
增强非线性特征提取的时间间隔感知序列推荐
2022-08-12 01:54宁昱霖
现代信息科技 2022年7期
宁昱霖
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
0 引 言
随着互联网技术的迅速发展,全球的数据总量呈井喷式增长。虽然大数据蕴含丰富的信息及巨大的商机,但信息过载造成的问题也随之而来。如何有效的从海量的数据中提炼出有价值的信息成为当今信息检索领域发展的一大难题。推荐系统作为缓解信息过载的技术之一,它已经成为电子商务、短视频、新闻推送等各个互联网领域的核心技术。
传统的推荐模型,例如基于内容和基于用户的协同过滤推荐,它们是以一种静态的方式建模用户和项目的交互且只可捕获用户广义的喜好,而在现实生活中用户的偏好是不断改变的并且用户前后的行为都存在极强的关联性。序列推荐模型就是利用了用户兴趣的动态性,试图将用户过去的历史行为记录建模成一个项目序列,根据用户最近交互的项目来预测他们的下一步行动。基于时间间隔的序列推荐模型是在传统的序列推荐模型中显式地融入用户与项目交互时间的间隔。但由于数据集中涉及了复杂的时间间隔信息,单一的前馈神经网络无法完全提取数据集中蕴含的信息,因此,本文准备使用三阶段线性层代替前馈神经网络以充分提取数据集中蕴含的信息。
1 模型与方法
本文提出的模型是基于基线模型TiSASRec进行改进的,在本节中,将详细介绍改进后的TiSASRec 模型的各个组成部分,包括个性化时间间隔处理、嵌入层、时间感知自注意力模块和预测层,模型流程如图1所示。
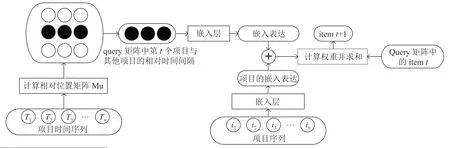
图1 模型流程图
1.1 问题描述
定义和分别表示用户字典和项目字典,给定每个用户∈的历史行为序列S={s,s,…},其中s∈,行为序列对应的时间序列可表示为T={t,t,…}。在时间步长时,模型会根据之前的项以及两两项目之间的时间间隔预测下一个项目。
1.2 项目序列及时间序列的处理
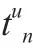
1.3 相对位置矩阵的计算
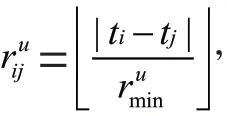
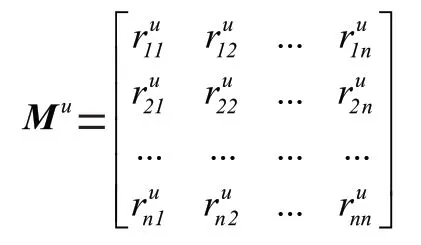
为了防止时间间隔过于稀疏,将时间间隔大于的时间间隔替换为,剪裁后的矩阵表示为M。
1.4 嵌入层
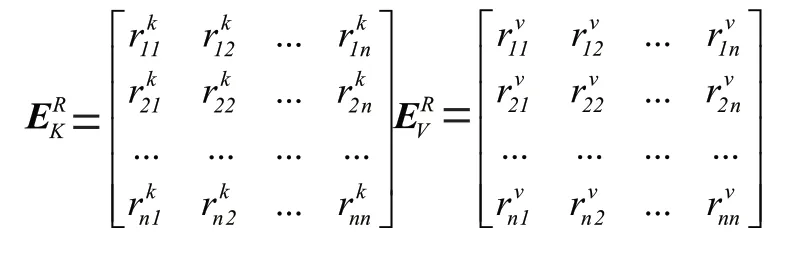
首先创建一个项目嵌入矩阵M∈,为嵌入维度。通过检索用户项目序列中的项目索引,从M中找到对应的嵌入表达,将其堆叠在一起,形成矩阵E,E∈R,可表示为E=[m,m,…,m]。然后,使用两个不同的可学习的位置嵌入矩阵E,E∈R分别作为自注意力机制中key,value 矩阵的绝对位置编码,表示为E=[p,p,…,p],E=[p,p,…,p]。对于相对位置嵌入矩阵的嵌入表示,同样采用两个版本E,E∈R,分别作为自注意力机制中key,value 矩阵的相对位置编码,表示为:
1.5 时间感知自注意力模块
1.5.1 时间感知自注意力机制
对于每个用户∈的项目交互序列E=[m,m,…,m],计算新的序列=[,,…,z],对于每个z都是由项目交互序列的嵌入表达经过线性变化后再加权求和得到的。用公式可表达为:
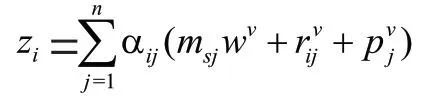
其中,w∈R为自注意力机制中将项目交互序列转化为value 矩阵的线性层,α是softmax 函数对于权重系数的归一化操作,可以表达为:
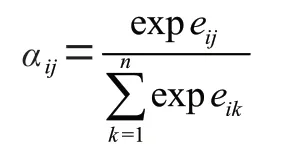
其中,e为结合交互序列中的项目信息,绝对位置信息以及相对位置信息的权重系数,可表示为:
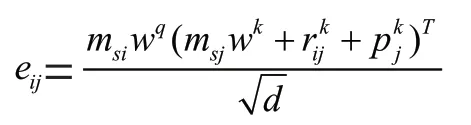
其中,w,w∈R分别为自注意力机制中将项目交互序列转化为query,key 矩阵的线性层。为了防止模型未卜先知,需屏蔽所有q和k的连接(>)。
1.5.2 多层线性层
时间感知自注意力机制本质上仍然是一个线性模块,没有提取数据集非线性特征的能力,因此,需要在时间感知自注意力机制后面添加一个可以提取数据集中非线性特征的模块。TiSASRec 模型采用一个前馈神经网络提取数据集的非线性特征,但由于模型的输入信息中包含复杂的时间信息,因此,本文选择使用三层线性层替换前馈神经网络进行非线性特征的提取,并且使用LeakyReLU 函数作为激活函数。其公式可表达为:
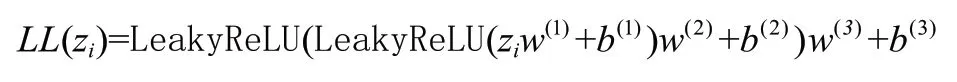
其中,∈R,∈,∈,∈,∈,∈R。
由于稠密数据集可能需要叠加多层注意力机制以及线性层,因此,会出现过拟合、梯度爆炸、训练不稳定等问题。因此,采用传统的层规范化、残差连接以及dropout 来解决这些问题。
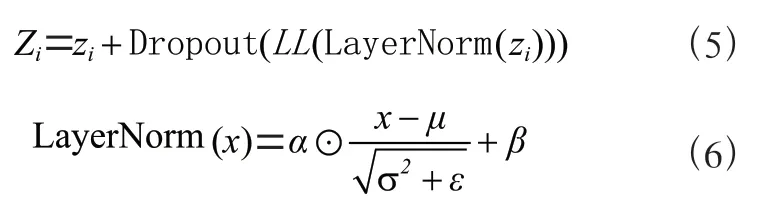
其中,⊙指的是元素的乘积,和是的均值和方差,和分别是比例因子和偏差项。
1.5.3 预测层
为了预测下一个项目,利用隐因子模型的思想计算用户对项目的偏好分数,公式为:

1.6 损失函数及模型推理
由于模型的目标是提供一个排序后的项目列表,以验证正样本在项目列表的位置。因此,通过负采样的方式来优化项目的排名。损失函数选择binary cross entropy 函数:
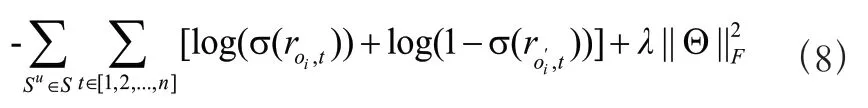

其中,o为期待的正输出,’为o的负样本,Θ={M,E,E,E,E},||•||是Frobenius 范数,是正则化参数,S是某个用户的项目序列,是全部用户的集合。
模型的任务是将给定的项目序列S={s,s,…,s}以及时间序列T={t,t,…,t}转化为=[,,…,z],z可表示为:

2 实验
2.1 数据集简介
Movielens 1M:一个广泛用于推荐系统的电影数据集,包含来自6 000 名用户对4 000 部电影的100 万条评分。
京东数据集:由京东公开,包含7 万名用户对2 万个物品的455 万条行为信息,为防止项目在项目序列中重复出现,本文只选取行为信息中的“浏览”部分作为样本。
豆瓣影评数据集:采集于豆瓣电影,包含60 万个用户对7 万部电影的400 万条评分。
数据清洗后的数据集数据如表1所示。
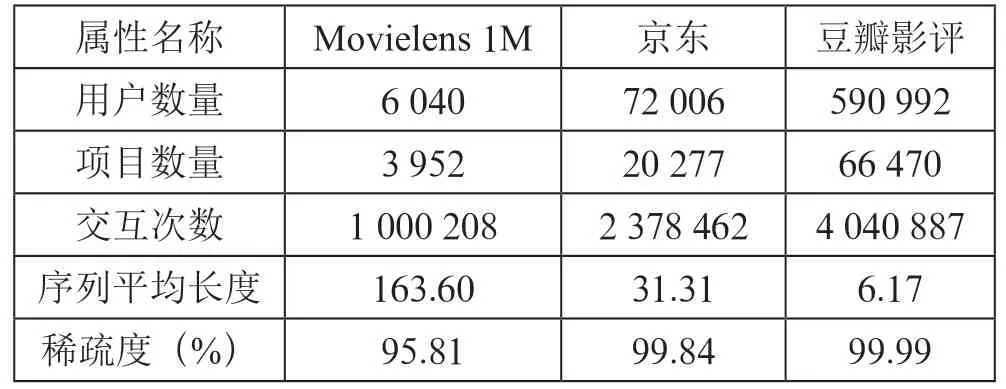
表1 数据集的数据
2.2 评估指标
由于模型最终会提供一个排序后的项目列表,因此,实验选取了两个常见的Top-评估指标HitRate@和NDCG@,以评估模型的性能。对于每个用户,模型会随机选取100 个负样本,将正样本与负样本混合,对这101 个样本进行排序,再通过HitRate@和NDCG@计算模型的性能。
HitRate@关注每个用户的正样本是否出现在101 个样本排序后列表的前个项目中,其计算公式为:
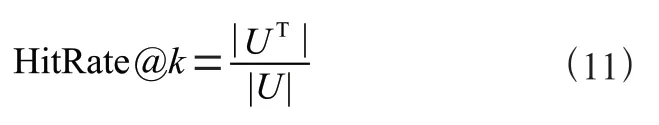
其中,||代表全体用户的数量,||代表所有模型推荐成功的用户数量。
NDCG@在HitRate@的基础上更细粒度地关注了正样本在101 个样本中的位置,位置靠前得到的增益越大。其计算公式为:
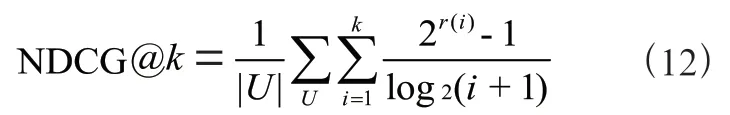
其中,()为指示函数,用于判定第个项目是否为正样本。
2.3 实验环境
操作系统及环境:Ubuntu18.04、Python3.8、CUDA11.0、PyTorch1.7.1。
GPU:NVIDIA GeForce RTX 2080 Ti。
CPU:Xeon E5-2678 v3。
2.4 实验结果对比与分析
由于本文提出的模型是根据TiSASRec 模型进行改进的,因此在本节,将在三个数据集上进行对比。相关超参数设置如表2所示。
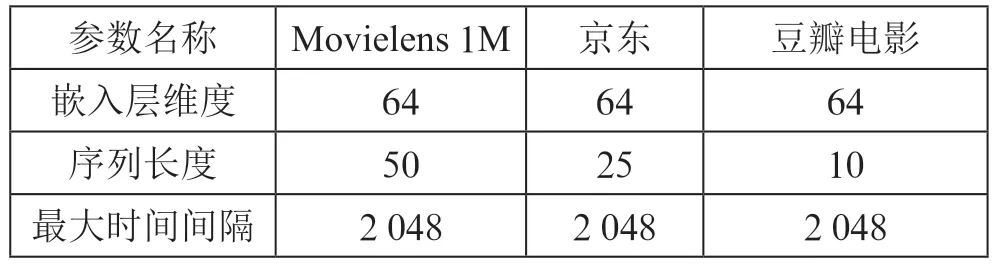
表2 默认超参数设置
实验结果对比如表3所示。
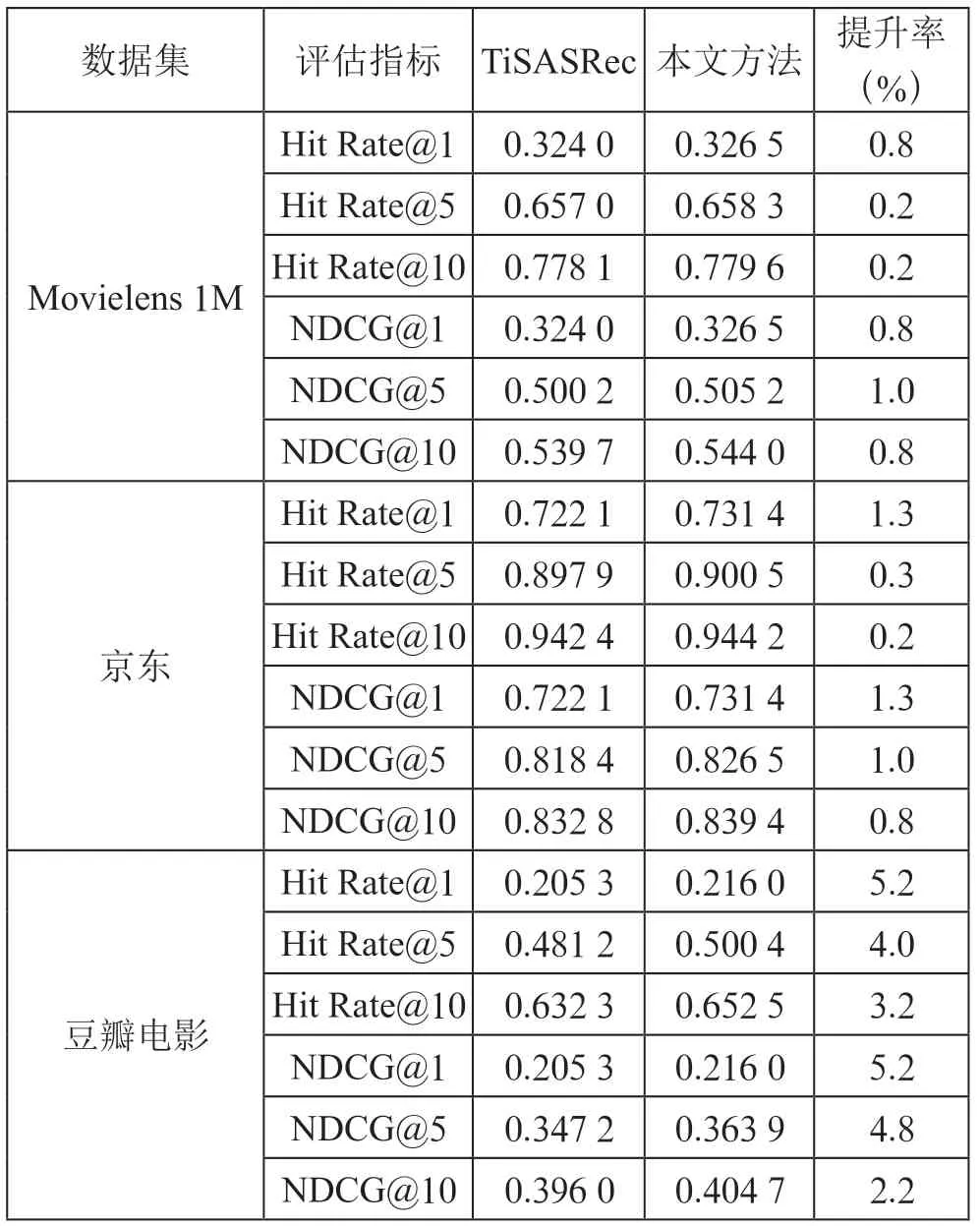
表3 实验结果对比
由表3可以看出,本文提出的方法在三个数据集上的性能皆优于TiSASRec 模型。这在一定程度上可以证明用三层线性层代替传统的前馈神经网络可以提高模型提取非线性特征的能力,尤其对于稀疏数据集豆瓣电影的提升最大,因为使用多层线性层更能捕获数据集中的细粒度特征。
3 结 论
本文基于TiSASRec 模型改进的模型通过使用三层不同维度的线性层代替传统的前馈神经网络,提高了模型提取非线性特征的能力。经实验验证,评估指标在三个数据集上性能皆有提高。后续的工作将聚焦于改进融入相对时间间隔信息的策略,降低模型的复杂度,提高推理速度。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
中学生数理化·高一版(2021年2期)2021-03-19
数学小灵通(1-2年级)(2020年11期)2020-12-28
小学生学习指导(低年级)(2019年3期)2019-04-22
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
读写算·小学低年级(2014年4期)2014-07-24
