
基于YOLO v5的烟火检测方法
2022-08-16 10:29温秀兰崔伟祥李子康
南京工程学院学报(自然科学版) 2022年2期
姚 波,温秀兰,崔伟祥,李子康
(南京工程学院自动化学院, 江苏 南京 211167)
火灾是威胁公共安全、危害人民生命财产的多发性灾害,能否快速、有效地发现火情并及时预警对维护日常的生活、生产秩序具有重大的意义[1].在烟火的实际检测中,由于着火点目标小、火点颜色与车灯、路灯等颜色背景相近、易受外部光线变化的影响,极易造成误检.目前对于烟火检测大多采用传感器检测方法,这种检测方法存在设备昂贵、检测范围相对较窄、延时和误报等问题[2].为了解决传感器检测存在的弊端,出现了基于传统图像处理的方法,主要是对烟火中易于辨识的颜色和边缘特征进行识别和检测,虽然在一定程度上解决了不同光线下的干扰问题,但对于一些复杂环境背景中产生的烟火检测依然会受到较大的干扰,鲁棒性不强,不能满足对火灾的实时检测要求[3].
近年来,随着深度学习的兴起,深度网络模型在视觉领域取得了突出进展,将深度网络模型应用于烟火检测成为研究热点,有学者先后提出了Faster Region Convolution Neural Network (Faster-RCNN)、Single Shot MultiBox Detector (SSD)、You Only Look Once(YOLO)等性能良好的网络模型,并成功应用于各种目标检测[4];文献[5]提出了一种改进的YOLO v5结构,将骨干网络中的残差模块替换成LSandGlass模块来减少信息损失,通过删除小尺度的检测层来提高计算速度,对图像中的遮挡目标和小目标取得了较优的检测效果;文献[6]采用通道注意力机制对YOLO v5的骨干网络进行改进,在SPP模块中引入SoftPool池化操作,改进后结构对红树林单目目标取得了较高的定位与识别能力,但在实时性方面还有待进一步提高;文献[7]提出了一种轻量型YOLO v5模型用于口罩佩戴检测,利用更为经济的GhostBottleneckCSP和ShuffleConv模块替换原网络中的C3及部分Conv模块,在减轻特征通道融合过程计算量的同时增强了特征的表达能力,整体95%的准确率以及大幅度减少的参数量有利于在资源有限的移动端进行部署;文献[8]利用YOLO v5s模型对密集分布的海上舰船目标进行实时检测,将损失函数设计为CIOU_loss,目标框的筛选采用DIOU_NMS, 增强了被遮挡、重叠的目标检测效果,但是目标的漏检数量较多,有待进一步的提高.
综合现有研究成果,发现深度学习网络模型在目标检测方面有独到之处,但是针对烟火检测目标小、特征难以提取且特征易与环境背景混淆等问题的研究还不多见.本文提出了一种基于YOLO v5的神经网络模型,对动态的视频烟火序列进行识别和检测,并与原始的YOLO v5模型进行比较,以验证提出方法在准确率和检测效率等方面的有效性.
1 YOLO v5目标检测算法
YOLO v5是在YOLO v4的基础上改进而来,在继承YOLO v4算法优势的同时,对骨干网络等部分进行了优化,从准确性以及检测速度上来看,是目前最优秀的单阶段检测网络之一[9].YOLO v5模型根据网络的深度和宽度不同,具体可以分为YOLO v5s, YOLO v5m,YOLO v5l,YOLO v5x四个不同的版本.其中YOLO v5s网络最小、速度最快、平均准确率(average precision,AP)精度最低,其它三种网络在此基础上,不断加深、加宽网络,提升AP精度,但速度的消耗也在不断增加.YOLO v5在网络结构上可以分为为输入端模块、骨干网络模块、多尺度特征融合模块和预测端模块.YOLO v5的输入端主要是对输入数据进行Mosaic数据增强,选择是否采用锚框自动计算的机制[10].Mosaic数据增强是在CuxMix数据增强的方式上演变而来,主要是将4张图片分别采用随机缩放、裁剪和排布的方式进行拼接.
Mosaic数据增强对输入数据进行随机缩放,无形间增加了许多小目标,使得网络对小目标的检测更精准.采用Mosaic数据增强时,可以直接计算4张图片的数据,使得Min-batch并不需要很大,1个GPU就可以达到很好的效果[11].在经典的YOLO算法中,锚框的尺寸大小都是开始时设定,后续网络在初始锚框基础上输出不同尺度的预测框,这些预测框和真实的标注框进行对比,计算两者的偏移量,再反向更新预测框的各个参数[12].为了更好地检测小目标物体,在原始模型的三个检测层上增加第四个检测层,需要多增加一层锚框参数.原始模型的锚框参数为:[10,13,16,30,33,23],[30,61,62,45,59,119],[116,90,156,198,373,326];增加后的锚框参数为:[5,6,8,14,15,11],[10,13,16,30,33,23],[30,61,62,45,59,119],[116,90,156,198,373,326].自适应缩放是采用缩减黑边的方式,将图片统一缩放到一个标准尺寸,再送入到检测网络.
2 YOLO v5算法改进
2.1 网络结构的改进
针对烟火检测中着火点目标小、缺乏充足的外观信息,难以将它们和背景或相似的目标区分、在真实的场景下存在光照剧烈变化、目标遮挡和目标尺度变化等问题,对YOLO v5的网络结构进行改进.原始的YOLO v5网络输出三个检测层,输出的尺度分别为20×20、40×40、80×80.考虑到着火点目标较小,原始的80×80输出特征图不能很好地显示着火点特征,因此,改进后的网络增加了第四个检测层,继续对第三层输出的80×80特征图进行上采样等处理,使得特征图继续扩大,同时将获得的160×160特征图与骨干网络中的第三层特征图进行Concat融合,以此获取更大的特征图进行小目标检测,提高对小目标的检测精度.
2.2 损失函数的改进
在模型训练时,通过损失函数来评价模型预测值与真实值之间的不一致程度.损失函数通常用来衡量模型的好坏,最常见的损失函数为IOU_loss,计算式为:
(1)
式中:A为目标框与预测框之间的交集;B为两个框之间的并集.
YOLO v5中采用GIOU_loss作为预测框的损失函数,计算式为:
(2)
式中:C为最小外接矩形;D为最小外接矩形与并集之差.
GIOU_loss虽然解决了两个框大小相同时,IOU_loss无法区分两者相交的情况以及预测框与目标框不相交时的情况,但GIOU_loss还是存在一些弊端,当预测框在目标框内部且预测框大小一致时,预测框和目标框的差集都是相同的,因此这种状态的GIOU值也都是相同的,这时GIOU退化成了IOU,无法区分相对位置关系[13].
DIOU_loss考虑重叠面积和中心点距离,当目标框包裹预测框时,直接度量2个框的距离,在模型训练时DIOU_loss的收敛更快.因此,将原网络中用于计算目标框回归损失函数的GIOU_loss替换成DIOU_loss作为预测框的损失函数,计算式为:
(3)
式中:R1为最小外接矩形对角线之间的距离;R2为目标框与预测框两个中心点的欧式距离.
3 试验及结果分析
3.1 数据集的获取与增强
目前没有统一和公开的烟火数据集,从百度、Google、GitHub等平台人工收集了13 000张图像,其中训练集占80%、验证集占10%、测试集占10%,利用LabelImg软件对采集到的数据进行标注.
目前的烟火检测主要针对室内场景和人员密集的公共场所,而这些场景的数据极难获取,这就导致训练模型不能很好地检测这些场景中的目标,泛化能力差、误检率高.如图1所示,在自然场景下,图1(a)将地面上颜色、形状类似火苗的垃圾误检为火焰;图1(b)将营业厅中工作人员的红色袖套误检为火焰.误检主要原因是场景样本少,实际中又很少有对应的场景数据.

(a) 菜场场景

(b) 商店场景
针对场景样本少的问题,借鉴GAN网络中的生成模型思想[14],构造一些丰富场景数据.本文采用复制增强的方法扩充场景数据,通过粘贴不同规模的不同对象到新的背景图像来进行数据增强.这种复制粘贴操作有足够的潜力去免费获取丰富、新颖的训练数据,这种数据增强方式与YOLO v5的Cut-mix方法不同,其复制粘贴的对象是从一张图像中抠掩膜部分对应的实例,然后随机粘贴到另一张图像中,所粘贴的对象精确到像素级,粘贴的位置要考虑上下文的关系,不能使粘贴后的图像显得突兀,如图2所示,通过复制粘贴操作形成人造的含有目标的样本.

图2 数据增强操作
将数据增强后的图片送入模型,经过训练后,检测对比图3可见,该方法有效,原图1(a)中地面上垃圾和原图1(b)营业厅中工作人员的红色袖套被误检的情况都得到了改善,大大降低了误检率.这主要得益于之前被误检的地方会被当作负样本进行训练,而复制粘贴进去的火焰数据具有明显的特征,利于网络对特征的提取和分析,提高了模型的泛化能力.
(a) 菜场场景增强前

(b) 菜场场景增强后
(c) 商店场景增强前

(d) 商店场景增强后
3.2 评价指标
在目标检测领域常用准确率P和召回率R来评价算法的优劣,其中准确率P是用来评估一个模型预测的准不准,召回率R是用来评估一个模型检测的目标全不全[15],其计算公式分别为:
(4)
式中:NTP为模型正确检测目标的个数;NFP为模型错误检测目标的个数;NFN为模型没有检测出目标的个数.
运用改进后的网络结构对数据集进行训练,计算其准确率和召回率,计算结果如图4、图5所示.由图4、图5可见,在置信度(confidence)为0.6的情况下,火的检测准确率P达到91.4%,召回率R达到88.6%;烟的检测准确率P达到89.1%,召回率R达到79.4%.
为了更好地评价模型的准确性,通常在评价算法性能优劣时引入平均准确率指标mAP,其中mAP@0.5是指IOU设为0.5时所有类别的平均AP[16],最终的计算结果如图6所示.根据图6曲线下方的面积大小来计算mAP,其中火的mAP达到了94%,烟的mAP达到87.6%.

图4 准确率P曲线图

图5 召回率R曲线图

图6 P-R曲线图
3.3 对比试验
在网络模型训练过程中,可以通过loss曲线观察网络训练的状态,为了验证将用于计算预测框回归损失函数的GIOU_loss替换成DIOU_loss是否可以提高网络的收敛速度,在同一个数据集上分别对改进前后损失函数的网络进行200个epoch训练,其loss曲线图如图7所示.由图7可知,替换后的损失函数在考虑了目标框的中心点后,可以更快地将目标回归出来,模型的收敛速度也快于原网络,说明将GIOU_loss替换DIOU_loss损失函数后提高了网络的收敛速度,并且与经典的YOLO v4算法相比,loss的值更低,在0.01左右,由此可见,改进后的网络模型训练结果更佳,可以作为一个合适的网络模型进行测试.

图7 改进前后loss曲线图
分别从P、R、mAP等指标对改进前后网络整体的性能进行评价[17],为了方便对比,将改进后的模型称为i-YOLO v5,采用上述指标评价结果如表1所示,表1中的P、R、mAP是烟和火两个类别的均值.由表1可见,相比于原网络模型,改进后的网络模型在烟火检测的各项指标都有了明显的提升,其mAP从83.5%上升到90.8%,提升了7.3%,与YOLO v4相比,mAP提升了14.6%,检测速度从原先的60.32 fps提升到现在的69.94 fps.由此可见,改进后网络模型在准确率和检测速度都有很大提升.
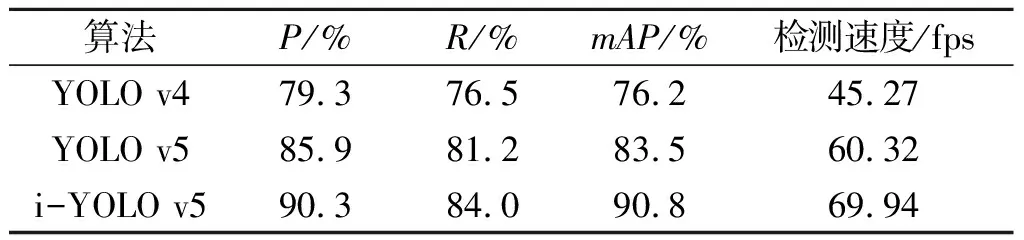
表1 改进前后网络性能测试结果
3.4 检测结果分析
改进前后网络的实际检测结果如图8所示.对比图8(a)和图8(b)可见,原YOLO v5对于存在遮挡的目标图像检测效果不佳,存在漏检的现象,而改进后的YOLO v5在目标被部分遮挡的情况下依然可以精准检测目标,说明改进后的YOLO v5在替换损失函数后,依旧保持对图像特征提取的能力;对比图8(c)和图8(d),原YOLO v5对于小目标的检测效果较差,不能检测出50×50像素点以下的小目标,而改进后的YOLO v5能很好地检测出小尺寸着火点,说明YOLO v5增加检测层后,网络对图像特征信息的提取能力进一步加强,使得漏检的问题得到了有效的改善;对比图8(e)和图8(f),原YOLO v5在特征信息相似的物体上存在误检的情况,而采用复制粘贴的数据增强方式后,有效避免了这种误检情况,有利于网络对特征的提取和分析、降低了误检率、提高了模型的泛化能力.

(a) 模型改进前

(e) 模型改进前

(f) 数据增强后
4 结语
针对目前烟火检测效率低下、误检率高的问题,本文在YOLO v5的基础上,提出一种改进的YOLO v5烟火检测方法.首先在YOLO v5原始的三个检测层上增加第四个检测层,加强对小尺寸目标的检测;然后将原网络中用于计算目标框回归损失函数的GIOU_loss替换成DIOU_loss,使得目标在被遮挡的场景中也可以将预测框快速回归,对于实际场景数据少、误检率高的情况,采用复制粘贴的数据增强方式,在丰富场景数据的同时,大大减少了误检率,得到更适用于烟火检测的YOLO v5模型.对比试验结果表明,改进后的YOLO v5的损失函数收敛更快,准确率更高,适合在实际生活中推广应用.
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
中学生数理化·中考版(2021年3期)2021-07-22
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
阅读(快乐英语中年级)(2021年2期)2021-04-01
农业科技与信息(2021年2期)2021-03-27
新世纪智能(数学备考)(2020年9期)2021-01-04
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
学生天地(2020年35期)2020-06-09
读友·少年文学(清雅版)(2019年10期)2019-05-21
