
基于影响力的跨社交网络谣言扩散模型与抑制方法
2022-08-10 08:12:04郭宏刚
计算机应用与软件 2022年7期
郭宏刚 杨 芳
1(河北师范大学计算机与网络空间安全学院 河北 石家庄 050024) 2(河北师范大学河北省网络与信息安全重点实验室 河北 石家庄 050024) 3(河北师范大学河北省供应链大数据分析与数据安全工程研究中心 河北 石家庄 050024) 4(河北公安警察职业学院警务科研处 河北 石家庄 050091)
0 引 言
随着移动互联网的普及,在线社交网络实现了飞速发展,从早期的Facebook和职场社交“linkedin”到近期风靡全球的短视频分享网络“抖音”等,在线社交网络已经延伸至人们娱乐、工作和生活之中[1],成为人类社会信息交流的一个重要方式。在线社交网络给人们交流带来了极大的便利,但也加速了不良舆论、不良广告及谣言的传播与扩散,对公共安全及社会经济造成不可忽略的破坏[2]。
谣言的网络传播机制与生物病毒的传染病模型存在许多相似之处,研究人员随之采用传染病模型研究谣言的传播和扩散过程[3]。文献[4]利用谣言在人类社区中的传播方式与病毒传播类似的特点,将微博社区用户抽象为网络中的节点,从宏观角度研究谣言在网络中的传播机理构造微博消息传播网。虽然传染病模型与谣言传播十分相似,但一部分人员在谣言传播中会对谣言进行纠正,对谣言传播产生弱化的效果,传染病模型则不包含该机制。文献[5]对传染病模型进行了修改,补充了用户正面观点和反面观点分别对谣言的促进和弱化机制,并将模型的模拟结果与Twitter的真实数据进行了比较,实现了较好的准确性。传染病模型的易感人群通过接触感染者成为新感染者,而社交网络用户通过理性判断决定是否传播谣言或是只阅读谣言,因此谣言传播中的用户具有很高的自主性和独立性。
为了提高谣言传播模型的准确性,文献[6]提出基于谣言接受概率函数的谣言传播模型CASR(Credulous Affected Spreader Rationals),CASR模型的谣言接收概率函数考虑了正负影响的媒介效应,很好地模拟了谣言的传播过程。文献[7]基于复杂网络提出了谣言传播模型,并且给出了最大化谣言传播的方法。虽然文献[6-7]对谣言传播的模拟效果好于基于传染病的模型,但这两个模型仅考虑了单一的社交网络,无法用于跨社交网络的谣言传播分析。
跨社交网络转发和分享消息已经成为当前十分普遍的社交内容传播形式,而现有的主要谣言传播模型尚未有效支持跨社交网络的谣言传播[8]。本文提出一种基于影响力分级的跨社交网络谣言传播模型,通过模型可计算和预测网络的谣言传播趋势,并且基于该模型设计了贪婪的谣言抑制方法。对于大规模的社交网络,为网络的每个节点建立传播路径会产生巨大的计算负担,本文借助影响力排名的结果,为传播模型保留高影响力节点的传播路径,忽略低影响力节点的传播路径,由此降低谣言传播模型的复杂度,并且降低谣言抑制算法的计算成本。
1 跨网络谣言传播模型
传统社交网络的传播模型将网络中用户的传播能力考虑为相等值,并未考虑影响力差异对谣言传播不同的推动作用[9]。本文根据社交网络拓扑结构的局部连接密度评估每个节点的影响力,并且将节点按影响力排名,考虑影响力强弱对谣言扩散的不同推动力。
1.1 社交影响力排名
网络中目标节点的邻居数量(即密度)能够反映节点的重要性和影响力,本文基于节点在网络拓扑中的位置和结构信息来评估节点的影响力。具体而言,分析用户与邻居节点间的拓扑结构相似性,相似的用户分为同一级影响力,将用户按影响力进行聚类处理。
将社交网络表示为图G=(V,E),用户集为V={v1,v2,…,v|V|},用户关系表示为边E={e1,e2,…,e|E|}。设Ni为节点vi的邻居集,将邻居数量作为vi的度,记为di。节点与邻居之间的关系视为用户影响力的一个决定因素,如果邻居节点间连接较为密集,那么消息容易在小范围内传播,导致消息的大规模扩散能力降低,因此邻居节点之间交互过强对该节点的影响力具有负面影响。通过式(1)计算节点vi的局部聚类系数:
(1)
局部聚类系数统计了节点与每个邻居的相同邻居数量,节点间相关性的度量方法是局部分簇系数的一个关键因素。采用外部聚类系数排名度量(External Clustering Ranking Measure,ECRM)[10]评估目标节点与其邻居之间的影响力等级。以图1为例描述ECRM方法,图中包含3个shell,第1次迭代选择图中度最小的节点,记为一级节点,第2次迭代从剩下的节点中选择度最小的节点,记为二级节点,如此迭代处理,直至所有节点被分配级别。例如:图中节点8和节点9均与第三级连接,因此第三级是这两个节点的共性,节点8和节点9组成第4级。

图1 ECRM方法的示意图
将网络分级后,根据邻居等级计算每个节点vi的shell向量。
定义1满足以下关系的向量称为节点vi的shell向量:
(2)
式中:|Ni(k)|表示节点vi第k级的邻居数量;f为网络的最大级数。
在图1的实例中,节点7-节点9的shell向量分别为:SV7={0,0,0,2,0,2,0},SV8={0,1,1,1,1,0,0},SV9={0,0,1,1,1,0,0}。采用皮尔森相关系数计算shell向量间的相关性,计算式为:
(3)

定义2节点vi的shell聚类系数定义为:
(4)
式中:第1项为相关系数;第2项为节点的度。节点vi与每个邻居之间的相关性越高,对vi传播能力的负面影响越大,(2-Ci,j)计算了节点vi的shell聚类系数。节点的度也是shell聚类系数的一部分,max(d)表示社交网络图的最大度。
运用邻居规则[11]提高影响力节点的准确性,首先计算节点的CRM(Clustering Ranking Measure):
(5)
式中:SCC为shell聚类系数。
对所有邻居的CRM求和,获得节点vi的ECRM:
(6)
算法1为节点影响力排名算法。首先通过k-shell算法为每个节点分级,通过式(2)计算每个节点的shell向量,再通过式(3)计算节点vi和vj之间的相关性Ci,j,然后计算vi的shell聚类系数SCCi。最终根据ECRM分数将节点按影响力降序排列。
算法1节点影响力排名算法
输入:社交网络图G=(V,E)。
输出:节点的影响力排名Lin。
1.通过k-shell算法为每个vi分配IT(vi);
//分配等级
2.foreachifrom 1 to |V| do
3.计算SVi;
//式(2)
4.end for
5.foreachifrom 1 to |V|
6.SCCi←0;
7.foreachvjinNido
8.计算Ci,j;
//式(3)
10.end for
11.end for
12.foreachifrom 1 to |V| do
13.CRMi=0;
14.foreachvjinNido
15.CRMi=CRMi+SCCj;
16.end for
17.end for
18.foreachifrom 1 to |V|
19.ECRMi=0;
20.foreachvjinNido
21.ECRMi=ECRMi+CRMj;
22.end for
23.end for
24.将节点按ECRM分数降序排列生成Lin;
1.2 谣言传播模型
线上社交网络的一个用户通过社交账号在某个社交网络发布消息、视频或者图像等内容,关注该账号的用户将收到通知并阅读该内容。各大社交网络均支持用户跨网络转发或分享内容,导致一些热点内容可能被广泛传播。图2所示是消息跨社交网络传播的示意图。设I={0,1,2,…,m}为社交网络的标识集,每个编号对应一个社交网络,如:0表示微博,1表示微信。将标识符为j的社交网络记为OSNj,谣言发布者在OSNj发布谣言内容,然后在其他网络选择“种子用户”,使谣言在其他网络扩散,将被选择的社交网络记为TOSN。假设每个用户的ID跨社交网络唯一,每个用户记为i∈OSNTOSN,在OSNj中关注用户i的集合记为F(i)j。
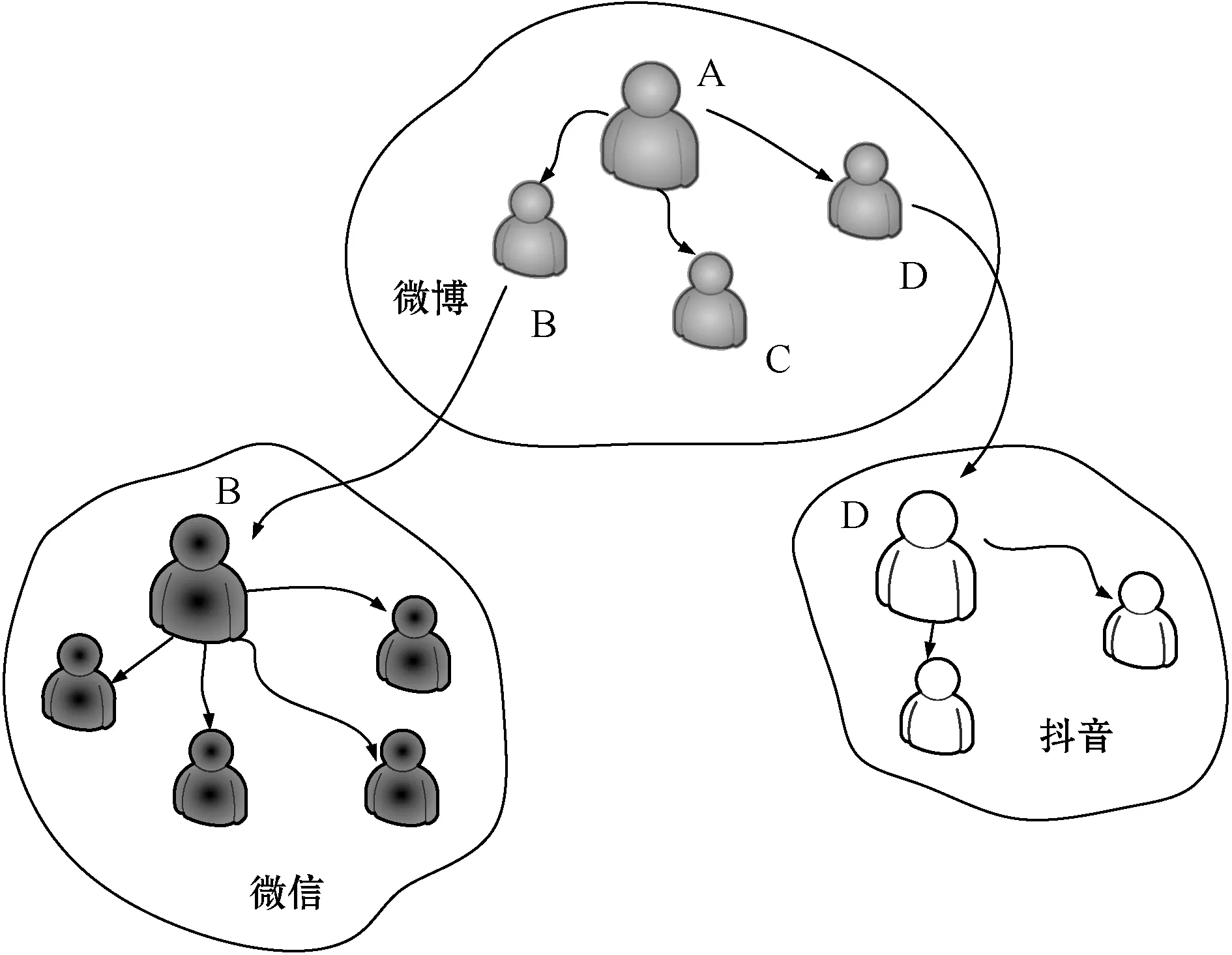
图2 跨社交网络消息传播示意图
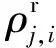
定义3将阅读用户i所发布谣言的人数称为谣言到达数。
假设用户A被100个人关注,其中50个人阅读了A发布的谣言,那么其谣言到达数为50。本文利用谣言到达数来评估谣言的传播力,为每个用户分配一个权重表示该用户在谣言传播中的贡献。用户i的谣言到达数σ(i)计算为:
(7)
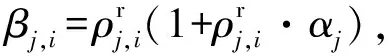
定义4将用户集S中每个用户i的谣言到达数总和称为谣言到达总数。用户集S的谣言到达总数计算式为:

(8)
用户集S的传播力可计算为:
(9)
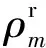
(10)
(11)
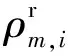
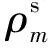
(12)
(13)
在Φ′(S)的定义中存在一个问题:该定义并未考虑父节点和子节点间的依赖关系,设βj,i表示子节点j对父节点i的贡献,那么包含父-子节点依赖关系的传播力计算为:
(14)
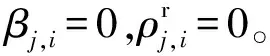
集合S的影响力Φ(S)修改为:
Φ(S)=Φ′(S)-Φ″(S)
(15)

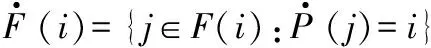
(16)
定义一个邻接矩阵A=[aji]标记子节点j是否连接父节点i,矩阵元素aji定义为:
(17)
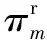
(18)
计算S集合所有用户的传播力σ(i)之和即可获得Φ′(S),然后为Φ′(S)增加父-子依赖关系的信息。设计一个矩阵Θ=[ϑji],其对角元素表示增加一个用户产生的增益,其他元素为父-子依赖关系的相关信息,矩阵Θ的元素ϑji定义为:
(19)
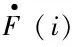
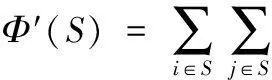
(20)
式中:Φ′(S)表示集合S的谣言到达数。
2 谣言抑制方法设计
设N为目标社交网络中所有用户的数量,xi∈{0,1}表示用户i是否被选择。将谣言抑制问题建模为以下的最小化问题:
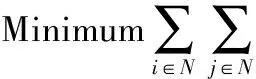
(21)
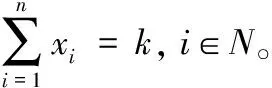
算法2为基于贪婪的谣言抑制算法,输入为可操控的用户数量和可操控的社交网络数量。贪婪算法主要通过依次将用户加入操控用户集S中,观察谣言到达数是否降低,最终找到最小化谣言到达数的用户集S。社交网络可以对S中的用户进行合理的处理,控制谣言的扩散。
算法2谣言抑制算法
输入:目标用户数量N,社交网络数量D。
输出:用户集S。
1.S←NULL;
//初始化S
2.while |S|≤Ndo
3.inc′←0;
4.R←N-|S|;
5.foreachiin {N-S} do
//遍历S集以外的用户
6.ifR==Dthen
//检查是否满足跨网络约束
//未能减少网络数量
9.end if
10.end if
11.inc←Φ′(S∪{i})-Φ′(S);
//计算谣言到达数
12.ifinc>inc′ then
13.inc′←inc;
14.u′←i;
15.end if
16.end for
17.S←S∪{u′};
18.end while
3 仿真实验与结果分析
实验环境为PC机:i7- 9850H处理器,2.6 GHz主频,32 GB内存,编程环境为MATLAB2017b。
3.1 实验数据集
从Twitter、微博和YouTube收集了3组数据集,分别构成两个单一网络benchmark数据集和一个跨社交网络(Cross Social Networks,CSN)benchmark数据集,详细信息如表1所示。Twitter数据集共包含458个关于“Charlie Hebdo攻击”事件的谣言,微博数据集共包含32个关于“河北省石家庄市”的谣言。CSN数据集由Twitter数据集和YouTube数据集组成,保留了“Charlie Hebdo攻击”谣言从Twitter分享到YouTube的连接,最终CSN的Twitter数据集共包含4 540个节点和62 881个有向连接,YouTube数据集的相关节点包含5 703个节点和83 245个有向连接。
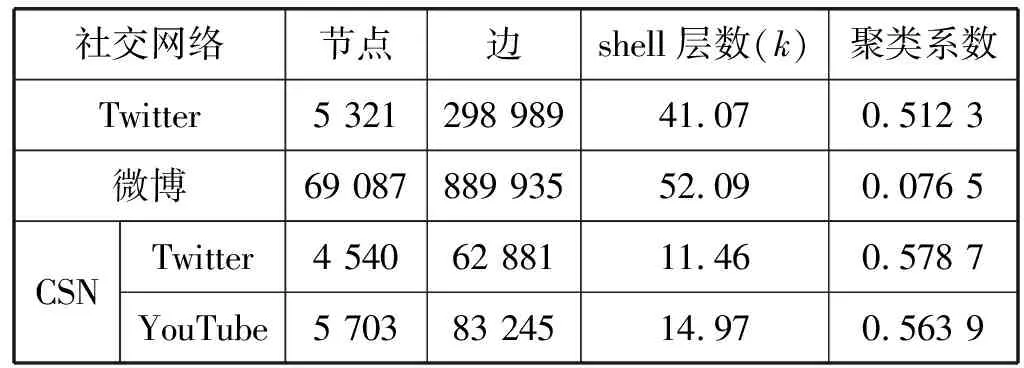
表1 Benchmark数据集基本信息
3.2 谣言传播模型的实验
线性阈值模型(Linear Threshold Model, LT)[12]和Epidemic模型[13]是两个主流的谣言传播模型。LT模型是一种基于概率的微观模型,主要分析了节点在局部区域的相关性和相互影响,从而模拟出谣言的传播趋势,该模型需要设立传播指数参数k,将Twitter数据集的k设为2.5,微博数据集的k设为1.5。Epidemic模型是一种基于传染病模型的宏观模型,通过感染人群将谣言不断地扩散到全网,该模型需要网络的聚类系数参数,将Twitter数据集的聚类系数设为0.512 3,微博数据集的聚类系数设为0.076 5。
图3为Twitter网络、微博网络和CSN的谣言传播曲线。在Twitter网络第6个时间步谣言出现第1个高峰,大约70%的用户参与传播谣言,在第14个时间步谣言出现第2个高峰,几乎所有用户参与传播谣言,然后谣言的热点开始下降,逐渐趋于平静。LT模型成功模拟出第1个高峰,并且也几乎模拟出第2个高峰,但LT模型仅仅模拟了传播的上升趋势,在峰值之后并未呈现下降趋势,与实际情况不符。Epidemic模型十分粗略地模拟出了总体上升和下降趋势,但是不包含对传播细节的描述。本文模型准确地模拟出第1个峰值,第2个峰值出现的时间略迟于实际情况,另外本文模型的峰值数据低于实际情况,主要原因在于该模型为了减低复杂度,仅保留了影响力节点的传播路径。
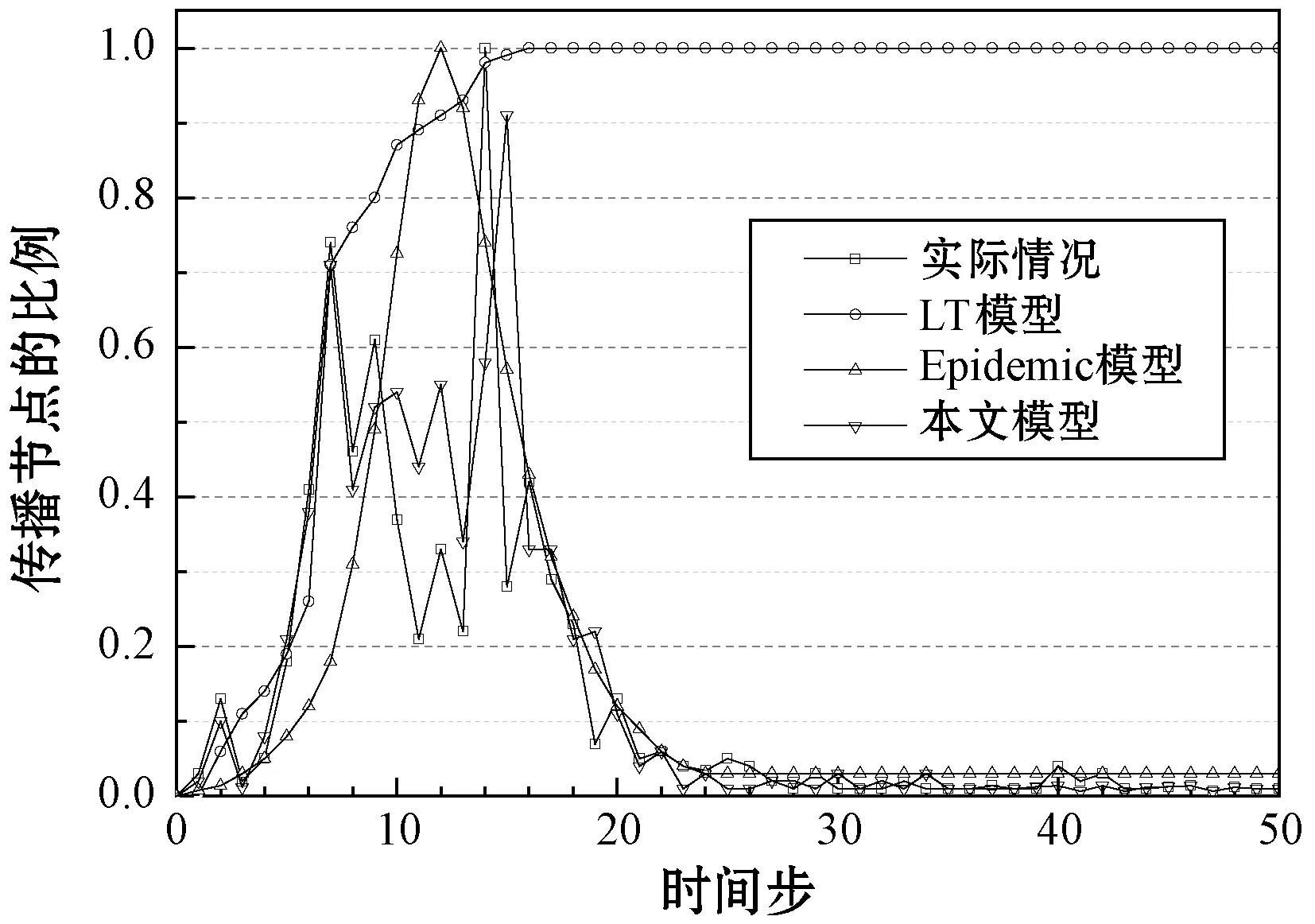
(a) Twitter网络的谣言传播曲线
在微博网络第2个时间步谣言出现第1个高峰,大约60%的用户参与传播谣言,在第20个时间步谣言出现第2个高峰,约28%的用户参与传播谣言,在第33个时间步谣言出现第3个高峰,约32%的用户参与传播谣言,然后谣言的热点开始下降,逐渐趋于平静。LT模型成功模拟出第1个高峰,LT模型仅仅模拟了传播的上升趋势,在峰值之后并未呈现下降趋势,与实际情况不符。Epidemic模型模拟出第一个峰值的上升和下降趋势,但不包含对传播细节的描述。本文模型第1个峰值出现的时间略迟于实际情况,成功模拟出第2个峰值,另外本文模型的峰值数据低于实际情况,主要原因在于该模型为了减低复杂度,仅保留了影响力节点的传播路径。
由于LT模型和Epidemic模型均不支持跨网络的谣言传播,因此仅将本文模型和实际传播情况进行了比较,如图3(c)所示。可以看出,本文模型较为准确地模拟出了谣言跨网络扩散的上升趋势和下降趋势,可用来预测谣言的跨网络传播趋势,作为谣言检测和谣言抑制的预处理步骤。
3.3 模型参数实验
在本文模型的贪婪谣言抑制算法中需要预先确定可操作的用户数量参数N,因此通过试错实验观察不同的N值(失活节点数量)对谣言抑制效果的影响。本文算法选择影响力高的传播节点作为失活节点,中断其传播行为,由此抑制谣言的传播。图4所示分别为Twitter、微博和CSN网络上谣言抑制实验的结果,三组实验表现出相似的现象,即失活的节点数量越多,谣言的下降速度越快,抑制效果越明显。
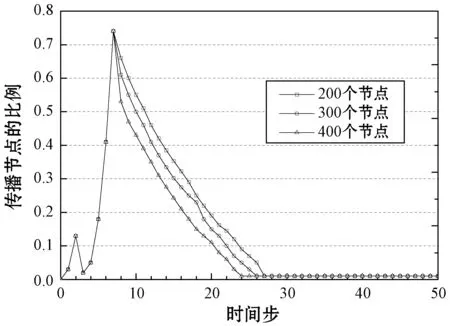
(a) Twitter网络的谣言抑制实验
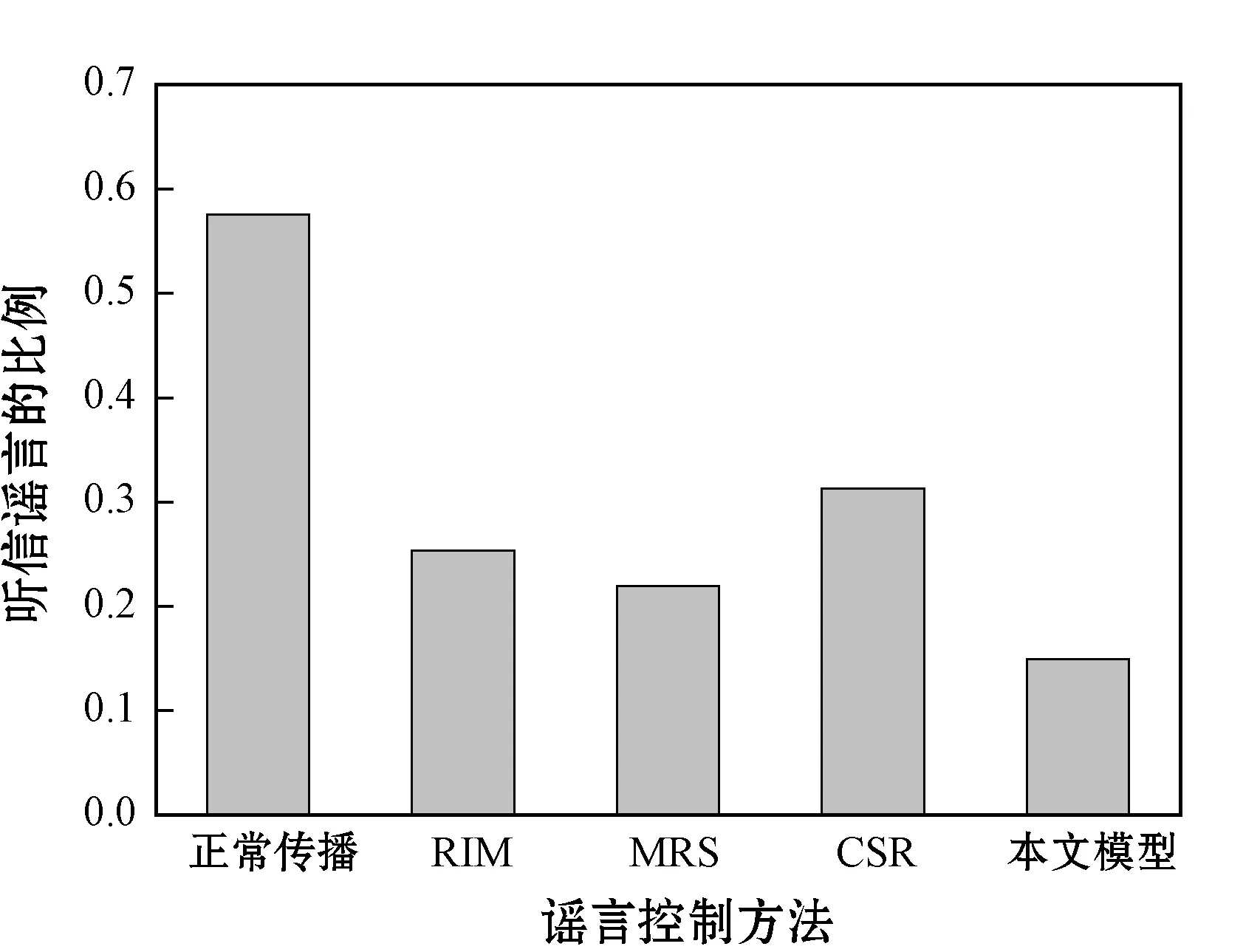
3.4 对比实验分析
为了评估本文贪婪谣言抑制算法的有效性,选择3个不同类型的谣言抑制算法与本文算法完成对比实验分析,结果如图5所示。RIM[14]是一种支持多社交网络的谣言最小化传播算法,该算法预测谣言下一步的传播路径,通过切断路径抑制谣言传播。MRS[15]是一种单一社交网络的谣言抑制方法,该方法考虑了正向意见对谣言传播的促进作用,也考虑了反对意见对谣言的抑制作用。CSR[16]也是一种单一社交网络的谣言抑制方法,该方法通过提高谣言在社区的传播率,从而降低谣言在社区间的传播概率。
(a) Twitter网络的对比实验
观察Twitter网络和微博两个数据集中听信谣言的人数比例,CSR的抑制效果差于其他三个模型,主要原因在于该模型虽然降低了社区间的传播,但提高了社区内的传播,导致总体的传播人数较高。本文模型和RIM模型对谣言的总体抑制效果较好,RIM模型通过对预测传播路径的切断来抑制谣言传播,本文则是通过直接失活传播能力强的节点来抑制谣言传播。
4 结 语
本文提出基于影响力分级的跨社交网络谣言传播模型,通过模型可计算和预测网络的谣言传播趋势,最终基于模型设计了贪婪的谣言抑制方法。本文模型能够较好地模拟出谣言传播的峰值及其时间,为了降低模型的复杂度,仅保留了影响力节点的传播路径,导致峰值数据低于实际情况。另外本文模型能够较为准确地模拟出谣言跨网络扩散的上升趋势和下降趋势,可用来预测谣言的跨网络传播趋势,作为谣言检测和谣言抑制的预处理步骤。
本文模型直接通过失活一部分节点对谣言传播进行抑制,但这会导致社交网络用户的满意度降低。未来将通过增强意见领袖的正向言论来对谣言进行澄清,以期在抑制谣言的同时,保持用户对社交网络的满意度。
猜你喜欢
环球时报(2022-04-13)2022-04-13 17:16:04
中国盐业(2018年17期)2018-12-23 02:16:56
NBA特刊(2018年14期)2018-08-13 08:51:40
电子测试(2017年15期)2017-12-18 07:19:27
人大建设(2017年11期)2017-04-20 08:22:49
民间文化论坛(2016年2期)2016-12-01 05:41:46
学生天地(2016年32期)2016-04-16 05:16:19
智能系统学报(2015年4期)2015-12-27 09:38:39
瞭望东方周刊(2015年12期)2015-04-14 23:28:02
人间(2015年21期)2015-03-11 15:24:39
