
BERT模型结合实体向量的知识图谱实体抽取方法
2022-08-24 10:24:28陈玮,张锐,尹钟
小型微型计算机系统 2022年8期
陈 玮,张 锐,尹 钟
(上海理工大学 光电信息与计算机工程学院,上海 200093)
E-mail:chenw1964@126.com
1 引 言
随着互联网和大数据技术的发展,万维网上的数据也在飞速增长,大量的知识就包含在这些数据之中,然而这些数据的质量参差不齐,这极大的阻碍了人们获取高准确性的知识.同时,互联网又是如今人们获取大规模知识的重要来源.近年来,学术界和工业界都着力于如何获取高质量的知识,并且对其分析、管理和服务.知识图谱[1](Knowledge Graph)是一种全新的展示知识之间的联系和自身内部结构的数据研究方式,具有直观、清晰、动态和高效的特点.知识图谱的关键技术在于运用图模型描述知识和对万物之间的关系进行建模[2].在构建知识图谱的过程中,需要从大量的数据中抽取知识并建立联系,这些数据可以分为结构化数据、半结构化数据和纯文本数据,其中,纯文本数据是知识的主要来源.实现从纯文本数据中获取实体信息依赖于实体抽取技术,知识图谱高适用性和准确度的保障是高精度的实体抽取技术[3].
实体抽取又叫做命名实体识别,是自然语言处理的一项子任务.实体抽取是指抽取文本中的信息元素,通常包括人名、组织、位置等.在实体抽取这项技术中,基于规则的方法是目前使用最广泛的方法.近年来,随着对机器学习算法研究的深入和创新,将机器学习相关方法应用于知识图谱实体抽取已成为现阶段的研究重点之一.
2 相关工作
在早期,知识图谱实体抽取技术的实现主要有基于规则的方法、基于词典的方法和基于在线知识库的方法,这3种方法都是在语言学专家人工构造实体抽取规则的基础上,将文本字符串进行与实体抽取规则匹配来进行实体抽取.这种方法有Grishman开发的Proteus系统[4]和Black开发的FACILE系统[5]等,虽然这种方法具有很高的准确率和召回率,但是仅仅适用于小规模的数据集,无法在规模较大的数据集上进行迁移和使用.后来出现了基于统计模型的方法,该类方法需要先将语料进行部分标注或者完全标注,再进行训练.经过标注语料之后,文本实体抽取问题就可以利用序列标注问题相关方法来进行处理,序列标注种的标签与当前输入的特征和之前的预测标签都有关系.主要采用的模型有隐马尔可夫模型(Hidden Markov Model,HMM)[6]、支持向量机模型(Support Vector Machine,SVM)[7]和条件随机场模型(Conditional Random Fields,CRF)[8].这种利用人工特征的方法取得了很好的识别效果,但它的弊端也很明显,不同领域的特征会有明显差异,导致识别方法不能够兼用.近年来,各界学者将机器学习和深度学习应用于各个领域并取得了很好的效果,命名实体识别问题也在逐渐与深度神经网络相结合.该类方法先将单词或者文本语句以一种特定的方法转化为不同维度的词向量,以词向量作为输入,再连接特定的神经网络,这种方式不再完全依赖于人工定义的特征.例如,卷积神经网络(Convolutional Neural Network,CNN)[9]、循环神经网络(Recurrent Neural Network,RNN)[10]、注意力机制(Attention Mechanism,AM)[11]和长短期记忆网络(Long Short-Term Memory,LSTM)[12].一个典型的基于深度学习的命名实体识别框架由分布式表示(Distributed Representation)、上下文解码器(Context Encoder)和标签解码器(Tag Decoder)3部分组成[13].2003年,Hammerton等[14]最早将神经网络LSTM应用到命名实体识别中.2014年,Collobert等[15]在文中采用CNN神经网络替代人工进行特征提取并结合CRF模型.2015年,Huang等[16]在文中将拼写特征与双向长短期记忆网络(Bidirectional Long Short-Term Memory,BiLSTM)、CRF模型相结合.2016年,Lample G等[17]也采用BiLSTM模型与CRF结合的神经网络模型并对多种语言进行命名实体识别.同年,Chiu等[18]在融合由两个公开的外部资源构造的词典特征基础上,利用卷积神经网络自动学习字符级特征,减少模型对特征工程的依赖,2017年,Shen等[19]在文中创新的将深度主动学习应用于命名实体识别任务的方法,该方法的最大优点就是利用少量的标注数据获得较高的学习准确度.2018年,Lin等[20]在方法中将词进行细化分解,并结合双向长短期记忆网络和条件随机场,提出了Finger-BiLSTM-CRF模型应用于命名实体识别.2019年,武惠[21]等将迁移学习与BiLSTM+CRF相结合应用于命名实体识别任务,并在人民日报数据集上取得了91.53%的准确率.
上述方法普遍注重于单个词或者单个字符的本身,没有考虑上下文的语境,也无法表征一词多义.这样抽取得到的知识实体表示仅仅是一个静态词向量,并没有结合实体所处的上下文语境.该类方法获取的知识实体用来构建知识图谱很难获取较高的准确率.谷歌团队Jacob Devlin等人[22]于2018年提出的一种BERT(Bidirectional Encoder Representation from Transformers)语言预处理模型来表征词向量.BERT的优势表现在字符级和词级的范化能力、句子级甚至是句子间的关系特征描述更加充分具体,因此,可以将BERT模型作为实体抽取的上游任务.然而在传统的BERT模型中,采用的是随机Mask方法,该方法忽略了对于实体向量的关注.
针对上面提到的问题,为了进一步提高知识图谱实体抽取的准确率,本文提出一种BERT模型结合实体向量的知识图谱实体抽取方法(下文中简称本文模型).本文模型在预处理任务中采用基于全词Mask的BERT模型生成句子向量和具有上下文语义的词向量,将词向量取平均值后得到实体向量,通过注意力机制将句子向量与实体向量结合,将结合后的新向量放入条件随机场进行序列标注,找到最优的标签以达到实体抽取的目的.实验结果表明,本文模型在实体抽取任务中取得了很好的实验性能.
3 本文模型
3.1 模型结构
本文提出的新模型结构应用于知识图谱实体抽取任务,模型结构如图1所示.本文模型主要分为3个部分:1)采用基于全词Mask的BERT模型对于输入文本进行预训练,得到句子表示embedding;2)将embedding中组成知识实体的词向量表示x1,x2取平均值得到Xp、xm,xn取平均值得到Xq,将句子表示中的CLS(序列标记[CLS]经过BERT模型后的向量表示)、Xp和Xq通过注意力机制得到新的向量Et;3)将新向量Et放入条件随机场CRF进行序列标注,找到最优的标签以达到实体抽取的目的.
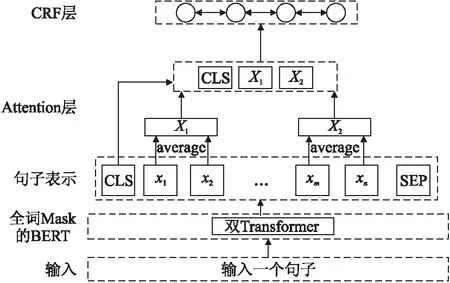
图1 本文模型结构图Fig.1 Model structure of this paper
3.2 基于全词Mask的BERT模型预训练算法
BERT是一个预训练语言表征模型,在ELMO模型和GPT模型的基础上,将二者的优势相结合,其结构如图2所示,BERT采用双向Transformer作为编码器,以此来融合左右两侧的上下文BERT模型在语言预训练方面与传统方法有所不同,没有像Word2Vec中的CBOW那样对每一个词进行预测,而是采用一种更为简洁的方法:MLM(Masked Language Model)遮蔽语言模型.Mask的作用是对计算过程中的某些值进行遮蔽,被遮蔽的值在参数更新时无法作用.在Transfer模型中存在padding Mask和sequence Mask,padding Mask的作用是方便处理标记布尔值的False的地方,sequence Mask是为了隐藏decoder需要处理的信息.本文模型中考虑了中文分词的习惯,将传统方法中的随机单词Mask换成全词Mask,如表1所示.

图2 BERT模型结构图Fig.2 Model structure of the BERT

表1 中文全词MaskTable 1 Chinese full word Mask
在BERT模型中,双向Transformer编码结构是其核心部分.Transformer完全不同于传统的RNN模型和CNN模型,Transformer对文本建模使用自注意力机制和全连接层.其编码单元结构如图3所示.

图3 Transformer编码单元结构图Fig.3 Transformer code unit structure
在Transformer编码单元结构中,核心是自注意力机制.该机制的主要功能是计算序列中每个单词与该序列中所有单词的相互关系,然后根据计算过后的相互关系来调整每个单词的权重.采用该机制得到的单词向量既包含单词本身含义又具有该词与其它词之间的关系,因此,这种方式可以学习到序列内部的长距离依赖关系.计算方法如式(1)所示.其中,Q表示查询向量;K表示键向量;V表示值向量;dk示输入向量维度.
attention(Q,K,V)=softmax(QKTdk)
(1)
自注意力的缺点是只能捕获一个维度的信息,因此,在Transformer中采用了Multi-Headed注意力机制.它先将矩阵Q、K、V进行h次不同的线性映射;然后,分别计算attention;得到的h个不同的特征表达;再将所有特征矩阵拼接起来,这样就可以获得h个维度的信息.具体如式(2)和式(3)所示:
MultiHead(K,Q,V)=Concata(h1,…hn)
(2)
h1=attention(QWQi,KWKi,VWVi)
(3)
自注意力机制的另一个缺点是不能捕获词的顺序信息,BERT引入了位置向量和段向量来区分两个句子的先后顺序.对于BERT来说,词向量、位置向量和段向量相加构成输入序列中每个词,通过深层双向编码,生成最终的句子向量.具体算法过程如算法1所示.
算法1. 基于全词Mask的BERT模型预训练算法
输入:纯文本数据
输出:embedding
第1步.读取数据集;
第2步.构建标签字典label_map,进行分字操作,匹配标签字典,构建list,在句子开头结尾添加标识符;
第3步.将字和标签全部转化为id;
第4步.构建全词mask[],空余位置用0补充完整,构建InputFeaures()并写入tf_record()中;
第5步.遍历所有训练样本并重复2、3、4步/for i in enumerate(tokens);
第6步.return embedding.
3.3 融合注意力机制的CRF算法
对于给定的文本信息,经过算法1,会得到句子向量表示embedding.本文模型是应用于知识图谱实体抽取.为了提高模型对知识实体的抽取效率,通过注意力机制将句子中词向量和CLS向量相结合.如图1所示,将x1和x2取平均后得到Xj,如式(4)所示,其中,a、b表示词向量的下标.
Xj=11+b-a∑baxi
(4)
通过式(5)将CLS和Xj连接在一起组成矩阵.
Et=[CLS,Xj]
(5)
然后,通过注意力机制给隐藏状态加权表征,得到新的状态序列.计算过程如式(6)、式(7)和式(8)所示:
et=Vttanh(WtEt+bt)
(6)
at=exp(et)∑nc=1ec
(7)
st=∑kt=1atEt
(8)
其中,et表示隐藏状态向量Et在t时刻的能量值,Vt和Wt表示t时刻的权重系数,bt表示t时刻对应的偏移量.
由于知识实体间的依赖性很强,例如,I-PER后面不可能于B-ORG相邻,可以将新隐藏状态序列s传入CRF层进行解码,得到最终预测标签序列.
对于任一个序列X=(x1,x2,…,xn),在此假定p是实体注意力层的输出得序列,p的大小为n×k,其中,n表示词的个数,k为标签个数,pi,j表示第i个词的第j个标签的分数.对预测序列Y=(y1,y2,…,yn)而言得到它的分数函数如式(9)所示:
s(X,Y)=∑ni=1(Ayi,yi+1+Pi,yi)
(9)
其中,A表示转移分数矩阵,Ai,j代表标签i转移为标签j的分数,A的大小为k+2,预测序列Y产生的概率为:
p(Y|X)=es(X,Y)∑Y~=YXs(X,Y~)
(10)
ln(p(Y|X))=S(X,Y)-ln(∑Y~=YXs(X,Y~)
(11)
式(10)和式(11)中,Y~表示真实得标注序列,YX表示所有可能的标注序列,进行解码后得到最大分数的输出序列标签Y*如式(12)所示.
Y*=argmaxs(X,Y~)
(12)
4 实验结果与分析
4.1 数据集与评价指标
BERT模型的训练依赖于海量的数据和非常强大的计算能力,因此,谷歌开源了不同版本的BERT模型,处理中文数据可以采用BERT-base版本,处理英文数据集可以采用BERT-base Uncased版本,此版本不需要转换英文首字母大小写.
本文实验采用的是人民日报语料库作为实验的数据集,它包含了3种实体类型,分别是人名、地名和组织名.监督训练的方式主要标注模型包括BIO、BIOE、BIOES等.本文选用的是BIO模型,该模型的标签一共有7个,其中,B代表命名实体首字,I代表实体中间,O代表非实体.相应的有B-PER、I-PER分别表示人名首字、人名非首字;B-LOC、I-LOC表示地点名首字、地点名非首字;B-ORG、I-ORG 指组织名首字、组织名非首字;O代表非命名实体.标注示例如表2所示.

表2 部分实体标注示例Table 2 Examples of partial entity annotations
本文实验使用准确率P(Precision)、召回率R(Recall)以及F1值对模型的性能进行评价.3个评价指标的计算公式如式(13)、式(14)和式(15)所示.
P=正确识别的实体个数所有识别的实体个数×100%
(13)
R=正确识别的实体个数所有标记的实体×100%
(14)
F1=2×P×RP+R×100%
(15)
4.2 实验环境准备
本文实验所需要配置的软硬件如表3所示.

表3 实验软硬件配置表Table 3 Experimental hardware and software configuration table
4.3 实验参数配置
在训练过程中,本实验采用了Adam优化器,设置学习率为0.001,同时,还设置LSTM_dim为200,batch_size为64,max_seq_len为128.为防止过拟合问题,在BiLSTM的输入输出中使用Dropout,取值为0.1.具体各种参数设定如表4所示.
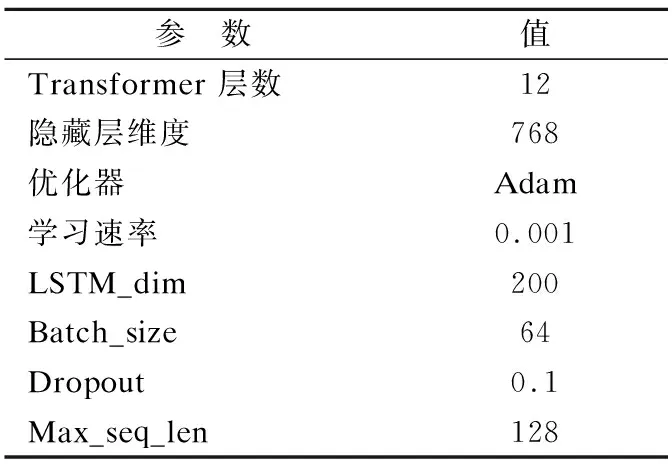
表4 实验参数设置Table 4 Experimental parameter setting
4.4 实验结果分析
通过BERT模型训练生成的不同维度向量对实验结果也存在一定的影响,本实验将LSTM_dim值分别设置100、200和300进行对比,对于3次不同实验的结果对比如图4所示,可以看出,实体抽取的准确率、召回率和F1值在向量维度设置为200时取得最优.当维度较低时,向量特征不够完整,会出现欠拟合现象,当维度过高时,实验中产生的噪声会被捕获,产生过拟合现象.

图4 不同维数下实验结果对比Fig.4 Comparison of experimental results in different dimensions
为了对本文模型的评价更加合理客观,实验选用人民日报语料库,采用BILSTM模型、LSTM+CRF模型、BILSTM+CRF和经典的BERT+BiLSTM+CRF模型作为对比,实验结果如表5所示.
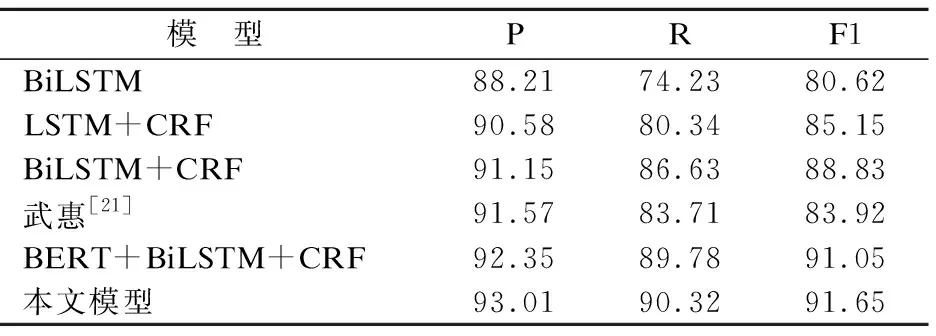
表5 不同模型实验结果(单位:%)Table 5 Experimental results of different models (unit:%)
由表5可以看出本文模型具有很好的效果,F1值高达91.65%.本文模型与传统的深度学习网络BiLSTM+CRF模型相比,F1值提高了3.17%,与经典的BERT+BiLSTM+CRF模型相比,F1值也提高了0.65%.武惠等人[21]将迁移模型结合BiLSTM+CRF虽然取得了91.59%的准确率,但是没有使用BERT模型,F1值只有83.92%.本文模型利用BERT模型训练出来的词向量和句子向量不仅具有良好的泛化能力,在表征不同语境中的句法和语义信息也有很好的效果,同时利用注意机制将句子向量与实体向量结合,着重于对知识文本中实体的关注,提高了知识图谱实体识别的性能.
此外,本实验还对比分析了表5中BiLSTM、LSTM+CRF、BiLSTM+CRF、BERT+BiSTM+CRF和本文模型的前15轮epoch的F1值更新情况,如图5所示.本文模型和BERT+BiSTM+CRF在训练初期的F1值就能达到0.75以上,并会持续上升,在epoch等于5时会达到最大值,最后会一直保持在最大值左右.其它3个神经网络模型在训练初期就处于一个非常低的水平,随着epoch值的增大而增加,在最高值时也没有达到本文模型的F1值.
为了验证本文模型的合理性,本实验将句子向量与词向量取平均后得到的实体向量的连接方式改为无注意力机制,即直接连接方式.实验结果如表6所示.

图5 不同epoch下的F1值Fig.5 F1 values under different epochs
由表6可以看出,采用注意力机制连接句子向量和实体向量取得了比较好的效果.原因在于采用无注意力连接方式增加了多余的参数来处理连接后的新向量,采用注意力机制会赋予句子向量和实体向量不同的权值,经过注意力机制处理的新向量放入条件随机场会有更好的识别效果.

表6 句子向量和实体向量连接方式对比(单位:%)Table 6 Sentence vector and entity vector connection method comparison (unit:%)
为了进一步验证本文提出模型的有效性,本文还选用了CoNLL-2003语料库进行实验,将其与其它几个主流命名实体识别模型(文献[15,16,18-20])进行比较,其结果如表7所示.

表7 本文模型与主流模型实验结果对比(单位:%)Table 7 Comparison of experimental results between the model in this paper and the mainstream models (unit :%)
表7中,总结了本文模型和其它文献方法在CoNLL-2003语料库的比较结果.Collobert等人[15]在将CNN神经网络替代人工进行特征提取并结合CRF模型,取得了F1值为88.05%的结果;Lample G等人[17]将BiLSTM-CRF模型直接与字符级的词向量结合,F1值达到了90.08%;Chiu等人[18]将BiLSTM与CNN模型结合,取得了91.94%的准确率.Lin等人[20]采用了细粒度词表示取得了91.09%的F1值.本文模型采用基于全词Mask的BERT模型生成句子向量和具有上下文语义的词向量,采用注意力机制结合句子向量和实体向量,再将结合后的新向量放入条件随机场,获得91.66%的F1值,优于其它几种模型的结果.从表7中可以看出本文模型的三种指标也优于其它文献中的方法.实验结果表明,本文模型具有更好的实体抽取能力.
5 结 语
目前,在众多知识图谱实体抽取技术方法中,普遍存在过度依赖领域专家和人工特征的现象.为了减少这种问题,本文通过基于全词Mask的BERT模型获得句子向量和赋有语境化的词向量,再通过注意力机制和条件随机场,构建的新模型应用于知识图谱实体抽取任务.在人民日报语料库的评测中,相比其他模型,本文模型取得了最佳的结果.同时在CoNLL-2003语料库中,本文模型也有不错的表现.对于本文模型来说,在上游文本预处理任务中使用BERT模型,训练得到包含上下文语义的词向量和句子向量,充分学习文本的特征信息,采用注意力机制将句子向量和实体向量结合,再放入条件随机场,提升了知识图谱实体抽取的效果.实验表明,本文模型对于提高知识图谱准确率具有一定的参考价值.
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
少先队活动(2020年12期)2021-01-14 01:47:40
中国外汇(2019年18期)2019-11-25 01:41:54
哲学评论(2017年1期)2017-07-31 18:04:00
传媒评论(2017年3期)2017-06-13 09:18:10
中成药(2017年3期)2017-05-17 06:09:01
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
领导科学论坛(2016年9期)2016-06-05 14:59:58
