
基于大数据聚类算法的计算机网络信息安全防护研究
2022-08-12 01:54郭畅
现代信息科技 2022年7期
郭畅
(沈阳现代制造服务学校,辽宁 沈阳 110148)
0 引 言
当下,计算机网络信息普遍存在着黑客攻击与篡改、病毒或木马程序入侵与窃取等风险,从而给国家、企业或个人带来威胁与损失。强化计算机网络信息安全,对于民航、铁路、电力、气象等信息化产业而言,既是自身安全发展的需要,而且也关系着经济社会安全。因此,国家和企业均十分重视计算机网络信息防护。从防护方法运用看,多数运用贝叶斯分类算法(BC),但此种防护方法运用领域的广度远不及大数据聚类算法(CALD)。大数据聚类算法不仅应用领域广,而且其技术成果相对较为成熟,但在网络信息安全防护的研究与运用中,该方法也存在着对目标属性的非线性关系的揭示不够明晰,造成一些问题来源不够确定。这就需要准确应用大数据聚类算法的反向传播模型,精准计算网络中的各中复杂关系,从而提高网络信息安全分析的科学性。本文以民航空管部门值班记录数据为样本,对计算机网络数据进行仿真与测试,以期为防护计算机网络信息安全提供技术支持。
1 大数据聚类算法概述
作为数据挖掘的一个主要概念,聚类意即根据某一标准,把数据集分割成不同的类或簇,使得同一类或同一簇的数据彼此足够相似、非同一类或非同一簇的数据非足够相,有助于分析者发现数据中隐藏的逻辑关系与形势。该算法包括单机与多机聚类算法,前者又分为传统聚类算法(基于分区、分层、密度、网络、模型的聚类算法)、抽样聚类算法(基于随机选择、层次方法、大型数据库聚类算法)和降维聚类算法,后者又分为并行聚类算法(划分数据并将其分布于不同机器上)以及基于Map Reduce 聚类算法如图1所示。这些算法既有优点,也有其缺点,如传统聚类算法虽然实现简单,但难以处理数量较大的数据;抽样聚类算法虽然时空开销较小,但聚类的精确性却容易受到抽样质量的影响;降维聚类算法虽然能够减少数据集、优化处理开销、高效且可扩展,但难以为高维数据集提供有效解决方案;并行聚类算法虽然高效,但算法却不容易实现;基于Map Reduce 聚类算法虽然具有很强的扩展性,但软、硬件资源消耗较多,难以为选择、提取等常用操作提供原语,且基于Map Reduce 的每个查询难以实现。
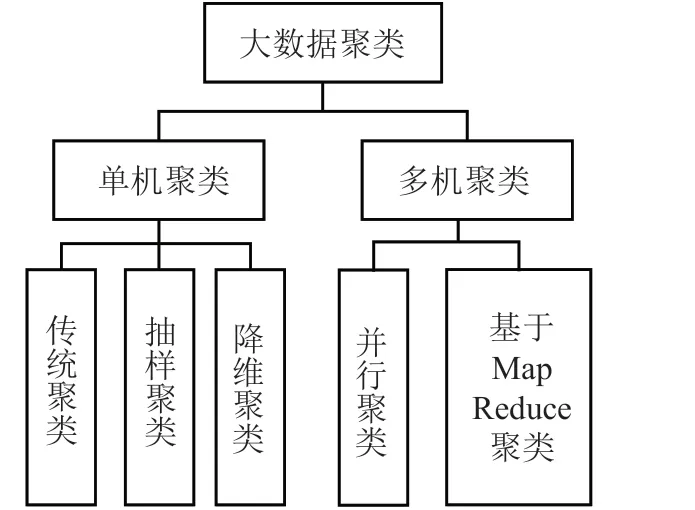
图1 大数据聚类算法分类
这需要在大数据聚类算法运用中强化其合理性,充分发挥其优点而规避其缺点。随着聚类技术的发展,大数据聚类算法已广泛运用于市场营销、金融、通信、农业、医疗、移动网络等领域,为这些领域的计算机网络信息安全防护提供了技术支撑与保障。比如,在金融领域,基于上市企业的盈利、偿债能力指标等进行聚类试验,可以获得股票板块分类,为投资者提供借鉴;在移动通信领域,根据原始数据处理,通过聚类算法挖掘用户的关注热点及其行为模式,从而为用户提供精确的位置服务等。
2 大数据聚类算法运用思路
计算机网络信息存在的风险问题,主要包括网络安全风险,如网络系统存在漏洞与缺陷、病毒与黑客攻击、恶意代码或恶意设备植入系统等;计算机系统风险,如相关设备配置不尽合理、运行不尽稳定、功能不尽完善,加之系统设计不够科学、管理不够规范,容易计算机病毒入侵、传染和扩散,从而造成计算机主板损坏、数据丢失、工作效率下降;信息数据风险,如数据泄露、数据篡改、数据滥用、违规传输、非法访问、流量异常等。大数据聚类算法运用的基本思路,是通过构建评估模型,分析计算机网络系统弱点及其安全策略的抵御攻击能力,针对系统、漏洞、攻击行为及安全策略进行综合评估,分析和评估这些要素的相互作用及影响,从而形成对计算机网络信息安全防护的综合评估。
在基于大数据聚类算法的计算机网络信息安全防护中,对于网络权值的调节,该算法一般运用后向传播方式,其中算法模型结构具体包括3 层,即输入层、隐含层及输出层如图2所示,其中在隐含层中又可能存在多层结构。
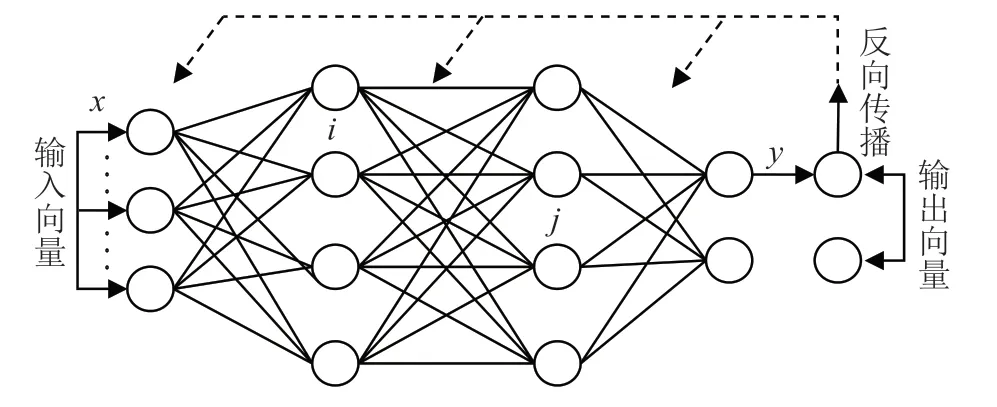
图2 大数据聚类算法拓扑图
在该结构模型的运用中,输入网络中的向量,经过隐含层的处理后输入向量,再经过输出层处理后输出向量,然后获得期望输出向量。在此过程中,一方面应注意输入层同隐含层之间的权值矩阵,可将其表示为,其中列向量V表示的是第个信息相匹配的权向量;另一方面应注意输出层与隐含层之间的权值矩阵,可将其表示为,其中列向量W表示的是第个信息能够实现的匹配性权向量。
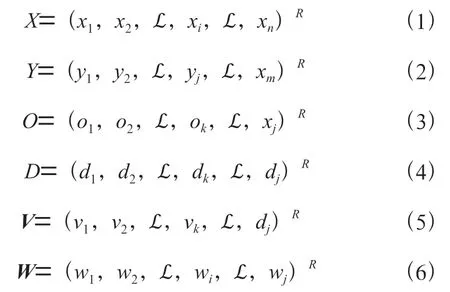
3 模拟仿真与测试
以民航空管部门值班记录数据为样本,对计算机网络数据进行仿真与测试。按照一定规则,笔者将安全防护策略的涉密信息安全分为五个等级如表1所示。基于大数据聚类算法,在一定条件下,对计算机网络信息防护策略进行模拟仿真,并运用相关数据对其进行测试。在大数据聚类算法设计与运用中,考虑防护策略体系包含广域网、局域网等多个子系统,且网络测试性能可能受到隐含层信息数量的影响,因此把12 个实际计算机网络设备作为分析对象,对参数进行设定。其中,最小训练误差goal、最大训练步数epochs、show 的取值分别为0.01、1 000、20,剩余参数则采取默认取值。其中,goal 值受到设备的正常率、完全好两个最小误差值的共同影响。
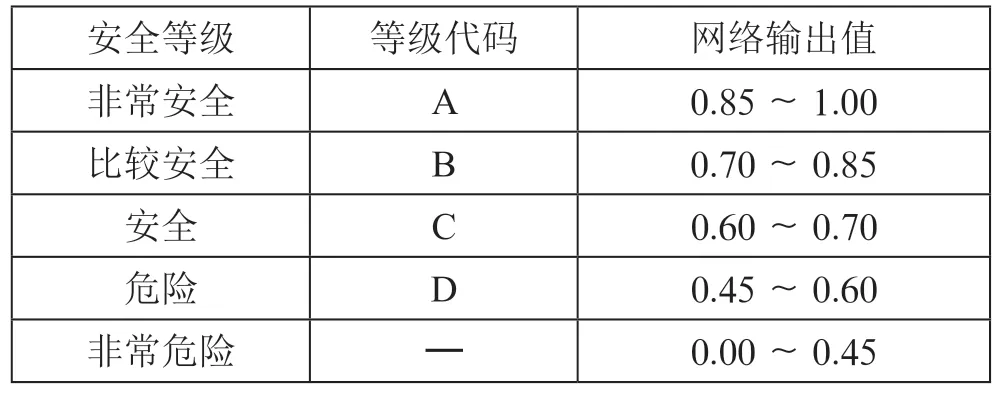
表1 安全及涉密信息安全等级一览
以12 组计算机网络的实际运行数据为测试对象和分析样本,实验测试结果如表2所示。
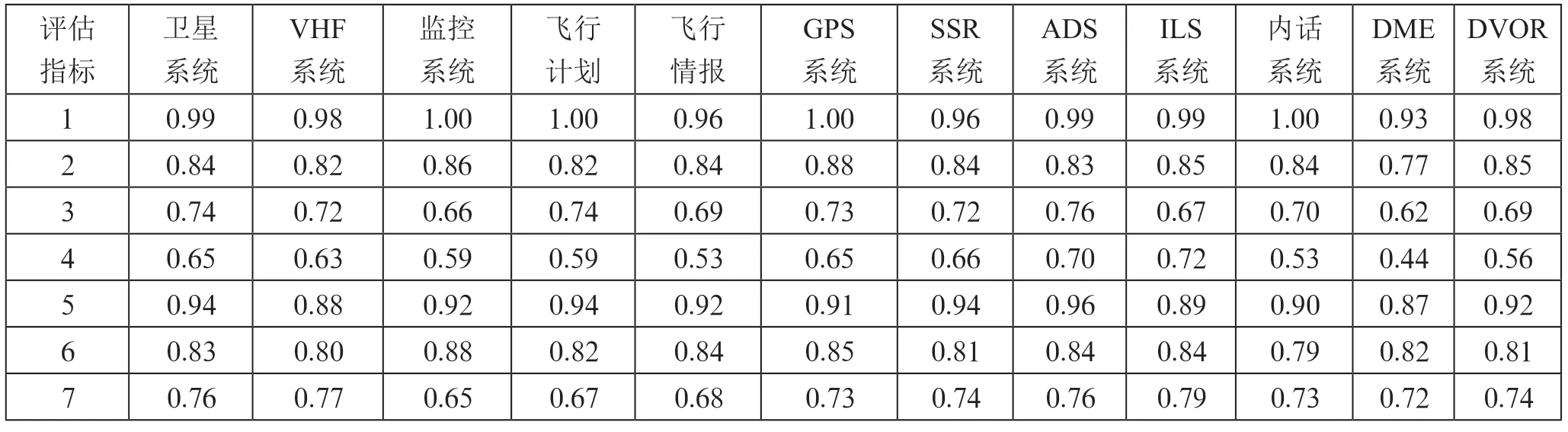
表2 样本测试结果
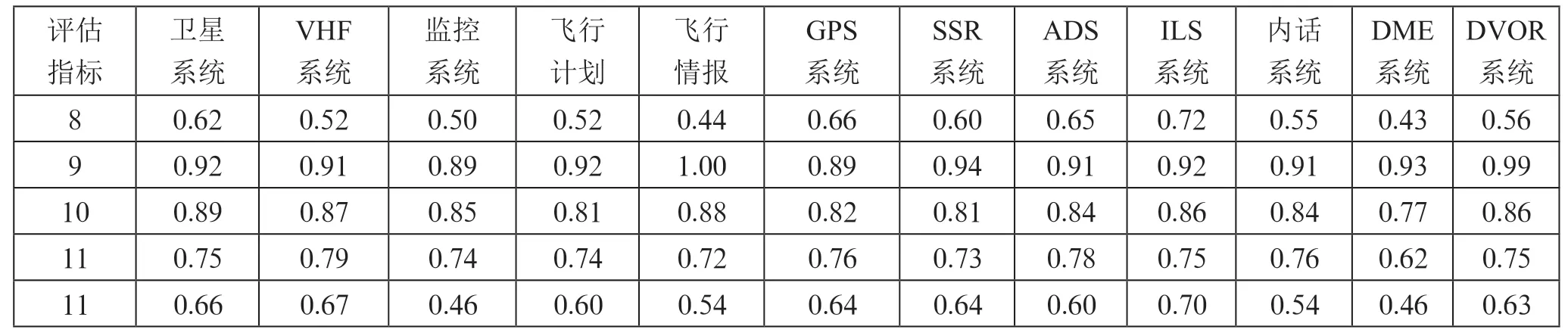
续表
在验证文中的网络性能方面,运用函数Trainlm 进行处理和验证,将目标值设定为0.01,通过3步训练,结果为0.001 201 54。这一结果在设计误差范围内,达到降低错误率的预期目的。从图3可以看出各种错误率相对应的实际效果。
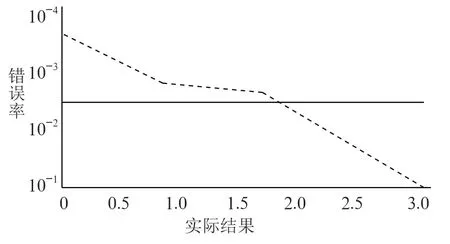
图3 计算机网络错误率
在验证上述训练方法获得的网络性能,笔者运用Postreg 函数对各项数据进行非线性回归分析,由此获得效果最优的结果。基于拟合度=0.999,非线性回归分析结果如图4所示。
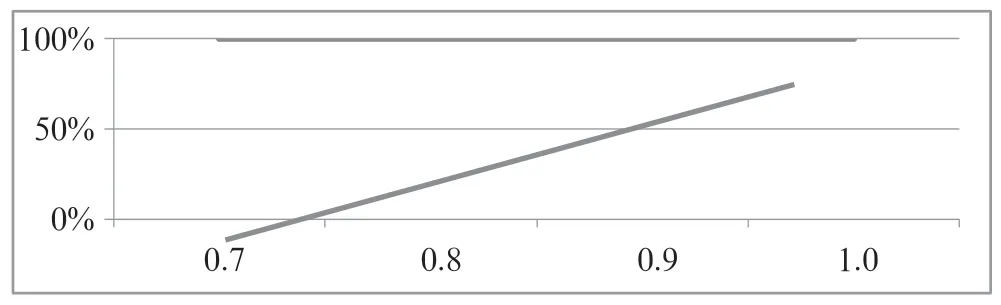
图4 非线性回归分析所得拟合曲线
在此基础上,运用仿真输出与目标两种向量,进行线性回归分析,并以相关系数作为线性回归分析的依据。在网络性能最优条件下,斜率与截距分别为1、0,其拟合度为1,这表明该方法较适用于计算机网络安全的非线性特征。
4 结 论
基于大数据聚类算法,探求计算机网络信息安全防护方法,并通过模拟仿真对此进行验证。结果表明,所提方法适用于计算机网络安全的非线性特征,能够准确反映计算机网络安全运行的状态,从而为防护计算机网络信息安全提供了有效的思路与保障。诚然,大数据聚类算法的运用,并不能完全解决计算机网络信息安全防护问题,应在此基础上,一方面,强化和完善计算机网络信息安全防御,如建立计算机网络信息安全检测系统、安全反应机制,定期对其安全性进行检查,以降低其安全问题发生的概率;另一方面,在内网与外网之间构建防火墙,提高其防火等级,为计算机网络运行提供有效保障。
猜你喜欢
电子制作(2018年16期)2018-09-26
电子制作(2018年12期)2018-08-01
现代企业文化(2018年13期)2018-06-09
消费导刊(2017年20期)2018-01-03
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
公民与法治(2016年21期)2016-05-17
信息记录材料(2016年4期)2016-03-11
电子设计工程(2015年6期)2015-02-27
江苏年鉴(2014年0期)2014-03-11
