
车载遥感高速公路广告影像的文本信息次过滤算法剔除了提取研究与应用
2022-08-18 08:53朱建伟李朝奎黄云涛王佳欣钟森
遥感信息 2022年2期
朱建伟,李朝奎,黄云涛,王佳欣,钟森
(1.湖南科技大学 地理空间信息技术国家地方联合工程实验室,湖南 湘潭 411201;2.湖南科技大学 测绘遥感信息工程湖南省重点实验室,湖南 湘潭 411201;3.北京航天自动控制研究所,北京 100085)
0 引言
截至2021年四月,我国高速公路总里程已达160 000 km,高速公路广告牌沿线设立,普通路段设立间隔约1 km,高速收费站、线路密集区域以及城市周围则更为密集。单块广告牌造价(以常见双面广告牌为例)为8万至12万元,租赁费用则因地段因素差异较大。全国各省高速沿线广告管理政策逐步完善,例如2014年湖南省人民政府办公厅印发了《湖南省高速公路沿线广告专项整治工作方案》。现阶段高速公路的广告牌管理主要采用沿线驱车,对高速沿线广告牌逐一下车检查的方式。现行方式不仅信息反馈迟缓、成本高昂,且作业人员存在安全隐患,因此,建立一个实现自动巡检和信息管理的高速公路广告牌智能管理系统已经成为当下迫切的需求。目前,在无人驾驶技术研究热潮的推动下,车载平台与遥感技术应用的结合被更加广泛地铺开。可以采用车载遥感技术采集高速公路广告牌影像数据,并基于计算机技术解译车载遥感获取的影像数据中包含的文本信息和图像信息,如空置的广告牌、破损的广告牌和非法占用的广告牌等,实现类似人脑的问题甄别。
车载遥感影像数据隶属于自然场景图像,参照目前自然场景文本提取的方法来看,自然场景中的文字由于其相关属性随机性较大,相对文档文本来说更加难于识别和提取。目前国内外诸多学者对自然场景静态图像中的文本信息识别与提取技术进行了挖掘。Veit等[1]设计了基于神经网络的自然场景静态图像文本信息识别算法,使用从原始RGB图像计算得到的复数值边缘方向图作为特征,通过训练神经网络对文本和非文本的区域进行分类。Frost等[2]提取边缘部分相对应的主导像素的梯度矢量流(gradient vectorflow,GVF)鉴定方法,将Sobel边缘图作为候选文本区域。这些方法主要针对提取英文文本。肖珂等[3]提出一种ISODATA聚类和支持向量机结合的自然场景静态图像文本识别方法,该方法对中文字符的提取是鲁棒的;杨宏志等[4]设计了基于改进Faster R-CNN的自然场景文本检测算法,但上述方法对本文应用需求中文本提取效果均较差。参考现有的文字提取方法,依托广告牌数据特性,本文提出了一种融合高精度MSER获取与基于像素点的笔画宽度变换字符识别优化算法,为实现高速公路广告牌智能化管理提供了一种原创性的技术支持。
1 研究方法
首先,对无人机数据进行MSER(最大稳定极值区域)检测得到所有可能包含文本信息的MSER区域;然后,根据广告文本特征对MSER区域进行筛选,得到高精度MSER包围盒;接着,利用MSER包围盒进行基于像素点的SWT文字检测,得到文本检测结果;最后,以经典的图像增强方法对结果进行降噪和整饰,得到影像中的文本信息,本文算法流程如图1所示。
1.1 高精度的MSER图像分割与筛选
1)MSER区域检测。以车载遥感影像数据来建立候选文本区域的问题在于,如何在类文本区域冗杂和广告牌文本信息形式多样的条件下检测出有效的文本区域。结合车载遥感广告牌数据与当下主流区域检测器各自的特点,本文选择了MSER(最大稳定极值区域)方法用于无人机数据的文本区域检测。该方法具备稳定性良好、可同时检测不同精细程度的区域,并且对灰度图像仿射变化具有不变性的优势。
MSER检测首先对影像数据进行灰度转化处理,再将其各个像素量化,设立量化灰度级数为G=256,灰度取值范围为0~255。对量化后的图像二值化,生成二值图像。在预设的灰度取值范围内,生成的灰度图像阈值每发生一次改变都会生成一幅与之对应的二值图。当阈值取极小时图像为全白,当阈值取极大时图像为全黑,如图2所示。在阈值不断由极小向极大变化的过程中,会存在着一些与其周围的灰度变化相比较变化非常小的连通域,这些连通域便是初步检测到的MSER,即初步的文本候选区域。该方法提取的MSER,背景对比度较大,自身的灰度值较为稳定,并且该区域在梯度阈值变化下灰度值保持得较好。由于静态场景图像中,同等灰度变化条件下文字区域背景波动较强,而文字区域则在灰度变化时较稳定,因而应用该算法能够提取常规方法例如颜色聚类等不能提取的一些连通域。

图2 梯度阈值下的MSER
2)文本特征分析。本文结合最大稳定极值区域的提取结果和原始数据中的文本特征,制定了一些针对性较强的先验知识,以此为约束条件过滤类文本区域,可以提高MSER的获取精度。
(1)基于字符长短轴长度比的约束条件。中文字符的构成以笔画为基础,字符的构成特征鲜明,又被称为方块字。结合此特点,以字符中心为原点,穿过原点到达字符边界的横轴和纵轴比例是被约束在一定范围内的。经过大量统计,可见MSER区域中两轴比例(该比例不区分横纵轴先后顺序)大于4∶1的区域为类文本区域,不存在中文字符。除此之外,一些特殊结构的字符不能满足先前的约束条件,如“1”和“一”等。经过研究发现,“1”和“一”等结构的拟合椭圆较易获取且方向都靠近竖直或水平,当拟合椭圆长短轴大于8∶1时,候选区域不存在中文字符。
(2)基于字符孔洞数的约束条件。候选区域中的单个中文字符孔洞数目容易把控。候选区域中的单个字符的孔洞数目通常不会过多。对无人机高速公路广告牌数据进行统计发现,区域内单个字符的孔洞数目最多不超过五个。
(3)基于字符占空比的约束条件。中文字符的构成区别于英文的构成方式,由笔画“堆积”而成,所以字符本身的像素面积与其拟合椭圆面积的比例是约束在一定范围内的,即占空比。由于字符偏旁部首的像素都散布松散,因此候选文本的拟合椭圆面积往往比候选的文本区域包围盒大。实验表明,候选文本区域中字符占空比小于0.15且大于0.8的文本包围盒不存在中文字符。
3) MSER二次过滤。高速公路广告牌数据中可识别出大量MSER,而其中还包含部分的类文本区域,如部分栏杆、广告牌边缘和铁架等区域,如图3、图4所示。为保证提取进度,滤除类文本区域是必要的一步。

图3 包含文本信息的MSER

图4 类文本区域
MSER是目前检测器中性能最优越的一种。但是其对模糊的高度敏感也使得它的应用产生了明显的弊端。本实验中高速公路广告牌影像受光线变换、图像迷糊和航拍姿态角度等因素的影响,将提取出的MSER直接纳入文字算法检测,不仅加大了计算量,而且大大降低了精度。
针对上述问题,对结果进行过滤:①滤除长短轴长度比大于8∶1的候选区域;②滤除孔洞数目大于5的候选区域;③滤除占空比小于0.2而大于0.85的候选区域。实验结果表明,通过该方法,可以过滤一定数目为包含文本信息的MSER包围盒。
1.2 SWT文字检测
笔划宽度变换(stroke width transform,SWT)字符识别算法是基于文字边缘像素的向量字符识别算法。广告牌包含的文本信息具有易辨识、边缘对比度大等特性。针对该特点,本文对原有的SWT算法进行了优化,具体步骤如下。
步骤1:初始化SWT[5]图像。
步骤2:计算原图像的Canny边缘和梯度方向。Canny能够准确地识别图像的实际边缘并且还具备响应最小的优势,故选用Canny检测算子对MSER中的字符像素区域进行边缘检测,并生成边缘图。Sobel算子计算MSER中各字符实际边缘的梯度,并在边缘精细定位的基础上生成梯度方向图。将二者结合便得到了笔画宽度变换。
边缘检测保障精度的前提是图像噪声需控制在合理范围。采用高斯滤波可以保证原图像的边缘走向不变,且能较好地保留特征点及边缘特性。字符笔画的两边是否具有相反方向的Canny边缘检测点很大程度上决定了实验结果的精度。字符边界灰度值的变化是包含大小和方向的向量,用梯度表示。使用点与Sobel算子相乘等方式得到不同的梯度向量。
步骤3:滤除非边缘点。字符边缘在通过高斯滤波后部分边缘的像素点存在被放大的问题,需要通过某种约束来滤除高斯滤波后才出现的非边缘点,使边缘尽可能平滑。某个像素点的位置处于图像的实际边缘上,则该边缘像素点的梯度向量值应该是最大的,否则滤除该非最大值。具体方法为通过设置上下阈值提高边缘检测精度,只用单阈值检测边缘的精度并不是很理想。这里采用启发式的方法便可以得到一个上阈值和一个下阈值,而处于下阈值之下的一定为非边缘像素。首先选用两个指标阈值,设置为上阈值(maxT)和下阈值(minT)。检测过程中大于maxT的即判定为边缘像素,低于minT的被判定为非边缘,而位于上阈值和下阈值中间的部分看其是否与已确定的边缘像素为邻接关系,若与边缘像素为邻接关系的判断为边缘。
步骤4:边缘检测完成并生成边缘的梯度方向图后,沿边缘寻找方向相反的一对梯度点,并且以两梯度点间的像素数量作为其宽度大小为这对方向相反的梯度点赋值。求出所有一一对应的边缘点,并将其相连后输出,得到一幅由笔画宽度组成的与原字符方向和大小一致的输出图,如图5所示。

图5 笔画宽度计算
步骤5:二次过滤,得到SWT Map。
1.3 图像增强
得到SWT Map以后,结果中字符的边界存在模糊、裂隙、尖刺和小桥等问题。利用图像增强的方法进行降噪处理,即进行开运算和闭运算处理,二者均可在保持原图像面积不变或细微改动的基础上处理SWT MAP中的边界噪声。
2 实验及分析
本文以湖南省湘潭市长潭西高速公路勘测项目为依托。研究区域位于湖南省长株潭城市群长潭西高速路段,长度约24 km,沿线两侧广告牌总计58个。
全部实验及数据采集均在相同条件下进行。实验平台为惠普笔记本电脑Envy15,CPU为Intel core i5处理器。实验开发工具为MATLAB2016a。车载相机型DSC-RX1RM2,像素为4 020万,焦距为35 mm。
根据实际情况和实验数据特点等条件,随机抽取部分数据并对提取的实际结果进行前后对比。影像中由人工目视数得的字符数量为实际字符数,记为T,由本文算法识别并提取出的字符数量为算法提取数,记为E,如表1所示。

表1 算法提取结果对比
目前该领域内普遍采用国际会议ICDAR所提出对于场景文本提取算法优劣的评价模型。该模型包含召回率(r)和准确率(ρ)两个评价因子。其中,召回率针对的是车载遥感影像数据中原有的文本连通域,准确率则表示预测的提取结果中符合要求的正样本有多少,表达如式(1)、式(2)所示。
(1)
(2)
式中:C表示E和T的交集。为了更加直观地评估该算法,通过式(3)所示的方法计算其综合性能。
(3)
式中:f表示综合性能,上限为1,越逼近极限则表示算法性能越好;α为准确率和召回率的权重因子。本文算法结果与其他方法的性能比较如表2所示。
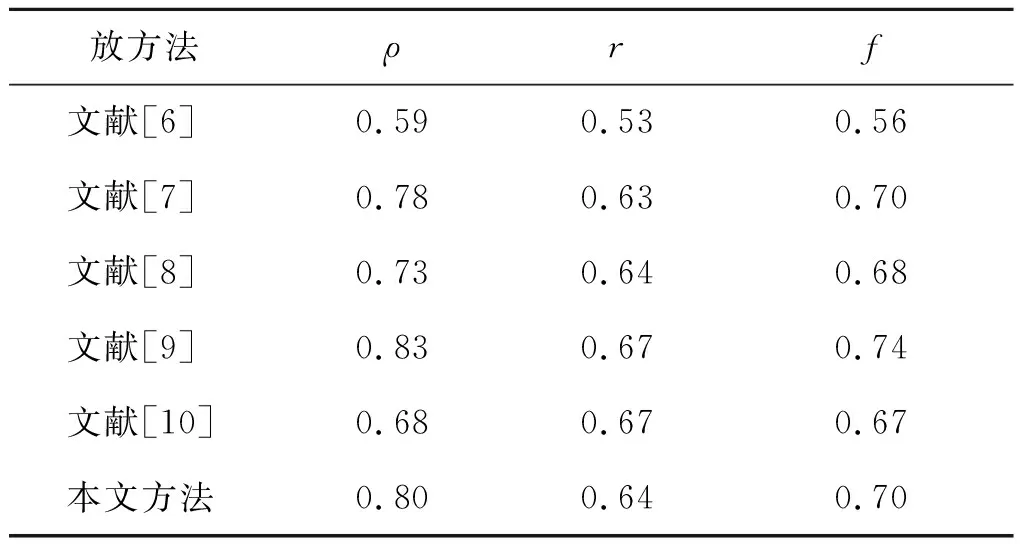
表2 六种自然场景文本提取方法性能比较
实验结果表明,本文基于车载遥感数据的文本识别方法是鲁棒的,该方法对广告牌问题甄别提供了有力支持。其中,文本信息提取结果为0的广告牌为空置广告牌;文本信息提取结果中字符数量未达要求的广告牌为破损、污损、褶皱广告牌;文本提取内容存在非原广告牌字迹的为非法广告牌等。选取部分较为具有代表性的实验结果如图6所示。

图6 算法实验结果展示
3 结束语
本文设计的MSER检测与二次过滤算法剔除了大量类文本信息的干扰,减少了计算量,且对于车载遥感广告牌数据中包含多样性的文本区域识别表现是鲁棒和高效的。本文落足当下高速公路广告牌巡检中的应用需求,以车载遥感广告牌影像数据为研究对象,将现有自然场景文本算法针对车载遥感数据的特点进行了改进和优化,实现了车载遥感广告牌数据中文本信息的高精度提取,为智能广告牌巡检中的自动化问题甄别提供了新的技术支持。
首次提出了一种车载遥感高速公路广告牌影像文本信息提取算法,并成功应用于高速公路广告牌巡检中,解决了现有方法效率低、危险性较高等难题。该技术支持了实现建立完善的智能化高速公路广告牌巡检管理系统,同时一定程度上解决了当下自然场景文本信息识别与提取方法只对英文文本信息的提取较为成熟的问题,克服了既有方法对该应用需求中文本提取效果欠佳的问题。研究结论如下。
1)以长潭西高速路段为实验载体,验证了车载遥感高速公路广告牌巡检的应用前景。
2)提出的广告牌文本信息提取方法的精度足以满足搭建计算机高速公路广告牌智能巡检管理系统的需求。
本文局限性在于该方法对极少数包含艺术字、手写体等较复杂情况下的广告牌文本识别效果欠佳,后续将作为研究重点。广告牌中的图像信息的检测与提取也是进一步研究的重点,是开发广告牌智能巡检管理系统的重要组成部分。
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
科学大众(2020年17期)2020-10-27
汉字汉语研究(2020年2期)2020-08-13
铁道通信信号(2020年8期)2020-02-06
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
作文周刊·小学一年级版(2019年20期)2019-06-27
汽车维修与保养(2019年3期)2019-06-19
新世纪智能(英语备考)(2019年3期)2019-06-12
