
域通用和域分离字典对学习的行人重识别算法
2022-08-09 06:11:04严双林颜昌沁
计算机工程与应用 2022年15期
颜 悦,严双林,颜昌沁
1.昭通学院 物理与信息工程学院,云南 昭通 657000
2.南京理工大学 计算机科学与工程学院,南京 210014
行人重识别,是指在非重叠相机视角下匹配行人,可用于大规模监控网络中特定行人目标的快速检索,目前已经取得了一系列重大研究进展[1-7],具有广阔的应用前景,包括行人检索、行人跟踪和行人行为分析等。尽管计算机视觉研究人员已经做出了很大的努力来提高行人重识别的性能,但是由于行人的外观在跨相机视角下通常表现出巨大的视觉歧义性,因此行人重识别技术仍存在巨大的挑战。
除了背景干扰、遮挡、照明变化和姿势差异外,不同相机视角之间的域偏移也是导致行人视觉歧义的关键因素之一。通常有两种方法可以解决这些问题,一种是学习或构造域不变特征表示,另一种是采用模型来减轻上述不利影响。对于前者,域不变特征可以是手工特征或基于学习的特征。在手工特征中,最常用的包括基于生物仿生特征的协方差描述符(covariance descriptor based on bioinspired features)[8]、局部特征的对称驱动累积(symmetry-driven accumulation of local features)[9]、分层高斯描述符(hierarchical gaussian descriptor)[10]、局部特征集合(ensemble of localized features)[11]和局部最大共现表示(local maximal occurrence representation)[3]。这些特征可以直接用于跨视角或无监督的行人重识别,但它们不能充分利用数据分布信息,因此无法解决不同相机视角之间的域偏移问题。在基于学习的特征表示中最常用的学习方法包括域分离网络(domain separation networks)[12]、图像-图像转换网络(image-image translation networks)[13]和奇异值分解网络(singular value decomposition network,SVDNet)[14]。但是,基于深度学习的特征表示方法通常需要手动标记大量的训练样本对,这极大地限制了在实际应用中的可扩展性。基于模型的行人重识别主要包括基于度量学习的方法[15-22]、基于字典学习的方法[23-27],以及基于深度学习的方法[22,28-30]。基于度量学习的方法通常是通过搜索最佳特征子空间来缓解视觉歧义。在该子空间中,类间差异可以被最大化,而类内差异可以被最小化。尽管鲁棒的特征表示对判别性有着重要影响,但在此类方法中通常没有被给予足够的重视。在减轻行人图像的视觉歧义时,基于字典的学习也是一种常用方法,它可以基于原始输入特征创建更鲁棒的特征。基于深度学习的方法由于其良好的性能吸引了研究人员的注意,但是这种方法需要大量手动标记的训练样本,可扩展性较差。因此,以上方法均不能完全缓解由不同相机视角之间的域偏移引起的行人外观歧义等问题。
从图1可以看出,不同相机视角下的域偏移是导致行人外观歧义的主要因素之一。另外还可以发现,同一相机视角中的域信息在一定时间内是稳定的,并且同一视角下的所有图像共享相同的域信息。此时,如果能将域信息从行人图像中分离出来,那么剩余的信息将不会受到域信息的干扰,并且来自不同视角的行人图像之间也将不再存在域偏移。基于这种思想,本文提出一种域通用和域分离字典对学习方法,用于跨视角行人重识别。在此方法中,假定来自同一相机视角下的图像共享相同的域。为了获得行人的视觉特征,将来自不同相机视角下的行人图像分为特定视角的域信息部分和域分离的行人外观特征部分。

图1 来自PRID2011数据集中的行人图像样本对Fig.1 Person image sample pairs selected from PRID2011 dataset
为了实现上述信息的分离,本文在低维空间中跨视角学习具有域信息的域通用字典,并将其用于从输入图像中分离出域信息,而学习域分离字典是用来表示分离域信息后的行人外观特征。同时,由于来自同一相机视角的图像具有域相似性,因此用于表示域信息的字典应该是低秩的。为了进一步提高学习字典的判别力,强制具有相同身份、相同视角的多幅图像的编码系数在域通用字典下有很强的一致性。此外,提出一种新颖的扩展正则化方法来解决不同行人相似外貌特征和同一行人不同外貌特征的视觉外观歧义问题。以两个视角X1和X2为例,所提出方法的具体实现过程如图2所示。
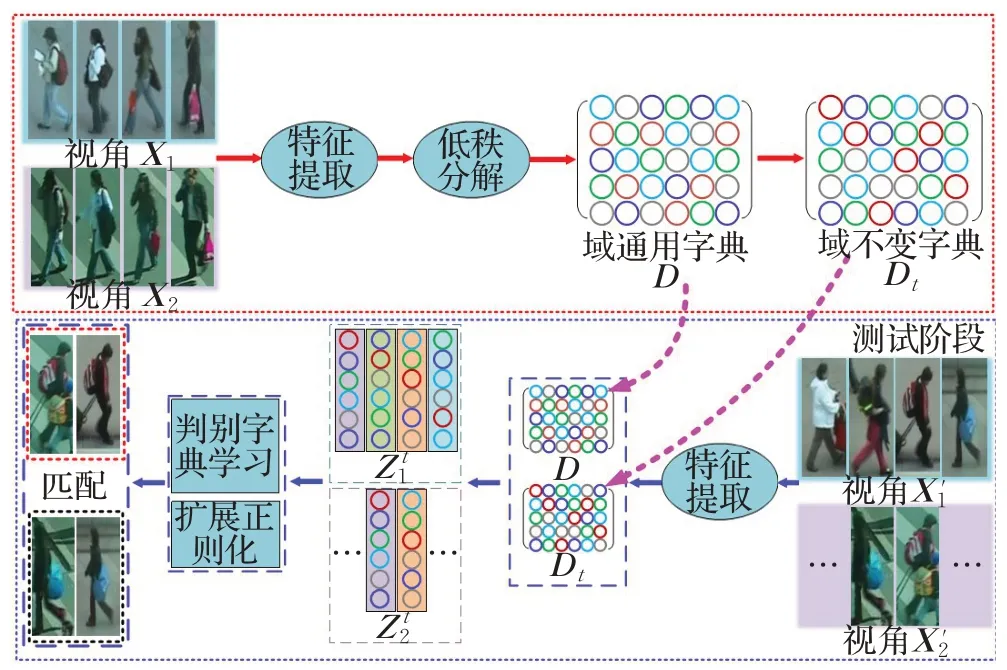
图2 所提出方法的总体框架Fig.2 Overall framework of proposed method
本文的主要创新如下:
(1)将同一视角下的行人图像分解为特定视角的域信息分量和分离域信息后的行人外观分量,并提出仅基于行人的外观设计行人匹配方案,从而避免域偏移对识别结果的不利影响。
(2)为了将域信息与行人外观信息分开,同时学习域通用和域分离字典,其中,鼓励来自同一相机视角中的所有图像在域通用字典下共享相同的稀疏表示,此时,可以将每个视角下的域信息与行人外观信息分离开来。
(3)为了促进学习字典的判别性并解决行人外观在视觉上的歧义,提出一种新颖的扩展正则化方法来解决不同行人的外貌特征比同一人更相似,而同一行人的外貌特征比不同人更不相似的问题。
1 提出的方法
1.1 判别性字典学习框架
字典学习是通过学习算法来构建一组具有表达能力的特征,实现对输入样本的有效表示。该过程能使学习到的字典具有较强的表达能力,但没有较强的判别能力。为解决这一问题,把鲁棒的特征表示学习和判别式度量学习整合到一个框架中。
首先,学习两个字典分别表示不同视角i下的行人图像特征:
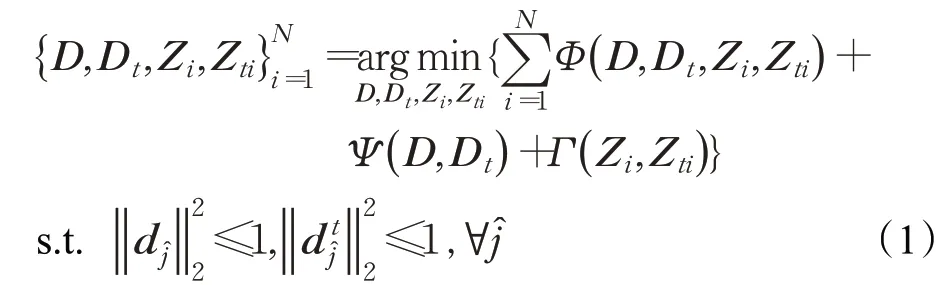
式中,D∈ℜm×d是所有相机视角下的行人图像共享的域通用字典(domain-commom dictionary),D t∈ℜm×d t表示域分离字典(domain-invariant dictionary),用于在分离域信息后对仅剩的行人外观特征进行编码,Z i是对应字典D的编码系数矩阵,Z ti是对应字典D t的编码系数矩阵。Φ(D,D t,Z i,Z ti)是数据保真度项,将其最小化可以赋予字典D和D t表达能力。Ψ(D,D t)是字典的判别促进项,Γ(Z i,Z ti)是编码系数的判别促进项,将这两项最小化可以使字典和编码系数具有更好的判别能力。d ĵ是D的第̂列,是D t的第̂列。
具体地,为了缓解不同相机视角之间的域偏移,首先把数据保真度项Φ(D,D t,Z i,Z ti)表示为:
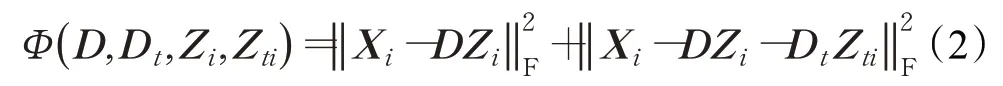
式中,X i∈ℜm×n表示相机视角i下的训练样本集,用于建立相机视角i的域信息,‖X i-DZ i-用于把域信息与不受域信息影响的行人外观特征分开。同时,来自同一台相机的图像具有相同的域特征,并且这些图像在域特征方面彼此线性相关,因此,把字典判别促进项表示为:
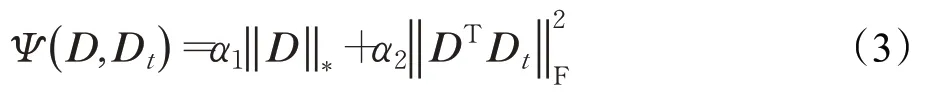
式中,‖D‖*是对字典D的核范数求解,它是矩阵D的奇异值之和,对该项最小化能够实现域信息从输入样本X i中的分离。同时,因为域信息分量和行人的外观特征具有不同的空间形态,引入结构不相干的正则项来促使字典D和D t相互独立。α1和α2是两个标量参数,分别代表着‖D‖*和项的权重信息。
另外,希望来自不同相机视角的同一行人在域分离字典D t上具有相同的编码系数,也就是说,如果只有两个相机视角(i和j),并且每个行人在每个视角中只有一张图像时,应将最小化。同时还希望来自不同相机视角的不同行人的编码系数之间的距离大于一个常数,此时有:

式中,c是一个常数。表示i视角下的第l个行人的编码系数;z t,jl表示j视角下的与i视角下第l个行人最不相似的行人编码系数,此时它们同属于一个行人身份;表示j视角下的与i视角下第l个行人最相似,但又是第l*个不同于行人身份l的行人编码系数,其中,意思是当时,,此时不同行人之间的距离远远大于同一行人之间的距离,它不会导致对行人身份的误判,损失记为0。而表示意味着在这种情况下使用行人图像特征的编码系数进行行人匹配会导致误识别,此时,最小化可以促使。进一步地,对于i视角域的编码系数矩阵Z i,相同的域应具有相同的稀疏表示。基于以上考虑,定义式(1)中的判别促进项Γ(Z i,Z ti)可表示为:
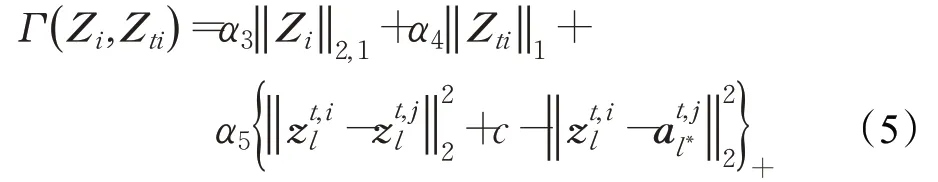
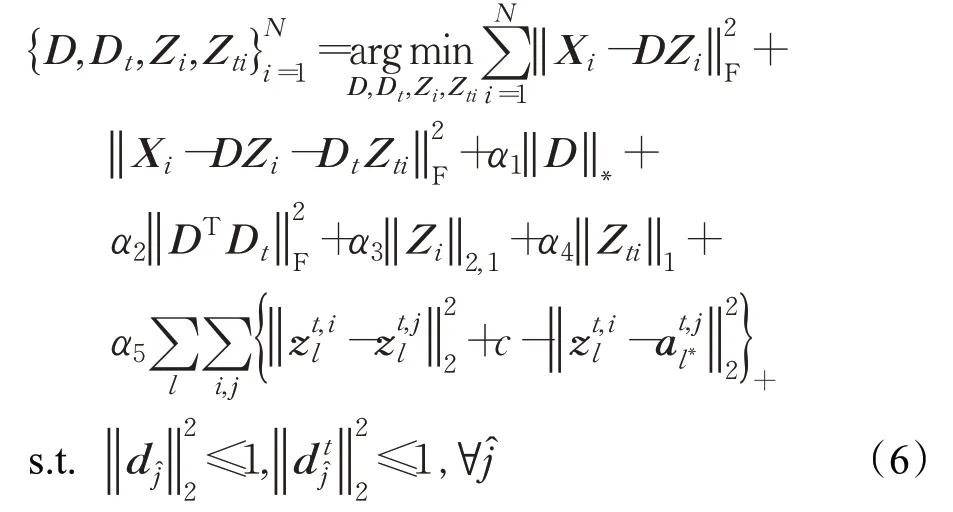
该模型可以扩展为多个视角和一个行人身份拥有多幅图像的行人重识别问题:

式中,表示i视角下的第k个行人的第l k张图像的编码系数;表示j视角下的和i视角下第k个行人第l k张图像的编码系数最不相似的第s k张图像的编码系数,此时它们属于同一行人身份,其中i≠j;表示i′视角下的和i视角下第k个行人第l k张图像的编码系数最相似的第k′个行人第l k′张图像的编码系数,此时它们属于不同行人身份,即k′≠k。式中,M i表示i相机视角下的行人数量,N k表示相机视角i下第k个行人的图像数量。
1.2 模型优化求解
1.2.1 更新Z i
为了更新编码系数Z i,固定D,D t,Z t,i不变,式(7)中关于Z i有以下目标函数:
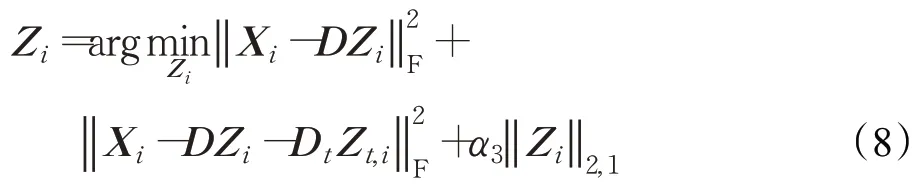
对于变量Z i是一个典型的l2,1最小化问题,通过文献[31]的方法可以很容易地解决它,此时,得到Z i的解析解:

其中,Λ1是由构成的对角稀疏矩阵,表示Z i的第j列。
1.2.2 更新Z t,i
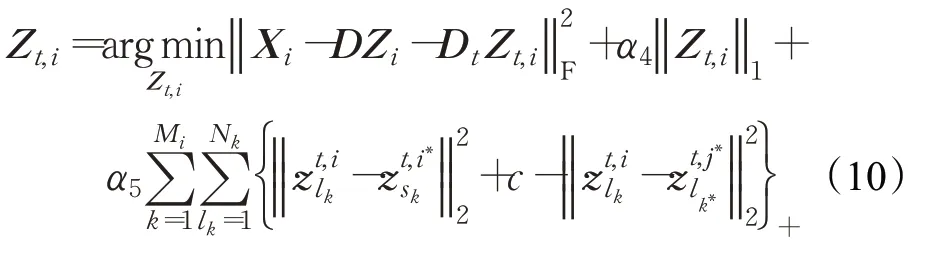
为了方便优化,将式(10)重写为向量形式:
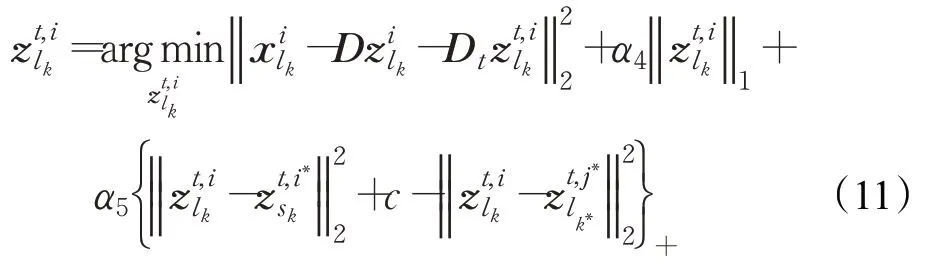
其中,是i视角下第k个行人的第l k张图像的特征。为了求解式(11)中的,需要引入一个松弛变量,此时,可以将等式(11)放宽为:
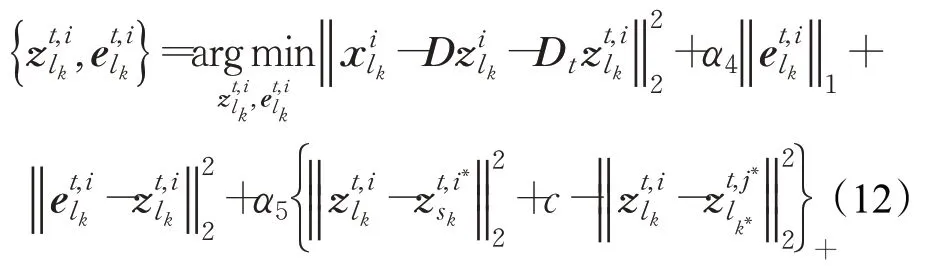
可以通过以下求解来更新变量:
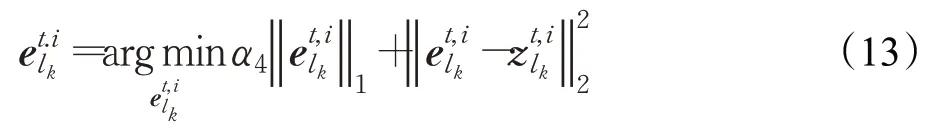
以上问题也是一个典型的l1最小化问题,使用迭代收缩算法Iterative Shrinkage Algorithm[32]可以很容易地解决这个问题。确定之后,可以通过文献[19]中采用的梯度下降法进行更新:
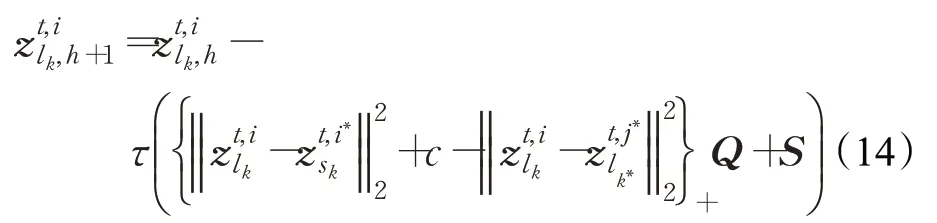
式中,h表示第h次迭代。,它 是 式(12)中关于在第h次迭代时的求导。Q=,它 是 式(12)中关于在第h次迭代时的求导。并且在求解过程中,当时,损失 记 为0,即取0,有;否则,。τ是梯度下降法中使用的步长,它根据迭代的次数进行变化,即。最后,根据更新的构造Z t,i,
1.2.3 更新D和D t
在更新编码系数Z i和Z t,i之后,字典D和D t可以通过交替更新获得,固定其他变量不变,式(7)中关于D和D t有以下目标函数:
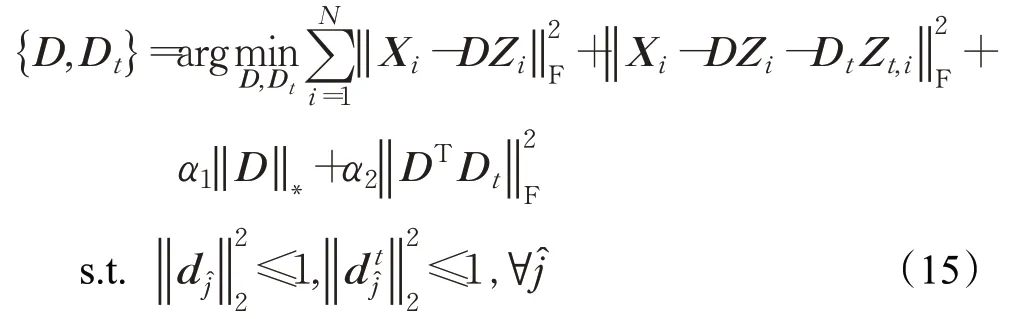
为了更新D,引入一个中间变量C,式(15)改写为:
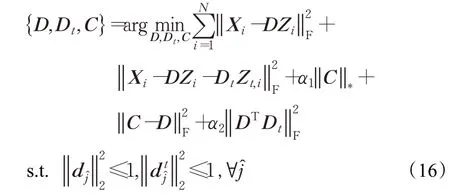
中间变量C可以通过以下求解得到:
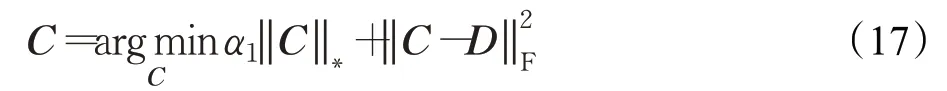
关于变量C是一个典型的核范数最小化问题,可通过奇异值阈值算法Singular Value Thresholding[33]来解决。确定C之后,引入一个松弛变量H更新D:
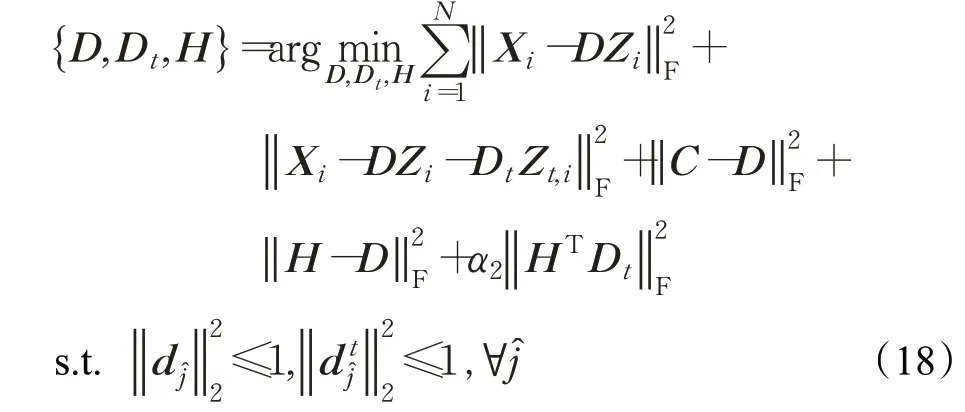
松弛变量H的解析解可以通过直接求导得到:

其中,I1∈ℜm×m为一个单位矩阵。使用更新得到的C和H,关于变量D可以通过以下求解来优化:
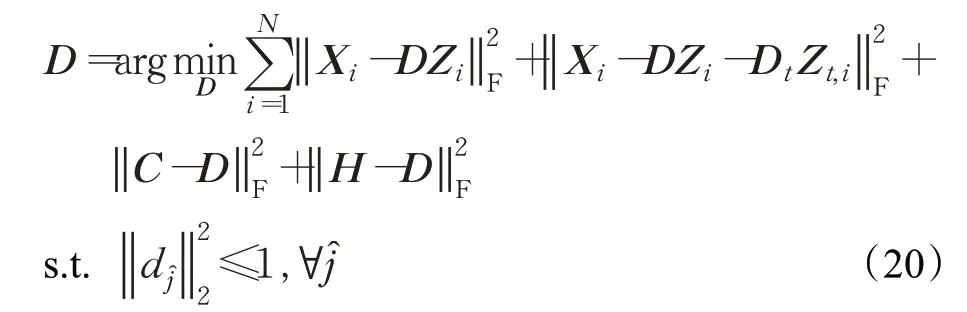
这个问题可以通过拉格朗日对偶法[34]来解决,其解析解为:
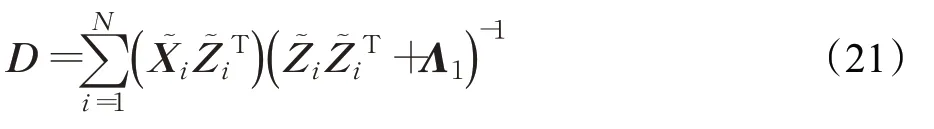
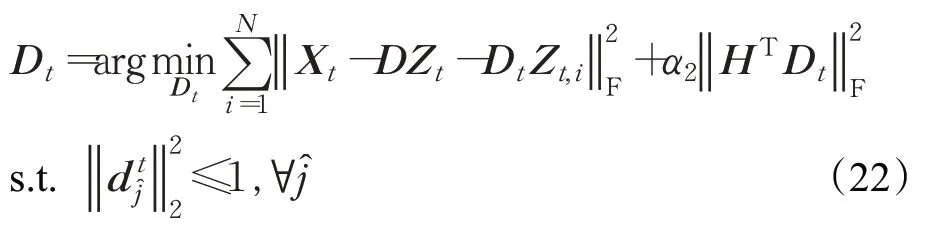
同样地,此问题也可以用公式(20)中采用的拉格朗日对偶法[34]得到解决。为了便于理解模型,以下算法总结了提出的判别性字典对学习的训练算法。
算法域通用和域分离字典对学习的行人重识别训练算法
输入:视角i下的行人训练图像X i,最大迭代次数M。
随机值初始化:Z i,Z t,i,D,D t。
当迭代次数小于M时,重复步骤1~8:
步骤1通过式(9)更新Z i;
步骤2通过迭代收缩算法更新式(13)中的;
步骤3通过式(14)更新;
步骤4通过构造Z t,i;
步骤5通过式(17)更新中间变量C;
步骤6通过式(19)更新松弛变量H;
步骤7通过式(21)更新变量D;
步骤8通过式(22)更新变量D t;
输出 当达到最大迭代次数M时输出D,D t。
1.3 识别方案
在测试中,用训练中学习到的字典D和D t,通过以下求解来实现域信息和特定行人信息的分离:
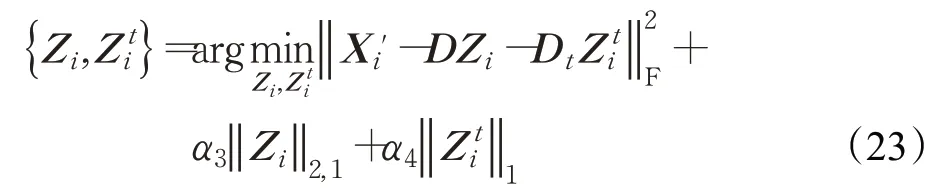
在式(23)中,X i'是测试样本,Z i表示视角i下的编码系数矩阵,Z ti表示视角i下的特定行人信息的编码系数矩阵,这个问题可以通过交替迭代法解决。首先固定变量{D,Zi t}更新Z i,关于Z i的目标函数表示为:
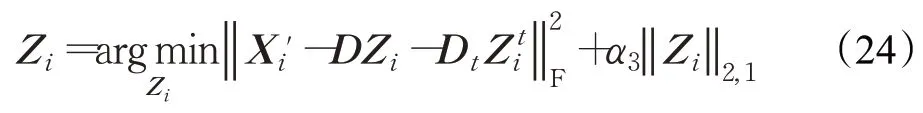
对于变量Z i也是一个l2,1最小化问题,通过文献[31]的方法可以很容易地解决它,此时,得到Z i的解析解:

其中,Λ1是由构成的对角矩阵,表示Z i的第j列。确定Z i以后,更新变量,式(23)关于的目标函数为:
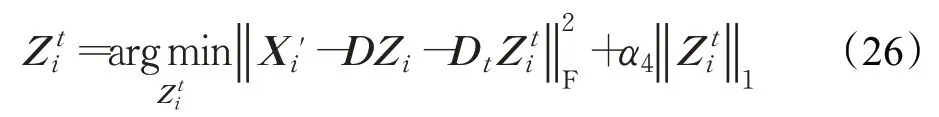
以上关于求解的问题也是一个典型的l1最小化问题,使用迭代收缩算法Iterative Shrinkage Algorithm[32]可以很容易地解决这个问题。
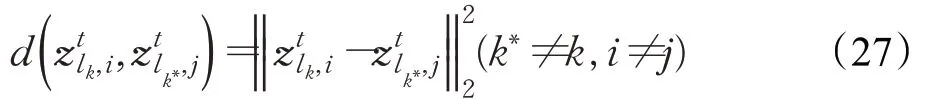
其中,表示相机视角j中第k*个行人的第l k*幅图像的编码系数。
2 实验结果与分析
2.1 数据集和参数设置
实验中,使用四个具有挑战性的行人重识别数据集证明该方法的有效性,包括PRID2011、GRID、CUHK01和i-LIDS。PRID2011数据集中的行人图像是由室外环境下的两个非重叠相机捕获,并且每个视角下都包含干扰图像。GRID数据集也存在大量不相关的行人干扰图像,并且两视角之间的遮挡,照明和背景情况存在较大差异。在CUHK01数据集中,每个身份在每个相机视角下都有两张图像,此数据集中的所有图像都来自安置于校园内的两台不同的相机。i-LIDS数据集中的行人图像是通过安装在机场到达大厅中的多个非重叠相机捕获,该数据集包含119个行人身份的476张图像,不同相机拍摄到的每个行人有2到8张不等。这些数据集具有不同的特征,因此可以更客观、全面地测试算法的性能。
在实验中,每个数据集被分为两个部分,一部分用作训练样本,另一部分用作测试样本,同时采用累积匹配特性(cumulative matching characteristic,CMC)曲线对识别性能进行定量评估。在提出的行人重识别模型中有七个参数,包括字典D和D t的大小d和d t,以及五个标量参数α1,α2,α3,α4,α5。为了对算法的有效性进行验证,在整个实验过程中,将上述参数的值分别设置为d=50,d t=760,α1=1,α2=0.01,α3=28,α4=1,α5=5。这些参数对识别性能的影响将在后面的小节中进行详细讨论。
2.2 GRID数据集
第一组实验在GRID数据集上进行,从不同视角拍摄得到的一些示例图像如图3所示。从这些图像可以看出,除了存在遮挡、行人姿势、照明等巨大变化以外,还存在大量不相关的行人图像的干扰,由此可见,该数据集对于行人重识别来说具有极大的挑战性。GRID数据集里的图像是从安置于地铁站中的8个非重叠摄像头拍摄得到,在此数据集中,有250个行人图像对,有775张不属于这250个行人对中的干扰图像,共有1 275个行人图像。本实验中,随机选择了125个行人身份的图像对作为训练数据,其余125个行人图像对与所有不相关的行人图像一起作为测试数据。重复该过程10次,并将平均识别率作为最终识别结果。将该方法与MtMCML(2014)[35]、PolyMap(2015)[36]、LOMO+XQDA(2015)[3]、LSSCDL(2016)[37]、DR-KISS(2016)[38]、GOG+XQDA(2016)[10]、SLSSCDL(2017)[26]、MHF(2017)[39]、DMLV(2017)[40]、CRAFT-MFA(2018)[41]、MKFSL(2017)[42]、DMVFL(2018)[43]、CSPL+GOG(2018)[44]、SRR+MSTC(2019)[45]进行对比。表1的结果显示本文的方法在GRID数据集上有很好的识别率,并且在Rank 1、Rank 5、Rank 20分别优于第二好的方法4.10、1.06和1.18个百分点。

图3 来自GRID数据集的行人图像示例Fig.3 Person image examples taken from GRID dataset
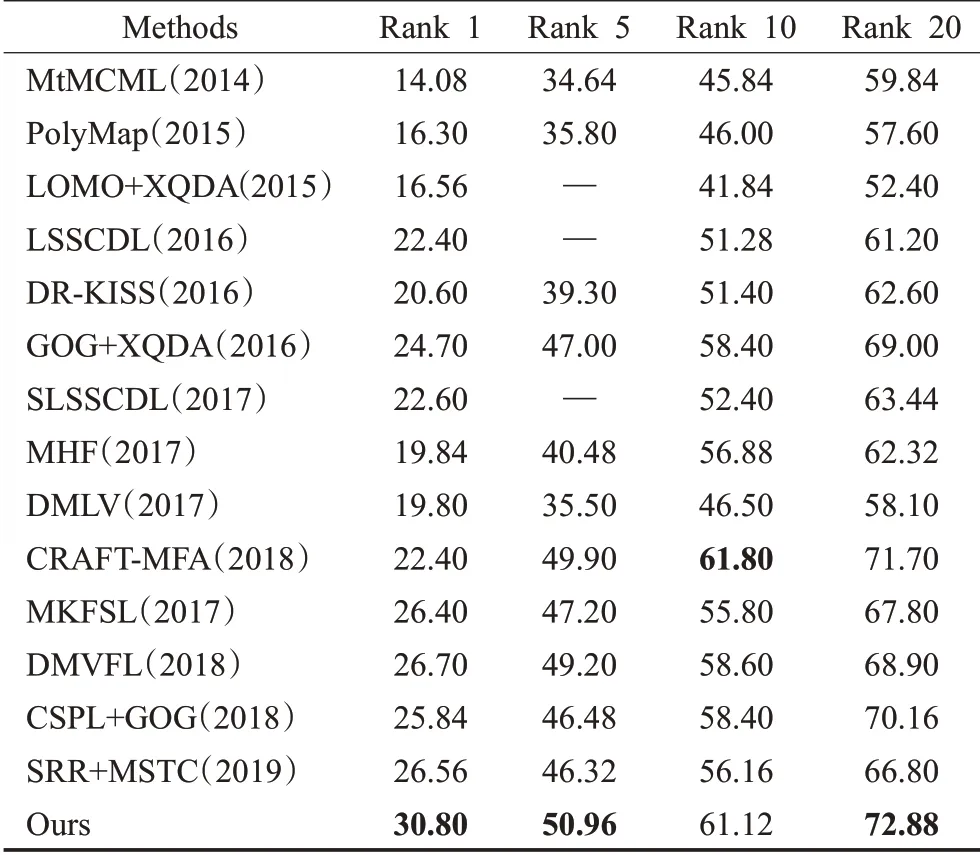
表1 不同算法在GRID数据集的识别率比较Table 1 Performance comparison of different algorithms on GRID %
2.3 PRID2011数据集
在PRID2011数据集上进行第二组实验,该数据集中的行人图像由室外环境下的两个非重叠摄像头捕获得到,每个人在每个相机视角中只有一个图像。在本实验中,随机选择100个行人身份的图像作为训练数据,并另外选择100个行人身份图像和749个干扰图像作为测试数据。重复该过程10次,将平均识别率视为最终识别结果,如图4。由于两个视角都存在干扰因素,该数据集更具挑战性。在PRID2011数据集上将本文的方法与一些最新方法进行了比较,如表2,包括RPLM(2012)[46]、MetricEnsemble(2015)[47]、LDNS(2016)[48]、LOMO+XQDA(2015)[3]、TCP(2016)[49]、LOMO+M(2017)[50]、LADF(2017)[40]、DMLV(2017)[40]、MKFSL(2017)[42]、APDLIC(2018)[25]。比较结果表明,该方法在不同Rank上的识别率最高,比次优方法分别高5.4、3.9、4.9和0.5个百分点。

图4 来自PRID2011数据集的行人图像示例Fig.4 Person image examples taken from PRID2011 dataset

表2 不同算法在PRID2011数据集的识别率比较Table 2 Performance comparison of different algorithms on PRID2011%
2.4 CUHK01数据集
在CUHK01数据集中,有971个行人身份被安置于校园环境中的两个不同摄像头捕获。与上述数据集不同,每个人在每个相机视图中都有两张图像,一个相机视角捕获行人的正视图或后视图,而另一个相机视角则主要捕获侧视图。在实验中,将所有行人图像标准化为128×48像素,并随机选择485个行人图像对进行训练,486个行人图像对进行测试。重复该过程10次,将平均结果作为最终行人的匹配率,如图5。表3显示了本文算法与MetricEnsemble(2015)[47]、LOMO+XQDA(2015)[3]、TCP(2016)[49]、DRJRL+kLFDA(2016)[29]、LDNS(2016)[48]、GOG+XQDA(2016)[10]、DR-KISS(2016)[38]、LADF(2017)[40]、DMLV(2017)[40]、MVLDML(2018)[21]、CSPL+GOG(2018)[44]、GOG+TDL(2019)[51]算法的比较结果。提出的方法显示了不错的识别结果,Rank 1值为71.20%,比次优算法高1.02个百分点。

图5 来自CUHK01数据集的行人图像示例Fig.5 Person image examples taken from CUHK01 dataset
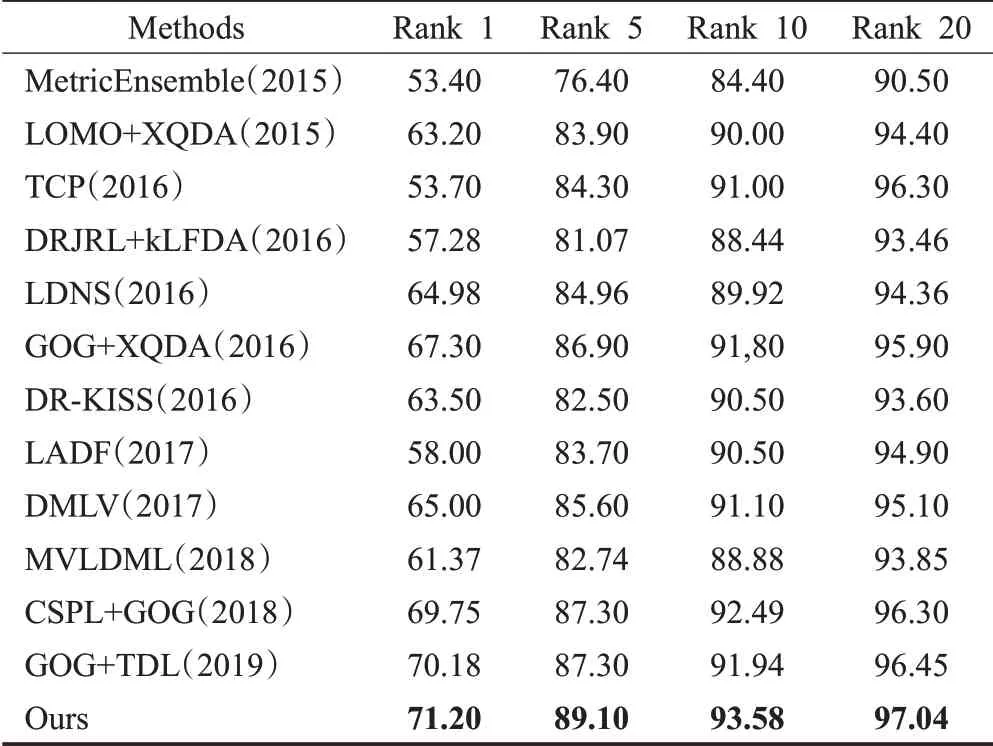
表3 不同算法在CUHK01数据集的识别率比较Table 3 Performance comparison of different algorithms on CUHK01%
2.5 i-LIDS数据集
在本次实验中,验证了该模型在多镜头i-LIDS数据集上的有效性。该数据集中的行人图像是通过安装在机场到达大厅中的多个非重叠摄像头捕获。该数据集包含119人的476张图像,在不同的相机视角下行人图像的范围从1到8不等。图6展示了一些行人示例图像。由于这些图像是由具有不同背景、不同相机采集的,并且还存在照明、遮挡和姿势差异的变化,因此,该数据集对正确匹配来自不同相机的行人图像提出了巨大的挑战。在此实验中,随机选择60人进行训练,其余59人被用来测试。实验进行了10次以后,取平均值与近年来提出的其他方法进行比较。表4显示了该算法与PRDC(2011)[52]、MetricEnsemble(2015)[47]、FT-JSTL+DGD(2016)[53]、TCP(2016)[49]、JDML(2017)[27]、MLQAW(2017)[16]、MMLBD(2017)[54]、FSCML(2017)[55]、JDSML(2019)[28]和GOG+TDL(2020)[51]的比较结果。可以清楚地看到,与其他方法相比,本文的方法在i-LIDS数据集上的性能有了很大的提高。

图6 来自i-LIDS数据集的行人图像示例Fig.6 Person image examples taken from i-LIDS dataset
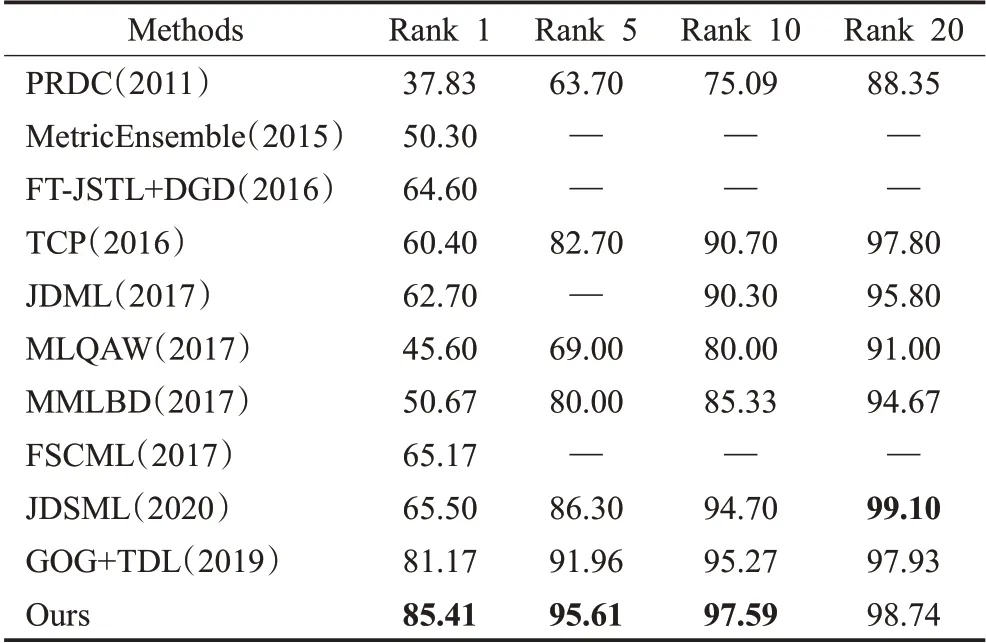
表4 不同算法在i-LIDS数据集的识别率比较Table 4 Performance comparison of different algorithms on i-LIDS %
2.6 算法分析
2.6.1 参数的影响和选择
实验中,字典D和D t的大小是影响算法性能的两个关键参数。因此,有必要讨论由字典原子数变化而引起的性能变化。在此过程中,使用GRID数据集作为测试集,通过固定一个字典的原子数大小,研究另一字典的原子数大小对识别性能的影响。图7显示了识别性能与两字典原子数d和d t值的关系。固定其余参数,调整字典D的大小d从20变为400,从图7(a)的结果可以看出,当d达到50时,本文的方法可以实现较高的识别精度。此外,还研究了d t对GRID数据集的影响,图7(b)表明,当d固定为50时,d t=760算法可以实现较高的识别性能。

图7 GRID数据集上不同字典大小D和D t对应的性能Fig.7 Performance of our algorithm on different sizes of D andD t on RID dataset
除字典D和D t的大小外,还需要设置五个标量参数,即α1、α2、α3、α4、α5。使用交叉验证来确定这些参数的取值。此过程在GRID和PRID2011数据集上进行,如图8、图9。首先,将α2、α3、α4、α5分别固定为0.01、28、1和5,然后讨论α1的影响。图8(a)和图9(a)显示了在GRID和PRID2011数据集上将α1设置为不同值时的影响。从结果可以看出,当α1达到1时,模型可以获得更好的性能,因此将其设置为1。在α1=1、α3=28、α4=1、α5=5的情况下,从图8(b)和图9(b)可以发现,当α2=0.01时算法可以达到不错的识别性能。图8(c)和图9(c)显示了当α1、α2、α4、α5分别固定为1、0.01、1和5时,α3=28算法可以为两个测试数据集实现较好的性能。为了研究参数α4的取值效果,分别将α1、α2、α3、α5固定为1、0.01、28和5。图8(d)和图9(d)表明,当α4达到1时,算法的识别精度达到平稳状态。此外,图8(e)和图9(e)显示了识别率与α5值的关系,其中α1、α2、α3、α4分别固定为1、0.01、28和1,当两个测试数据集的α5均达到5时,模型将获得令人满意的性能。
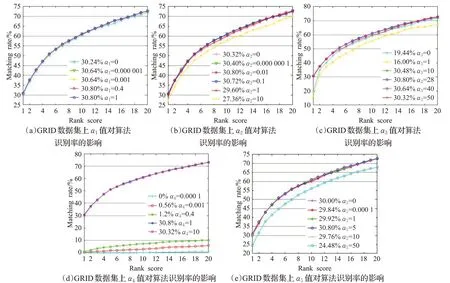
图8 GRID数据集上不同的α1、α2、α3、α4、α5值对算法识别率的影响Fig.8 Recognition rates of proposed algorithm on different values ofα1,α2,α3,α4,α5 on GRID dataset
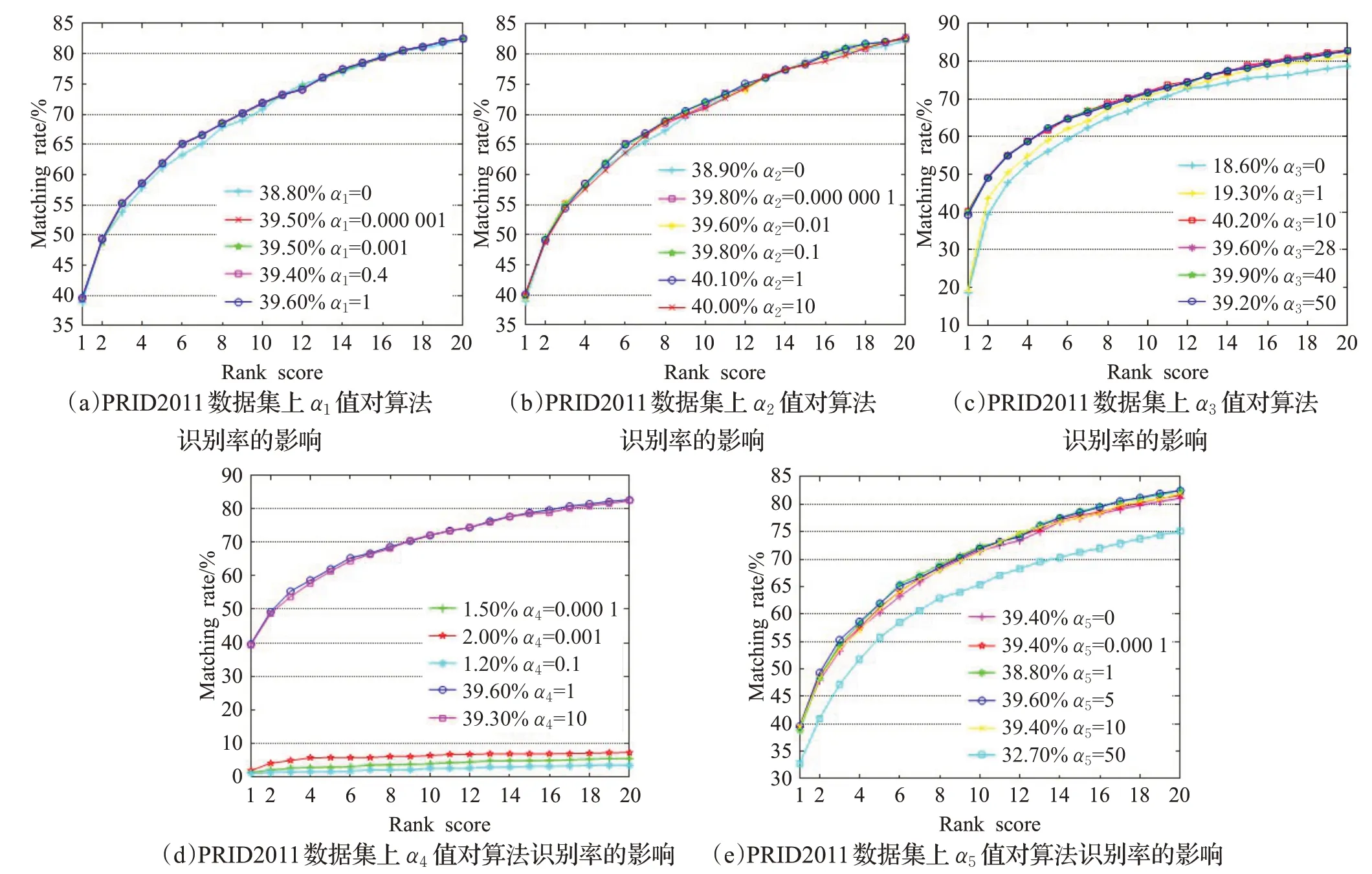
图9 PRID2011数据集上不同的α1、α2、α3、α4、α5值对算法识别率的影响Fig.9 Recognition rates of proposed algorithm on different values ofα1,α2,α3,α4,α5 on PRID2011 dataset
2.6.2 收敛分析
式(3)并非对变量{D,D t}都是共同凸的,但对于它们各自而言是凸的。而诸如上述的收敛问题已经被广泛研究,并可通过交替迭代方法来解决。因此,本小节对两个字典的收敛性进行分析。图10显示了GRID数据集上两个字典的收敛曲线。可以清楚地看到,经过不到10次迭代,所有变量的迭代差值逐渐收敛为0。
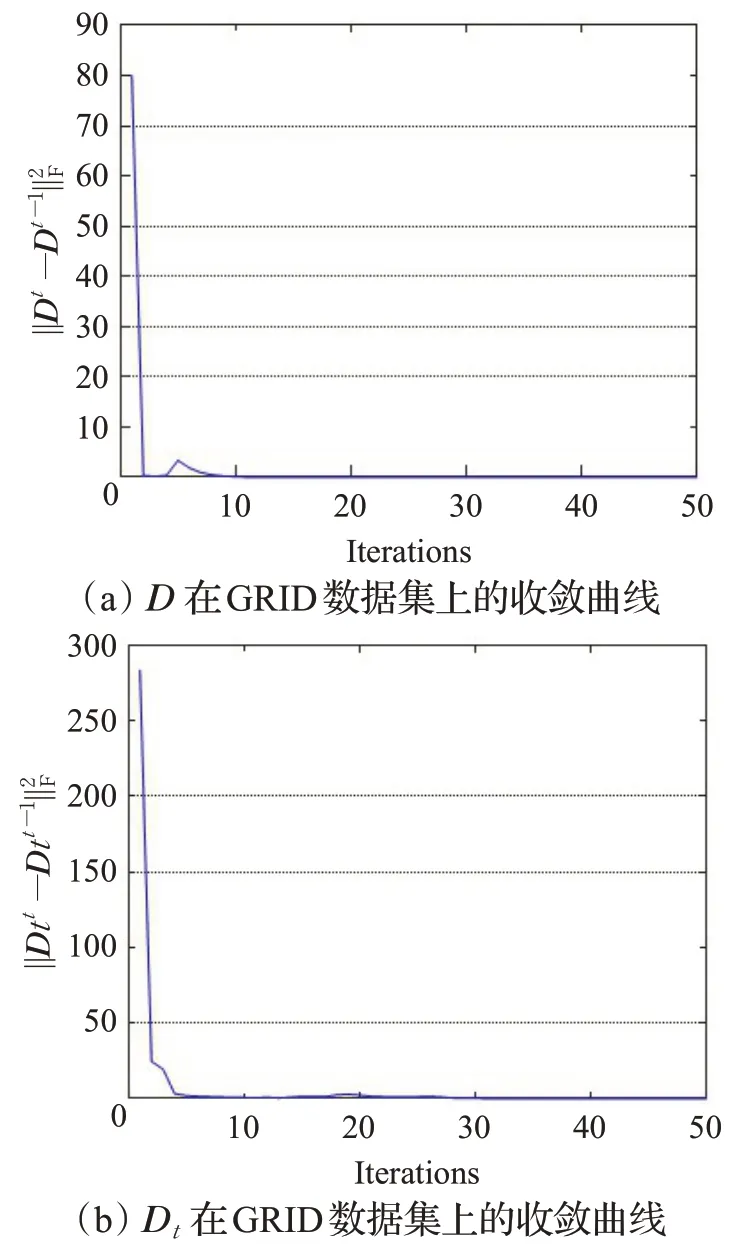
图10 D、D t在GRID数据集上的收敛曲线Fig.10 Convergence curve of D and D t on GRID dataset
2.6.3 仅基于行人外观设计匹配方案的优势分析
公式(6)是仅基于行人外观设计匹配方案的目标函数,在式(6)中,通过项将域信息从行人图像中分离了出来,此时,剩余的行人图像信息不会受到域信息的干扰。若没有分离域信息,直接基于同时存在域信息分量和行人外观信息分量的图像训练模型,目标函数将会变成:

此时训练的模型将会受到不同视角下的不同域信息的干扰。具体地,在GRID数据集上分析仅基于行人设计的优势,图11显示了仅基于行人外观设计匹配方案和基于同时存在域信息分量和行人外观信息分量设计匹配方案两个模型的识别率曲线。由图11可以看出,本文仅基于行人外观设计匹配方案的识别率远远高于基于同时存在域信息分量和行人外观信息分量设计匹配方案的识别率。

图11 在GRID数据集上仅基于行人外观设计匹配方案的算法曲线分析Fig.11 Algorithm curve analysis based only on person appearance design matching scheme on GRID dataset
3 结束语
为了缓解由不同相机视角引起的域偏移问题,提出了一种基于不同成分分离的域分离的图像特征表示模型。该模型可以将域信息与行人图像信息进行分离,从而实现跨视角的行人重识别。同时,为了提高表示系数的判别性,提出了一种新颖的扩展正则化方法,以鼓励外貌相似身份却不同的行人彼此远离。在四个具有挑战性的数据集上进行实验,由于本文的算法可以有效缓解不同相机视角之间的域偏移问题,因此与其他一些相关方法相比具有更好的性能。相对于深度学习方法,本文算法可以不用大规模的训练样本就能获得较好的性能,同时在复杂的背景环境及变化的光照视角条件下也能取得良好的匹配结果,因此具有较好的实际意义。
猜你喜欢
家教世界(2023年28期)2023-11-14 10:13:50
家教世界(2023年25期)2023-10-09 02:11:56
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09 06:12:12
意林(2021年5期)2021-04-18 12:21:17
汉字汉语研究(2020年2期)2020-08-13 07:52:48
电子制作(2019年22期)2020-01-14 03:16:24
扬子江(2019年1期)2019-03-08 02:52:34
疯狂英语·新读写(2018年3期)2018-11-29 22:37:11
小天使·一年级语数英综合(2017年6期)2017-06-07 23:51:16
创新作文(小学版)(2016年19期)2016-08-22 05:54:08
