是它具有承受噪音的能力.MFCC可以表示人耳关键带宽随频率的变化,并且它们可以用梅尔频率标度来捕获语音的关键特征.在本文,对预处理后的语音片段,采用python的librosa库函数生成MFCC特征.
在图4所示的注意力残差网络中,共有五个卷积模块,每个卷积模块是由卷积核,批归一化层(Batch Normalization,BN)及激活函数(Relu)组成的多个卷积层所组成.因注意力机制在通道维度和空间维度获得自适应的精细化特征的特点,在残差神经网络中引入注意力机制,从处理后的语音片段中提取的MFCC特征输入第一个卷积模块后,将经过卷积模块提取的特征输入到下一卷积模块,并依次通过通道注意力模块和空间注意力模块,然后将卷积模块提取的特征与在不同维度提取的特征相加输入到后面的卷积层,直到第五个卷积模块.最后,经过平均池化层和展平层,用Softmax激活函数进行分类,得到输出结果.网络中的Conv1的卷积核大小为7×7,步长为2,其余每个卷积层使用3×3的卷积核,步长为2.
在残差网络中,经过3个卷积层绕过残差路径以处理梯度问题.损失函数采用分类交叉熵,该模型为减少训练的时长不使用丢弃率.当模型的输入和输出尺寸在大小相匹配时,直接使用残差路径.否则,根据恒等映射来补零增加尺寸,进行大小匹配.对每阶段的卷积层都进行批归一化处理,然后依次激活.算法:
输入MFCC特征
输出 识别结果
步骤1.对语音数据切分,扩充模型训练的样本量.
步骤2. 寻找最佳的学习率值,这时损失函数值仍在下降.
步骤3.冻结前面的注意力残差层,留最后一层.
步骤4.训练最后一层.
步骤5.解冻前面的注意力残差层.
步骤6.再次寻找最佳学习率值,此时损失函数值仍在下降.
步骤7.训练整个网络,直到网络过拟合.
在分类任务时二分类时,Softmax[18]退化为逻辑回归分类.本文对采集的语音根据BDI-II量表得分的标签实现对抑郁倾向的分类.Softmax回归的决策函数为:
=argmaxy∈{0,1}ωTyx
(1)
其中,y表示类别标签,x表示样本,ω为权重向量。
3 实验结果与分析
3.1 语料采集
25名抑郁倾向被试均来自在校大学生.由经过良好培训的实验人员依据汉密尔顿量表(Hamilton Depression Scale,HAMD)[19]对被试进行抑郁障碍的诊断性评估.在测试期间所有被试不存在药物依赖与滥用及其他精神疾病,没有严重的躯体障碍、自杀等危险行为.
同时,25名健康被试作为控制对照组参与了本研究.他们均来自广告招募的在校大学生.健康对照组被试与抑郁倾向组被试在性别、年龄和受教育程度上没有明显差异.在实验前,对抑郁倾向被试和健康对照被试重新进行了9项患者健康问卷(Patient Health Questionnaire-9,PHQ-9)[20]和贝克抑郁量表(Beck Depression Inventory,BDI-II)[21]评估,以排除不符合要求的被试,筛选出符合要求的被试,并签写了知情同意书.
抑郁倾向被试入组标准:1)年龄介于18-25;2)BDI-II量表分值在14-28分之间,表明患者的抑郁程度为轻度到中度;3)无其他精神疾病和自杀行为发生;4)无药物依赖与滥用以及器质性疾病;5)在外表无明显的抑郁特征与标志;6)无攻击性,并且有能力独自理解和配合完成实验.
健康对照组被试的入组标准:1)年龄介于18-25;2)BDI-II量表得分在14分以下,表明被试无抑郁倾向;3)PHQ-9量表和BDI-II量表评估得分均在正常范围内;4)无躯体障碍史.所有被试普通话标准、右利手和正常视力或矫正视力正常.在实验前,所有被试均签署了知情同意书.表1报告了详细的人口统计信息.
若整个录音过程持续进行,被试的注意力或反应能力可能会有所降低,因此录音过程分为多个阶段进行,中途被试稍作休息和停顿.语料采集的场景如图5所示.

图5 数据采集场景图Fig.5 Data collection scene
抑郁症个体存在自我加工和自我识别的损害,存在着消极的自我参照,对自我过度关注,为此,本研究借助心理学SER经典范式来设计抑郁语料.采用了2(被试类型:健康对照组、抑郁倾向组)×3(情绪状态:正、中、负)×4(任务类型:词汇朗读、短文朗读、访谈、图片描述)的实验设计方式.
在实验中,我们向被试呈现词汇、短文、图片和访谈任务完成语料的设计.实验在专业的录音棚进行,所有任务和指导语均在同一电脑程序中,被试坐在距离电脑约1米的位置.录制的语音采样率为44.1kHz,16bit量化以单声道格式保存为WAV文件.各录音任务对应的时长和统计信息如表2所示.
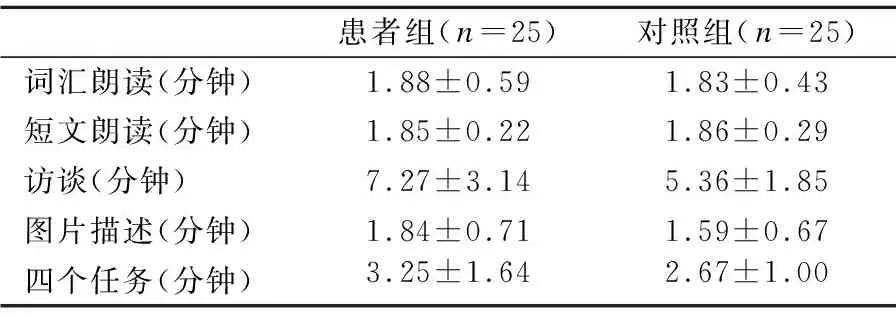
表2 抑郁倾向被试与健康对照组的录音时长*Table 2 Recording duration of depressive individuals and healthy controls*
3.2 数据预处理
为了得到优化的特征,本文去除了设备的杂音、被试的咳嗽声、读错以及重读部分和主试干扰被试,例如纠正错误发音和提示任务的具体细节部分.为了避免被试语音的个人特征影响实验的准确率,使用Python以编程方式剪切被试的长时间沉默段语音,一方面保证实验的准确性,一方面扩充语料,其中每个被试的访谈被剪切成4秒的片段[13,15].原始数据集共有196样本定义为数据集A,按照4s切分后的样本定义为数据集B,如表3所示.

表3 原始数据与切分数据分布表Table 3 Original data and segmented data distribution table
对训练数据依据BDI-II量表得分进行标注.本文利用重采样将原始录制的语音样本的采样率44.1kHz降到16kHz.
3.3 实验环境
为进行本文方法的合理评估,实验的硬件、软件环境如下.
硬件环境:处理器:56 Intel(R) Xeon(R) CPU@2.00GHz;GPU:两块 NVDIA GTX TITAN XP,25GB;内存:16GB.
软件环境:操作系统:Ubuntu18.04.3;编程语言:Python3.6;深度学习框架:Pytorch1.3以及Sklearn、CUDA10.0.
3.4 模型参数
实验采用的优化是随机梯度下降法(Stochastic Gradient Descent,SGD),学习率为0.0001,损失函数由于SGD频繁更新会造成严重的震荡,加入了动量(momentum)优化来加快收敛并减小震荡.损失函数选用学习率为0.001的交叉熵损失 (Crossentropy Loss).在训练模型时,正则化方法被采用防止过拟合,模型参数值具体见表4.

表4 模型超参数配置Table 4 Model hyperparameter configuration
3.5 评价指标
为了对选用特征的分类性能进行评估,在表5中,抑郁分类的准确性评估原则可以通过真正例(True Positives,TP)、真负例(True Negatives,TN)、假正例(False Positives,FP)和假负例(False Negatives,FN)来表示.

表5 分类结果混淆矩阵Table 5 Confusion matrix of classification results
在表5中,TP表示(模型预测结果和实际标签均为抑郁倾向),FP表示(模型预测结果为抑郁倾向,实际标签为健康),TN表示(模型预测结果和实际标签均为健康)和FN表示(模型预测结果为健康,实际标签为抑郁倾向)由上述4个量可以定义以下4个常用评价指标:
Accuracy=TP+TNTP+TN+FP+FN×100%
(2)
Precision=TPTP+FP×100%
(3)
Recall=TPTP+FN×100%
(4)
F1score=2TP2TP+FN+FP×100%
(5)
其中,Accuracy为准确率,指在所有的样本中正确识别抑郁倾向和健康的样本占所有样本的比重,Precision称为精确率或查准率,指被预测为抑郁倾向的样本中,真正类别为抑郁倾向样本所占比例,Recall称为召回率,表示所有真实类别为抑郁倾向样本中被正确预测为抑郁倾向样本所占的比例,F1 score称为F1分数,是一个综合指标.
3.6 对比实验设置
不同分类器对语音特征的提取能力有差异,本文选用在分类任务中实践结果较好的分类器,包括高斯混合模型(Gaussian Process,GP)、支持向量机(Support Vector Machines,SVM)、k-比邻(k-Nearest Neighbor,KNN)和AdaBoost算法作为对比实验.
3.7 结果分析
A)基于注意力残差实验的结果
从预处理后的语音数据中提取MFCC特征,将其输入到不同深度的分类算法中,结果如表6所示.本文将未加入注意力机制时的残差模型作为基线与注意力残差模型输入相同的特征进行对比,以此来验证注意力机制对实验结果的影响.
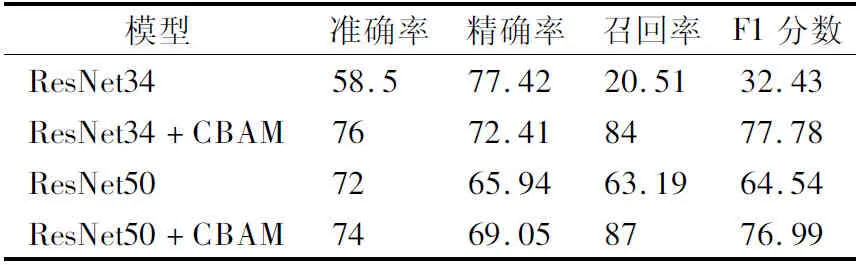
表6 MFCC预测结果(%)Table 6 MFCC predict results (%)
结果表明,加入注意力机制后,分类性能相对于基准模型明显提升,4个评价指标均得到了比较理想的结果,对抑郁倾向的识别有很大的帮助.这是因为加入注意力机制后,在不改变输入特征大小的情况下,得到更精准的与抑郁倾向相关的特征,使得训练的模型更易分类,从侧面反映了本算法对特征的学习能力和表示能力.
本文绘制了加入注意力机制后,使用训练好的模型对样本进行分类,得到的混淆矩阵如图6所示.其中,真实样本标签为抑郁倾向的样本被分类成健康样本所占的比例是13%,被正确分类为抑郁倾向的比例是87%;真实样本标签是健康的样本被分类为抑郁倾向的比例是39%,被正确分类为健康的比例是61%.

图6 ResNet34+CBAM,ResNet50+CBAM 混淆矩阵Fig.6 Confusion matrix of ResNet34+CBAM,ResNet50+CBAM
本文样本设计是在不同的情绪刺激下进行的,借助注意力残差算法对不同任务下的不同刺激进行了考察.具体结果见表7.在正性情绪刺激下,词汇朗读任务的预测效果最好,其最高预测准确率为76%,召回率为88%;在中性情绪刺激下,访谈任务的效果最好,其最高预测准确率为84.5%,召回率为85%;负性材料中,图片描述的效果最好,其预测准确率为89%,召回率为92%.整体来看,在不同的任务及刺激条件下,语音特征对个体是否抑郁的预测效果基本在60%以上.
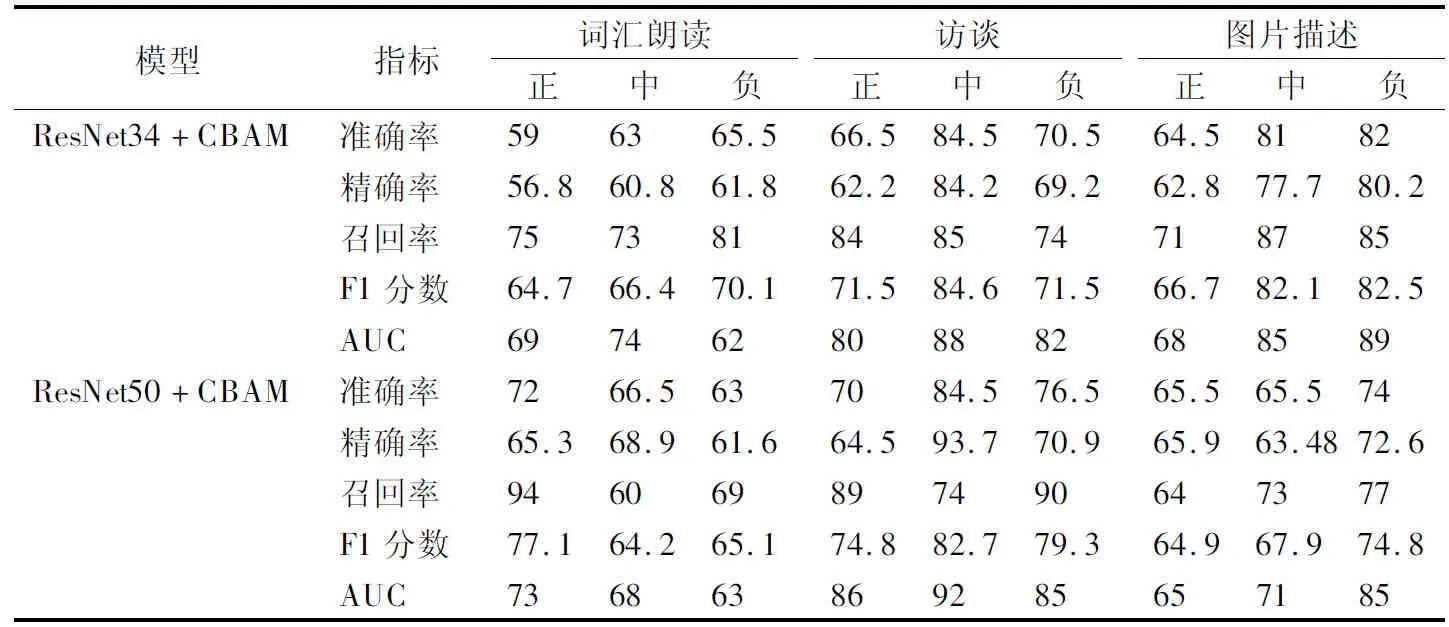
表7 各任务类型在不同情绪效价下模型分类结果(%)Table 7 Model classification results of different tasks under different emotional stimuli (%)

表8 不同性别下的模型分类结果(%)Table 8 Model classification results in different genders (%)
从情绪的角度来看,语音特征能够较好地区分在正中负3种情绪下个体是否有抑郁倾向.这表明抑郁倾向个体与正常人相比,确实存在情绪方面的异常,而这一异常体现在了个体的声音特性上.正性与负性情绪效价从任务角度出发,图片描述任务模型较理想,可能原因是图片描述任务是要求被试根据屏幕显示的图片根据自己的情绪体验进行描述,更能反映个体的情绪.访谈任务也创设了一个情绪环境,比图片描述的准确率低可能是没有更强烈的情绪刺激.词汇朗读任务的效果显然没有以上两种任务效果好,可能是由于该任务是要求被试根据屏幕显示的文字进行朗读,没有激发个体的内心体验和自我感受,该结果与文献[22]得到的结果保持一致.自发的语音(如访谈、图片描述)比自发语音(如朗读)能够获得更好的结果,且偏负性的问题对应的分类效果比其他任务更好.这可能暗示了抑郁倾向个体和健康人存在认知加工方式的不同,存在着消极的自我参照,从而使得在面对自发的负性任务时产生了不同的情绪体验,进而反映在了语音上.
在设计样本时,由于男性和女性语音在抑郁表现上的潜在差异.本文涵盖了男性与女性群体,性别考察结果如表8所示.从表中明显可以看出女性群体的准确率高于男性群体的准确率,这与文献[23]的研究结果一致,进一步验证了性别对模型的分类性能可能会有影响.
B)对比实验结果分析
在相同数据集基础上,为验证不同算法对实验结果的影响,对比分析了注意力残差模型与不同机器学习算法,实验结果如表9所示.
为了进一步说明本文算法在抑郁倾向识别任务下的高性能,与其他文献得到的实验结果进行了对比.根据表9可知,在本文设计的抑郁语料集中,提取语音的MFCC特征,输入到提出的注意力残差网络和对比的机器学习算法中,注意力残差网络的各指标均高于机器学习算法,说明具有更好的泛化能力和鲁棒性.

表9 在不同算法下的结果对比(%)Table 9 Comparison of the results under different algorithms (%)
C)模型性能预测
AUC(Area Under Curve,AUC)表示ROC( Receiver Operating Characteristic)曲线下的面积,用来评价模型和微调参数.AUC同时考虑了模型对健康被试和抑郁倾向被试的分类能力,对模型做出合理的评价.当AUC值越接近1,ROC曲线越平滑,模型分类效果越好.实验结果ROC曲线如图7所示,由图可知,AUC值均在0.80以上,说明提出的模型可信度高.
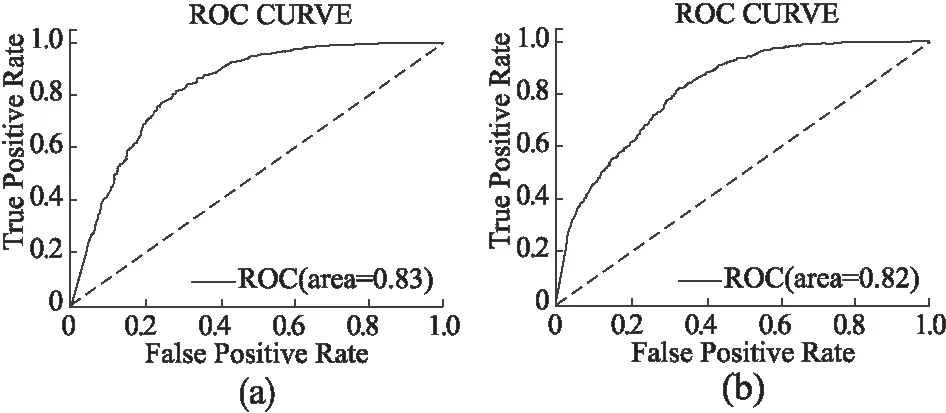
图7 ResNet34+CBAM,ResNet50+CBAM ROC曲线Fig.7 ROC curve of ResNet34+CBAM,ResNet50+CBAM
4 结束语
针对语音抑郁倾向识别问题,本文借助注意力机制的思想,设计注意力残差模型对语音抑郁倾向进行分类识别.实验中将MFCC特征输入到不同深度的注意力残差网络,以获取更多的语音特征,捕获空间位置的相关性,为克服模型在深度变深时梯度消失的问题,采用残差块提高特征提取的准确率.实验准确率达到76%,可以有效识别抑郁倾向.鉴于研究的不足,今后将对现有的语料进行数据增强处理,扩大实验语料的规模,以及进一步考察在不同任务下性别对抑郁倾向识别的影响.
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
电子制作(2019年14期)2019-08-20 05:43:38
自动化学报(2019年6期)2019-07-23 01:18:32
电子制作(2019年9期)2019-05-30 09:42:10
小说界(2018年5期)2018-11-26 12:43:42
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
