
高管团队知识隐藏结构模型与量表开发
2022-08-12 08:09:20荣鹏飞王瑞雪
科技进步与对策 2022年15期
荣鹏飞,王 嘉,王瑞雪
(上海师范大学 哲学与法政学院,上海 200234)
0 引言
由CEO、总经理及副总经理等组成的企业高管团队(TMT),是负责制定和执行企业战略决策的高层经理的相关小群体[1]。在日益激烈的市场竞争中,企业经营环境不断变化,大量风险性、不确定性因素使企业高管团队在制定、执行战略决策中经常面临突发情况,需要解决各种新问题。因此,仅依靠高管团队内部现有的知识储备难以满足决策需求,高管团队迫切需要获取新知识,通过团队成员间的知识共享和交流激发团队创造力,进行决策创新[2]。尽管已有学者对高管团队如何从外界获取所需知识[3]、促进团队内部知识共享作了相关研究[4],并建议采用搭建企业知识管理平台、规范组织内部知识共享制度等促进知识交流,但在高管团队内部仍然普遍存在隐藏、回避与保留知识的消极活动,深刻影响高管团队决策过程[5],从而引起学者们的高度重视。如Arain等[6]考察了组织内部高层管理者之间的知识隐藏现象,结果发现,高层管理者的知识隐藏行为对高层管理者之间的不信任关系产生显著正向影响;Rong等[2]的研究表明,在团队学习过程中,高管团队成员间的知识隐藏行为会阻碍知识和信息在高管团队内部的有效传递,从而降低团队学习效用。
知识隐藏是员工在面对同事的知识请求时产生的故意隐瞒或者刻意掩饰行为[7]。早期,学者们主要围绕个体知识隐藏的前因和效能展开研究,得出以下结论:一是影响个体知识隐藏的前因既有领导风格[8]、人口统计特征[9]和感知的知识所有权[10]等个体因素,又有组织氛围[11]和人际不信任[7]等组织因素,以及职场排斥[12]、消极互惠[11]等情景因素;二是尽管知识隐藏行为有助于保障隐藏者的短期绩效,但从长期看会降低个体、组织的创新力和成长能力,对其产生消极影响[13-14]。此后,学者们发现知识隐藏行为普遍存在于各种组织中[9],并由此展开了对团队知识隐藏行为的研究。团队知识隐藏研究可反映整个团队内部的知识隐藏状况,有助于揭示团队成员间相互隐藏知识且恶性循环的问题[15]。与个体知识隐藏行为相比,团队知识隐藏既涉及团队成员个体的心理、认知等因素[13],又与团队互动行为密切相关[16],更加复杂和较难把握。因此,团队知识隐藏研究尚处于起步阶段。目前,少量团队知识隐藏研究发现,团队知识隐藏行为不仅会削弱团队交互记忆系统功能[15],而且会产生降低团队创造力、导致团队成员不信任等消极后果[17-18]。
知识隐藏研究起源于西方,为了便于开展该领域研究,Connelly等[7]最早采用问卷调查法和基于事件的经验抽样法编制了包含12个题项的知识隐藏测量问卷,将知识隐藏划分为推托隐藏、装傻和合理隐藏3个维度。其中,推托隐藏是指隐藏者提供给请求者不正确的信息,或虽答应帮忙但尽量拖延,完全没有真正帮忙的意图或行为;装傻是指被请求者假装听不懂请求者问题并不愿意帮忙;合理隐藏是指隐藏者以第三方不愿意泄露为由,拒绝向请求者提供想要的知识或信息[19]。该量表通过信、效度检验,成为目前研究个体或团队一般知识隐藏问题的主要测量工具。国内学者也使用该量表研究知识隐藏现象,或是以该量表为基础进行修订。如赵婷(2013)在参考Connelly等(2012)的问卷时发现,中国情境下的知识隐藏行为并非3个维度,因此修订了该问卷,将知识隐藏划分为主动隐藏和被动隐藏两个维度[20]。此外,Peng[9]设计了知识保留问卷,包括“保留有用的信息和知识”“隐藏具有创新性的成果”“不愿意把自己的知识和经验转为团队知识”3个条目,用来测量知识隐藏行为。虽然该量表通过了信度检验,但未能厘清知识隐藏行为的内部结构,因此并未获得广泛应用。从知识隐藏包含的内容看,Connelly等[8]对知识隐藏结构维度的划分是从“如何隐藏知识”问题出发的,开发的量表也是基于西方国家强调个体价值的文化背景,极具个人主义色彩。由于缺乏本土化的测量量表,国内学者主要沿袭Connelly等(2012)对知识隐藏结构维度的划分,采用其开发的量表测量我国员工个体或一般工作团队的知识隐藏行为,这不符合中国文化倡导集体主义、团队合作的内在逻辑[9],也难以满足我国团队知识隐藏研究需要。中国文化背景下的高管团队知识隐藏行为与高管团队成员心理、认知和决策互动过程密切相关。与个体员工或一般工作团队相比,高管团队肩负着企业生死存亡的重大使命,面临巨大工作环境压力,高管团队成员间的利益纠葛与关系也更加复杂、微妙,这些使得高管团队知识隐藏行为在前因、隐藏内容和隐藏方式等方面必然与一般工作团队的知识隐藏行为不同,尤其是与西方国家一般团队的知识隐藏行为差异更大。由此可见,不加区别地采用Connelly等(2012)对知识隐藏结构维度的划分和开发的量表测量我国高管团队知识隐藏行为显然不合适。从本质属性看,知识隐藏是一种行为,有其自身的发展和变化过程,且在不同文化背景下表现出差异化行为特征[21]。因此,结合中国本土文化背景开发高管团队知识隐藏行为量表,成为研究高管团队知识隐藏行为亟待解决的重要问题。
基于上述分析,本研究主要有以下目的:①在扎根理论研究基础上,运用小规模问卷调查、半结构化访谈和参与式观察方法收集数据,通过归类、提炼主题,构建本土文化背景下团队运行过程中的高管团队知识隐藏结构模型;②根据高管团队知识隐藏结构维度开发高管团队知识隐藏测量量表,并通过探索性和验证性因子分析等进行验证,以便为中国文化背景下高管团队知识隐藏研究提供理论依据和测量工具。
1 高管团队知识隐藏结构模型开发
为了构建高管团队知识隐藏结构模型,参照郭晓薇和范伟[22]的研究,采用繁衍与整合方法发展核心构念。其中,繁衍是指利用繁殖衍生的生物学原理使各种初始概念得以自然涌现并逐渐增多;整合则是在繁衍的基础上将各种自然涌现的初始概念,按照内涵相同或相似原则进行整理、合并,以析出关键性概念。为了满足繁衍与整合方法的要求,本研究首先采取理论性抽样方法抽取研究样本,然后综合运用小规模问卷调查、半结构化访谈和参与式观察3种方式收集原始数据资料,通过两两比较进行数据资料的三角验证,以确保研究具有较高信度和效度。
1.1 理论性抽样
质性研究强调通过研究对象获取充足信息,以便获得解释性理解。因此,为了满足质性研究需要,本研究舍弃概率性抽样,采用理论性抽样方法,按照整体分析框架、概念演绎与发展要求,选择中国文化背景下的企业高管团队作为研究对象,同时,为确保样本具有充分代表性,对所选高管团队提出以下具体要求:①来自于不同地区、不同行业领域,且所在企业性质与规模具有一定差异性;②团队成立在2年以上,且团队规模大小不等;③团队成员分别具有不同专业背景,在高管团队内担任不同管理职责;④团队成员具有一年以上高管工作经历,在性别、年龄、教育背景等人口统计学特征方面呈现阶梯状分布特点。
遵循以上要求,本研究所选样本数量以达到理论性饱和为准,最终10家企业高管团队、共104名高管成为本文研究对象。其中,男性占63.46%,女性占36.54%;30岁及以下者占9.62%,31~40岁者占21.15%,41~50岁者占32.69%,51岁及以上者占36.54%;高中或中专学历者占1.92%,大专学历者占13.46%,本科学历者占46.16%,硕士学历者占26.92%,博士及以上学历者占11.54%;高管任期为1~2年者占5.77%,3~5年者占15.38%,6~8年者占30.77%,9年及以上者占48.08%;总经理(含CEO)占9.62%,副总经理占17.31%,部门总监占21.15%,部门经理占51.92%。
1.2 数据收集
1.2.1 小规模问卷调查
为了初步调查、了解高管团队知识隐藏现象,本研究根据繁衍与整合理论发展方法要求,利用期刊数据库和报刊、媒体等途径广泛搜集国内外相关文献,在对已有研究进行系统分析和整理的基础上提取与高管团队知识隐藏行为密切相关的内容,然后遵循理论内涵相似性原则和知识隐藏行为演化过程的内在逻辑进行归类与整合。如在概念内涵上参考Peng[9]的研究,区分知识保留、知识囤积、知识共享欠缺等行为与知识隐藏的差异,只将高管团队成员在面对其他高管的知识请求时产生的故意隐瞒或刻意掩饰行为界定为高管团队知识隐藏行为;在隐藏意愿上借鉴赵婷[20]的问卷,将知识隐藏看成是高管团队成员的主观行为,从而把非主观行为(如虽有隐藏意愿却无可隐藏的知识等)排除在外;在隐藏方式上将Connelly等[7]提出的推托隐藏、装傻和合理隐藏均纳入高管团队知识隐藏行为范畴等。通过整合现有知识隐藏研究,围绕高管团队知识隐藏现象、高管团队知识隐藏策略选择、高管团队知识隐藏方式和高管团队知识隐藏行为演化设计初始调查问卷,利用微信、邮寄和电子邮件等方式,面向上述10家企业高管团队的104名高管开展问卷调查。剔除错答等8份无效问卷后,共获得有效调查问卷96份。
本研究对小规模调查所获问卷进行统计,结果发现:①在团队运行过程中,高管团队普遍存在知识隐藏现象;②高管团队成员会根据团队运行情况适时隐藏知识;③在团队运行过程中,高管团队成员会以不同方式隐藏掌握的知识;④高管团队成员的知识隐藏行为并非一成不变,而是随着团队运行情况不断调整,高管团队成员也可能会适时公开隐藏的知识。
1.2.2 半结构化访谈
本研究按照由浅入深、从抽象到具体的原则拟定半结构化访谈提纲,再根据访谈提纲对访谈对象开展半结构化访谈。半结构化访谈如表1所示,其中,为引起访谈对象关注,问题1被设为开放式,以便引出问题2与问题3;问题2和问题3具有探索性,旨在挖掘团队运行过程中高管团队知识隐藏过程;问题4具有拓展性,旨在补充高管团队知识隐藏过程要素,以进一步完善其内部结构;问题5带有验证性,旨在了解高管团队知识隐藏行为过程是否具有普适性;问题6带有启发性,旨在引起访谈对象对知识隐藏现象进行深入思考。

表1 半结构化访谈提纲
开始半结构化访谈前,研究人员向访谈对象逐一解释高管团队、知识隐藏等基本概念,确保访谈对象能够准确理解访谈问题;访谈过程中,研究人员就访谈问题与访谈对象互动交流,每位访谈对象的访谈时间均控制在30~40分钟;半结构化访谈至无法获取新的建设性信息为止,共访谈2家企业的17位高管。访谈结束后,研究人员整理了通过半结构化访谈获得的质性研究资料,以便开展扎根理论研究。
1.2.3 参与式观察
为了更加深入地了解高管团队知识隐藏行为,挖掘高管团队知识隐藏现象的内在过程机理,研究人员选择了4家不同类型企业的高管团队,适时参与高管团队会议,观察、记录具有代表性的高管团队决策运行过程,仔细收集能够反映高管团队知识隐藏行为的质性研究资料,以满足数据三角验证需求。
1.3 数据资料分析
由于扎根理论研究比较适用于开展解释性和探索性研究[23],能够满足揭示高管团队知识隐藏过程机理的客观需要,因此本文采用扎根理论研究法,按照“开放式编码—主轴式编码—选择式编码”的分析过程,开发高管团队知识隐藏维度构念,构建高管团队知识隐藏结构模型。
1.3.1 开放式编码分析
开放式编码是打散收集到的资料并赋予概念,然后重新组合的操作化过程,是扎根理论研究中对原始资料的初步探索[24]。本研究对所获资料进行开放式编码分析的目的是通过密集的资料验证,发现高管团队知识隐藏现象的概念类属并加以命名,以便确定类属特征和维度。为此,研究人员遵循贴近材料的原则,在仔细阅读和比较每份原始资料的基础上,根据访谈对象陈述,采用逐句、逐行和逐段编码相结合的方法选定原生词汇,以反映高管团队成员对知识隐藏现象的看法及反应,使各种初始概念能够自然涌现。为了获得丰富的概念与范畴,研究人员在阅读材料的过程中首先摘选出关键且具有代表性的词条、句子与片段,将其命名并形成初始概念,然后对逻辑和语义上有交叉或重合的初始概念进行提炼、聚类,形成最终确定的初始概念。通过开放式编码分析,研究人员从10家企业高管团队的104名高管取样数据中共抽取69个初始概念。开放式编码示例见表2。

表2 开放式编码示例
1.3.2 主轴式编码分析
主轴式编码是从概念层面分析不同范畴间的内在联系,根据逻辑关系重新归类,从中识别出主范畴并进一步提取核心范畴的过程[25]。进行主轴式编码分析的主要目的是发现和建立高管团队知识隐藏概念类属的内在联系,揭示研究资料各组成部分间的有机关联。为此,研究人员逐一将由开放式编码获得的初始概念与原始资料进行比较、分析,将逻辑关联的初始概念划归其所属子范畴,并对各子范畴进行比较,从内在含义和逻辑关系上判断各子范畴间是否存在潜在联结,以确保每个子范畴的内涵具有排他性。在此基础上,研究人员进一步发展主范畴,确定子范畴与主范畴间的从属关系,从而建立各范畴间的内在逻辑、从属结构。通过整理开放式编码获取的69个初始概念,从中提取与高管团队知识隐藏行为有关的核心概念,共获得12个子范畴,然后根据其内涵发展变化,将子范畴归纳为3个主范畴,见表3。

表3 主轴式编码
1.3.3 选择式编码分析
选择式编码是系统分析已经发现的概念类属后选择核心类属,通过将核心类属与其它类属相联系,揭示其内在逻辑关系,形成能够与其它类属相连接且有分析力的完整解释框架[26]。参考陈向明[27]的建议,按照选择式编码分析的操作步骤及核心范畴需满足的特征提取核心范畴。经过多重比较和分析,最终提取出“高管团队知识隐藏”这一核心范畴,其内涵进一步解读为“高管团队成员在面对其他高管知识请求时,通过行为预估和策略选择作出的故意隐瞒知识或对掌握的知识进行刻意掩饰的行为及其演化过程”。高管团队知识隐藏行为包括高管知识隐藏行为预估、高管知识隐藏策略选择和高管知识隐藏行为演化3个方面。其中,高管知识隐藏行为预估是指高管团队成员在面对其他高管知识请求时,对隐藏个人知识可能产生的效果进行事先判断与评估;高管知识隐藏策略选择是高管团队成员通过知识隐藏行为预估,对是否隐藏个人掌握的知识及如何隐藏等采取的具体策略选择;高管知识隐藏行为演化是高管团队成员根据环境变化,对知识隐藏策略进行判断,进而调整知识隐藏行为的策略选择。研究人员对前期发现的概念类属展开深入、系统地分析,并将通过主轴式编码提取的概念范畴与高管成员对知识隐藏过程的理解反复比较,在此基础上构建高管团队知识隐藏模型,具体如图1所示。
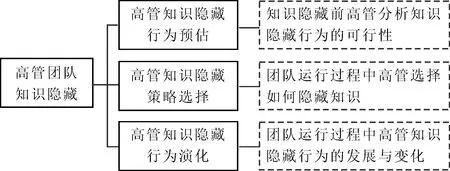
图1 高管团队知识隐藏模型
1.3.4 理论饱和度检验
理论饱和度是指不能够通过获取额外数据发展出不同于现有的范畴特征[28]。研究人员在进行选择式编码分析后,随机抽取访谈对象的访谈条目,未能从中提取出新的研究范畴,因此终止采样过程,本研究由此通过了理论饱和度检验。
2 高管团队知识隐藏量表开发与模型验证
2.1 量表开发
为了开发出可以测量高管团队知识隐藏行为的科学量表,使其能够涵盖高管团队知识隐藏的理论边界,本研究参考国内外学者关于高管团队、知识隐藏的理论研究成果,借鉴Connelly等(2012)关于员工个体知识隐藏的测量题项,以小规模问卷调查、半结构化访谈和参与式观察获取的质性资料为基础,结合扎根理论研究材料,整理形成团队运行过程中高管团队知识隐藏初始量表测量题项。为了确保测量题项表达简洁、准确,专门聘请人力资源管理领域的2位资深教授,不断完善高管团队知识隐藏初始量表测量题项的概念内涵和语义表达。经过逐项修订后,高管团队知识隐藏初始测量量表见表4。

表4 高管团队知识隐藏初始测量量表
2.2 模型验证
2.2.1 随机抽样
为了便于开展探索性因子分析和验证性因子分析,相关调查分两阶段进行。第一阶段为小规模预试样本调研,所获数据用于探索性因子分析;第二阶段为大规模问卷调查,所获数据用于验证性因子分析。
为了确保问卷回收数量,预试样本调研主要面向高校在职MBA和EMBA学员且在长三角地区企业担任高管,同时,请其将调查问卷发给所在企业高管团队的其他高管填写后统一回收。除去5份漏答或错答的调查问卷,回收有效问卷327份,有效回收率为79.37%,包括28家企业高管团队。为了确保个体数据能够聚合至团队层面,对预试样本数据分别计算组内一致性系数Rwg(J)、跨级相关系数ICC(1)和ICC(2)。结果发现,1家企业高管团队的9份样本数据的Rwg(J)系数小于0.60,删除该团队数据,继续检验,剩余27个团队数据的Rwg(J)值均大于0.7,ICC(1)和ICC(2)值分别大于阈值0.05、0.50,ICC(1)的F统计量均大于1且通过显著性检验,表明27个团队的个体层面数据能聚合至团队层面。
为了验证高管团队知识隐藏模型的构思维度,第二阶段的问卷调查主要面向上海、郑州、南昌等地企业高管团队,通过现场发放、微信推送、电子邮件等方式进行,累计发放883份调查问卷,回收607份,剔除4份不合格问卷后,有效回收率为68.29%,包括53家企业高管团队。通过团队聚合性分析,研究发现,2家企业高管团队的19份样本数据的Rwg(J)系数小于0.60,删除上述2个团队数据后再进行检验,余下51个高管团队数据的Rwg(J)值均大于0.7,ICC(1)和ICC(2)值分别大于阈值0.05、0.50,ICC(1)的F统计量均大于1且通过显著性检验,表明上述51个高管团队的个体层面数据能够聚合至团队层面。
综合以上两阶段调研,样本的描述性统计结果见表5。

表5 两阶段调研样本描述性统计结果
2.2.2 探索性因子分析
通过探索性因子分析,找出高管团队知识隐藏多元观测变量的本质结构并进行降维处理。探索性因子分析利用SPSS17.0统计软件进行,采用主成分分析法提取公因子,使用最大方差法进行正交旋转以获取因子载荷。结果发现,高管团队知识隐藏行为被划分为高管知识隐藏行为预估、高管知识隐藏策略选择和高管知识隐藏行为演化3个子维度,删除各维度中与概念相关性较弱的测量题项后,获得最终因子分析结果,见表6。其中,高管知识隐藏行为预估维度中被删除的题项是“团队运行过程中,我会分析知识隐藏的必要性”;高管知识隐藏行为演化维度中被删除的题项是“我会根据需要调整知识隐藏策略”。

表6 探索性因子分析结果
本研究探索性因子分析的KMO值是0.847,说明通过因子分析获取因子维度的方法合适。高管团队知识隐藏3个因子的初始特征值都大于1,解释方差分别为14.164%、18.291%、12.356%,累计解释方差是44.811%,各题项因子载荷均大于0.6,Cronbach's α值分别是0.816、0.824、0.779,说明各因子有较高的区分效度与信度。
2.2.3 验证性因子分析
根据Anderson和Gerbing[29]的建议,为了验证三维度模型是否为测量高管团队知识隐藏的最佳模型,采用验证性因子分析考察各因子与其对应的测度项之间是否符合预设的理论关系,进而验证高管团队知识隐藏结构模型。在对已有文献展开理论分析的基础上,基于探索性因子分析和主轴式编码分析结果,对高管团队知识隐藏的3个因子进行不同组合,提出3个具有竞争性的备择模型,见图2。其中,M0为单因子模型,包括高管知识隐藏行为预估单因子维度;M1为双因子模型,包括高管知识隐藏行为预估和高管知识隐藏策略选择双因子维度;M2为三因子模型,包括高管知识隐藏行为预估、高管知识隐藏策略选择和高管知识隐藏行为演化三因子维度。在此基础上,使用第二阶段调查获得的样本数据进行验证性因子分析,获取不同因子模型拟合指标值,见表7。通过比较不同因子模型指标拟合情况,确定高管团队知识隐藏的最佳测量模型,从而达到验证模型的目的。
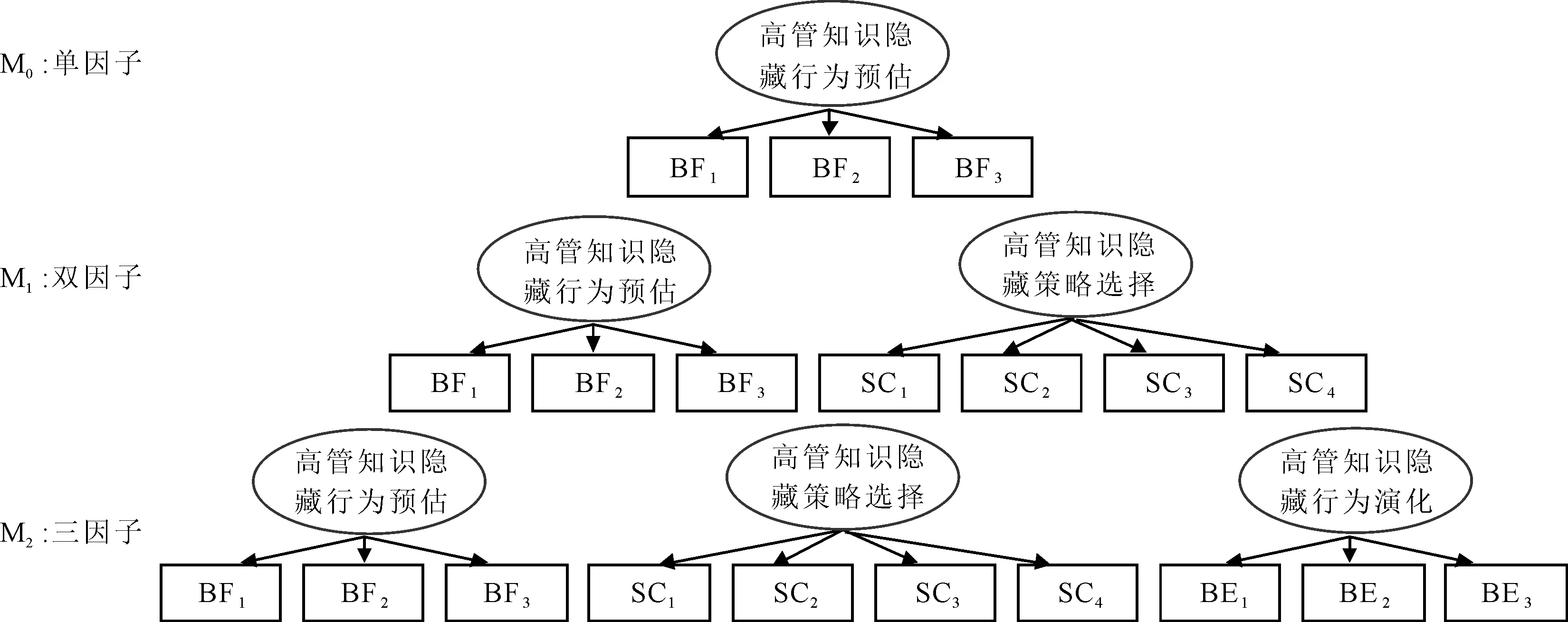
图2 高管团队知识隐藏备择模型
选择5个常用拟合指标χ2/df、RMSEA、GFI、CFI和NNFI,考察各备择模型的拟合情况,结果见表7。
由表7可知,三因子模型的拟合指标均优于其它因子模型,说明三维度高管团队知识隐藏备择模型的代表性最好,因此认为将高管团队知识隐藏划分为高管知识隐藏行为预估、高管知识隐藏策略选择和高管知识隐藏行为演化3个维度是较为理想的测量模型,由此M2也成为高管团队知识隐藏的最终理论分析模型,其验证性因子分析结果见图3。
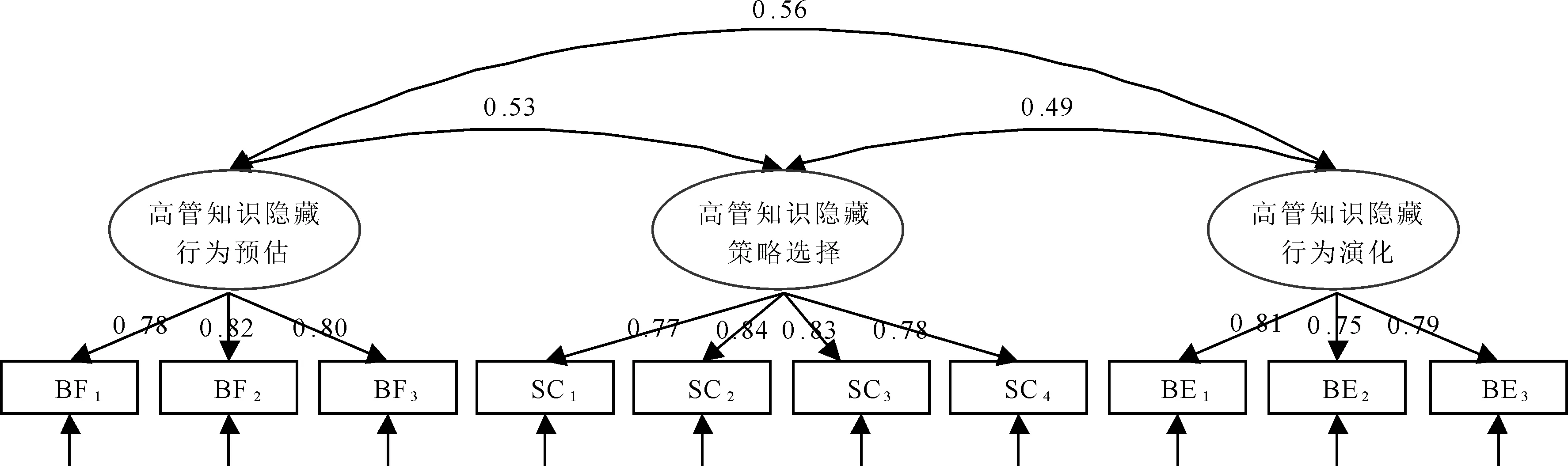
图3 验证性因子分析结果

表7 验证性因子分析模型拟合情况
本研究进一步提取各因子平均方差AVE,判断测量题项对其所属因子维度的平均变异解释力。结果发现,三维因子AVE的值均大于0.5,说明量表的聚合效度较好。
3 研究结论与讨论
运用扎根理论研究、问卷调查等方法,构建团队运行过程中高管团队知识隐藏结构模型,开发出高管团队知识隐藏测量量表,并得出以下研究结论:①高管团队知识隐藏是一个具有丰富内涵的多维度构念,高管团队知识隐藏结构模型中的三因子(高管知识隐藏行为预估、高管知识隐藏策略选择、高管知识隐藏行为演化)是一个有机整体,共同构成了高管团队知识隐藏的理论内涵;②高管团队知识隐藏测量量表包括高管知识隐藏行为预估、高管知识隐藏策略选择和高管知识隐藏行为演化3个维度,其中高管知识隐藏行为预估和高管知识隐藏行为演化分别包含3个测量题项,高管知识隐藏策略选择包含4个测量题项。数据分析结果表明,该量表具有较高信度和效度,是一个有效的评价量表。
从理论角度看,以往关于员工个体层面知识隐藏行为的研究很难揭示组织层面知识隐藏的内在作用机理,而且西方学者针对员工个体开发的知识隐藏量表在测量团队知识隐藏行为时也表现出与组织情境不相符合的特征[8],尤其是对于责任使命重大、成员关系较为复杂的高管团队而言,缺乏考量中国文化背景的高管团队知识隐藏测量量表极大阻碍了对高管团队知识隐藏行为的深入探讨。鉴于此,本研究的理论贡献主要在于:第一,与Connelly等(2012)、赵婷(2013)和Peng(2013)围绕知识隐藏结构维度和测量工具展开的研究相比,本研究得出的3个高管团队知识隐藏维度具有更高层次感和立体感,能够更加全面地反映高管团队知识隐藏行为。其中,高管知识隐藏行为预估体现了高管团队成员在团队运行过程中,根据不同环境和条件作出的知识隐藏行为选择,是高管面对外界环境变化采取的灵活措施;高管知识隐藏策略选择是高管团队成员在团队运行过程中通过采取不同策略隐藏自己掌握的知识,达到防止知识外泄的目的;高管知识隐藏行为演化表明高管团队成员间的知识隐藏行为并非一成不变,而是根据团队运行情况不断调整知识隐藏策略,以满足高管个人或是团队需要。第二,本研究在扎根探索的基础上,结合本土文化背景开发的高管团队知识隐藏测量量表,既可直接应用于高管团队知识隐藏定量研究,为该领域研究提供理论依据和测量工具支持,同时,对其它组织情境下知识隐藏行为的测量研究具有借鉴价值。第三,将针对员工个体或一般工作团队的知识隐藏研究转化为企业高管团队研究,这对于未来开展高管团队知识隐藏研究具有直接价值,同时,对其他特定工作团队的知识隐藏研究也具有借鉴意义和启发作用。
本研究对企业高管团队合理规避知识隐藏行为、加强高管团队内部知识管理具有现实指导意义,具体表现在以下方面:①团队运行态势和个人利益相关性是导致高管团队成员知识隐藏行为的重要诱因,关系到高管知识隐藏行为预估结果,因此企业领导应时刻关注高管团队决策运行,关心团队决策行为与高管个体利益的相关性,确保高管团队决策运行平稳、有序;②高管团队知识隐藏是一个较复杂的过程,高管团队成员会在不同时机选择不同方式隐藏自己掌握的知识,因此企业领导应敏锐感知高管团队成员心理和行为变化,关注高管团队成员是否隐藏知识,并在查明高管知识隐藏原因的基础上采取有效措施,鼓励高管团队成员共享知识;③环境变化是引发高管知识隐藏策略调整、变更,以及促进高管知识隐藏行为演化的重要原因,因此企业应努力打造团结、友好的高管团队工作氛围,鼓励高管成员在团队运行过程中进行反思,开展批评与自我批评,为团队决策积极建言献策,共享知识和信息,并以团队领袖为核心形成团队合力,齐心协力地完善和执行企业战略决策。
猜你喜欢
城市建设理论研究(电子版)(2022年27期)2022-09-30 08:42:22
城市建设理论研究(电子版)(2022年10期)2022-06-08 07:11:48
城市建设理论研究(电子版)(2022年4期)2022-06-08 01:25:34
城市建设理论研究(电子版)(2022年9期)2022-06-07 08:29:06
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09 06:12:12
汉字汉语研究(2020年2期)2020-08-13 07:52:48
电子制作(2019年22期)2020-01-14 03:16:24
股市动态分析(2019年11期)2019-07-08 02:45:30
股市动态分析(2019年23期)2019-07-06 01:17:04
股市动态分析(2019年24期)2019-07-06 01:16:28
